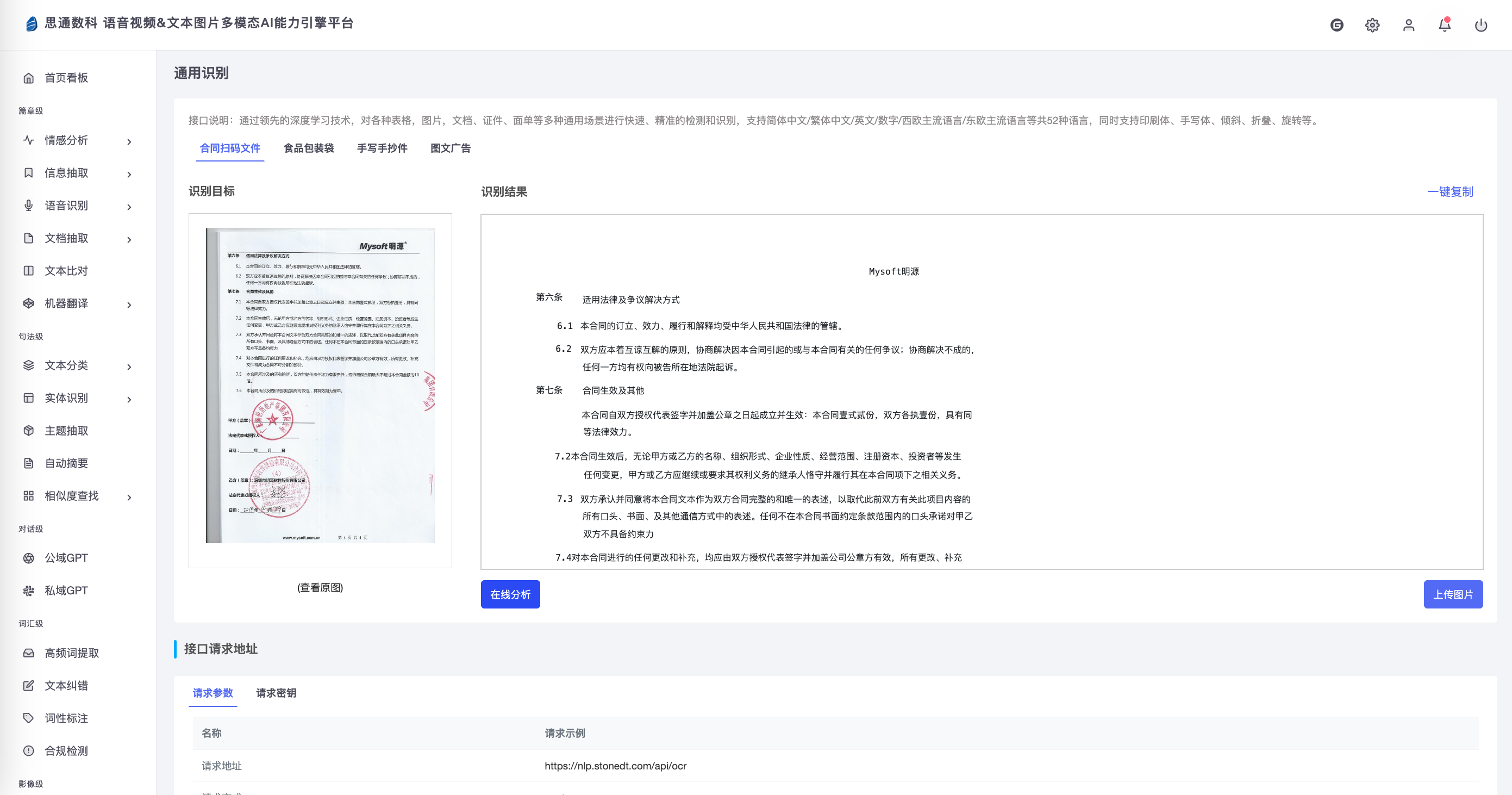
在传统档案馆中,纸质文件的处理和管理是一个重要且繁琐的环节,特别是面对庞大的历史资料库。思通数科的AI能力平台提供了一种高效的数字化解决方案,利用OCR技术将纸质档案中的信息自动提取并转化为数字文本,具体过程包括以下几个步骤:
1.扫描与图像预处理
首先,系统将纸质档案文件进行扫描,将其转换为高清图像。此步骤不仅要保证图像的清晰度,还要对图像进行预处理,例如校正倾斜、去除噪声、调整对比度等。这些预处理操作可以减少OCR识别中的干扰因素,特别是在原件有褶皱或页面模糊时,对图像预处理可以提升识别效果。
2.自动边界检测与切割
档案文件有时包含多个部分,如表格、文字和图片。AI平台利用边界检测算法来自动识别文档的边缘,从而准确地截取文件中的文字区域,并过滤掉空白边缘或杂物(例如钉孔、污渍等)。边界检测功能在对单张大幅度的档案文件进行识别时,能自动检测出各个需要识别的区域,有效避免误识别和多余信息干扰。
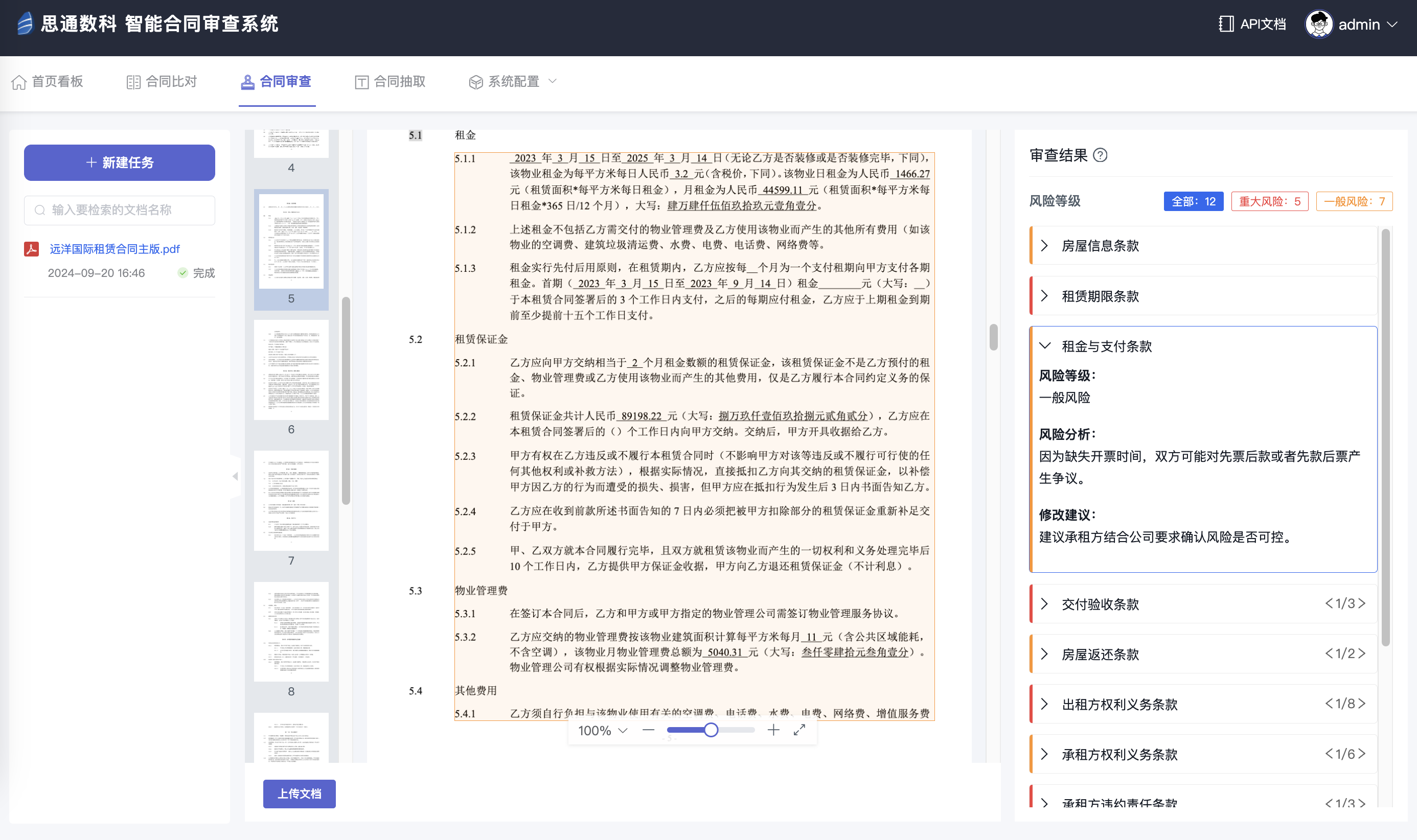
3.文字与图片分离抽取
档案文件中通常包括文字和图片(例如签名、图示等),而OCR识别更适用于文字。AI平台可以先对图像进行分析,利用图像识别技术区分出文字部分和非文字部分,自动屏蔽图片区域或标签区域,以便专注于文字识别。通过这种方式,可以避免图像干扰,提升文字提取的精度。
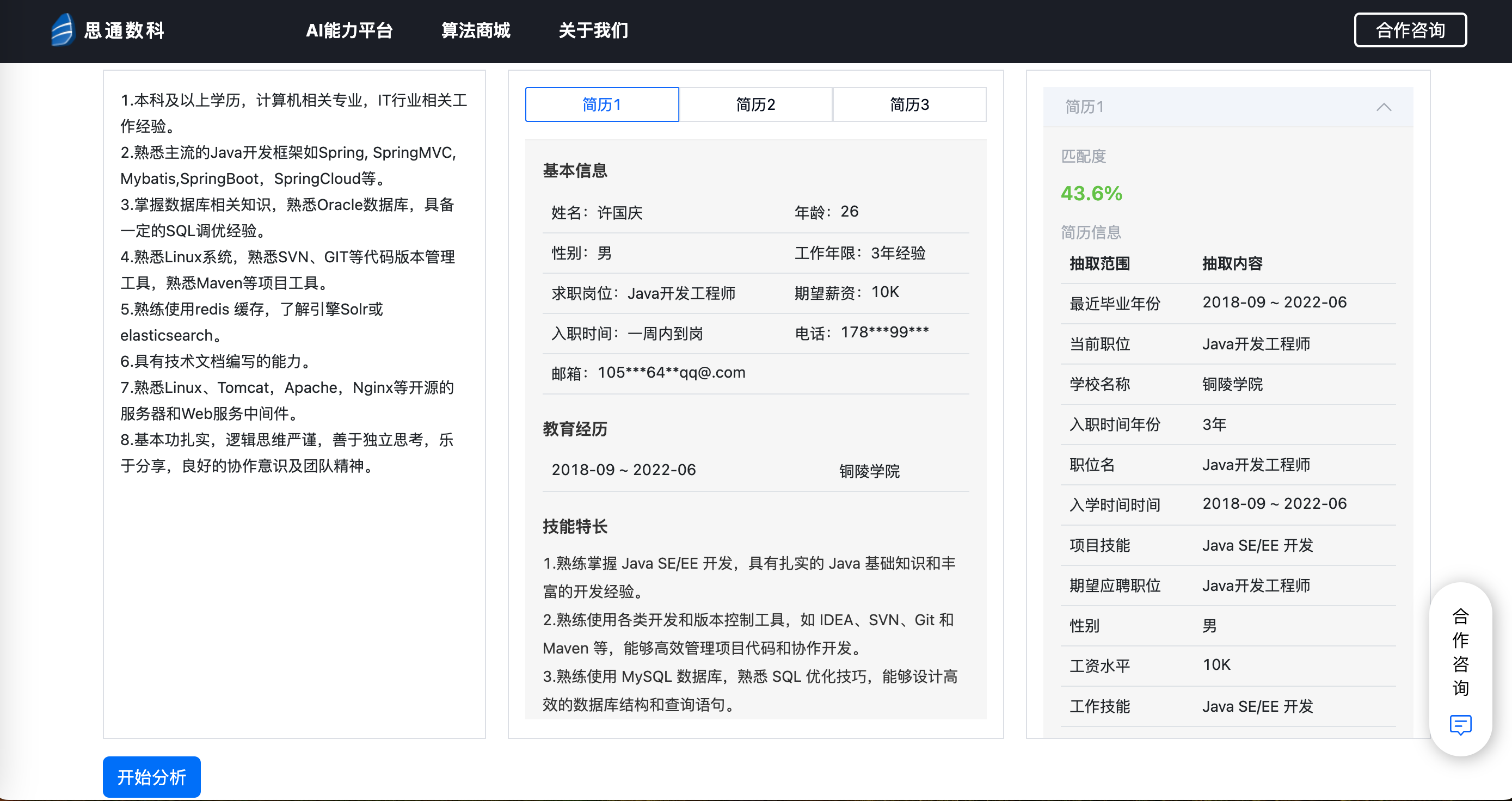
4.档案识别与文本提取
在完成预处理后,系统会对图像中的文字部分进行OCR识别,提取出文档内容。OCR模型可以支持多种字体识别,包括手写体、打印体以及一些历史文档中的复古字体。此外,平台的OCR识别支持大批量自动处理,可以设定任务流水线,使得大量文档能在短时间内处理完毕。识别后的文本可以进一步结构化存储,便于后续的查找和管理。
5.识别结果自动保存
识别完成后,系统会将结果转化为数字文档,并存入档案管理系统中。这些数字化的文本不仅可以生成PDF或Word文档,还可以直接保存为结构化数据库格式,便于后续的检索和分析。同时,系统可以为每个数字化文件自动生成日期、类型等元数据信息,便于后续的查询和档案整理。
思通数科的AI能力平台,使档案馆可以大幅提高纸质档案数字化的效率和质量,实现自动化和高精度的信息转化,特别是对于大批量的档案文件,也能够实现全天候无人值守的自动处理,真正将纸质信息有效转化为可检索的数字资产。
更多产品体验及相关信息,请访问思通数科官网。
体验地址:https://nlp.stonedt.com
或通过网络搜索“思通数科AI多模态能力平台”
更多咨询: