不管是服务导出还是服务引入,都发生在应用启动过程中,比如:在启动类上加上 @EnableDubbo 时,该注解上有一个 @DubboComponentScan 注解,@DubboComponentScan 注解 Import 了一个 DubboComponentScanRegistrar,DubboComponentScanRegistrar 中会调用 DubboSpringInitializer.initialize(),该方法中会注册一个 DubboDeployApplicationListener,而 DubboDeployApplicationListener 会监听 Spring 容器启动完成事件 ContextRefreshedEvent,一旦接收到这个事件后,就会开始 Dubbo 的启动流程,就会执行 DefaultModuleDeployer 的 start() 进行服务导出与服务引入。
在启动过程中,在做完服务导出与服务引入后,还会做几件非常重要的事情:
服务导出
当在某个接口的实现类上加上 @DubboService 后,就表示定义了一个 Dubbo 服务,应用启动时 Dubbo 只要扫描到了 @DubboService,就会解析对应的类,得到服务相关的配置信息,比如:
解析完服务的配置信息后,就会把这些配置信息封装成为一个 ServiceConfig 对象,并调用其 export() 进行服务导出,此时一个 ServiceConfig 对象就表示一个Dubbo 服务。
而所谓的服务导出,主要就是完成三件事情:
确定服务参数
一个 Dubbo 服务,除开服务的名字,也就是接口名,还会有很多其他的属性,比如:超时时间、版本号、服务所属应用名、所支持的协议及绑定的端口等众多信息。
但是,通常这些信息并不会全部在 @DubboService 中进行定义,比如:一个 Dubbo 服务肯定是属于某个应用的,而一个应用下可以有多个 Dubbo 服务,所以可以在应用级别定义一些通用的配置,比如协议。
在 application.yml 中定义:
dubbo:application:name: dubbo-springboot-demo-providerprotocol:name: triport: 20880表示当前应用下所有的 Dubbo 服务都支持通过 tri 协议进行访问,并且访问端口为 20880,所以在进行某个服务的服务导出时,就需要将应用中的这些配置信息合并到当前服务的配置信息中。
另外,除开可以通过 @DubboService 来配置服务,也可以在配置中心对服务进行配置,比如:在配置中心中配置:
dubbo.service.org.apache.dubbo.samples.api.DemoService.timeout=5000
表示当前服务的超时时间为 5s。
所以,在服务导出时,也需要从配置中心获取当前服务的配置,如果在 @DubboService 中也定义了 timeout,那么就用配置中心的覆盖掉,配置中心的配置优先级更高。
最终确定出服务的各种参数,这块内容和 Dubbo2.7 一致。
服务注册
当确定好了最终的服务配置后,Dubbo 就会根据这些配置信息生成对应的服务 URL,比如:
tri://192.168.65.221:20880/org.apache.dubbo.springboot.demo.DemoService?application=dubbo-springboot-demo-provider&timeout=3000
这个 URL 就表示了一个 Dubbo 服务,服务消费者只要能获得到这个服务 URL,就知道了关于这个 Dubbo 服务的全部信息,包括服务名、支持的协议、ip、port、各种配置。
确定了服务 URL 之后,服务注册要做的事情就是把这个服务 URL 存到注册中心(比如:Zookeeper)中去,说的再简单一点,就是把这个字符串存到 Zookeeper中去,这个步骤其实是非常简单的,实现这个功能的源码在 RegistryProtocol 中的 export() 方法中,最终服务 URL 存在了 Zookeeper 的 /dubbo/ 接口名 /providers 目录下。
但是服务注册并不仅仅就这么简单,既然上面的这个 URL 表示一个服务,并且还包括了服务的一些配置信息,那这些配置信息如果改变了呢?比如:利用 Dubbo管理台中的动态配置功能(注意,并不是配置中心)来修改服务配置,动态配置可以应用运行过程中动态的修改服务的配置,并实时生效。
如果利用动态配置功能修改了服务的参数,那此时就要重新生成服务 URL 并重新注册到注册中心,这样服务消费者就能及时的获取到服务配置信息。
而对于服务提供者而言,在服务注册过程中,还需要能监听到动态配置的变化,一旦发生了变化,就根据最新的配置重新生成服务 URL,并重新注册到中心。
应用级注册
在 Dubbo3.0 之前,Dubbo 是接口级注册,服务注册就是把接口名以及服务配置信息注册到注册中心中,注册中心存储的数据格式大概为:
接口名1:tri://192.168.1.221:20880/接口名1?application=应用名
接口名2:tri://192.168.1.221:20880/接口名2?application=应用名
接口名3:tri://192.168.1.221:20880/接口名3?application=应用名key 是接口名,value 就是服务 URL,上面的内容就表示现在有一个应用,该应用下有 3 个接口,应用实例部署在 192.168.1.221,此时,如果给该应用增加一个实例,实例 ip 为192.168.1.222,那么新的实例也需要进行服务注册,会向注册中心新增 3 条数据:
接口名1:tri://192.168.1.221:20880/接口名1?application=应用名
接口名2:tri://192.168.1.221:20880/接口名2?application=应用名
接口名3:tri://192.168.1.221:20880/接口名3?application=应用名接口名1:tri://192.168.1.222:20880/接口名1?application=应用名
接口名2:tri://192.168.1.222:20880/接口名2?application=应用名
接口名3:tri://192.168.1.222:20880/接口名3?application=应用名可以发现,如果一个应用中有 3 个 Dubbo 服务,那么每增加一个实例,就会向注册中心增加 3 条记录,那如果一个应用中有 10 个 Dubbo 服务,那么每增加一个实例,就会向注册中心增加 10 条记录,注册中心的压力会随着应用实例的增加而剧烈增加。
反过来,如果一个应用有 3 个 Dubbo 服务,5 个实例,那么注册中心就有 15 条记录,此时增加一个 Dubbo 服务,那么注册中心就会新增 5 条记录,注册中心的压力也会剧烈增加。
注册中心的数据越多,数据就变化的越频繁,比如:修改服务的 timeout,那么对于注册中心和应用都需要消耗资源用来处理数据变化。
所以为了降低注册中心的压力,Dubbo3.0 支持了应用级注册,同时也兼容接口级注册,用户可以逐步迁移成应用级注册,而一旦采用应用级注册,最终注册中心的数据存储就变成为:
应用名:192.168.1.221:20880
应用名:192.168.1.222:20880表示在注册中心中,只记录应用所对应的实例信息(IP + 绑定的端口),这样只有一个应用的实例增加了,那么注册中心的数据才会增加,而不关心一个应用中到底有多少个 Dubbo 服务。
这样带来的好处就是,注册中心存储的数据变少了,注册中心中数据的变化频率变小了,并且使用应用级注册,使得 Dubbo3 能实现与异构微服务体系如:Spring Cloud、Kubernetes Service 等在地址发现层面更容易互通, 为连通 Dubbo 与其他微服务体系提供可行方案。
应用级注册带来了好处,但是对于 Dubbo 来说又出现了一些新的问题,比如:原本,服务消费者可以直接从注册中心就知道某个 Dubbo 服务的所有服务提供者以及相关的协议、ip、port、配置等信息,那现在注册中心上只有 ip、port,那对于服务消费者而言:服务消费者怎么知道现在它要用的某个 Dubbo 服务,也就是某个接口对应的应用是哪个呢?
对于这个问题,在进行服务导出的过程中,会在 Zookeeper 中存一个映射关系,在服务导出的最后一步,在 ServiceConfig 的 exported() 方法中,会保存这个映射关系:接口名:应用名。这个映射关系存在 Zookeeper 的 /dubbo/mapping 目录下,存了这个信息后,消费者就能根据接口名找到所对应的应用名了。
消费者知道了要使用的 Dubbo 服务在哪个应用,那也就能从注册中心中根据应用名查到应用的所有实例信息( ip + port ),也就是可以发送方法调用请求了,但是在真正发送请求之前,还得知道服务的配置信息,对于消费者而言,它得知道当前要调用的这个 Dubbo 服务支持什么协议、timeout 是多少,那服务的配置信息从哪里获取呢?
之前的服务配置信息是直接从注册中心就可以获取到的,就是服务 URL 后面,但是现在不行了,现在需要从服务提供者的元数据服务获取,前面提到过,在应用启动过程中会进行服务导出和服务引入,然后就会暴露一个应用元数据服务,其实这个应用元数据服务就是一个 Dubbo 服务(Dubbo 框架内置的,自己实现的 ),消费者可以调用这个服务来获取某个应用中所提供的所有 Dubbo 服务以及服务配置信息,这样也就能知道服务的配置信息了。
知道了应用注册的好处,以及相关问题的解决方式,那么来看它到底是如何实现的。
首先,我们可以通过配置 dubbo.application.register-mode 来控制:
不管是什么注册,都需要存数据到注册中心,而 Dubbo3 的源码实现中会根据所配置的注册中心生成两个 URL(不是服务 URL,可以理解为注册中心 URL,用来访问注册中心的):
这两个 URL 只有 schema 不一样,一个是 service-discovery-registry,一个是 registry,而 registry 是 Dubbo3 之前就存在的,也就代表接口级服务注册,而service-discovery-registry 就表示应用级服务注册。
在服务注册相关的源码中,当调用 RegistryProtocol 的 export() 方法处理 registry:// 时,会利用 ZookeeperRegistry 把服务 URL 注册到 Zookeeper 中去,这就是接口级注册。
而类似,当调用 RegistryProtocol 的 export() 方法处理 service-discovery-registry:// 时,会利用 ServiceDiscoveryRegistry 来进行相关逻辑的处理,那是不是就是在这里把应用信息注册到注册中心去呢?并没有这么简单。
所以 ServiceDiscoveryRegistry 在注册一个服务 URL 时,并不会往注册中心存数据,而只是把服务 URL 存到到一个 MetadataInfo 对象中,MetadataInfo 对象中就保存了当前应用中所有的 Dubbo 服务信息:服务名、支持的协议、绑定的端口、timeout 等。
前面提到过,在应用启动的最后,才会进行应用级注册,而应用级注册就是当前的应用实例上相关的信息存入注册中心,包括:
比如:
{"name":"dubbo-springboot-demo-provider","id":"192.168.65.221:20882","address":"192.168.65.221","port":20882,"sslPort":null,"payload":{"@class":"org.apache.dubbo.registry.zookeeper.ZookeeperInstance","id":"192.168.65.221:20882","name":"dubbo-springboot-demo-provider","metadata":{"dubbo.endpoints":"[{\"port\":20882,\"protocol\":\"dubbo\"},{\"port\":50051,\"protocol\":\"tri\"}]","dubbo.metadata-service.url-params":"{\"connections\":\"1\",\"version\":\"1.0.0\",\"dubbo\":\"2.0.2\",\"side\":\"provider\",\"port\":\"20882\",\"protocol\":\"dubbo\"}","dubbo.metadata.revision":"65d5c7b814616ab10d32860b54781686","dubbo.metadata.storage-type":"local"} },"registrationTimeUTC":1654585977352,"serviceType":"DYNAMIC","uriSpec":null
}一个实例上可能支持多个协议以及多个端口,那如何确定实例的 ip 和端口呢?
答案是:获取 MetadataInfo 对象中保存的所有服务 URL,优先取 dubbo 协议对应 ip 和 port,没有 dubbo 协议则所有服务 URL 中的第一个 URL 的 ip 和 port。
另外一个协议一般只会对应一个端口,但是如何就是对应了多个,比如:
dubbo:application:name: dubbo-springboot-demo-providerprotocols:p1:name: dubboport: 20881p2:name: dubboport: 20882p3:name: triport: 50051如果是这样,最终存入 endpoint 中的会保证一个协议只对应一个端口,另外那个将被忽略,最终服务消费者在进行服务引入时将会用到这个 endpoint 信息。
确定好实例信息后之后,就进行最终的应用注册了,就把实例信息存入注册中心的 /services/应用名,目录下:

可以看出 services 节点下存的是应用名,应用名的节点下存的是实例 ip 和实例 port,而 ip 和 port 这个节点中的内容就是实例的一些基本信息。
额外,我们可以配置 dubbo.metadata.storage-type,默认时 local,可以通过配置改为 remote:
dubbo:application:name: dubbo-springboot-demo-providermetadata-type: remote这个配置其实跟应用元数据服务有关系:
在 Dubbo2.7 中就有了元数据中心,它其实就是用来减轻注册中心的压力的,Dubbo 会把服务信息完整的存一份到元数据中心,元数据中心也可以用 Zookeeper来实现,在暴露完元数据服务之后,在注册实例信息到注册中心之前,就会把 MetadataInfo 存入元数据中心,比如:
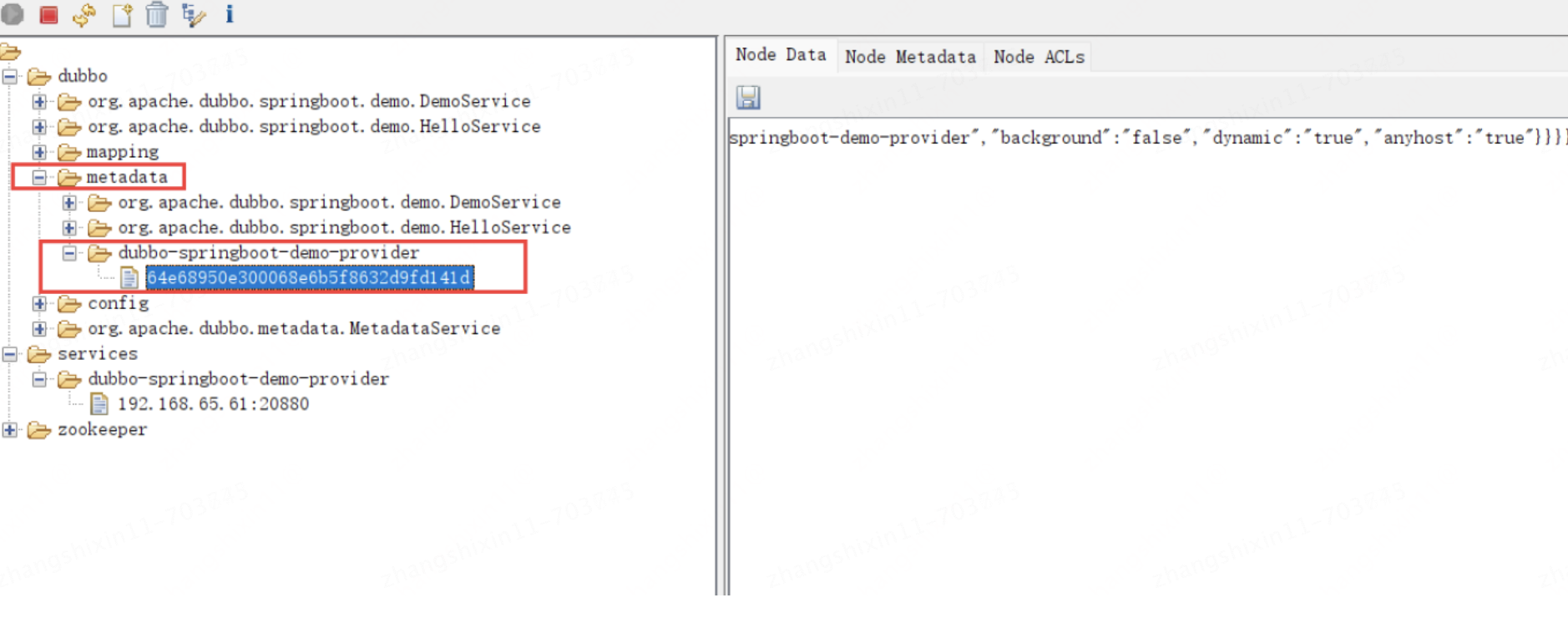
节点内容为:
{"app":"dubbo-springboot-demo-provider","revision":"64e68950e300068e6b5f8632d9fd141d","services":{"org.apache.dubbo.springboot.demo.HelloService:tri":{"name":"org.apache.dubbo.springboot.demo.HelloService","protocol":"tri","path":"org.apache.dubbo.springboot.demo.HelloService","params":{"side":"provider","release":"","methods":"sayHello","deprecated":"false","dubbo":"2.0.2","interface":"org.apache.dubbo.springboot.demo.HelloService","service-name-mapping":"true","generic":"false","metadata-type":"remote","application":"dubbo-springboot-demo-provider","background":"false","dynamic":"true","anyhost":"true"}},"org.apache.dubbo.springboot.demo.DemoService:tri":{"name":"org.apache.dubbo.springboot.demo.DemoService","protocol":"tri","path":"org.apache.dubbo.springboot.demo.DemoService","params":{"side":"provider","release":"","methods":"sayHelloStream,sayHello,sayHelloServerStream","deprecated":"false","dubbo":"2.0.2","interface":"org.apache.dubbo.springboot.demo.DemoService","service-name-mapping":"true","generic":"false","metadata-type":"remote","application":"dubbo-springboot-demo-provider","background":"false","dynamic":"true","anyhost":"true"}}}
}这里面就记录了当前实例上提供了哪些服务以及对应的协议,注意并没有保存对应的端口......,所以后面服务消费者得利用实例信息中的 endpoint,因为endpoint 中记录了协议对应的端口....
其实元数据中心和元数据服务提供的功能是一样的,都可以用来获取某个实例的 MetadataInfo,上面中的 UUID 表示实例编号,只不过元数据中心是集中式的,元数据服务式分散在各个提供者实例中的,如果整个微服务集群压力不大,那么效果差不多,如果微服务集群压力大,那么元数据中心的压力就大,此时单个元数据服务就更适合,所以默认也是采用的元数据服务。
至此,应用级服务注册的原理就分析完了,总结一下:
服务暴露
服务暴露就是根据不同的协议启动不同的 Server,比如:dubbo 和 tri 协议启动的都是 Netty,像 Dubbo2.7 中的 http 协议启动的就是 Tomcat,这块在服务调用的时候再来分析。
服务引入
@DubboReference
private DemoService demoService;需要利用 @DubboReference 注解来引入某一个 Dubbo 服务,应用在启动过程中,进行完服务导出之后,就会进行服务引入,属性的类型就是一个 Dubbo 服务接口,而服务引入最终要做到的就是给这个属性赋值一个接口代理对象。
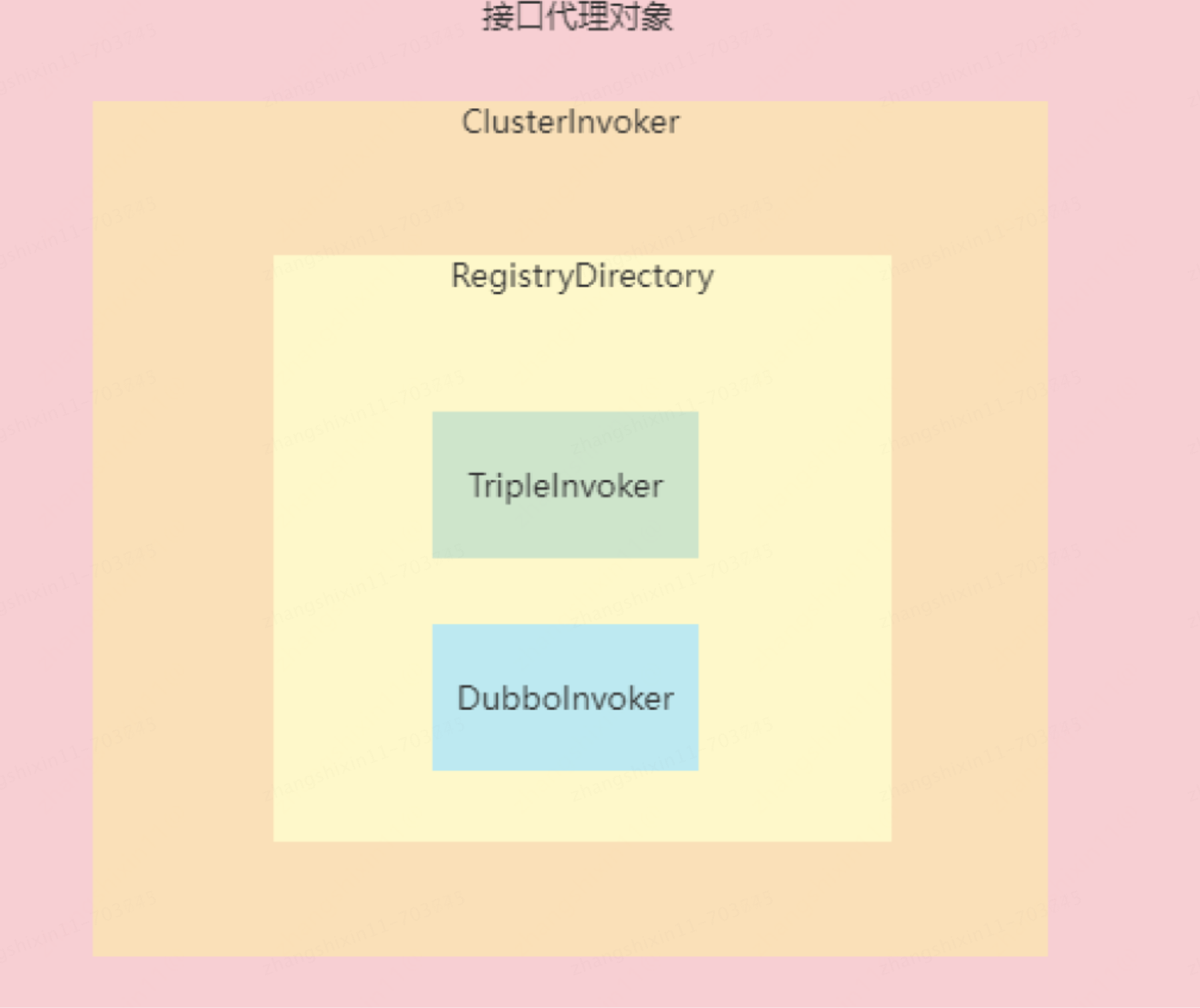
在 Dubbo2.7 中,只有接口级服务注册,服务消费者会利用接口名从注册中心找到该服务接口所有的服务 URL,服务消费者会根据每个服务 URL 的 protocol、ip、port 生成对应的 Invoker 对象,比如生成 TripleInvoker、DubboInvoker 等,调用这些 Invoker 的 invoke() 方法就会发送数据到对应的 ip、port,生成好所有的 Invoker 对象之后,就会把这些 Invoker 对象进行封装并生成一个服务接口的代理对象,代理对象调用某个方法时,会把所调用的方法信息生成一个 Invocation 对象,并最终通过某一个 Invoker 的 invoke() 方法把 Invocation 对象发送出去,所以代理对象中的 Invoker 对象是关键,服务引入最核心的就是要生成这些 Invoker 对象。
Invoker 是非常核心的一个概念,也有非常多种类,比如:
像 TripleInvoker 和 DubboInvoker 对应的就是具体服务提供者,包含了服务提供者的 ip 地址和端口,并且会负责跟对应的 ip 和 port 建立 Socket 连接,后续就可以基于这个 Socket 连接并按协议格式发送 Invocation 对象。
比如现在引入了 DemoService 这个服务,那如果该服务支持:
那么在服务消费端这边,就会生成两个 TripleInvoker 和一个 DubboInvoker,代理对象执行方法时就会进行负载均衡选择其中一个 Invoker 进行调用。
接口级服务引入
在服务导出时,Dubbo3.0 默认情况下即会进行接口级注册,也会进行应用级注册,目的就是为了兼容服务消费者应用,用的还是 Dubbo2.7,用 Dubbo2.7 就只能老老实实的进行接口级服务引入。
接口级服务引入核心就是要找到当前所引入的服务有哪些服务 URL,然后根据每个服务 URL 生成对应的 Invoker,流程为:
应用级服务引入
在 Dubbo 中,应用级服务引入,并不是指引入某个应用,这里和 SpringCloud 是有区别的,在 SpringCloud 中,服务消费者只要从注册中心找到要调用的应用的所有实例地址就可以了,但是在 Dubbo 中找到应用的实例地址还远远不够,因为在 Dubbo 中是直接使用的接口,所以在 Dubbo 中就算是应用级服务引入,最终还是得找到服务接口有哪些服务提供者。
所以,对于服务消费者而言,不管是使用接口级服务引入,还是应用级服务引入,最终的结果应该得是一样的,也就是某个服务接口的提供者 Invoker 是一样的,不可能使用应用级服务引入得到的 Invoker 多一个或少一个,但是!!!,目前会有情况不一致,就是一个协议有多个端口时,比如在服务提供者应用这边支持:
dubbo:application:name: dubbo-springboot-demo-providerprotocols:p1:name: dubboport: 20881p2:name: triport: 20882p3:name: triport: 50051那么在消费端进行服务引入时,比如:引入 DemoService 时,接口级服务引入会生成 3 个 Invoker(2个 TripleInvoker,1个DubboInvoker),而应用级服务引入只会生成 2 个 Invoker(1个TripleInvoker,1个DubboInvoker),原因就是在进行应用级注册时是按照一个协议对应一个port存的。
那既然接口级服务引入和应用级服务引入最终的结果差不多,可能就不理解了,那应用级服务引入有什么好处呢?要知道应用级服务引入和应用级服务注册是对应,服务提供者应用如果只做应用级注册,那么对应的服务消费者就只能进行应用级服务引入,好处就是前面所说的,减轻了注册中心的压力等,那么带来的影响就是服务消费者端寻找服务 URL 的逻辑更复杂了。
只要找到了当前引入服务对应的服务 URL,然后生成对应的 Invoker,并最终生成一个 ClusterInvoker。
在进行应用级服务引入时:
MigrationInvoker 的生成
上面分析了接口级服务引入和应用级服务引入,最终都是得到某个服务对应的服务提供者 Invoker,那最终进行服务调用时,到底该怎么选择呢?
所以在 Dubbo3.0 中,可以配置:
# dubbo.application.service-discovery.migration 仅支持通过 -D 以及 全局配置中心 两种方式进行配置。dubbo.application.service-discovery.migration=APPLICATION_FIRST# 可选值# FORCE_INTERFACE,强制使用接口级服务引入# FORCE_APPLICATION,强制使用应用级服务引入# APPLICATION_FIRST,智能选择是接口级还是应用级,默认就是这个对于前两种强制的方式,没什么特殊,就是上面走上面分析的两个过程,没有额外的逻辑,那对于 APPLICATION_FIRST 就需要有额外的逻辑了,也就是 Dubbo 要判断,当前所引入的这个服务,应该走接口级还是应用级,这该如何判断呢?
事实上,在进行某个服务的服务引入时,会统一利用 InterfaceCompatibleRegistryProtocol 的 refer 来生成一个 MigrationInvoker 对象,在 MigrationInvoker 中有三个属性:
private volatile ClusterInvoker<T> invoker; // 用来记录接口级ClusterInvoker
private volatile ClusterInvoker<T> serviceDiscoveryInvoker; // 用来记录应用级的ClusterInvokerprivate volatile ClusterInvoker<T> currentAvailableInvoker; // 用来记录当前使用的ClusterInvoker,要么是接口级,要么应用级一开始构造出来的 MigrationInvoker 对象中三个属性都为空,接下来会利用 MigrationRuleListener 来处理 MigrationInvoker 对象,也就是给这三个属性赋值。
在 MigrationRuleListener 的构造方法中,会从配置中心读取 DUBBO_SERVICEDISCOVERY_MIGRATION 组下面的"当前应用名+.migration"的配置项,配置项为 yml 格式,对应的对象为 MigrationRule,也就是可以配置具体的迁移规则,比如:某个接口或某个应用的 MigrationStep(FORCE_INTERFACE、APPLICATION_FIRST、FORCE_APPLICATION),还可以配置 threshold,表示一个阈值,比如:配置为 2,表示应用级 Invoker 数量是接口级 Invoker 数量的两倍时才使用应用级 Invoker,不然就使用接口级数量,可以参考:https://cn.dubbo.apache.org/zh/docs/advanced/migration-invoker/
如果没有配置迁移规则,则会看当前应用中是否配置了 migration.step,如果没有,那就从全局配置中心读取 dubbo.application.service-discovery.migration 来获取 MigrationStep,如果也没有配置,那 MigrationStep 默认为 APPLICATION_FIRST
如果没有配置迁移规则,则会看当前应用中是否配置了 migration.threshold,如果没有配,则 threshold 默认为 -1。
在应用中可以这么配置:
dubbo:application:name: dubbo-springboot-demo-consumerparameters:migration.step: FORCE_APPLICATIONmigration.threshold: 2确定了 step 和 threshold 之后,就要真正开始给 MigrationInvoker 对象中的三个属性赋值了,先根据 step 调用不同的方法
switch (step) {case APPLICATION_FIRST:// 先进行接口级服务引入得到对应的ClusterInvoker,并赋值给invoker属性// 再进行应用级服务引入得到对应的ClusterInvoker,并赋值给serviceDiscoveryInvoker属性
// 再根据两者的数量判断到底用哪个,并且把确定的ClusterInvoker赋值给currentAvailableInvoker属性migrationInvoker.migrateToApplicationFirstInvoker(newRule);break;case FORCE_APPLICATION:
// 只进行应用级服务引入得到对应的ClusterInvoker,并赋值给serviceDiscoveryInvoker和currentAvailableInvoker属性success = migrationInvoker.migrateToForceApplicationInvoker(newRule);break;case FORCE_INTERFACE:default:
// 只进行接口级服务引入得到对应的ClusterInvoker,并赋值给invoker和currentAvailableInvoker属性success = migrationInvoker.migrateToForceInterfaceInvoker(newRule);}这里只需要分析当 step 为 APPLICATION_FIRST 时,是如何确定最终要使用的 ClusterInvoker 的。
得到了接口级 ClusterInvoker 和应用级 ClusterInvoker 之后,就会利用 DefaultMigrationAddressComparator 来进行判断:
threshold 默认为 0,那就表示在既有应用级 Invoker 又有接口级 Invoker 的情况下,就一定会用应用级 Invoker,两个正数相除,结果肯定为正数,当然你自己可以控制 threshold,如果既有既有应用级 Invoker 又有接口级 Invoker 的情况下,你想在应用级 Invoker 的个数大于接口级 Invoker 的个数时采用应用级Invoker,那就可以把 threshold 设置为 1,表示个数相等,或者个数相除之后的结果大于 1 时用应用级 Invoker,否者用接口级 Invoker
这样 MigrationInvoker 对象中的三个数据就能确定好值了,和在最终的接口代理对象执行某个方法时,就会调用 MigrationInvoker 对象的 invoke,在这个invoke 方法中会直接执行 currentAvailableInvoker 对应的 invoker 的 invoker 方法,从而进入到了接口级 ClusterInvoker 或应用级 ClusterInvoker 中,从而进行负载均衡,选择出具体的 DubboInvoer 或 TripleInvoker,完成真正的服务调用。
服务调用底层原理
在 Dubbo2.7 中,默认的是 Dubbo 协议,因为 Dubbo 协议相比较于 Http1.1 而言,Dubbo 协议性能上是要更好的。
但是 Dubbo 协议自己的缺点就是不通用,假如现在通过 Dubbo 协议提供了一个服务,那如果想要调用该服务就必须要求服务消费者也要支持 Dubbo 协议,比如想通过浏览器直接调用 Dubbo 服务是不行的,想通过 Nginx 调 Dubbo 服务也是不行得。
而随着企业的发展,往往可能会出现公司内部使用多种技术栈,可能这个部门使用 Dubbo,另外一个部门使用 Spring Cloud,另外一个部门使用 gRPC,那此时部门之间要想相互调用服务就比较复杂了,所以需要一个通用的、性能也好的协议,这就是 Triple 协议。
Triple 协议是基于 Http2 协议的,也就是在使用 Triple 协议发送数据时,会按 HTTP2 协议的格式来发送数据,而 HTTP2 协议相比较于 HTTP1 协议而言,HTTP2是 HTTP1 的升级版,完全兼容 HTTP1,而且 HTTP2 协议从设计层面就解决了 HTTP1 性能低的问题。
另外,Google 公司开发的 gRPC,也基于的 HTTP2,目前 gRPC 是云原生事实上协议标准,包括 k8s/etcd 等都支持 gRPC 协议。
所以 Dubbo3.0 为了能够更方便的和 k8s 进行通信,在实现 Triple 的时候也兼容了 gRPC,也就是可以用 gPRC 的客户端调用 Dubbo3.0 所提供的 triple 服务,也可以用 triple 服务调用 gRPC 的服务。
Triple 的底层原理分析
就是因为 HTTP2 中的数据帧机制,Triple 协议才能支持 UNARY、SERVER_STREAM、BI_STREAM 三种模式。
Triple 请求调用和响应处理
创建一个 Stream 的前提是先得有一个 Socket 连接,所以我们得先知道 Socket 连接是在哪创建的。
在服务提供者进行服务导出时,会按照协议以及对应的端口启动 Server,比如:Triple 协议就会启动 Netty 并绑定指定的端口,等待 Socket 连接,在进行服务消费者进行服务引入的过程中,会生成 TripleInvoker 对象,在构造 TripleInvoker 对象的构造方法中,会利用 ConnectionManager 创建一个 Connection 对象,而Connection 对象中包含了一个 Bootstrap 对象(Netty 中用来建立 Socket 连接的),不过以上都只是创建对象,并不会真正和服务去建立 Socket 连接,所以在生成 TripleInvoker 对象过程中不会真正去创建 Socket 连接,那什么时候创建的呢?
当我们在服务消费端执行以下代码时:demoService.sayHello("habit")
demoService 是一个代理对象,在执行方法的过程中,最终会调用 TripleInvoker 的 doInvoke() 方法,在 doInvoke() 方法中,会利用 Connection 对象来判断Socket 连接是否可用,如果不可用并且没有初始化,那就会创建 Socket 连接。
一个 Connection 对象就表示一个 Socket 连接,在 TripleInvoker 对象中也只有一个 Connection 对象,也就是一个 TripleInvoker 对象只对应一个 Socket 连接,这个和 DubboInvoker 不太一样,一个 DubboInvoker 中可以有多个 ExchangeClient,每个 ExchangeClient 都会与服务端创建一个 Socket 连接,所以一个DubboInvoker 可以对应多个 Socket 连接,当然多个 Socket 连接的目的就是提高并发,不过在 TripleInvoker 对象中就不需要这么来设计了,因为可以 Stream机制来提高并发。
以上,我们知道了,当我们利用服务接口的代理对象执行方法时就会创建一个 Socket 连接,就算这个代理对象再次执行方法时也不会再次创建 Socket 连接了,值得注意的是,有可能两个服务接口对应的是一个 Socket 连接,举个例子。
比如服务提供者应用 A,提供了 DemoService 和 HelloService 两个服务,服务消费者应用 B 引入了这两个服务,那么在服务消费者这端,这个两个接口对应的代理对象对应的 TripleInvoker 是不同的两个,但是这两个 TripleInvoker 会公用一个 Socket 连接,因为 ConnectionManager 在创建 Connection 对象时会根据服务 URL 的 address 进行缓存,后续这两个代理对象在执行方法时使用的就是同一个 Socket 连接,但是是不同的 Stream。
Socket 连接创建好之后,就需要发送 Invocation 对象给服务提供者了,因为是基于的 HTTP2,所以要先创建一个 Stream,然后再通过 Stream 来发送数据。
TripleInvoker 中用的是 Netty,所以最终会利用 Netty 来创建 Stream,对应的对象为 Http2StreamChannel,消费端的 TripleInvoker 最终会利用Http2StreamChannel 来发送和接收数据帧,数据帧对应的对象为 Http2Frame,它又分为 Http2DataFrame、Http2HeadersFrame 等具体类型。
正常情况下,会每生成一个数据帧就会通过 Http2StreamChannel 发送出去,但是在 Triple 中有一个小小的优化,会有一个批量发送的思想,当要发送一个数据帧时,会先把数据帧放入一个 WriteQueue 中,然后会从线程池中拿到一个线程调用 WriteQueue 的 flush 方法,该方法的实现为:
private void flush() {try {QueuedCommand cmd;int i = 0;boolean flushedOnce = false;// 只要队列中有元素就取出来,没有则退出whilewhile ((cmd = queue.poll()) != null) {// 把数据帧添加到Http2StreamChannel中,添加并不会立马发送,调用了flush才发送cmd.run(channel);i++;// DEQUE_CHUNK_SIZE=128// 连续从队列中取到了128个数据帧就flush一次if (i == DEQUE_CHUNK_SIZE) {i = 0;channel.flush();flushedOnce = true;}}// i != 0 表示从队列中取到了数据但是没满128个// 如果i=0,flushedOnce=false也flush一次if (i != 0 || !flushedOnce) {channel.