第三次作业
作业①:
1.要求:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(
http://www.weather.com.cn
)。使用scrapy框架分别实现单线程和多线程的方式爬取。
–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。
- 输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
- Gitee****文件夹链接
2.代码片段
import scrapy
import os
from urllib.parse import urljoin
from scrapy.exceptions import CloseSpiderclass WeatherInfoSpider(scrapy.Spider):spider_name = 'weather'allowed_sites = ['weather.com.cn']initial_urls = ['http://www.weather.com.cn/']# 设定页面和图片下载的限制page_limit = 17image_limit = 117page_counter = 0image_counter = 0def start_requests(self):self.logger.info('Starting requests...')for url in self.initial_urls:yield scrapy.Request(url, callback=self.process_page)def process_page(self, response):# 检查是否已达到页面限制if self.page_counter >= self.page_limit:raise CloseSpider('Reached maximum page limit.')self.page_counter += 1self.logger.info(f'Visited page {self.page_counter}.')# 提取图片链接images = response.css('img::attr(src)').getall()for image in images:full_image_url = urljoin(response.url, image)self.image_counter += 1self.logger.info(f'Found image URL: {full_image_url}')yield {'image_url': full_image_url}# 检查是否已达到图片下载限制if self.image_counter >= self.image_limit:raise CloseSpider('Reached maximum image download limit.')# 提取并请求其他页面链接links = response.css('a::attr(href)').getall()for link in links:if self.page_counter >= self.page_limit:breakfull_link = urljoin(response.url, link)yield scrapy.Request(full_link, callback=self.process_page)def close(self, reason):self.logger.info(f'Spider closed. Reason: {reason}')3.截图
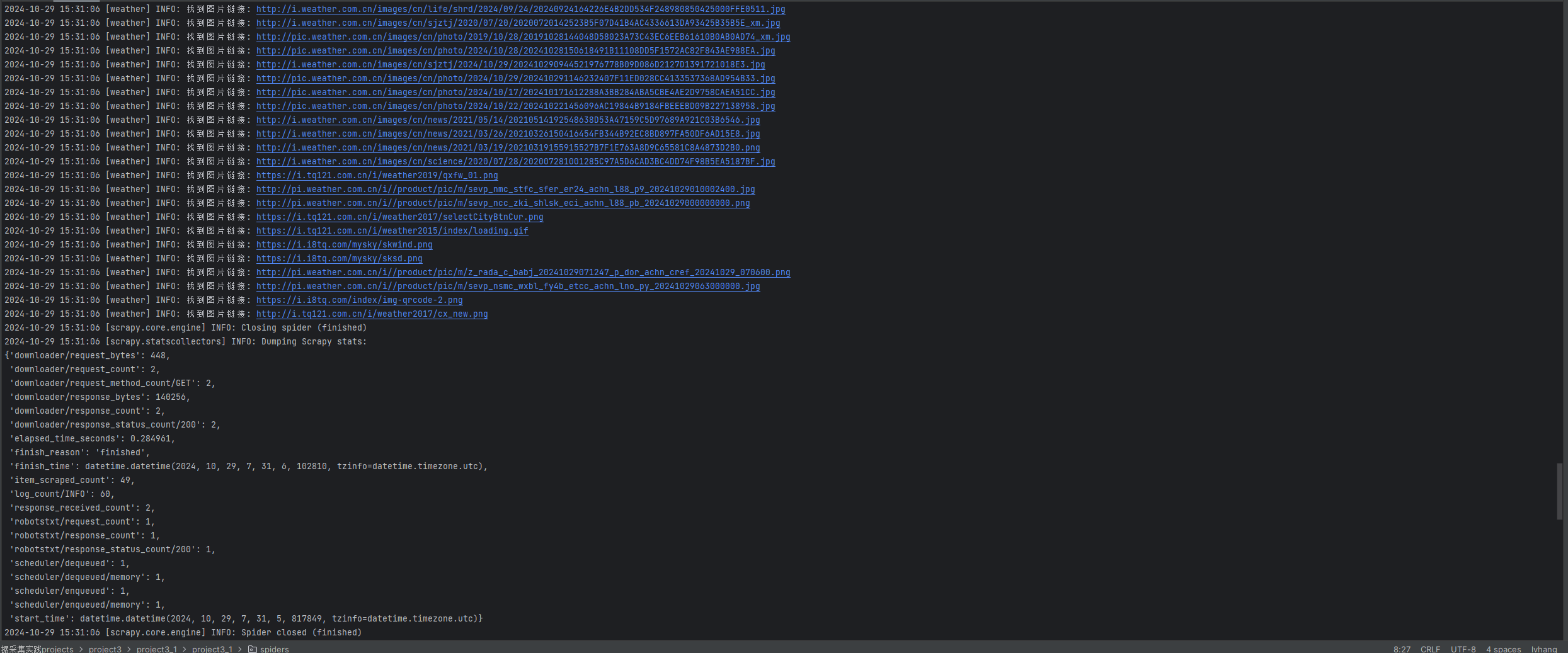
心得体会:
单线程爬取:适用于需要爬取的页面较少,且目标网站响应速度较快。
多线程爬取:适用于需要抓取大量数据,或者目标网站的响应速度较慢时。
作业②
1.要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。
-
候选网站:东方财富网:https://www.eastmoney.com/
-
-
输出信息:MySQL数据库存储和输出格式如下:
-
表头英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计
-
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 振幅 最高 最低 今开 昨收 1 688093 N世华 28.47 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.20 17.55 2…… -
Gitee文件夹链接
2.代码片段
from typing import Any, Dict
import scrapy
import re
import json
import pymysqlclass StockItem(scrapy.Item):latest_price = scrapy.Field()change_percentage = scrapy.Field()change_amount = scrapy.Field()volume = scrapy.Field()turnover = scrapy.Field()amplitude = scrapy.Field()code = scrapy.Field()name = scrapy.Field()high = scrapy.Field()low = scrapy.Field()today_open = scrapy.Field()yesterday_close = scrapy.Field()class StockSpider(scrapy.Spider):name = 'stock_spider'start_urls = ['http://25.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124021313927342030325_some_timestamp&pn=1&pz=20&po=1&np=1&ut=some_unique_token&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f2,f3,f4,f5,f6,f7,f12,f14,f15,f16,f17,f18&_=some_other_timestamp']def parse(self, response: scrapy.http.Response) -> Any:body = response.textdiff_pattern = re.compile(r'"diff":\[(.*?)\]', re.DOTALL)diff_data = diff_pattern.search(body).group(1)data_pattern = re.compile(r'\{(.*?)\}', re.DOTALL)stock_records = data_pattern.findall(diff_data)for record in stock_records:stock_data = json.loads('{' + record + '}')item = StockItem()item['latest_price'] = stock_data.get('f2')item['change_percentage'] = stock_data.get('f3')item['change_amount'] = stock_data.get('f4')item['volume'] = stock_data.get('f5')item['turnover'] = stock_data.get('f6')item['amplitude'] = stock_data.get('f7')item['code'] = stock_data.get('f12')item['name'] = stock_data.get('f14')item['high'] = stock_data.get('f15')item['low'] = stock_data.get('f16')item['today_open'] = stock_data.get('f17')item['yesterday_close'] = stock_data.get('f18')yield itemclass StockPipeline:def open_spider(self, spider: scrapy.Spider):try:self.connection = pymysql.connect(host='127.0.0.1',user='root',password='Cjkmysql.',port=3306,charset='utf8',database='chenoojkk')self.cursor = self.connection.cursor()self.cursor.execute('DROP TABLE IF EXISTS stocks')create_table_sql = """CREATE TABLE stocks (latest_price DOUBLE,change_percentage DOUBLE,change_amount DOUBLE,volume DOUBLE,turnover DOUBLE,amplitude DOUBLE,code VARCHAR(12) PRIMARY KEY,name VARCHAR(32),high DOUBLE,low DOUBLE,today_open DOUBLE,yesterday_close DOUBLE)"""self.cursor.execute(create_table_sql)except Exception as e:print(f"Error opening spider: {e}")def process_item(self, item: StockItem, spider: scrapy.Spider) -> StockItem:try:insert_sql = """INSERT INTO stocks (latest_price, change_percentage, change_amount, volume, turnover, amplitude, code, name, high, low, today_open, yesterday_close) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""values = (item['latest_price'], item['change_percentage'], item['change_amount'],item['volume'], item['turnover'], item['amplitude'], item['code'],item['name'], item['high'], item['low'], item['today_open'], item['yesterday_close'])self.cursor.execute(insert_sql, values)self.connection.commit()except Exception as e:print(f"Error processing item: {e}")return itemdef close_spider(self, spider: scrapy.Spider):self.cursor.close()self.connection.close()
3.截图
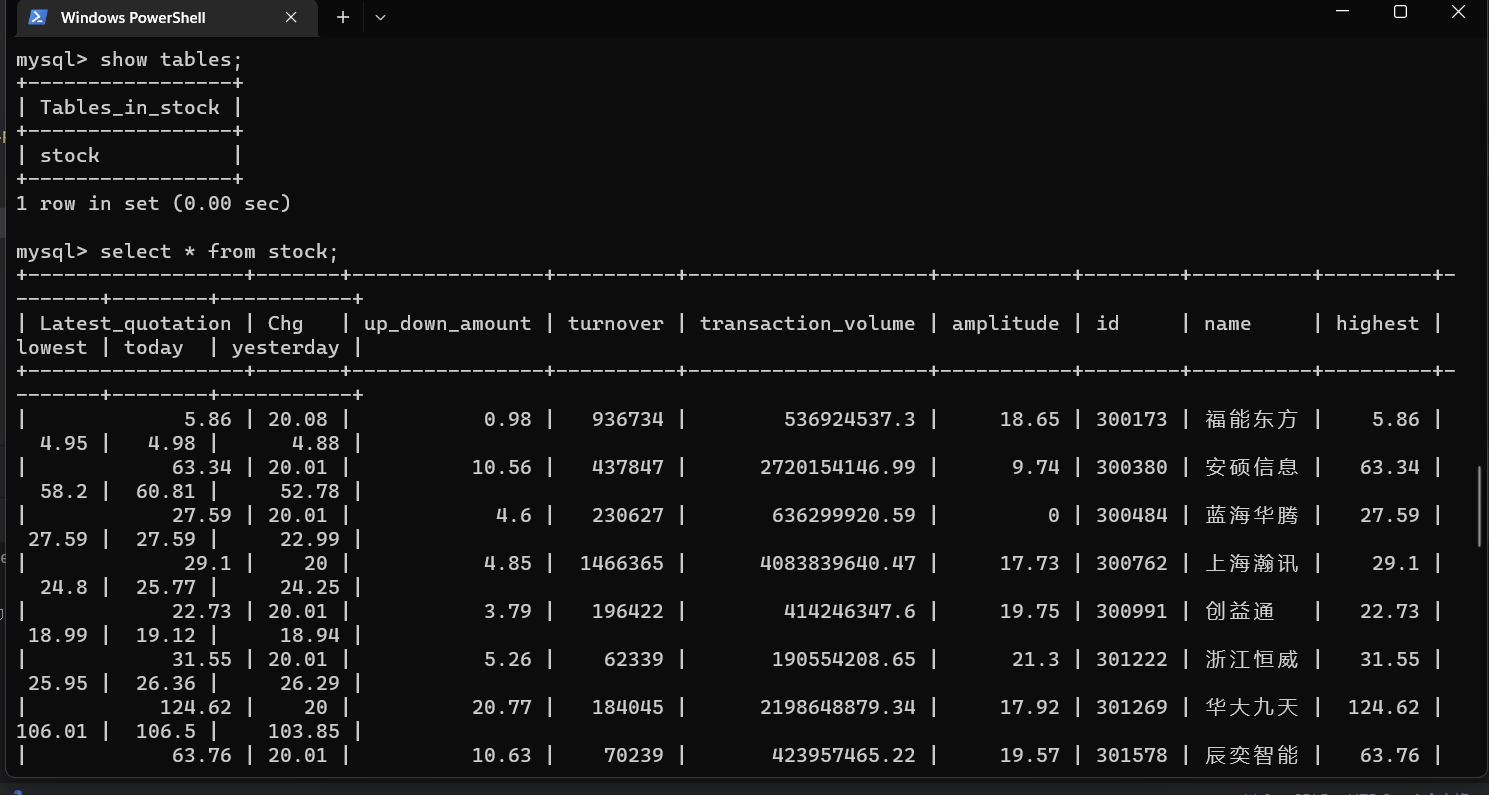
心得体会:
学会了如何将数据存入数据库,由于使用终端较难可视化,下次将使用navicat
作业③:
1.要求
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
-
候选网站:****中国银行网:https://www.boc.cn/sourcedb/whpj/
-
输出信息:
-
Gitee文件夹链接
| Currency | TBP | CBP | TSP | CSP | Time |
|---|---|---|---|---|---|
| 阿联酋迪拉姆 | 198.58 | 192.31 | 199.98 | 206.59 | 11:27:14 |
2.代码
import scrapy
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst, MapCompose
from w3lib.html import remove_tags
from Practical_work3.items import Work3Item
import pymysqlclass Work3Spider(scrapy.Spider):name = 'work3_revised'start_requests = [scrapy.http.Request('https://www.boc.cn/sourcedb/whpj/', callback=self.parse)]def parse(self, response):for row in response.css('table[align="left"] tr'):loader = ItemLoader(item=Work3Item(), selector=row, default_output_processor=TakeFirst())loader.add_css('name', 'td:nth-child(1)::text')loader.add_css('price1', 'td:nth-child(2)::text')loader.add_css('price2', 'td:nth-child(3)::text')loader.add_css('price3', 'td:nth-child(4)::text')loader.add_css('price4', 'td:nth-child(5)::text')loader.add_css('price5', 'td:nth-child(6)::text')loader.add_css('date', 'td:nth-last-child(1)::text')loader.add_value('name', MapCompose(remove_tags)(loader.get_output_value('name')))yield loader.load_item()class Work3Pipeline:def __init__(self):self.db = Noneself.cursor = Nonedef open_spider(self, spider):try:self.db = pymysql.connect(host='127.0.0.1', user='root', passwd='Cjkmysql.', port=3306, charset='utf8', database='chenoojkk')self.cursor = self.db.cursor()self.create_table()except Exception as e:print(f"Failed to connect to database: {e}")def create_table(self):try:self.cursor.execute('DROP TABLE IF EXISTS bank')self.cursor.execute("""CREATE TABLE bank (Currency varchar(32),p1 varchar(17),p2 varchar(17),p3 varchar(17),p4 varchar(17),p5 varchar(17),Time varchar(32))""")except Exception as e:print(f"Failed to create table: {e}")def process_item(self, item, spider):try:self.cursor.execute("""INSERT INTO bank (Currency, p1, p2, p3, p4, p5, Time)VALUES (%s, %s, %s, %s, %s, %s, %s)""", (item['name'],item['price1'],item['price2'],item['price3'],item['price4'],item['price5'],item['date']))self.db.commit()except Exception as e:print(f"Failed to insert item: {e}")return itemdef close_spider(self, spider):if self.cursor:self.cursor.close()if self.db:self.db.close()
3.截图
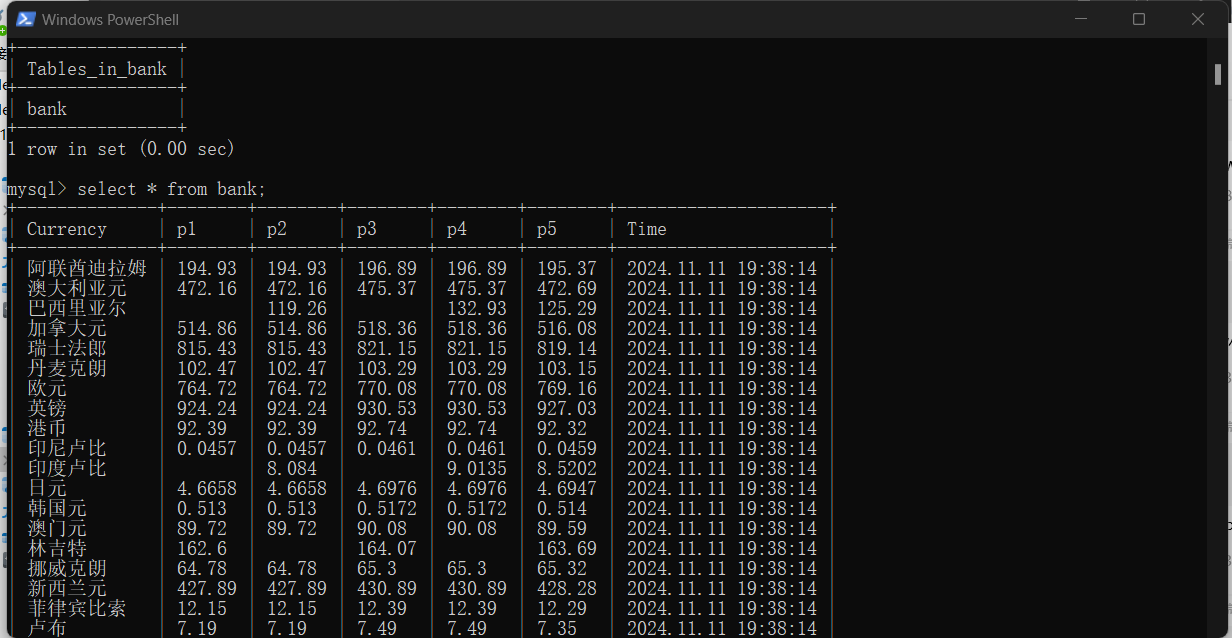
心得体会:
Scrapy 框架 提供了一个完整的爬取和数据存储的解决方案,能够处理请求、解析、数据存储等问题,非常适合构建大规模爬虫。