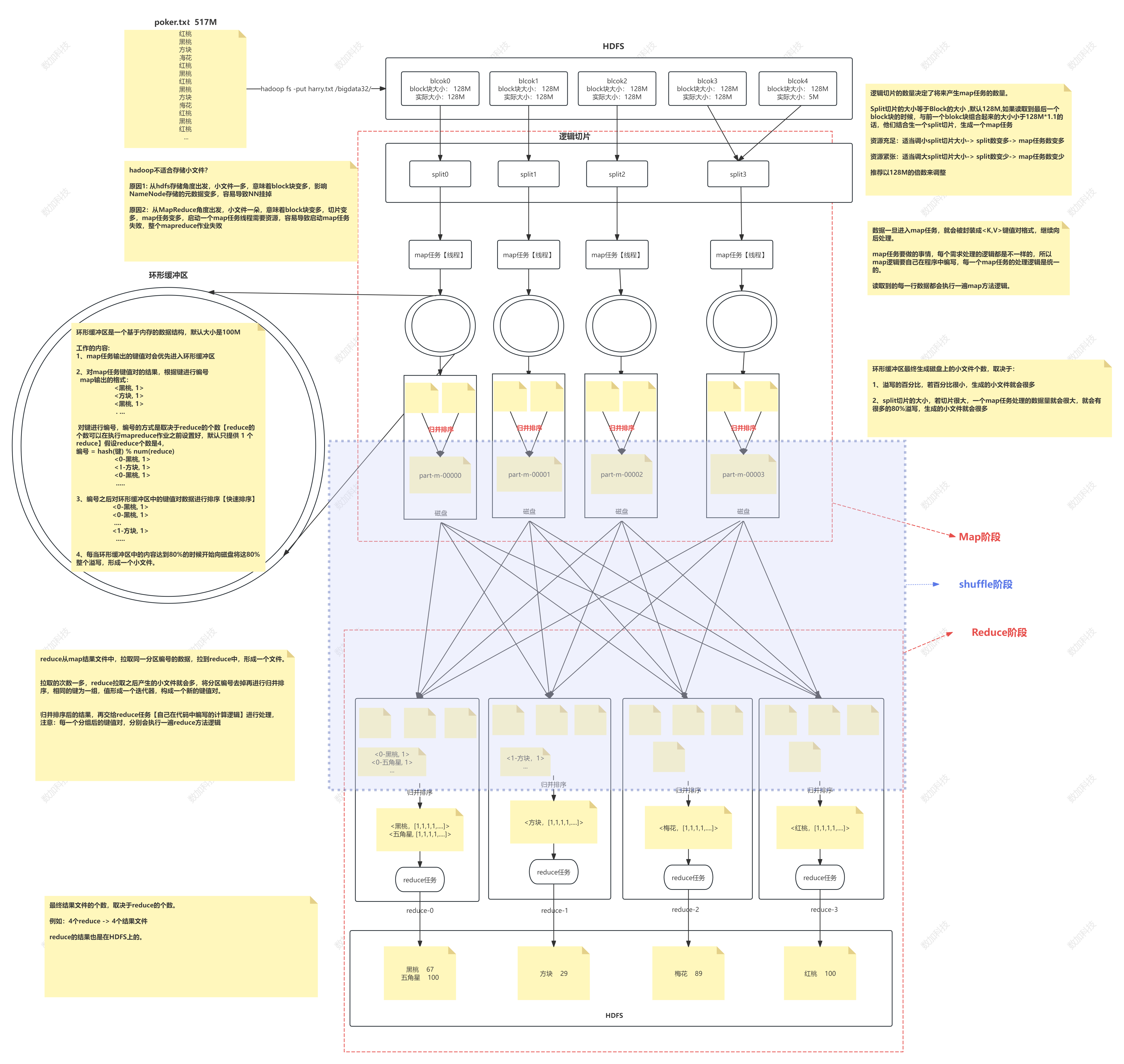
* 客户端通过hadoop fs -put/bigdata命令 将元数据切分成块存放在HDFS上,且每一个块我们给大小128M* 之后我们将每一个block块通过逻辑切片,切成一个个split()切片,一般,我们的默认切片大小跟block块保持一致,如果我们读到最后一个block块,与前一个block块组合起来的大小小于140M,将最后两个split()切片块结合成一个新的split()切片,并且我们的逻辑切片的数量决定了将来产生map任务的数量,生成了一个个map任务
随着我们资源不同,可以适当的调整split切片大小1.资源充足: 适当的调小split切片的大小-> split数量就会变多->map任务也就变多了
2.资源紧张: 适当的增大split切片的大小 -> split数量变少-> map任务 也会变少* 当我们的数据一旦进入了map任务中,就会被封装成<K,V>键值对格式,再继续向后处理。
map任务的工作内容:将每一个map内容的处理逻辑进行统一,且我们读取每一行数据都会执行一遍map方法逻辑* map任务键值对的结果会优先的进入环形缓冲区 根据建进行编号map输出格式,之后我们要对建进行编号,编号的方式取决于reduce的个数(reduce的个数我们要在mapreduce之前设置好,默认只提供一个reduce)
编号完成之后要对环形缓冲区的键值对数据进行排序(快速排序),将我们相同的编号放在一起
当环形缓冲区的内容达到80%的时候向磁盘将这80%进行溢写,形成一个小文件环形缓冲区小文件的个数,取决于:
1.溢写的百分比,若百分比很小,那么存入磁盘的文件就会很多
2。split切片的大小,若切片很大,那么一个map任务处理的数据量就会很大,那么就会有很多的80%溢写,生成很多的小文件*然后我们将多个同缓冲区溢写形成的文件,进行归并排序,形成一个新的文件 以上是map阶段
* 我们将map结果文件的同一分区编号的数据,拉取到reduce中,形成一个文件
我们拉取的次数越多产生的小文件也就越多,将分区编号去掉进行归并排序,相同的建为一组值形成了一个迭代器,形成了一个新的键值对
将上述的结果,再交给reduce任务进行处理(注意我们每一个分组后的键值对都会执行一遍reduce方法逻辑)
* 最后我们的reduce 的结果也是在hdfs中