目录
- 文件权限管理
- 访问控制列表ACL
- VIM的使用及内容查询
- 文本三剑客
- 基本正则和扩展正则
- shell脚本之变量
简单总结一下linux中的权限
1.首先介绍一下关于linux中的用户:
Linux中每个用户是通过 User Id (UID)来唯一标识的,且Linux中可以将一个或多个用户加入用户组中,用户组是通过Group ID(GID) 来唯一标识的。在这其中我们需要明白用户和组之间的关系。
- 用户的主要组(primary group):用户必须属于一个且只有一个主组,默认创建用户时会自动创建
和用户名同名的组,做为用户的主要组,由于此组中只有一个用户,又称为私有组 - 用户的附加组(supplementary group): 一个用户可以属于零个或多个辅助组,附属组
2.用户和组的主要配置文件:
* /etc/passwd:用户及其属性信息(名称、UID、主组ID等)
* /etc/shadow:用户密码及其相关属性
* /etc/group:组及其属性信息
* /etc/gshadow:组密码及其相关属性
passwd文件格式:
etc/passwd
* login name:登录用名(wang)
* passwd:密码 (x)
* UID:用户身份编号 (1000)
* GID:登录默认所在组编号 (1000)
* GECOS:用户全名或注释
* home directory:用户主目录 (/home/wang)
* shell:用户默认使用shell (/bin/bash)
gshdow文件格式:
etc/gshdow
* 群组名称:就是群的名称
* 群组密码:
* 组管理员列表:组管理员的列表,更改组密码和成员
* 以当前组为附加组的用户列表:多个用户间用逗号分隔
shadow文件格式:
etc/shadow
* 登录用名
* 用户密码:一般用sha512加密
* 从1970年1月1日起到密码最近一次被更改的时间
* 密码再过几天可以被变更(0表示随时可被变更)
* 密码再过几天必须被变更(99999表示永不过期)
* 密码过期前几天系统提醒用户(默认为一周)
* 密码过期几天后帐号会被锁定
* 从1970年1月1日算起,多少天后帐号失效
3.用户和组管理常用命令
用户管理命令:
* useradd:添加用户
* usermod:修改用户属性
* userdel:删除用户
格式:
user[options] [options] username
useradd -r -u 1001 mqh #添加用户
usermod -u 1002 mqh #修改用户属性
userdel -f mqh #删除用户
添加用户常见选项
-u UID
-o 配合-u 选项,不检查UID的唯一性
-g GID 指明用户所属基本组,可为组名,也可以GID
-c "COMMENT“ 用户的注释信息
-d HOME_DIR 以指定的路径(不存在)为家目录
-s SHELL 指明用户的默认shell程序,可用列表在/etc/shells文件中
-G GROUP1[,GROUP2,...] 为用户指明附加组,组须事先存在
-N 不创建私用组做主组,使用users组做主组
-r 创建系统用户 CentOS 6之前: ID<500,CentOS7 以后: ID<1000
-m 创建家目录,用于系统用户
-M 不创建家目录,用于非系统用户
-p 指定加密的密码
修改用户属性常见选项:
-u UID: 新UID
-g GID: 新主组
-G GROUP1[,GROUP2,...[,GROUPN]]]:新附加组,原来的附加组将会被覆盖;若保留原有,则要同时使用-a选项
-s SHELL:新的默认SHELL
-c 'COMMENT':新的注释信息
-d HOME: 新家目录不会自动创建;若要创建新家目录并移动原家数据,同时使用-m选项
-l login_name: 新的名字
-L: lock指定用户,在/etc/shadow 密码栏的增加 !
-U: unlock指定用户,将 /etc/shadow 密码栏的 ! 拿掉
-e YYYY-MM-DD: 指明用户账号过期日期
-f INACTIVE: 设定非活动期限,即宽限期
删除用户常见选项:
-f, --force 强制
-r, --remove 删除用户家目录和邮箱
组命令
* groupadd
* groupmod
* groupdel
group[options] [options] groupname
groupadd -g -r 1001 mqh #添加组
groupmod -g 1002 mqh #修改组属性
groupdel -f mqh #删除组组的常用选项
组的常用选项
#创建
-g GID 指明GID号;
-r 创建系统组,CentOS 6之前: ID<500,CentOS 7以后: ID<1000
#修改
-n group_name: 新名字
-g GID: 新的GID
#删除
-f, --force 强制删除,即使是用户的主组也强制删除组,但会导致无主组的用户不可用无法登录
添加/修改用户密码
passwd [options] username
echo -e '123456\n123456' | passwd mqh #非交互式修改密码(\n表换行)常见选项
-d:删除指定用户密码
-l:锁定指定用户
-u:解锁指定用户
-e:强制用户下次登录修改密码
-f:强制操作
-n mindays:指定最短使用期限
-x maxdays:最大使用期限
-w warndays:提前多少天开始警告
-i inactivedays:非活动期限
--stdin:从标准输入接收用户密码,Ubuntu无此选项
查看用户相关id信息
`id [OPTION] username`
常见选项-u: 显示UID
-g: 显示GID
-G: 显示用户所属的组的ID
-n: 显示名称,需配合ugG使用
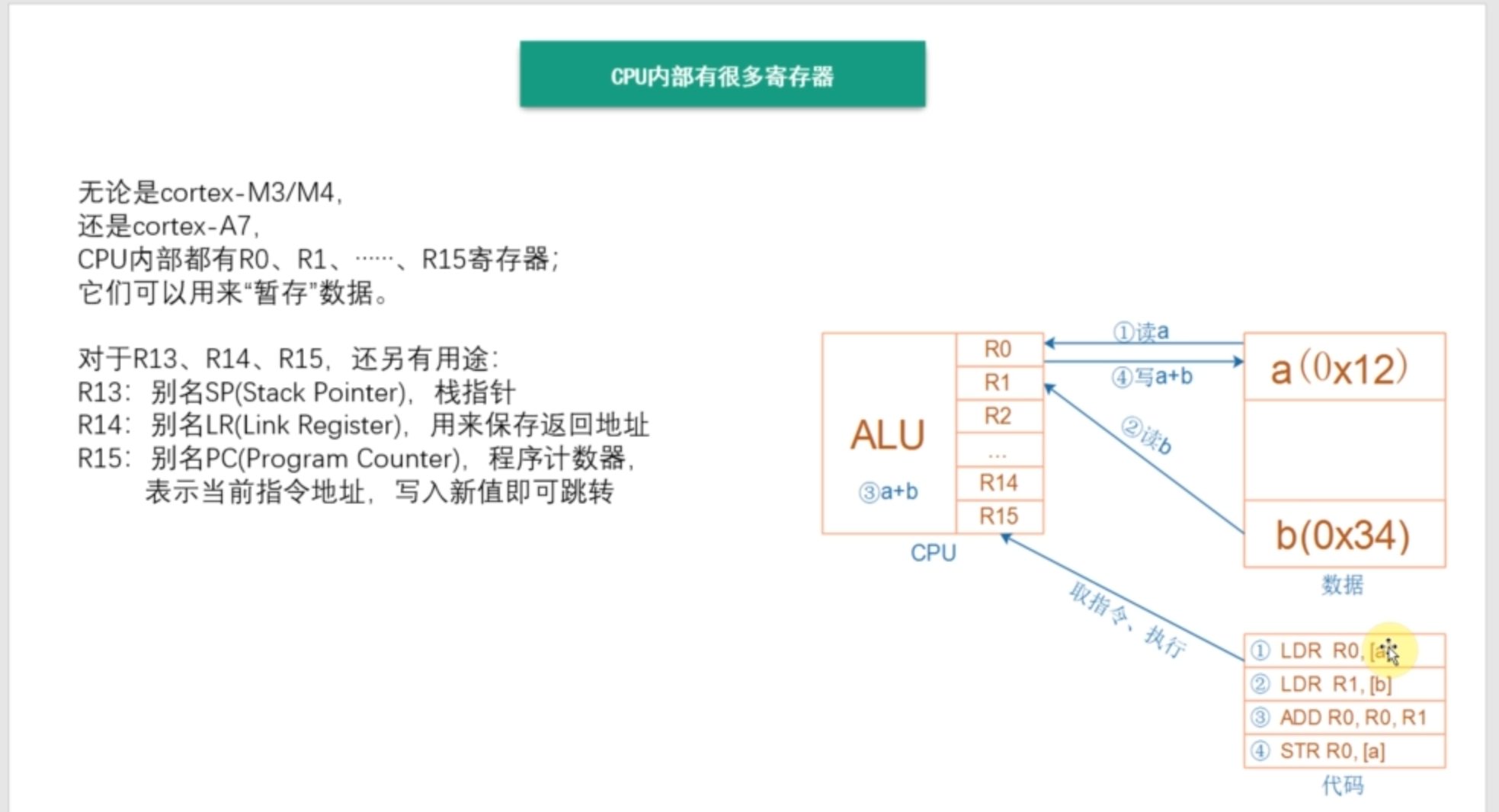
文件权限管理
程序访问文件时的权限,取决于此程序的发起者。
- 进程的发起者,同文件的属主:则应用文件属主权限
- 进程的发起者,属于文件属组;则应用文件属组权限
- 应用文件“其它”权限
文件权限说明
举例:-rwxrw----
从右往左看,一共10个字符,分成三段,第一段“---”代表的是“o”及other,表其他组和用户,第二段“rw-”代表的是“g”及group,表文件所属的组,第三段“rwx”代表的是“u”及owner,表文件所属的主(用户),第四段“-”代表文件类型。

r Readable 4
w Writable 2
x eXcutable 1
对文件的权限:
- r 可使用文件查看类工具,比如:cat,可以获取其内容
- w 可修改其内容,文件的是否被删除和文件的权限无关
- x 可以把此文件提请内核启动为一个进程,即可以执行(运行)此文件(此文件的内容必须是可执行)
文件权限常见组合
--- 0
r 4
r-x 5
rw 6
rwx 7
数学法的权限:
八进制数学
--- 000 0
--x 001 1
-w- 010 2
-wx 011 3
r-- 100 4
r-x 101 5
rw- 110 6
rwx 111 7
举例:
rw-r----- 640
rwxr-xr-x 755
设置文件的所有者chown
chown [user]:[group] file
设置文件的属组信息chgrp
chgrp [group] file
修改文件权限chmod
chmod -R a+x file # -R递归修改权限 a+x:属主加上X权限,修改指定一类用户某个或某个权限
chmod -R u=rwx file #修改指定一类用户的所有权限
chmod 777 file # 777:rwx
访问控制列表ACL
ACL:Access Control List,实现灵活的权限管理
除了文件的所有者,所属组和其它人,可以对更多的用户设置权限。
ACL生效顺序:所有者,自定义用户,所属组|自定义组,其他人
1.ACL相关命令
setfacl 用于设置文件或目录的ACL
setfacl -m u:meng:rwx file3.txt #u:meng:rwx 代表修改meng用户的u权限
getfacl 可查看设置的ACL权限
getfacl file3.txt

从上图可以看出使用setfacl后再ll,可以发现文件权限出现了一些小变化,多了一个加号,加号代表额外的ACL规则。而且从现有的发现来看,我们修改的是u权限,按理来说-rw-r--r--应该变成-rwxr--r--,但事实并非如此。原因是:ls -l 命令显示的基本权限位只反映了文件的基本权限,而不是ACL设置的权限。即使使用 setfacl 修改了某个用户的权限,基本权限位不会自动更新为反映ACL的变化。所以这个时候可以使用getfacl来查看这个文件的ACL规则。
2.mask权限
mask 是一个特殊的ACL条目,它定义了所有用户和组的权限上限。换句话说,mask 决定了哪些权限可以被实际应用于文件或目录,即使ACL中设置了某些权限,如果这些权限超出了mask的范围,它们将不会生效。作用:用于限制所有用户和组的权限上限。
setfacl -m m:r-x file3.txt #无论之后再修改成什么权限,最终只有r-x生效
VIM的使用及内容查询
vim file #按 i 进入编辑模式
vim基本命令
按“:”进入Ex模式 ,创建一个命令提示符: 处于底部的屏幕左侧
:w 写(存)磁盘文件
:wq 写入并退出
:x 写入并退出
:X 加密
:q 退出
:q! 不存盘退出,即使更改都将丢失
:r filename 读文件内容到当前文件中
:w filename 将当前文件内容写入另一个文件
:!command 执行命令
:r!command 读入命令的输出

文件内容查询
cat命令
cat [options] file
常用选项
-n:显示行号
-b:显示非空行的行号
-E:在每行末尾显示 $
head和tail命令
head [options] file
常用选项
-c # 指定获取前#字节
-n # 指定获取前#行,#如果为负数,表示从文件头取到倒数第#前范例:
[root@localhost meng]# head -c 10 passwd2
root:x:0:0
[root@localhost meng]# head -n 3 passwd2
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologintail [options] file
常用选项
-c # 指定获取后#字节
-n # 指定获取后#行,如果#是负数,表示从第#行开始到文件结束
-f 跟踪显示文件新追加的内容,常用于日志监控范例:
[root@localhost meng]# tail -c 10 passwd2
n/nologin
[root@localhost meng]# tail -n 3 passwd2
sssd:x:997:994:User for sssd:/:/sbin/nologin
chrony:x:996:993::/var/lib/chrony:/sbin/nologin
sshd:x:74:74:Privilege-separated SSH:/var/empty/sshd:/sbin/nologinwc命令
wc [options] file
常用选项
-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度范例:
[root@localhost meng]# cat file2.txt
hello 我的
cat: /xxx: No such file or directory
[root@localhost meng]# wc -l file2.txt
2 file2.txt
[root@localhost meng]# wc -w file2.txt
9 file2.txt
[root@localhost meng]# wc -c file2.txt
50 file2.txt
[root@localhost meng]# wc -m file2.txt
46 file2.txt
[root@localhost meng]# wc -L file2.txt
36 file2.txtcut命令
cut [options] file
常用选项:
-b list:按字节位置提取数据。例如 1-3 表示第 1 到第 3 字节
-c list:按字符位置提取数据。用法与 -b 类似(对于多字节字符更准确)。
-d delimiter:指定字段分隔符
-f list:按字段提取数据。例如 1-3 表示第 1 到第 3 字段
-s:只处理包含分隔符的行。 范例:
[root@localhost meng]# cat file6.txt
apple,banana,pear
red,bule,green
cat,dog,bird[root@localhost meng]# cut -b 1-4 file6.txt
appl
red,
cat,[root@localhost meng]# cut -d"," -f 1-2 file6.txt
apple,banana
red,bule
cat,dog文本查找
locate命令
介绍:
locate 是通过查询系统上预建的文件索引数据库 /var/lib/mlocate/mlocate.db来查询文件的,想要使用locate或者find命令,首先需要安装mlocate包,安装完后执行updatedb更新数据库。索引构建过程需要遍历整个根文件系统,很消耗资源,所以执行updatedb的时候需要系统较为空闲时自动进行。
[root@localhost meng]# yum install mlocate
[root@localhost meng]# updatedb
[root@localhost meng]# ll /var/lib/mlocate/mlocate.db
rw-r----- 1 root slocate 869840 11月 7 06:54 /var/lib/mlocate/mlocate.db特点:
- 查找速度快
- 模糊查找
- 非实时查找(新创建or删除的文件无法查询)
- 搜索的是文件的全路径,不仅仅是文件名
- 仅支持搜索用户具备读取和执行权限的目录
locate命令
locate [options] [PATTERN]常用选项:
-i 不区分大小写的搜索
-n N 只列举前N个匹配项目
-r 使用基本正则表达式范例:
[root@localhost meng]# locate -n 4 conf
/boot/config-4.18.0-348.el8.0.2.x86_64
/boot/grub2/i386-pc/configfile.mod
/boot/loader/entries/9eb148c7e35a4fcfbe73a10cc3ad2551-0-rescue.conf
/boot/loader/entries/9eb148c7e35a4fcfbe73a10cc3ad2551-4.18.0-348.el8.0.2.x86_64.conffind命令
介绍:
find 是实时查找工具,通过遍历指定路径完成文件查找。
特点:
- 查找速度略慢
- 精确查找
- 实时查找
- 查找条件丰富
- 仅支持搜索用户具备读取和执行权限的目录
格式:
find [OPTION] [查找路径] [查找条件] [处理动作]
查找路径:指定具体目标路径;默认为当前目录
查找条件:指定的查找标准,可以文件名、大小、类型、权限等标准进行;默认为找出指定路径下的所
有文件
处理动作:对符合条件的文件做操作,默认输出至屏幕
find根据文件名和inode查找
find [options] [PATTERN]常用选项:
-name "文件名称" #支持使用glob,如:*, ?, [], [^],通配符要加双引号引起来
-iname "文件名称" #不区分字母大小写
-inum n #按inode号查找范例:
[root@localhost meng]# find /home/meng/ -name "*.txt"
/home/meng/file1.txt
/home/meng/file2.txt
/home/meng/file3.txt
/home/meng/filea.txt
/home/meng/fileb.txt
/home/meng/filec.txt
/home/meng/filed.txt
/home/meng/file4.txt
[root@localhost meng]# find / -name "file1.txt"
/home/mqh/file1.txt
/home/meng/file1.txt
[root@localhost meng]# find -name "file1.txt"
./file1.txtfind根据属主、属组查找
常用选项:
-user #查找属主为指定用户(UID)的文件
-group #查找属组为指定组(GID)的文件
-uid #查找属主为指定的UID号的文件
-gid #查找属组为指定的GID号的文件
-nouser #查找没有属主的文件
-nogroup #查找没有属组的文件范例:
[root@localhost meng]# find / -user meng
find: ‘/proc/2031/task/2031/fd/7’: No such file or directory
find: ‘/proc/2031/task/2031/fdinfo/7’: No such file or directory
find: ‘/proc/2031/fd/6’: No such file or directory
find: ‘/proc/2031/fdinfo/6’: No such file or directory
/var/spool/mail/meng
/home/meng
/home/meng/.bash_logout
/home/meng/.bash_profile
/home/meng/.bashrc
/home/meng/file2.txt
/home/meng/file3.txt
/home/meng/.bash_historyfind根据文件类型查找
-type TYPE常用选项:
TYPE可以是以下形式:
f: 普通文件
d: 目录文件
l: 符号链接文件
s:套接字文件
b: 块设备文件
c: 字符设备文件
p: 管道文件范例:
[root@localhost meng]# ll /home
总用量 0
drwx------ 2 meng meng 256 10月 31 10:51 meng
drwx------ 2 mengqinghui meng 62 10月 31 09:03 mengqinghui
drwxr-xr-x 2 root root 157 10月 26 10:08 mqh
[root@localhost meng]# find /home -type d -ls16786460 0 drwxr-xr-x 5 root root 48 10月 31 09:03 /home33582862 0 drwxr-xr-x 2 root root 157 10月 26 10:08 /home/mqh711371 0 drwx------ 2 meng meng 256 10月 31 10:51 /home/meng16786453 0 drwx------ 2 mengqinghui meng 62 10月 31 09:03 /home/mengqinghui根据文件大小来查找
范例:
[root@localhost meng]# find -size +2k
./.file4.txt.swp
[root@localhost meng]# find -size -1M
./filea.txt
./fileb.txt
./filec.txt
./filed.txt文本三剑客
grep命令
工作模式:
由正则表达式字符及文本字符所编写的过滤条件来帮助用户对目标文本进行匹配检查,并打印到行。
grep命令
格式:
grep [OPTIONS] PATTERN [FILE...]常用选项:
--color=auto 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行,即取反
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系
-w 匹配整个单词
-E 使用ERE,相当于egrep(扩展正则表达式)
-F 不支持正则表达式,相当于fgrep
-P 支持Perl格式的正则表达式
-f file 根据模式文件处理
-r 递归目录,但不处理软链接
-R 递归目录,但处理软链接范例:#匹配hello字符
[root@localhost meng]# cat file2.txt
hello 我的
cat: /xxx: No such file or directory
[root@localhost meng]# grep -w hello file2.txt
hello 我的#查询80端口
[root@localhost meng]# ps aux | grep 80
polkitd 903 0.0 0.6 1766344 24080 ? Ssl 06:24 0:00 /usr/lib/polkit-1/polkitd --no-debug
root 918 0.0 1.0 438880 41076 ? S 06:24 0:00 /usr/libexec/sssd/sssd_nss --uid 0 --gid 0 --logger=files
root 922 0.0 0.1 92624 7580 ? Ss 06:24 0:00 /usr/lib/systemd/systemd-logind
root 2104 0.0 0.0 221928 1120 pts/0 S+ 08:24 0:00 grep --color=auto 80#查询并打印本机ip地址
[root@localhost meng]# ifconfig ens33 | grep -Eo '([0-9]{1,3}\.){3}[0-9]{1,3}'|head -1
192.168.93.200sed命令
工作模式:
1.读取输入流里的一行,将其存储在模式空间中。
2.依次执行一个或多个操作命令,如替换,删除,插入等。
3.根据第二步的操作结果,对模式空间内的内容进行修改。
4.输入模式空间的内容。
5.处理完当前行后,清空模式空间,准备处理下一行。
举例说明:
[root@localhost meng]# cat file5.txt
"小米" phone
“苹果” phone
“华为” phone
“锤子” phone
[root@localhost meng]# sed -e 's/小米/苹果/g' -e '/苹果/d' file5.txt
“华为” phone
“锤子” phone根据sed的工作模式可得:
1.读取第一行 "小米" phone,模式空间里的内容为"小米" phone
2.执行's/小米/苹果/g'命令,及将所有的小米替换为苹果,模式空间内的内容就变成了 “苹果” phone
3.执行下一个操作命令'/苹果/d',及删除包含苹果的行
4.输出模式空间的内容(空的,之前的步骤删掉苹果了)
5.清空模式空间
6.继续读取下一行“华为” phone,模式空间里的内容为"华为" phone
7.执行's/小米/苹果/g'命令,内容不匹配,所有原本的内容不变
8.输出模式空间的内容,“华为” phone
9.继续读取下一行。。。
sed命令
格式:
sed [option]... 'script;script;...' [inputfile...]常用选项:
-n 不输出模式空间内容到屏幕,即不自动打印
-e 允许使用多个编辑命令
-f FILE 从指定文件中读取编辑脚本
-r, -E 使用扩展正则表达式
-i 直接修改
-i.bak 备份文件并原处编辑
-s 将多个文件视为独立文件,而不是单个连续的长文件流替换命令:
s/old/new/:将每一行中的第一个匹配项替换为新文本
s/old/new/g:将每一行中的所有匹配项替换为新文本
s/old/new/2:将每一行中的第二个匹配项替换为新文本
s/old/new/p:打印替换后的行范例:
[root@localhost meng]# cat file5.txt
"小米" “红米” '红米' phone
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# sed 's/小米/华为/' file5.txt
"华为" “红米” '红米' phone
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# sed 's/红米/锤子/g' file5.txt
"小米" “锤子” '锤子' phone
"华为" “荣耀” ‘锤子’ '锤子' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# sed 's/红米/apple/2' file5.txt
"小米" “红米” 'apple' phone
"华为" “荣耀” ‘红米’ 'apple' phone
“苹果” “apple” phone
“锤子” phone
'锤子'插入命令:
i\:在匹配行之前插入文本
a\:在匹配行之后附加文本
c\:将匹配行替换为指定文本范例:
[root@localhost meng]# cat file5.txt
"小米" “红米” '红米' phone
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# sed '/小米/i\在小米之前插入雷军' file5.txt
在小米之前插入雷军
"小米" “红米” '红米' phone
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# sed '/小米/a\在小米之后插入雷军' file5.txt
"小米" “红米” '红米' phone
在小米之后插入雷军
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# sed '/红米/c\将包含红米的行替换雷军' file5.txt
将包含红米的行替换雷军
将包含红米的行替换雷军
“苹果” “apple” phone
“锤子” phone
'锤子'删除命令:
d:删除匹配的行
1d:删除第一行
1,3d:删除第1到第3行范例:
[root@localhost meng]# cat file5.txt
"小米" “红米” '红米' phone
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# sed '/锤子/d' file5.txt
"小米" “红米” '红米' phone
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
[root@localhost meng]# sed '1d' file5.txt
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# sed '1,3d' file5.txt
“锤子” phone
'锤子'awk命令
awk工作模式:
1.读取一行
每次读取输入流中的一行,并将其存储在内部缓冲区中。
2.分割字段
默认使用空格或制表符作为字段分隔符,将每一行分割成多个字段,可以使用-F 选项或 FS 变量指定其他分隔符。
3.执行规则
依次执行在脚本中定义的规则。每个规则由一个模式和一个操作组成,格式为 pattern { action },如果模式匹配当前行,则执行相应的操作。
4.处理内置变量
awk 提供了一些内置变量,用于访问和操作字段、行号等信息。
5.输出结果
awk命令
常见内置变量:
$0:当前行的全部内容。
$1, $2, ...:当前行的第一个字段、第二个字段等。
NF:当前行的字段数。
NR:当前行的行号。
FS:字段分隔符。
OFS:输出字段分隔符,默认为空格。
ORS:输出行分隔符,默认为换行符。[root@localhost meng]# cat file6.txt
apple,banana,pear
red,bule,green
cat,dog,bird
[root@localhost meng]# awk -F, '{print $0}' file6.txt
apple,banana,pear
red,bule,green
cat,dog,bird
[root@localhost meng]# awk -F, '{print $1}' file6.txt
apple
red
cat
[root@localhost meng]# awk -F, '{print $0,NF}' file6.txt
apple,banana,pear 3
red,bule,green 3
cat,dog,bird 3
[root@localhost meng]# awk -F, '{print NR,$0}' file6.txt
1 apple,banana,pear
2 red,bule,green
3 cat,dog,birdawk特殊规则
BEGIN:在处理任何输入行之前执行的代码块。
END:在处理所有输入行之后执行的代码块。范例:
[root@localhost meng]# awk -F, 'BEGIN{ print "在处理文件前打印我" } { print $0 }' file6.txt
在处理文件前打印我
apple,banana,pear
red,bule,green
cat,dog,bird
[root@localhost meng]# awk -F, '{ print $0 } END{ print "总行数:",NR }' file6.txt
apple,banana,pear
red,bule,green
cat,dog,bird
总行数: 3awk的常见action
print命令
作用:输出指点内容
范例:
[root@localhost meng]# awk '{ print $0 }' file5.txt
"小米" “红米” '红米' phone
"华为" “荣耀” ‘红米’ '红米' phone
“苹果” “apple” phone
“锤子” phone
'锤子'
[root@localhost meng]# awk '{ print $1 }' file5.txt
"小米"
"华为"
“苹果”
“锤子”
'锤子'printf命令
用途:格式化输出。格式符:
%s:显示字符串
%d, %i:显示十进制整数
%f:显示为浮点数
%e, %E:显示科学计数法数值
%c:显示字符的ASCII码
%g, %G:以科学计数法或浮点形式显示数值
%u:无符号整数
%%:显示%自身格式修饰符:
- 左对齐(默认右对齐)
+ 显示数值的正负符号
宽度:指定输出的最小宽度。
例如:%-10s 表示左对齐,宽度为10。
精度:对于浮点数,指定小数点后的位数。
例如:%.2f 表示保留两位小数。
前导零:指定输出的最小宽度,并用零填充。
例如:%05d 表示宽度为5,不足部分用零填充。范例:
[root@localhost meng]# cat file7.txt
apple,100,0.999
banana,2,1.5
pear,30,2.50
[root@localhost meng]# awk -F, '{ printf "字符串: %s, 数字: %d\n", $1,$2 }' file7.txt
字符串: apple, 数字: 100
字符串: banana, 数字: 2
字符串: pear, 数字: 30
[root@localhost meng]# awk -F, '{ printf "字符串: %s, 数字: %.3f\n", $1,$3 }' file7.txt
字符串: apple, 数字: 0.999
字符串: banana, 数字: 1.500
字符串: pear, 数字: 2.500
[root@localhost meng]# awk -F, '{ printf "%-10s %5d %8.2f\n", $1,$2,$3 }' file7.txt
apple 100 1.00
banana 2 1.50
pear 30 2.50
[root@localhost meng]# awk -F, '{ printf "字符串: %s, 数字: %d%%\n", $1,$2 * 10 }' file7.txt
字符串: apple, 数字: 1000%
字符串: banana, 数字: 20%
字符串: pear, 数字: 300%变量赋值
用途:给变量赋值。
范例:
[root@localhost meng]# cat file7.txt
apple,100,0.999
banana,2,1.5
pear,30,2.50
10,20,30
[root@localhost meng]# awk -F, '{ sum += $2 } END { print "sum:",sum }' file7.txt
sum: 152if-else语句
作用:条件判断
范例:
[root@localhost meng]# cat file7.txt
apple,100,0.999
banana,2,1.5
pear,30,2.50
10,20,30#输出符合第2列大于20的所有行
[root@localhost meng]# awk -F, '{ if($2 > 20) print $0 }' file7.txt
apple,100,0.999
pear,30,2.50#输出符合第2列大于20的所有行里的第一行
[root@localhost meng]# awk -F, '{ if($2 > 20) print $1 }' file7.txt
apple
pear[root@localhost meng]# awk -F, '{ if($2 > 2000) {print $0} else { print $1} }' file7.txt
apple
banana
pear
10
[root@localhost meng]# awk -F, '{ if($2 > 0) {print $0} else { print $1} }' file7.txt
apple,100,0.999
banana,2,1.5
pear,30,2.50
10,20,30switch 语句
作用:根据多个条件选择执行不同的操作
范例:
[root@localhost meng]# cat file7.txt
apple,100,0.999
banana,2,1.5
pear,30,2.50
10,20,30
[root@localhost meng]# awk -F, '{ switch ($1) { case "apple": print "这是一个苹果";break; case "10": print "这是个数字";break; default: print "未识别";} }' file7.txt
这是一个苹果
未识别
未识别
这是个数字循环语句
循环语句之for循环
作用:重复执行一组操作
范例:
#逐个输出每一行的所有字段
[root@localhost meng]# awk -F, '{ for (i = 1; i <= NF; i++) print $i; }' file7.txt
apple
100
0.999
banana
2
1.5
pear
30
2.50
10
20
30[root@localhost meng]# tail -n 1 file7.txt
10,20,30
[root@localhost meng]# tail -n 1 file7.txt | awk -F, '{sum=0; for(i=1;i<=NF;i++){sum+=$i}; print sum}'
60
解读:sum初始为0,当i=1时,其所代表的第一个字段(就是10),将10赋值给sum,
此时sum为10而不是1,以此类推sum=i1+i2+i3 也就是sum=10+20+30循环语句之while循环
作用:在条件为真时重复执行一组操作
范例:
[root@localhost meng]# cat file7.txt
apple,100,0.999
banana,2,1.5
pear,30,2.50
10,20,30[root@localhost meng]# awk -F, '{ i = 100; while (i <= NF) { print $i; i++; } }' file7.txt
[root@localhost meng]# awk -F, '{ i = 1; while (i <= NF) { print $i; i++; } }' file7.txt
apple
100
0.999
banana
2
1.5
pear
30
2.50
10
20
30
[root@localhost meng]# awk -F, '{ print NF }' file7.txt
3
3
3
3解读:已知,file7文件里共有4行,每行有三个字段,i的初始为1,
当 i = 1时,while判断为真,依次输出每一行里的所有字段,当i的值超过3时,while判断为假,不再执行while循环。do-while循环
作用:先执行一次do操作,然后再检查条件
范例:
[root@localhost meng]# awk -F, '{ i = 1; do { print $i; i++; } while (i <= NF); }' file7.txt
apple
100
0.999
banana
2
1.5
pear
30
2.50
10
20
30特殊控制语句
next语句
作用:跳过当前行,继续执行下一行
范例:
[root@localhost meng]# cat file7.txt
apple,100,0.999
banana,2,1.5
next,”跳过我这行“
pear,30,2.50
10,20,30
[root@localhost meng]# awk -F, '{ if ($1 == "next") next; print $0; }' file7.txt
apple,100,0.999
banana,2,1.5
pear,30,2.50
10,20,30exit语句
作用:立即退出awk脚本
范例:
[root@localhost meng]# cat file7.txt
apple,100,0.999
stop,”遇到我你就得停了喔“
banana,2,1.5
next,”跳过我这行“
pear,30,2.50
10,20,30
[root@localhost meng]# awk -F, '{ if ($1 == "stop") exit; print $0; }' file7.txt
apple,100,0.999基本正则和扩展正则
基本正则表达式常用用法包括:字符匹配、匹配次数、位置锚定和分组
字符匹配
-v : 反向匹配
.:匹配任意单个字符
[ ]:匹配括号内的任意一个字符
[ ^ ]:匹配不在括号内的任意一个字符
[ - ]:匹配指定范围内的任意一个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母,示例:[[:lower:]],相当于[a-z]
[:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 包括空格、制表符(水平和垂直)、换行符、回车符等各种类型的空白,比[:blank:]包含的范围广
[:cntrl:] 不可打印的控制字符
[:digit:] 十进制数字
[:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
范例:
[root@localhost meng]# cat file8.txt
1
3
9
apple
pear
dog
158# [] 匹配包含括号内的任意字符
[root@localhost meng]# grep '[d]' file8.txt
dog# [^]除了括号内的字符
[root@localhost meng]# grep '[^dog]' file8.txt
1
3
9
apple
pear
158# 匹配范围内的字符
[root@localhost meng]# grep '[1-6]' file8.txt
1
3
158# 匹配包含字母的字符
[root@localhost meng]# grep '[[:alpha:]]' file8.txt
apple
pear
dog匹配次数
* #匹配前面的字符任意次,包括0次
.* #任意长度的任意字符
\? #匹配其前面的字符出现0次或1次
\+ #匹配其前面的字符出现最少1次
\{n\} #匹配前面的字符n次
\{m,n\} #匹配前面的字符至少m次,至多n次
\{,n\} #匹配前面的字符至多n次,<=n
\{n,\} #匹配前面的字符至少n次范例:
#匹配匹配前面的字符任意次,包括0次
[root@localhost meng]# grep 'a*' file8.txt
1
3
9
apple
pear
dog
158#匹配其前面的字符出现0次或1次
[root@localhost meng]# grep 'a\?' file8.txt
1
3
9
apple
pear
dog
158
[root@localhost meng]# grep 'dog\?' file8.txt
dog#匹配前面的字符n次
[root@localhost meng]# grep 'p\{2\}' file8.txt
apple\{n,\} #匹配前面的字符至少n次
[root@localhost meng]# grep 'p\{2,\}' file8.txt
apple位置锚定
^:匹配行首。
$:匹配行尾。
^[[:space:]]*$:空白行
\<PATTERN\>:匹配整个单词范例:
[root@localhost meng]# cat /etc/fstab#
# /etc/fstab
# Created by anaconda on Sun Oct 20 19:35:58 2024
#
# Accessible filesystems, by reference, are maintained under '/dev/disk/'.
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info.
#
# After editing this file, run 'systemctl daemon-reload' to update systemd
# units generated from this file.
#
/dev/mapper/rl-root / xfs defaults 0 0
UUID=982d5922-9968-45a9-9859-6ef07c69a7ec /boot xfs defaults 0 0
/dev/mapper/rl-swap none swap defaults 0 0# 除了以#开头的任意字符
[root@localhost meng]# grep '^[^#]' /etc/fstab
/dev/mapper/rl-root / xfs defaults 0 0
UUID=982d5922-9968-45a9-9859-6ef07c69a7ec /boot xfs defaults 0 0
/dev/mapper/rl-swap none swap defaults 0 0#匹配整个单词
[root@localhost meng]# grep '\<swap\>' /etc/fstab
/dev/mapper/rl-swap none swap defaults 0 0分组
\( \):分组,用于捕获子表达式
\1:引用第一个捕获组
\2:引用第二个捕获组,依此类推范例:
# 匹配包含 ap 的行
[root@localhost meng]# grep 'ap' file8.txt
apple# 匹配包含 a 后跟任意字符再跟 a 的行
[root@localhost meng]# grep 'a.\(a\)' file8.txt
banana基本正则(BRE)和扩展正则(ERE)的区别
区别一:
BRE: +、?、{、}、|,使用这些字符时需要转义(\),如\?, \+
ERE:不需要转义,可直接使用
区别二:
BRE分组时,使用的是\(和\),例:\(abc\)
ERE分组时,使用的是(),例:(abc)
实例
[root@localhost meng]# cat file1.txt
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin#BRE 删除每行的第一个字符
[root@localhost meng]# sed 's/^.//' file1.txt
oot:x:0:0:root:/root:/bin/bash
in:x:1:1:bin:/bin:/sbin/nologin
aemon:x:2:2:daemon:/sbin:/sbin/nologin
dm:x:3:4:adm:/var/adm:/sbin/nologin解读:s:替换 , /^.: ^是行首,.匹配任意字符(/是转义), //:空字符串# 删除每行的第二个字符
[root@localhost meng]# cut -c1,3- file1.txt | paste -sd '\n'
rot:x:0:0:root:/root:/bin/bash
bn:x:1:1:bin:/bin:/sbin/nologin
demon:x:2:2:daemon:/sbin:/sbin/nologin
am:x:3:4:adm:/var/adm:/sbin/nologin解读:-c1,3-:提取第一个字符和第三个字符及以后的部分paste -sd '\n':将提取的结果重新组合成行#BRE 删除每行最后一个字符
[root@localhost meng]# awk '{ sub(/.$/, ""); print }' file1.txt
root:x:0:0:root:/root:/bin/bas
bin:x:1:1:bin:/bin:/sbin/nologi
daemon:x:2:2:daemon:/sbin:/sbin/nologi
adm:x:3:4:adm:/var/adm:/sbin/nologi解读: sub(/.$/, ""); print 是一个awk脚本,
sub:在 awk 中用于查找并替换第一个匹配的子字符串
格式:sub(regex, replacement, target)
regex代表正则表达式
replacement代表用于替换匹配到的子字符串
target代表当前行
即:
sub(/.$/, ""); print :将最后一个字符替换为 ""(空)。
/.$/:正则表达式,匹配 最后一个字符。
"":替换为 空。
print:打印处理后的字符串# 删除每一行倒数第二个字符
[root@localhost meng]# rev file1.txt | cut -c1,3- | rev
root:x:0:0:root:/root:/bin/bah
bin:x:1:1:bin:/bin:/sbin/nologn
daemon:x:2:2:daemon:/sbin:/sbin/nologn
adm:x:3:4:adm:/var/adm:/sbin/nologn解读: rev是将内容逆向显示,第一个rev将内容逆向,然后执行cut,第二个rev再把内容逆回来
shell脚本之变量
变量命名规则
名称规则:
- 变量名只能包含字母(a-z, A-Z)、数字(0-9)和下划线(_)。
- 变量名不能以数字开头。
- 变量名区分大小写。
赋值规则:
- 变量赋值时,等号两边不能有空格。
- 变量引用时,使用 $ 符号加上变量名。
变量类型
普通变量:
生效范围为当前shell进程;一旦关闭终端或脚本执行结束就会销毁。对当前shell之外的其它shell进程,包括当前shell的子shell进程均无效。
环境变量:
生效范围为当前shell进程及其子进程;可以使子进程(包括孙子进程)继承父进程的变量,但是无法让父进程使用子进程的变量。
name=VALUE #赋值变量(普通变量)
export name #声明变量(环境变量)$name #用于在命令中使用变量的值
echo $name #将变量的值输出到终端或文件,常用于调试和显示信息
unset name #删除变量echo $BASHPID #查看shell进程的pid
cat /proc/$PID/environ #查看进程的环境变量只读变量:
使用 readonly 命令将变量设置为只读,一旦设置为只读,变量的值不能被修改。
[root@localhost meng]# readonly num=100
[root@localhost meng]# echo $num
100
[root@localhost meng]# num=99
-bash: num: 只读变量位置变量:
表示传递给脚本或函数的参数,通过 $1, $2, $3 等引用。
[root@localhost meng]# cat shell1.sh
#!/bin/bash
echo "hello world"
echo "first word: $1"
echo "second word: $2"
[root@localhost meng]# bash shell1.sh yes no
hello world
first word: yes
second word: no状态变量
表示当前的状态或信息。
常见特殊变量:
$?:上一个命令的退出状态码(常用于检验上一个命令是否成功,返回值为0代表成功)
$$:当前 Shell 进程的 PID
$!:最近一个后台进程的 PID
$#:传递给脚本或函数的参数个数
$*:所有位置参数作为一个字符串
$@:所有位置参数,每个参数作为一个单独的字符串[root@localhost meng]# cat file1.txt > /dev/null
[root@localhost meng]# echo $?
0
[root@localhost meng]# echo $$
1500使用shell解决鸡兔同笼问题
30鸡和兔的头,80鸡和兔的脚,分别有几只鸡,几只兔?#!/bin/bash
# 定义变量
heads=30
feet=80#鸡的数量
chicken=$(( (4 * heads - feet) / 2 ))#兔的数量
rabbit=$(( heads - chicken ))echo "鸡:$chicken"
echo "兔:$rabbit"[root@localhost meng]# bash shell2.sh
鸡:20
兔:10结合shell完成循环和条件判断
#!/bin/bash#遍历 21-30 的数字
for a in {21..30}# 使用do-while循环判断用户是否存在do#将循环变量a依次附加到user后面,形成用户名user1,user2.。Username="User$a"# &>/dev/null 减少不必要的输出if id "$Username" &>/dev/null; thenecho "用户 $Username 已存在"elseuseradd "$Username"# 判断useradd命令是否成功if [ $? -eq 0 ]; thenecho "用户创建成功"elseecho "用户已创建"fifi
done