作业①:
1)指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。
代码解析
weather_spiders.py文件
解析起始页面
def parse(self, response):urls = response.xpath('//div[@class="tu"]/a/@href').extract()for url in urls:yield scrapy.Request(url=url, callback=self.imgs_parse)
- parse 方法是 Scrapy 默认的回调方法,处理响应并提取数据。
- 使用 XPath 提取特定 div 下的所有链接,生成一个 URL 列表。
- 对每个提取的 URL,创建一个新的 scrapy.Request,并将其交由 imgs_parse 方法处理。
解析图片链接
def imgs_parse(self, response):item = WeatherItem()item["pic_url"] = response.xpath('/html/body/div[3]/div[1]/div[1]/div[2]/div/ul/li/a/img/@src').extract()yield item
- imgs_parse 方法用于处理每个图像页面的响应。
- 创建 WeatherItem 实例以存储数据。
- 使用 XPath 提取图像链接,并将其存储在 pic_url 字段中。
- 最后,通过 yield 返回 item,将数据传递给 Scrapy 的管道处理。
pipelines.py文件
覆盖 get_media_requests 方法
def get_media_requests(self, item, info):for i in range(len(item['pic_url'])):yield scrapy.Request(url=item['pic_url'][i])
- get_media_requests 方法负责生成每个图片的下载请求。
- item 参数是 Scrapy Item 对象,包含了爬虫抓取到的数据。
- info 参数是关于当前请求的信息。
覆盖 item_completed 方法
def item_completed(self, results, item, info):if not results[0][0]:raise DropItem('下载失败')return item
- item_completed 方法在所有图片下载完成后调用。
- results 是一个列表,每个元组包含两个元素,第一个元素是下载成功与否的布尔值,第二个元素是保存图片信息的字典。
- 通过 if not results[0][0]: 判断第一个下载请求是否成功,如果失败,就抛出 DropItem 异常,以丢弃这个 item,且输出 '下载失败' 的消息。
- 如果下载成功,返回原始的 item。
items.py文件
class WeatherItem(scrapy.Item):pic_url = scrapy.Field()
settings.py文件
- Scrapy 默认是多线程的,但你可以通过配置来限制它的并发请求数,从而实现单线程和多线程的爬取。
*单线程爬取
CONCURRENT_REQUESTS = 1 - 多线程爬取
CONCURRENT_REQUESTS = 16
输出信息
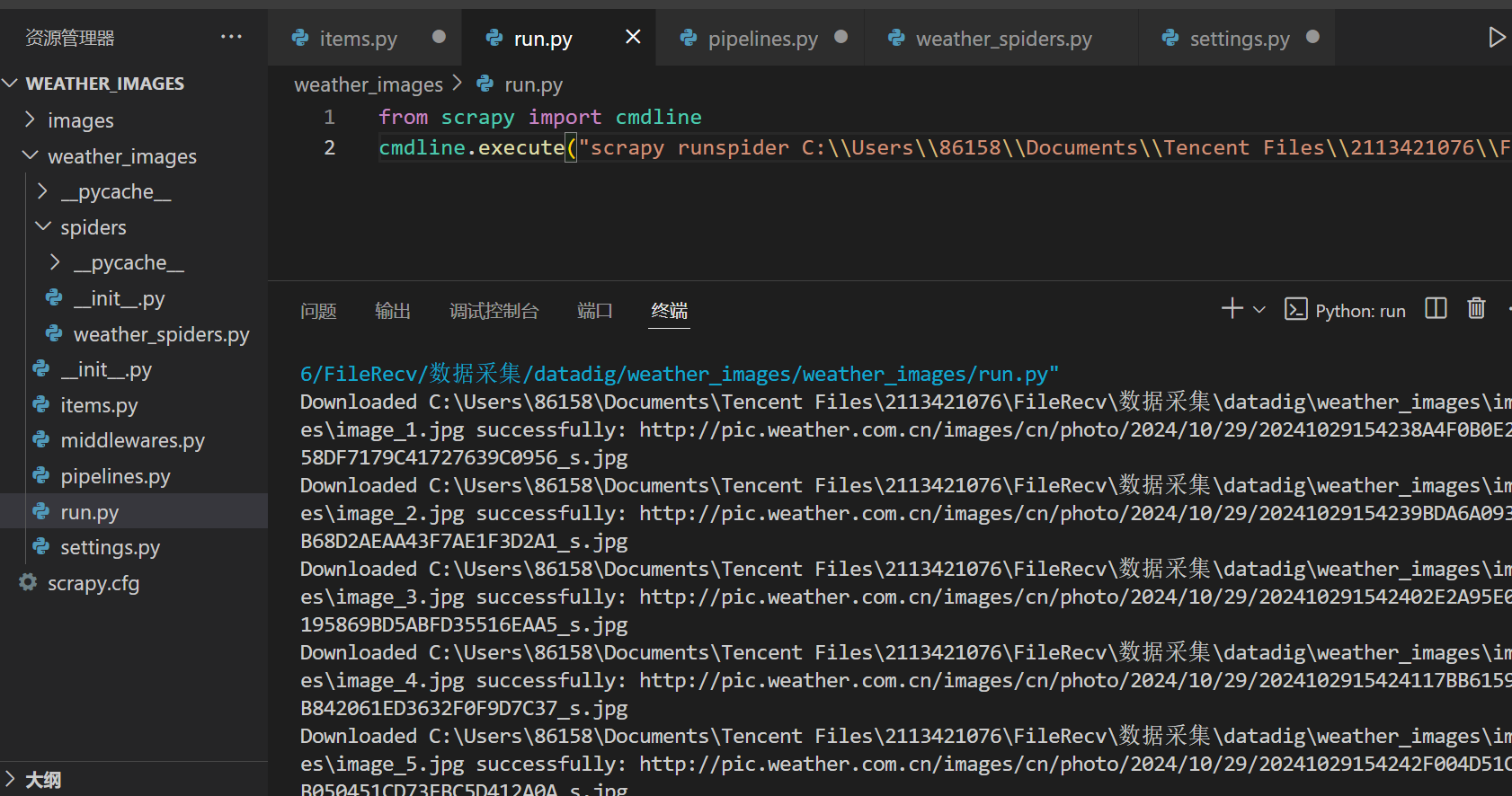
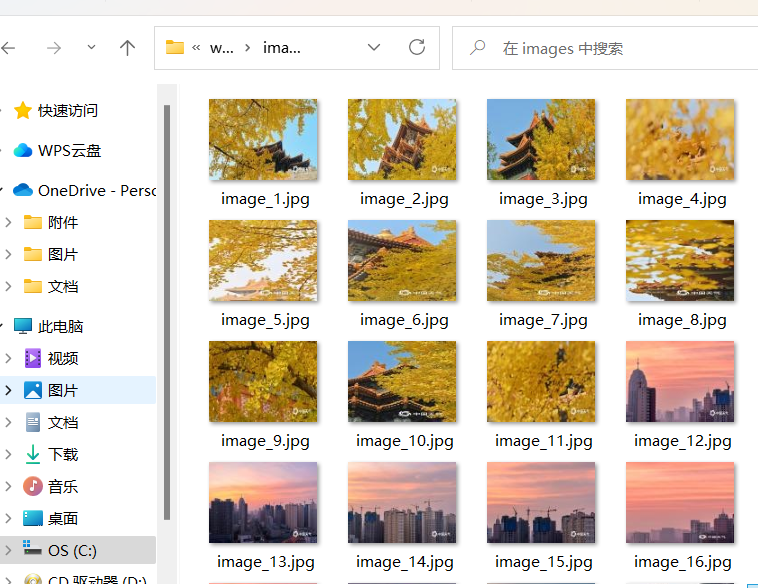
Gitee文件夹链接
2)心得体会
-
XPath 的灵活性:XPath 是提取 HTML 表达式的强大工具。在代码中,正是利用 XPath 成功定位了所需数据。对于复杂的网页结构,掌握 XPath 能够简化数据提取过程。
-
Scrapy 工具链:Scrapy 的请求和回调机制使得抓取过程可以实现高效而清晰的工作流。通过 yield 返回请求和数据,保持了代码的简洁性与优雅性。
-
数据处理:使用自定义的 WeatherItem 使得数据在抓取后可以方便地进行处理,这符合面向对象编程的理念,能够提升代码的模块化和重用性。
作业②
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
候选网站:东方财富网:https://www.eastmoney.com/
代码解析
stock_spiders.py文件
- 定义 parse 方法,接收网页响应。
- 使用 XPath 获取包含股票数据的 div 元素。
for stock in stocks:item = StockItem()item['bStockNo'] = stock.xpath('.//div[@class="code"]/text()').get()item['bStockName'] = stock.xpath('.//div[@class="name"]/text()').get()item['latestPrice'] = stock.xpath('.//div[@class="latest"]/text()').get()item['priceChangePercent'] = stock.xpath('.//div[@class="percent"]/text()').get()item['priceChange'] = stock.xpath('.//div[@class="change"]/text()').get()item['volume'] = stock.xpath('.//div[@class="volume"]/text()').get()item['amplitude'] = stock.xpath('.//div[@class="amplitude"]/text()').get()item['highest'] = stock.xpath('.//div[@class="highest"]/text()').get()item['lowest'] = stock.xpath('.//div[@class="lowest"]/text()').get()item['openPrice'] = stock.xpath('.//div[@class="open"]/text()').get()item['closePrice'] = stock.xpath('.//div[@class="close"]/text()').get()yield item
- 遍历获取的股票数据,创建 StockItem 实例。
- 使用 XPath 提取每个股票的各项信息,并赋值给 item。
- 最后,使用 yield 将 item 返回。
pipelines.py文件
self.cursor = self.connection.cursor()
self.cursor.execute('''CREATE TABLE IF NOT EXISTS stocks (id INT PRIMARY KEY AUTO_INCREMENT,bStockNo VARCHAR(20),bStockName VARCHAR(100),latestPrice FLOAT,priceChangePercent FLOAT,priceChange FLOAT,volume VARCHAR(20),amplitude VARCHAR(20),highest FLOAT,lowest FLOAT,openPrice FLOAT,closePrice FLOAT)
''')
self.connection.commit()
- 创建一个游标以执行 SQL 语句。
- 检查并创建 stocks 表,如果表不存在的话。
def close_spider(self, spider):self.cursor.close()self.connection.close()
- 定义 close_spider 方法,负责关闭数据库连接和游标。
def process_item(self, item, spider):self.cursor.execute('''INSERT INTO stocks (bStockNo, bStockName, latestPrice, priceChangePercent,priceChange, volume, amplitude, highest, lowest, openPrice, closePrice)VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)''', (item['bStockNo'], item['bStockName'], item['latestPrice'],item['priceChangePercent'], item['priceChange'], item['volume'],item['amplitude'], item['highest'], item['lowest'],item['openPrice'], item['closePrice']))self.connection.commit()return item
- 定义 process_item 方法,处理每个抓取到的 item。
- 使用 SQL 语句将数据插入数据库,并提交更改。
itmes.py
class StockItem(scrapy.Item):id = scrapy.Field() # 序号bStockNo = scrapy.Field() # 股票代码bStockName = scrapy.Field() # 股票名称latestPrice = scrapy.Field() # 最新报价priceChangePercent = scrapy.Field() # 涨跌幅priceChange = scrapy.Field() # 涨跌额volume = scrapy.Field() # 成交量amplitude = scrapy.Field() # 振幅highest = scrapy.Field() # 最高lowest = scrapy.Field() # 最低openPrice = scrapy.Field() # 今开closePrice = scrapy.Field() # 昨收
输出信息
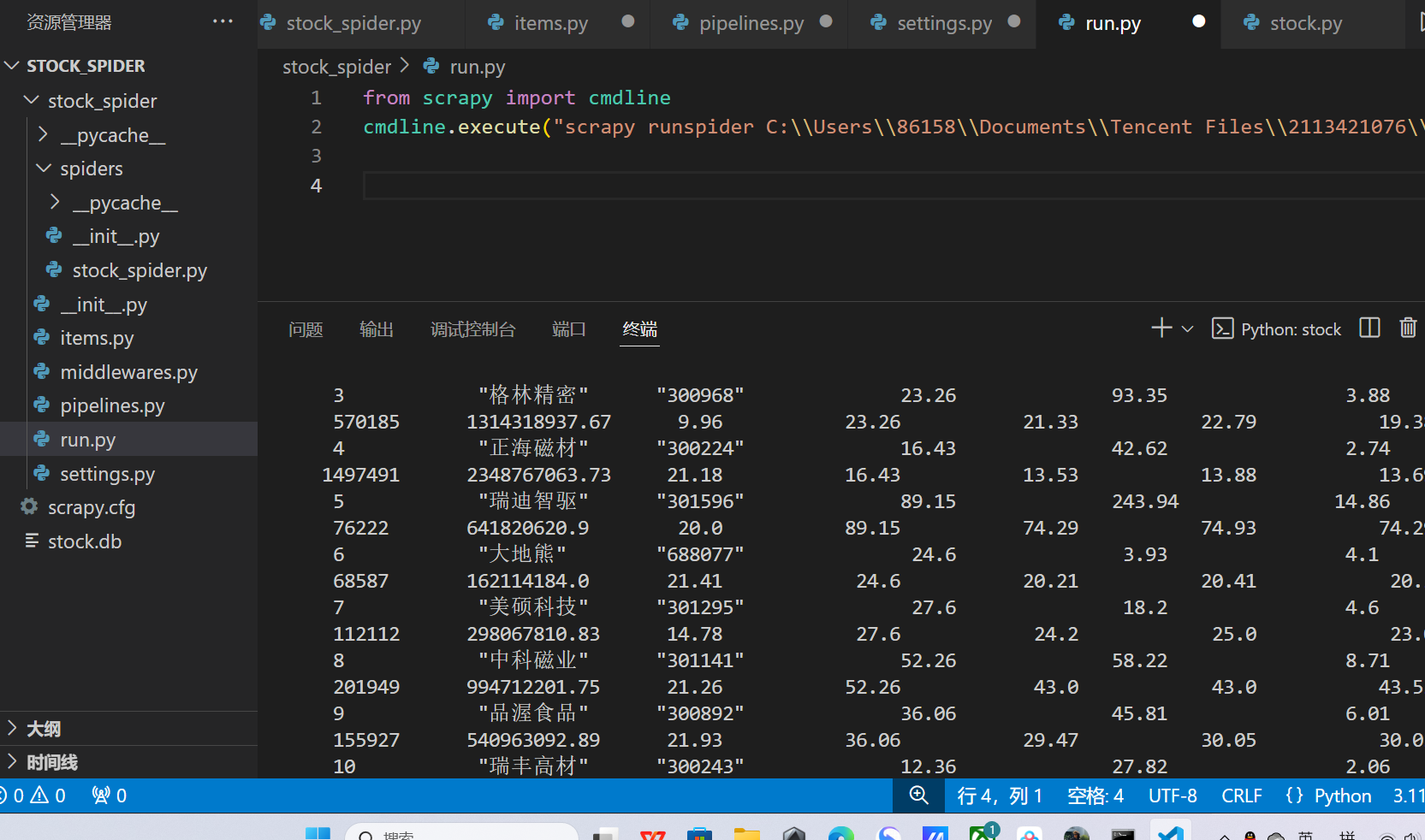
Gitee文件夹链接
2)心得体会
-
使用 pymysql 连接数据库是一种常见的做法,配置从 Scrapy 设置中获取,增强了灵活性和可维护性。
-
写代码要考虑到良好的资源管理,确保在爬虫结束后释放数据库连接,有助于避免资源泄漏。
-
可以考虑增加错误处理机制,以提高程序的鲁棒性。
作业③:
1)熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
代码解析
myspiders.py文件
- 使用 XPath 获取数据的方式灵活且高效,为后续数据提取做好准备。
for tr in trs[1:]:Currency = tr.xpath("./td[1]/text()").extract_first().strip()TSP = tr.xpath("./td[4]/text()").extract_first().strip()CSP = tr.xpath("./td[5]/text()").extract_first().strip()TBP = tr.xpath("./td[6]/text()").extract_first().strip()CBP = tr.xpath("./td[7]/text()").extract_first().strip()Time = tr.xpath("./td[8]/text()").extract_first().strip()
- 遍历表格行,从每一行提取出所需的字段数据。
item['Currency'] = Currencyitem['TSP'] = TSPitem['CSP'] = CSPitem['TBP'] = TBPitem['CBP'] = CBPitem['Times'] = Timeitem['Id'] = contcont += 1yield item
- 将提取到的数据赋值给 item 对象,并通过 yield 返回。。
pipelines.py文件
connect = pymysql.connect(host='localhost', user='chenshuo', password='cs031904104',database='cs031904104', charset='UTF-8') cur = connect.cursor() - 建立数据库连接并创建游标,后续将使用该游标执行 SQL 命令。
try:cur.execute("insert into rate_cs (id,Currency,TSP,CSP,TBP,CBP,Times) values ('%d','%s','%s','%s','%s','%s','%s')" % (item['Id'], item['Currency'].replace("'", "''"), item['TSP'].replace("'", "''"),item['CSP'].replace("'", "''"), item['TBP'].replace("'", "''"),item['CBP'].replace("'", "''"), item['Times'].replace("'", "''")))connect.commit() # 提交命令except Exception as er:print(er)
- 使用 try 块执行插入操作,捕获并打印可能发生的异常。
- 使用 SQL 语句插入数据并提交更改,特别处理了单引号的问题以避免 SQL 错误。
connect.close() # 关闭与数据库的连接return item
- 关闭数据库连接并返回处理后的 item。
items.py文件
class Exp42Item(scrapy.Item):Currency = scrapy.Field()TSP = scrapy.Field()CSP = scrapy.Field()TBP = scrapy.Field()CBP = scrapy.Field()Times = scrapy.Field()Id = scrapy.Field()pass
输出信息
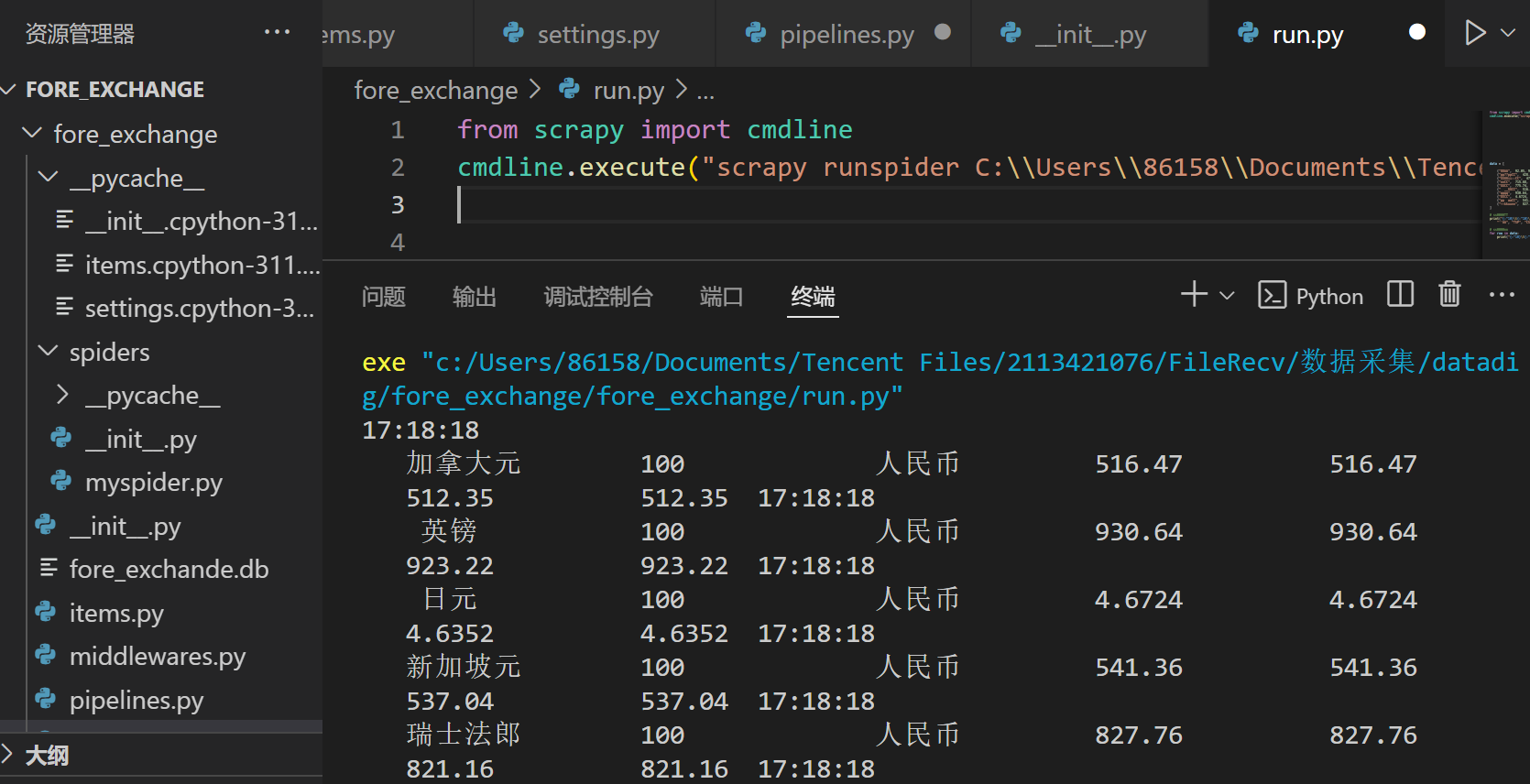
Gitee文件夹链接
2)心得体会
- 打印输出便于调试,帮助开发者查看数据是否正确提取。
- 虽然使用字符串格式化插入数据方便,但不够安全,易受 SQL 注入攻击,下次可以尝试使用参数化查询。