ElasticSearch 是什么?
ElasticSearch 是一个分布式的、基于 Lucene 的搜索引擎和数据分析引擎(服务器)
ElasticSearch 提供了 RESTful 风格的操作 API,是用 java 语言编写的开源软件,可以提供 PB 级别的数据存储与搜索
ElasticSearch 基本概念
ElasticSearch 是面向文档型的数据库,一条数据在 ElasticSearch 里面就是一个文档,以 JSON 的格式进行存储
索引(index)
类似于数据库,是文档数据的逻辑存储空间,是具有相似特征的文档的集合
文档(document)
是 ElasticSearch 中存储的基本数据单元,以 JSON 的格式表示,类似于 mysql 中的一条记录
类型(type)
在 ElasticSearch 早期版本中,用于对索引数据的逻辑分组,从 7.x 版本开始被移除,后续索引均为固定的 _doc 类型(具体原因是在 ES 中 不通 type 下的相同字段数据,在 lucene 中的处理方式是一样的,会导致数据冲突,需要进行特殊的处理)
字段(field)
字段是文档的基本组成部分,一个文档可以由多个字段组成,对应着要存储的数据的不同属性
字段可以是基本类型、数据类型或者嵌套类型
映射(mapping)
映射是对文档及其字段的类型、格式的元数据信息的定义,类似于数据库中的 scheme
节点(node)
节点是 ElasticSearch 运行的一个实例,可以看出是组成 ElasticSearch 集群的一个独立服务器,一台物理机上可以有多个节点
节点按照其功能可以分成三种:主节点(Master Node)、协调节点(Coordinating Node)、数据节点(Data Node)
- 主节点(Master Node):处理创建、删除索引等请求,维护集群状态信息,可以设置一个节点不承担主节点角色
- 协调节点(Coordinating Node):处理客户端请求,把请求分发到合适的节点,把最终
结果汇聚到一起,每一个节点默认起到了协调节点的作用 - 数据节点(Data Node):用来保存数据的节点、在数据扩展上起到了关键作用,可以设置一个节点不承担数据节点角色
集群(cluster)
集群是一个或者多个节点的集合,这些节点协同工作存储数据和处理数据
分片(shard)
分片是 ElasticSearch 中存储数据的容器,所有文档都存储在分片中,一个索引由多个分片组成,分片可以分为主分片(primary shard)和副本分片(replica shard)
- 主分片(primary shard):是文档数据存储的物理容器,用来解决数据水平扩展的问题,通过主分片,可以将数据分不到集群内的所有节点上,一个分片就是一个运行的 Lucene 实例
- 副本分片(replica shard):是主分片的一个拷贝,用来备份数据,为搜索文档和返回文档提供读操作服务
- 主分片可以对应 0 个、1 个或者多个副本分片
- 副本分片数可以动态调整
- 当主分片宕机的时候,副本分片提升为主分片
- 副本分片和主分片不能分布在同一个节点上
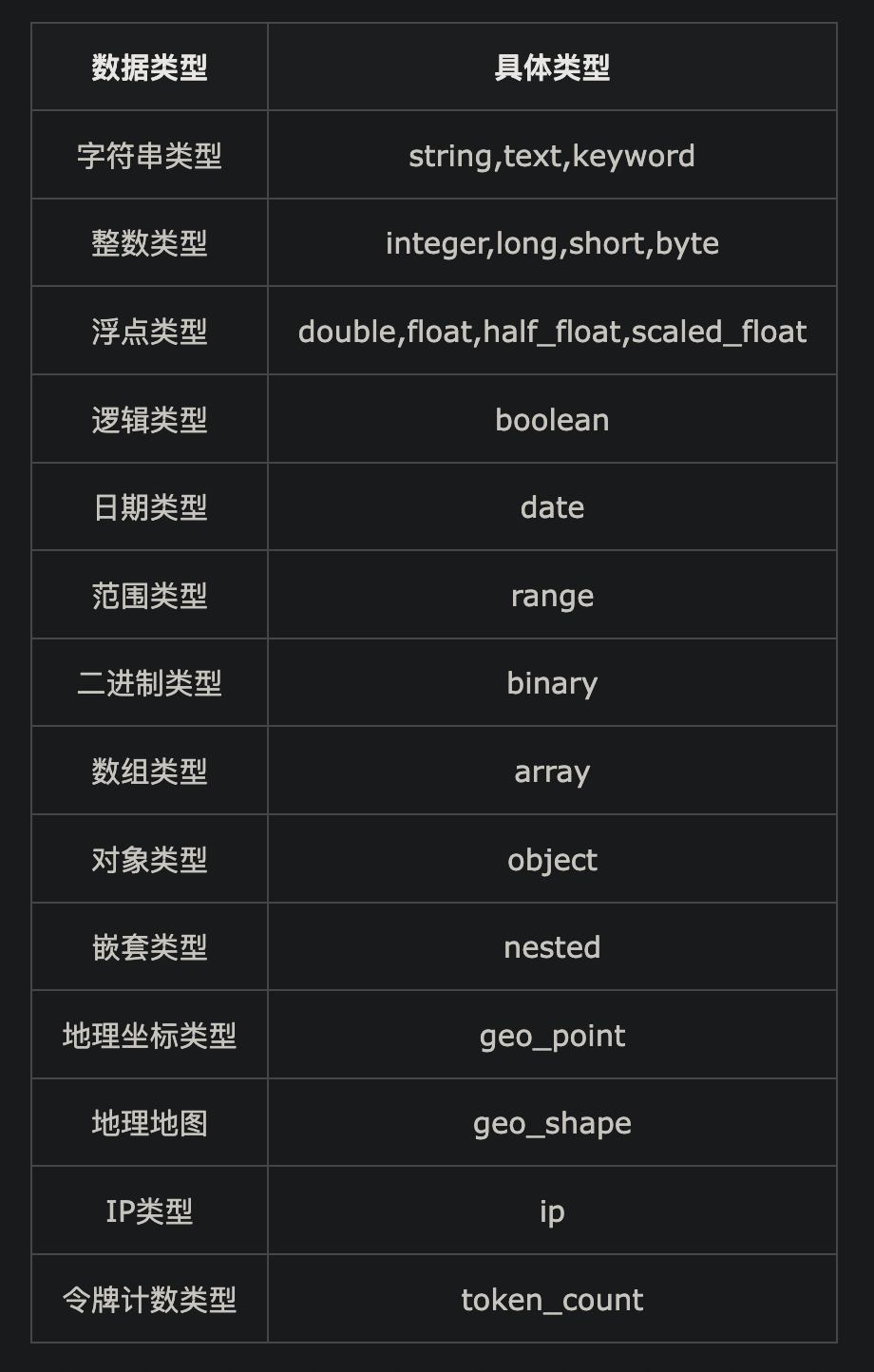
ElasticSearch 数据类型
常见的数据类型如下
注意事项:
5.x版本之后不在支持 string类型,而是用 text、keyword 类型代替
- text 类型字段不用于排序,需要使用分词器进行分词
- keyword 用于索引结构化的字段,keyword 类型的字段只能精确搜索,不会分词
Kibana 基本操作
集群数据操作
# 获取集群信息
GET _cluster/health# 获取节点信息
GET _cat/nodes# 获取分片信息
GET _cat/shards# 获取所有索引信息
GET /_cat/indices?v# 查看所有映射信息
GET /_mapping?pretty=true# 查看某一个索引映射信息
# 格式:GET {index_name}/_mapping?pretty=true
GET movies/_mapping?pretty=true# 创建索引
PUT student_info
{"settings": {"number_of_shards": 3,"number_of_replicas": 0},"mappings": {"properties": {"age": {"type": "long"},"name": {"type": "keyword"},"desc": {"type": "text"},"hobby": {"type": "text"}}}
}文档写操作
# 创建文档
# 如果命令中索引不存在的话,会自动创建索引
# 如果索引存在,索引中字段不存在,则会自动创建映射字段
POST users_info/_doc
{"user" : "Mike","post_date" : "2019-04-15T14:12:12","message" : "trying out Kibana","ingfo": "Happy"
}# 制定 id 创建文档
# 如果命令中索引不存在的话,会自动创建索引
# 如果索引存在,索引中字段不存在,则会自动创建映射字段
# 如果文档 id 已经存在,则会报错,提示文档已经存在(document already exists)
POST users_info2222/_doc/5?op_type=create
{"user" : "ZYC","post_date" : "2016-04-15T14:12:12","message" : "i have id","ingfo222": "Happy"
}# PUT等价命令
put users_info2222/_create/5
{"user" : "ZYC","post_date" : "2016-04-15T14:12:12","message" : "i have id","ingfo222": "Happy"
}# 如果 op_type=index 为更新文档,更新成功则版本号(_version)+1
# ?op_type=index 条件不存在,默认为 index
# 更新的目标文档不存在,则会创建文档
POST users_info2222/_doc/5?op_type=index
{"user" : "ZYC","post_date" : "2016-04-15T14:12:12","message" : "i have id","ingfo222": "Happy"
}# PUT等价命令
put users_info2222/_doc/5
{"user" : "11dian","post_date" : "2016-04-15T14:12:12","message" : "i have id by put"
}# 更新文档
# 按 _id 更新文档,版本号不变,只更新 doc 内制定字段信息
POST users_info2222/_update/5
{"doc":{"message" : "Update!"}
}文档读操作
# 按照 id 读取文档
# 格式:{index_name}/_doc/{_id}
GET users_info2222/_doc/5# 文档未找到,则返回信息:"found": false
GET users_info2222/_doc/10# 批量查询
GET _msearch
{"index" : "users_info2222"}
{"query" : {"match_all" : {}},"size":2}
Elasticsearch 索引原理
Elasticsearch 是如何实现 master 选举的
详细描述一下 Elasticsearch 索引文档的过程
详细描述一下 Elasticsearch 搜索的过程?
在并发情况下,Elasticsearch 如果保证读写一致?