# 标题
<h1>一级标题</h1>
<h2>二级标题</h2>
<h3>三级标题</h3>
# 实际在渲染出的网页中标题的字号还与CSS定义有关,所以不一定标题级数越高,字号越大# 文本
<p>文本</p>
<p><b>加粗文本</b></p>
<p><i>斜体文本</i></p>
<p><u>下划线文本</u></p>
<p>换行<br>文本</p># 图片
<img src="图片路径"width="图片宽度"># 链接
<a href="超链接"[target="_self" | target="_blank"]>描述信息</a>
target 可选参数,"_self"在当前页面跳转,"_blank"在新窗口跳转
<a href="https://space.bilibili.com/3493122610825915"target="_self">我的主页</a># 容器
<div style="background-color:red;"><a href="https://baidu.com">链接1</a><a href="https://baidu.com">链接2</a>
</div>
# 便于对容器中的所有元素统一添加样式
<span style="background-color:red;"><a href="https://baidu.com">链接1</a><a href="https://baidu.com">链接2</a>
</span>
# span与div的区别:span为内联元素,一行可以有不止一项span容器,而div容器一行只能有一项# 列表
# 有序列表
<ol><li>语文</li> # 1.语文<li>数学</li> # 2.数学<li>英语</li> # 3.英语
</ol>
# 无序列表
<ul><li>语文</li> # ·语文<li>数学</li> # ·数学<li>英语</li> # ·英语
</ul># 表格
<table [border="1"]><thead><tr><td>表头1</td><td>表头2</td></tr></thead><tbody><tr><td>11</td><td>12</td></tr><tr><td>21</td><td>22</td></tr></tbody>
</table>
border 即添加表格边框,参数"1"指定边框大小
网页解析:
Regular Expression:
正则优点:速度快,效率高,准确性高
正则缺点:新手上手难度高
元字符:
| 元字符 |
作用 |
| . |
匹配除换行符以外的任意字符 |
| \w |
匹配字母或数字或下划线 |
| \s |
匹配任意的空白符 |
| \d |
匹配数字 |
| \n |
匹配单个换行符 |
| \t |
匹配单个制表符 |
| ^ |
匹配字符串的开始 |
| $ |
匹配字符串的结尾 |
| \W |
匹配非字母或数字或下划线 |
| \D |
匹配非数字 |
| \S |
匹配非空白符 |
| a|b |
匹配字符a或字符b |
| ( ) |
匹配括号内的表达式,也表示元组 |
| [ ] |
匹配字符组中的字符 |
| [^ ] |
匹配除字符组中字符的所有字符 |
量词:
| 量词 |
作用 |
| * |
重复零次或更多次 |
| + |
重复单次或更多次 |
| ? |
重复零次或单次 |
|
重复n次 |
|
重复n次或更多次 |
|
重复n到m次 |
🌟量词用于控制前面的元字符出现的次数
正则表达式:
贪婪匹配:.*
惰性匹配(回溯算法):.*?
| 功能 |
正则表达式 |
| 匹配中文字符 |
[\u4e00-\u9fa5] |
| 匹配双字节字符(包括汉字) |
[^\x00-\xff] |
| 匹配空白行 |
\n\s*\r |
| 匹配Email地址 |
[\w!#$%&'*+/=?^_`{ |
| 匹配网址URL |
[a-zA-z]+://[^\s]* |
| 匹配国内电话号码 |
\d{3}-\d |
| 匹配中国邮政编码 |
[1-9]\d{5}(?!\d) |
| 匹配18位身份证号 |
^(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9] |
| 匹配(年-月-日)格式日期 |
([0-9]{3}[1-9] |
Re解析:
import re
# findall ———— 匹配字符串中所有的符合正则表达式的内容
lst = re.findall(r"\d+","电话号:10086,座机:10010")
print(lst)
lst 数据类型:列表 ["10086","10010"]# finditer ———— 匹配字符串中所有的符合正则表达式的内容(返回迭代器)
it = re.finditer(r"\d+","电话号:10086,座机:10010")
for i in it:print(i.group()) # group函数将迭代器中的有效内容输出# search ———— 匹配首个符合正则表达式的内容(match对象,获取数据使用·group()函数)
s = re.search(r"\d+","电话号:10086,座机:10010")
print(s.group())# match ———— (从头开始)匹配字符串中符合正则表达式的内容
s = re.match(r"\d+","10086,座机:10010")
print(s.group())# 预加载正则表达式
obj = re.compile(r"\d+") # 封装自定义正则表达式
ret = obj.finditer("电话号:10086,座机:10010")
for it in ret:print(it.group())# 示例
s = """"
<div class='actor'><span id='1'>成龙</span></div>
<div class='director'><span id='2'>张艺谋</span></div>
<div class='writer'><span id='3'>韩寒</span></div>
<div class='composer'><span id='4'>久石让</span></div>
<div class='designer'><span id='5'>原研哉</span></div>
""""
obj = re.compile(r"<div class='.*?'><span id='(?P<id>\d+)'>(?P<姓名>.*?)</span></div>", re.S) # re.S让"."匹配换行符
result = obj.finditer(s)
for it in result:print(it.group("姓名"))print(it.group("id"))
# 使用命名捕获组:(?P<分组名>正则表达式)单独从匹配内容中提取相关内容
实战案例:
# 实例 ———— 豆瓣Top250电影标题、评分、年份等
import requests
import re
import csvurl = "https://movie.douban.com/top250"
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"
}
response = requests.get(url, headers=head)
page_content = response.content.decode(encoding="utf-8")# 解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<title>.*?)'r'</span>.*?<p class="">.*?<br>(?P<year>.*?) .*?<span'r'class="rating_num" property="v:average">(?P<score>.*?)</span>.*?'r'<span>(?P<comment>.*?)人评价</span>', re.S)# 开始匹配
result = obj.finditer(page_content)
f = open("Douban_Top250_Movies.csv", mode="w")
f_csv = csv.writer(f) # 将文件以csv格式写入
for it in result:# print(it.group("title"))# print(it.group("score"))# print(it.group("comment"))# print(it.group("year").strip())dic = it.groupdict() # 将迭代器中的内容以字典形式写入dic['year'] = dic['year'].strip() # 去除年份前空格重新写入f_csv.writerow(dic.values())
f.close()
print("Successfully!")
Beautiful Soup:
安装:
# 安装并导入BeautifulSoup库:
pip install bs4
from bs4 import BeautufulSoup# 调用库函数实例化对象(指定解析器"html.parser")
content = requests.get("http://www.baidu.com/").text
soup = Beautifulsoup(content,"html.parser")
成员属性/函数:
# 成员属性
p = soup.p # HTML中首个<p>标签中的内容
img = soup.img # HTML中首个<img>标签中的内容# 成员函数
# 语法
find/find_all(self, name=None, attrs={}, recursive=True, text=None)
name # 标签名
attrs # 属性字典
recursive # 递归循环查找,默认:True
text # 文本内容
# Find函数返回首个满足条件的标签内容(Tag类型)
p = soup.find("p", id="link1", attrs={"class":"man"}, text="tassel")
p.name # 获取标签名称
p.attrs # 获取标签所有属性的键和值
p.text # 获取标签的文本字符串
# 示例
all_prices = soup.find_all("p",attrs={"class":"price_color"}) # HTML中所有<p>标签中class键值对应"price_color"的内容
# 循环打印所有价格标签内容
for price in all_prices: print(price)
'''<p class="price_color">A$51.77</p><p class="price_color">A$53.74</p><p class="price_color">A$50.10</p><p class="price_color">A$47.82</p><p class="price_color">A$54.23</p><p class="price_color">A$22.65</p><p class="price_color">A$33.34</p><p class="price_color">A$17.93</p>
'''
# 循环打印所有价格标签中的文本字符串
for price in all_prices: print(price.string)
'''A$51.77A$53.74A$50.10A$47.82A$54.23A$22.65A$33.34A$17.93
'''
# 还可以利用切片操作再次简化所获取的信息
price.string[2:]
实战案例:
# 实例 ———— 豆瓣Top250电影标题
import requests
import time
import random
from bs4 import BeautifulSoup# 伪装真实客户端
user_agents = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"# 添加更多User-Agent...
]# 打开文件准备写入
with open('Douban_Top250_Movies.txt', 'w', encoding='utf-8') as file:# 分页请求for start_num in range(0, 250, 25):try:# 随机选择User-Agenthead = {"User-Agent": random.choice(user_agents)}# 发出请求response = requests.get(f'https://movie.douban.com/top250?start={start_num}', headers=head)response.raise_for_status() # 检查响应状态码html = response.text# 实例化对象soup = BeautifulSoup(html, "html.parser")all_titles = soup.find_all("span", attrs={"class": "title"})# 循环打印并写入文件for title in all_titles:title_string = title.stringif "/" not in title_string:file.write(title_string + '\n') # 写入文件并换行except requests.RequestException as error:print(f"Request failed for start_num {start_num}: {error}")time.sleep(1) # 设置请求间隔,避免触发反爬虫机制print("Successfully saved to Douban_Top250_Movies.txt!")
response.close()
🌟注意,爬取结束后需关闭访问状态,否则将被网站识别为异常账户,后续无法继续爬取
Xpath:
XML:
HTML文档属于XML文档中的子类,而Xpath为XML文档中搜索内容的语言,因此可以使用Xpath来解析HTML网页源代码,并实现爬取功能(使用之前需安装 lxml库 )
语法:
# 基础用法
from lxml import etree
xml = """<book><id>1</id><name>野花遍地香</name><price>1.23</price><author><nick>周大强</nick><son><nick>周小强</nick></son><nick>周芷若</nick><div><nick>张无忌</nick></div></author></book> """tree = etree.XML(xml)
result_1 = tree.xpath("/book") # '/'根节点
result_2 = tree.xpath("/book/name")
result_3 = tree.xpath("/book/name/text()") # text()获取文本
result_4 = tree.xpath("/book/author//nick/text()") # '//'后代所有标签(深度搜索)
result_5 = tree.xpath("/book/author/*/nick/text()") # '*'通配符
# 进阶用法
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8" /><title>Title</title>
</head>
<body><ul><li><a href="http://www.baidu.com">百度</a></li><li><a href="http://www.google.com">谷歌</a></li><li><a href="http://www.sogou.com">搜狗</a></li></ul><ol><li><a href="plane">飞机</a></li><li><a href="gun">大炮</a></li><li><a href="train">火车</a></li></ol><div class="job">李嘉诚</div><div class="common">胡辣汤</div>
</body>
</html>tree = etree.parse("Xpath_Test.html")
result_1 = tree.xpath("/html")
result_2 = tree.xpath("/html/body/ul/li/a/text()")
result_3 = tree.xpath("/html/body/ul/li[1]/a/text()") # Xpath索引顺序从'1'开始
ol_li_list = tree.xpath("/html/body/ol/li")
for li in ol_li_list:# 从各li中提取文字信息result_4 = li.xpath("./a/text()") # '.'相对路径result_5 = li.xpath("./a/@href") # '@'获取属性值
result_6 = tree.xpath("/html/body/ol/li/a[@href='gun']/text()") # [@xxx=xxx]属性筛选
利用浏览器自带的开发工具可以十分方便地获取网页指定内容的Xpath路径
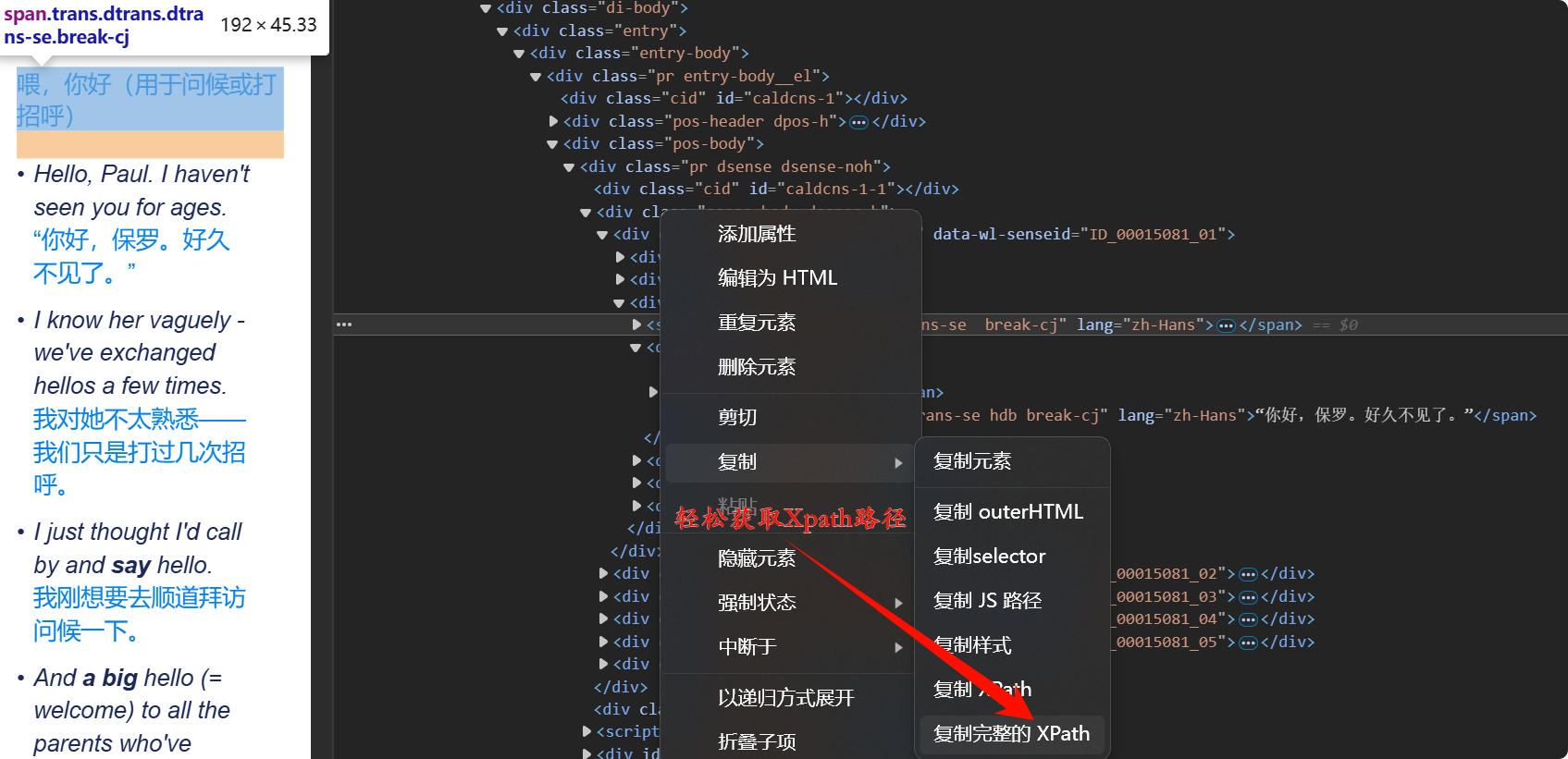
进阶篇:
Cookie处理:
对于某些特殊的网站需要登录后才能获取相应数据,此时需要结合 'Cookie' + 'url' 请求访问网站,利用 'session' 进行连续请求,请求过程中不会丢失 'cookie' ,所以可以做到登录爬取
import requestsurl = "https://novel.com/user/login"
data = {"loginName": "Tassel","password": "123456"
}# 登录(会话)
session = requests.session()
session.post(url, data=data)# 获取书架内容
resp = session.get("https://novel.com/author/shelf?page=1&appKey=20241107")
print(resp.json())

# 定义请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ''AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/121.0.0.0 Safari/537.36','Cookie': '_iuqxldmzr_=32; WEVNSM=1.0.0;''WM_TID=W%2B2UhElokMpFQQAFQELUn9wfjRvH6lk%2B;''ntes_utid=tid._.46j7nkoJT0FBQhVQVVbFy9gKzA7Wv0pn._.0;''NMTID=00ObVYRGkNufmW7gkdKldpTc7slEQoAAAGMluRQ0A;''_ntes_nnid=0db8a97a3f0ccb5f24f4d668f5fc9f42,1703338595424;''_ntes_nuid=0db8a97a3f0ccb5f24f4d668f5fc9f42;''WNMCID=eytpiz.1703338596196.01.0;'
}
防盗链:
某些网站对于源码链接可能会做某些处理,使得获取的链接部分有误,此时需要根据某些参数(如CounId)进行修正;另外,某些网站在接受请求时会进行溯源,即检查上级请求URL,若不是从指定URL跳转访问,则代表访问异常,此时需要根据防盗链溯源
import requests# 获取countId(首页)
url = "https://www.pearvideo.com/video_1721692"
countId = url.split("_")[1]# 获取videoStatus.json()中srcUrl(视频页面 ———— 次级请求)
videoStatus = f"https://www.pearvide.com/videoStatus.jsp?contId={countId}&mrd=0.6952007481227842"
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) ""AppleWebKit/537.36 (KHTML, like Gecko) ""Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0",# 防盗链"Referer": url
}
# 请求视频页面,获取下载链接
resp = requests.get(videoStatus, headers=head)
dic = resp.json()
srcUrl = dic['videoInfo']['video']['srcUrl'] # json文件搜索
systemTime = dic['systemTime']
srcUrl = srcUrl.replace(systemTime, f"cont-{countId}") # 替换countId获取下载链接# 下载视频
with open("v.mp4", mode="wb") as f:f.write(requests.get(srcUrl).content)
代理(很刑):
大规模数据爬取很可能会被网站封IP,此时可以借助代理
import requests
# 218.60.8.83:3129
proxies = {"https": "https://218.60.8.83:3129"
}
resp = requests.get("https://www.baidu.com")
resp.encoding = 'utf-8'
print(resp.text)
飞升篇:
进程:资源单位,线程:执行单位

多线程:
from threading import Thread # 线程类def func():for i in range(100):print("func", i)if __name__ == '__main__':# 创建线程并分配线程任务t = Thread(target=func)# 线程状态:可开始工作(具体的执行时间由CPU决定)t.start()for i in range(100):print("main", i)
# 线程传参
from threading import Threaddef func(name):for i in range(100):print(name, i)if __name__ == '__main__':# 线程1t1 = Thread(target=func, args=("周杰伦",)) # 传参必须是元组t1.start()# 线程2t2 = Thread(target=func, args=("王力宏",))t2.start()for i in range(100):print("main", i)
多进程:
from multiprocessing import Processdef func():for i in range(100):print("子进程", i)if __name__ == '__main__':p = Process(target=func)p.start()for i in range(100):print("主进程", i)
线程池与进程池:
在线程池中同时开启多个线程,将任务分配给线程池,具体的线程调度由线程池决定
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutordef func(name):for i in range(100):print(name, i)if __name__ == '__main__':# 创建线程池with ThreadPoolExecutor(50) as t:# 100个线程任务交于线程池分配执行for i in range(100):t.submit(func, name=f"线程{i}")# 线程守护(等待线程任务完成,才继续执行以下代码)print("Successfully!")
协程:
通常来说,当程序处于I/O操作时,线程(单线程)会处于阻塞状态,此时CPU会选择性切换到其他程序上,阻塞结束后再返回计算,此时对于当前程序而言,CPU利用效率较低;此时,利用协程技术,用户可以指定程序处于阻塞状态时,CPU优先处理当前程序的其他任务,阻塞状态结束后返回计算,因此对于当前程序而言,CPU利用效率极高
多任务异步协程:
基础:
import asyncio
import timeasync def func1():print("Hello C++!")# 程序出现同步操作时,异步中断# time.sleep(3) ———— 同步操作await asyncio.sleep(3)print("Hello C++!")async def func2():print("Hello Python!")# time.sleep(2)await asyncio.sleep(2)print("Hello Python!")async def func3():print("Hello Java!")# time.sleep(4)await asyncio.sleep(4)print("Hello Java!")# 协程任务执行主函数
async def main():# 异步协程函数,函数执行得到协程对象,包装为任务tasks = [asyncio.create_task(func1()),asyncio.create_task(func2()),asyncio.create_task(func3())]await asyncio.wait(tasks)if __name__ == '__main__':t1 = time.time()asyncio.run(main())t2 = time.time()print(t2 - t1)
aiohttp模块:
import asyncio
import aiohttpurls = ["https://c-ssl.duitang.com/uploads/item/202002/20/20200220153559_smefo.jpeg","https://c-ssl.duitang.com/uploads/blog/202106/04/20210604225859_b1298.jpg"
]async def aiodownload(url):name = url.rsplit("/", 1)[1]async with aiohttp.ClientSession() as session: # 等价与requests.get()模块async with session.get(url) as resp: # 得到请求,写入文件with open("鬼灭之刃-时透/"+name, mode="wb") as f:f.write(await resp.content.read()) # 读取内容是异步操作,需要await挂起async def main():tasks = []for url in urls:tasks.append(asyncio.create_task(aiodownload(url)))await asyncio.wait(tasks)if __name__ == '__main__':asyncio.run(main())
实践案例:
# 西游记前100回内容爬取
import requests
import asyncio
import aiohttp
import json
import aiofiles# 获取各章节cid (同步操作)
def get_items(url):resp = requests.get(url)dic = resp.json()lit = dic['data']['novel']['items']print(lit)return litasync def download(title,cid):data = {"book_id": "4306063500","cid": f'4306063500|{cid}',"need_bookinfo": 1}data = json.dumps(data)url = f'http://dushu.baidu.com/api/pc/getChapterContent?data={data}'# 发送请求async with aiohttp.ClientSession() as session:async with session.get(url, data=data) as resp:dic = await resp.json()async with aiofiles.open('./book/'+title, mode='w', encoding='utf-8') as f:await f.write(dic['data']['novel']['content'])async def main():url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}'lit = get_items(url)tasks = []# 准备异步任务for item in lit:title = item['title']cid = item['cid']tasks.append(asyncio.create_task(download(title, cid)))await asyncio.wait(tasks)if __name__ == "__main__":asyncio.run(main())
拓展:
视频网站工作原理解析:
若视频直接通过
转码:2K,1080p,720p
切片处理(单文件拆分)
文件记录:视频播放顺序、视频存放路径以及其他 "元数据"
|