本文分享自《华为云DTSE》第五期开源专刊,作者:贺张俭 华为云IoT技术专家
随着物联网平台业务的快速增长,基于传统消息中间件构筑面临着处理亿级设备连接和海量数据的挑战。本文分析了消息中间件的架构发展趋势以及核心优势,还探讨了Apache Pulsar在华为云IoT平台上的实践应用,展示了华为云IoT是如何在其之上构筑支持亿级设备和处理大规模数据流方面的高安全、高可靠、高性能。
物联网平台推送业务介绍

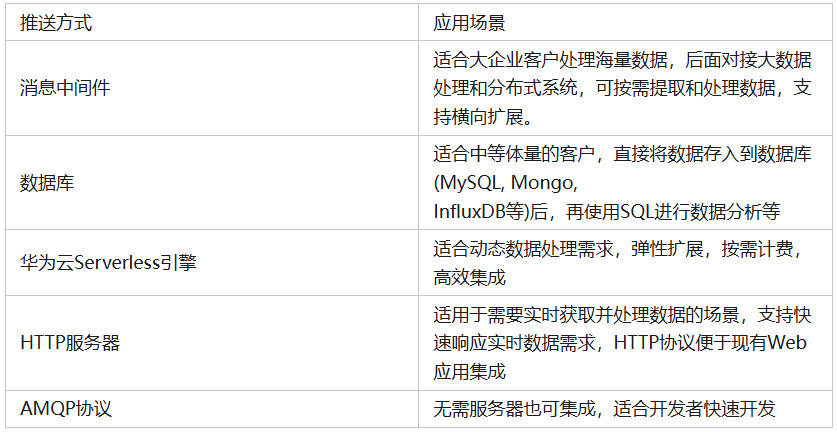
华为云IoTDA服务是华为云物联网的一个核心底座服务,提供海量设备连接上云、设备和云端双向消息通信、数据流转、设备联动规则等能力,上图为IoTDA架构图。数据流转服务是华为云IoTDA的一个核心功能,为用户提供高效、灵活的数据处理能力。当物联网平台中的设备满足预设规则条件时,平台会自动触发相应的操作,帮助用户实现关键业务目标,如将数据对接至华为云其他服务,实现全栈的数据存储、计算和分析。针对各式各样的用户、开发者,华为云IoTDA规划了多种接受数据方式。
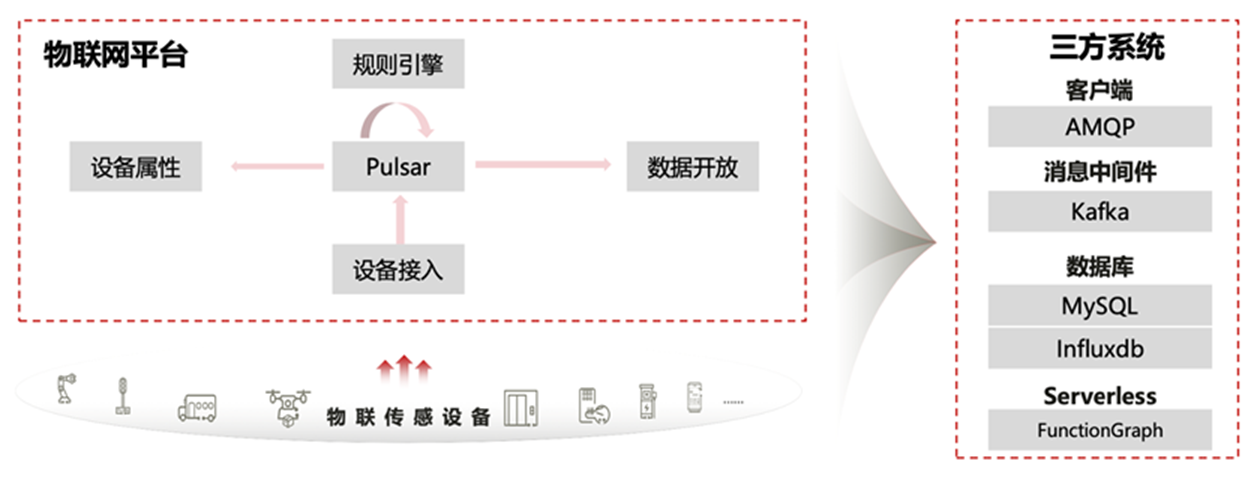
物联网平台推送业务扩展性遇到问题
谈到消息中间件,就不得不提到Apache Kafka,Apache Kafka在2011年开源,在过往的一段时间内几乎成为了消息中间件的代名词、消息中间件接口上的事实标准。同时Confluent公司也积极地在做Kafka的商业化服务,近年来也完成了去ZooKeeper、级联存储等重大特性。物联网平台最初也使用Apache Kafka作为其消息组件。
Kafka作为早期的领跑者,凭借简洁的概念,优秀的性能,积累了大量的用户和丰富的场景应用。但在应用上云、业务量不断上涨、SaaS应用多租化的趋势下,暴露出了一些问题。
-
消息中间件费用高:出于可靠性的要求,常见的高可用方案都会将数据至少分布在两个AZ上,其费用包括云上磁盘存储费用,以及部分公有云跨可用区流量费用,值得一提的是,像华为云等一些云厂商不收取跨可用区流量费用。
-
扩容时间长:云上的应用更加弹性,往往需要在业务高峰时进行扩容,Kafka的topic数据持久化在本地磁盘,一旦进行扩容,需要进行数据的迁移,这个时间可能会达到小时级甚至天级别。
-
Topic量级限制:随着SaaS应用的发展,租户间的消息队列隔离变得更加重要。Kafka的存储模型,一个partition对应一个磁盘文件,且依赖PageCache。在Topic量级超过5000之后,性能表现结果较差。
-
长尾时延高:Kafka的消息写入需要等待Leader落盘成功才能写入,相比更高SLA保障或Quorum模式的系统没有优势。
-
消费模型单一:消息中间件需要支持队列(共享)的消费模式,从而在较多消费者连接的时候降低资源的大量浪费。而像AMQP这种业务则必须这种消费模式,否则需要在业务层自己构筑相应的能力。
消息中间件架构发展趋势与华为云的实践
面对这些问题,市场上的挑战者们如AutoMQ、Pulsar、WarpStream等提出了各自的解决方案,从目前公开的资料来看:
-
降低消息中间件费用:为降低持久化费用,可以广泛使用对象存储(使用级联存储或直接存储或仅在WAL中使用磁盘)。而对于跨可用区流量费用,除非直接存储到高可用的对象存储,否则流量费在所难免。
-
缩短扩容时间:扩容时间长由于主从磁盘的复制模式,扩容出的节点需要从旧的磁盘处复制内容,这时候写入还在持续,这一过程可能需要较长时间完成。可以通过解决存储的扩容问题(使用对象存储或Quorum的模式),或尽量降低需要复制的内容(级联存储到对象存储)。
-
扩大Topic量级:从大数据批量处理的视角来看,问题并不显著。但在SaaS应用或物联网解决方案中,有着很强的单通道诉求,租户与租户间,设备与设备间的消息队列隔离变得更加重要。通常通过存储模型的优化,避免单个Topic对应单个文件句柄来解决。
-
降低长尾时延:可以通过WAL或Quorum两种技术手段来降低时延。
-
消费模型多样化:此特性并不是一个通用问题,问题场景出在较多消费者能力较差需要共享消费单个partition时,(企业)内网大数据处理中很少出现这个场景。截止目前,只有Pulsar做了队列模型消费的支持,不过Kafka也提出了KIP-932来支持队列的消费模式,预期在接下来能补齐队列消费模式。
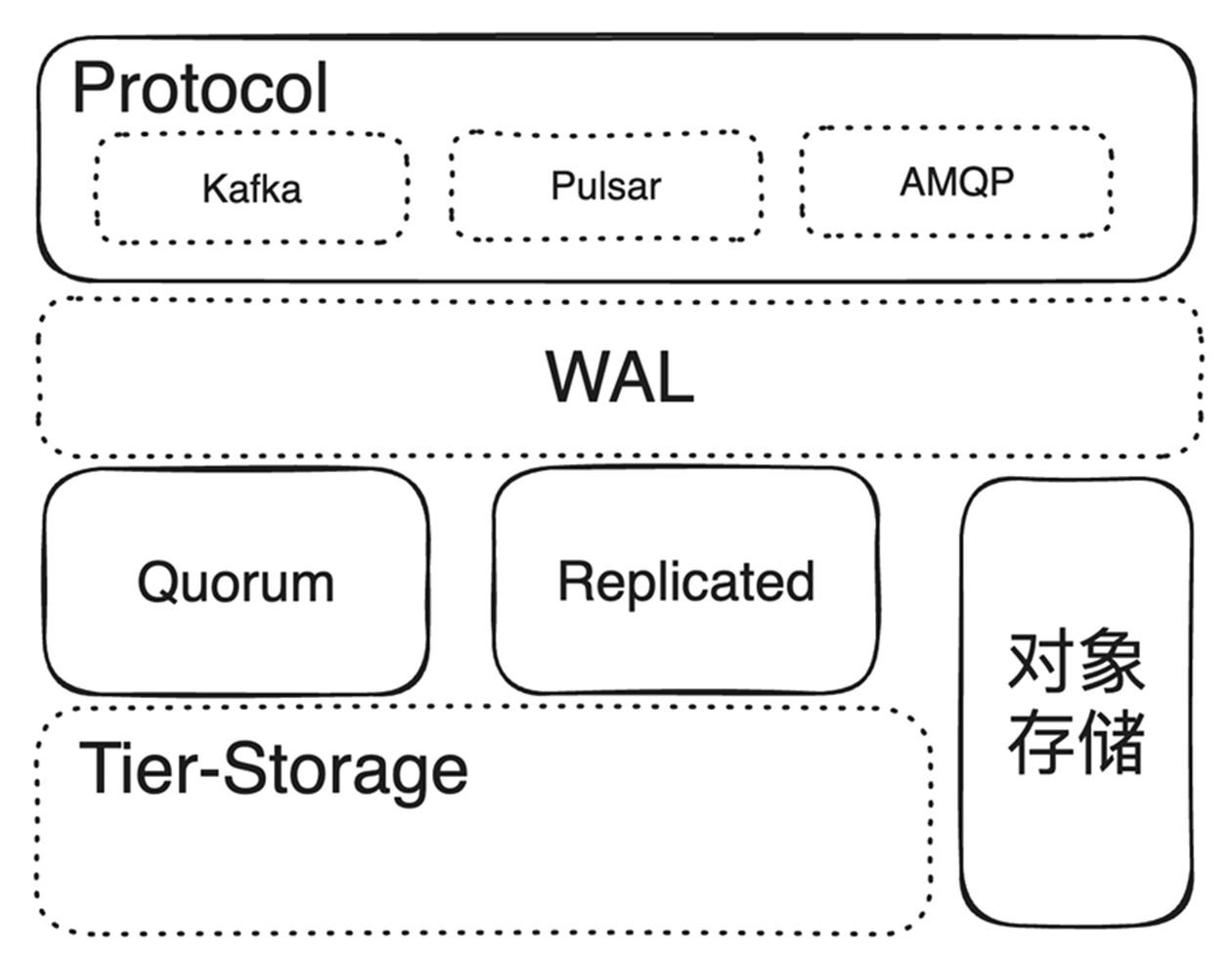
从大的实现策略上来看,关键的技术决策分歧点如下图(图中虚线为可选模块)
-
协议层,支持一种或多种协议,支持Kafka协议还是支持Pulsar协议?
-
是否存在WAL,拥有WAL会表现出更低的延迟,但是由于WAL本身需要高可用,无法避免一份跨AZ的流量费用
-
存储层,是否直接使用对象存储,或者是否使用分级存储,将冷数据offload到对象存储
存储层,如果使用磁盘存储,使用主从模式还是Quorum模式,Quorum会有更平稳的延时(如P99),但网络拓扑可能会变得复杂(为了性能,通常客户端会直接连接多个broker)
根据上面的技术分歧点,业内的AutoMQ、Kafka、Pulsar、WarpStream的技术路线可以描述为:
-
AutoMQ:支持Kafka协议,使用WAL,持久化存储在对象存储上的消息中间件。
-
Kafka:支持Kafka协议(Kafka当然支持Kafka协议),无WAL,持久化存储在主从模式的磁盘上,同时支持级联到对象存储的消息中间件。
-
Pulsar:支持Kafka、Pulsar、AMQP等多种协议,使用WAL,持久化存储在Quorum的磁盘上,同时支持级联到对象存储的消息中间件。
-
WarpStream:支持Kafka协议,无WAL,持久化存储在对象存储的消息中间件。
总得来说,针对消息中间件的关键优化点,业内达成了一定程度上的共识,协议也一定程度上形成了事实上的标准(Kafka协议),接下来可能细节设计、工程能力会变得更加重要。
Apache Pulsar在Kafka的挑战者中诞生较早,且相对全面,较好地解决了扩容时间长、Topic量级限制、长尾时延高、消费模型单一的问题。华为云IoTDA最终选型基于Apache Pulsar构筑核心消息中间件。
Apache Pulsar官方描述:Apache Pulsar是Apache软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息、存储、轻量化函数式计算为一体,采用计算与存储分离架构,支持多租户、持久化、多机房跨区域数据复制,具有强一致性、高吞吐、低延时及高扩展性等流数据存储特性,被看作是云原生时代实时消息流传输、存储和计算的理想平台。
华为云IoT不仅仅深度使用了Apache Pulsar,同时还积极参与Pulsar社区的发展,致力于提升Pulsar的安全性、可靠性和功能性,除了已经合并的300+PR贡献(含下游、周边项目)之外,还开发了多项增强功能,计划在未来合并到社区版本中。
-
调试能力增强:Pulsar自带的调试能力只能通过调整broker的日志级别来观察debug信息,海量消息场景下,难以在生产环境开启。IoT产品部将Pulsar与配置中心对接,引入新的配置项,仅为指定的主题打印详细的调试信息,从而快速识别和解决消息从生产者到服务端的延迟问题。这一特性上线后,帮助排查解决数十个问题。
-
性能相关增强:将SkyWalking调用链能力集成到Pulsar和BookKeeper中,提供细节化的性能分析。有助于用户了解系统的性能情况,识别长尾请求,进行做出性能优化
-
可靠性增强:与社区更倾向于在问题发生后解决问题相比,IoT产品部采取的策略是增强系统的自愈能力。例如,当检测到磁盘数据不一致时可自动重启以修复数据,生产者失败率过高时可重建生产者,以及当Broker检测到消费者异常(如持续生产、有接受队列长度但无消费)时自动断开消费者链接。尽管这些措施可能导致丢失一些故障定位信息,但它们弥补了社区在自动恢复方面的不足,确保系统在异常情况下保持稳定运行。
华为云IoT&丰图科技案例分析
丰图科技的前身是顺丰科技的地理信息研发中心,是顺丰集团的子公司。致力于打造数字化和AI系统能读懂的实时精准地图,为企业和个人提供位置智能决策服务。
客户痛点:
-
消息并发数20倍增长
-
车辆高频行驶
丰图科技拥有3万+货运车辆摄像头负责地图拍摄,接入的数据流转,最高可达15万TPS。华为云IoT相比企业自建平台省钱省心,它拥有高可用、高可靠、高性价比的平台实例,并支持按需扩容。
华为云IoT凭借高可用、高可靠的消息总线,稳定支持15万TPS的数据流转,快速将上云的数据流转给EI、大数据等高阶服务,帮助客户快速挖掘数据价值。助力丰图科技通过货运车辆的运行轨迹,获取实时街景,完成动态地图的绘制,基于传感数据,打造新商业模式。
总结
华为云IoT团队积极参与Apache Pulsar及其下游项目的社区发展,确保了Pulsar在华为云物联网平台上的稳定运行超过五年,从而增强了平台的核心竞争力。此外,该团队也对Apache BookKeeper、ApolloConfig、openGemini等其他开源项目做出了显著贡献。
华为云IoT产品部将继续致力于积极参与和支持开源社区,不仅通过技术分享和问题解决,还积极参与开源项目的治理、新功能的开发及社区的建设等多个方面,有效推动技术创新,并实现IoT业务与技术的协同发展。
凭借与开源社区的紧密合作,华为云IoT平台在高并发环境下的高性能表现得到了提升,为企业提供了可靠、高效的服务。IoT产品团队将继续为物联网的高效运转和数字化转型提供更全面的支持。
华为开发者空间,汇聚鸿蒙、昇腾、鲲鹏、GaussDB、欧拉等各项根技术的开发资源及工具,致力于为每位开发者提供一台云主机、一套开发工具及云上存储空间,让开发者基于华为根生态创新。点击链接,免费领取您的专属云主机
点击关注,第一时间了解华为云新鲜技术~