gitee链接:
https://gitee.com/zxbaixuexi/2024scrapy/tree/master/第四次实践
作业①:
1)
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、“深证 A 股”3 个板块的股票数据信息。
候选网站:东方财富网:
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
from selenium.webdriver.chrome.service import Service as ChromeService
import pymysql# 连接自己的数据库,根据自己情况修改
conn = pymysql.connect(host="127.0.0.1", port=3306, user='root', passwd='123456', charset='utf8', db='homework1')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)# 显式指定Chrome二进制文件路径(根据实际安装路径进行修改)
chrome_binary_path = r"D:\noneprogramsoft\Google\Chrome\Application\chrome.exe"
#ChromeDriver
CHROMEDRIVER_PATH = r"C:\Users\supermejane\Desktop\爬虫实践\test4\chromedriver.exe"# 配置Chrome选项
options = webdriver.ChromeOptions()
options.binary_location = chrome_binary_path
#Service
service = ChromeService(executable_path=CHROMEDRIVER_PATH)# 创建一个WebDriver对象,并指定驱动程序路径
driver = webdriver.Chrome(service=service, options=options)urls = ["https://quote.eastmoney.com/center/gridlist.html#hs_a_board","https://quote.eastmoney.com/center/gridlist.html#sh_a_board","https://quote.eastmoney.com/center/gridlist.html#sz_a_board"]
tables = ["husheng","shangzheng","shengzheng"]
# 爬取前n页股票信息
def parseData(driver,n,tableName):for page in range(1, n + 1): # 爬取n页print(f"正在爬取第 {page} 页股票信息")# 定位所有股票信息的元素stocks_list = driver.find_elements(By.XPATH, "//div[@class='listview full']//tbody//tr")# 打印股票信息for stock in stocks_list:stock_id = stock.find_element(By.XPATH, './/td[1]').textstock_code = stock.find_element(By.XPATH, './/td[2]/a').textstock_name = stock.find_element(By.XPATH, './/td[3]/a').textstock_latest_price = stock.find_element(By.XPATH, './/td[5]//span').textstock_change_percent = stock.find_element(By.XPATH, './/td[6]//span').textstock_change_amount = stock.find_element(By.XPATH, './/td[7]//span').textstock_volume = stock.find_element(By.XPATH, './/td[8]').textstock_turnover = stock.find_element(By.XPATH, './/td[9]').textstock_amplitude = stock.find_element(By.XPATH, './/td[10]').textstock_highest = stock.find_element(By.XPATH, './/td[11]//span').textstock_lowest = stock.find_element(By.XPATH, './/td[12]//span').textstock_open_price = stock.find_element(By.XPATH, './/td[13]//span').textstock_close_price = stock.find_element(By.XPATH, './/td[14]').textsql = f"INSERT INTO {tableName} VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"cursor.execute(sql,[stock_id, stock_code, stock_name, stock_latest_price, stock_change_percent.strip("%"),stock_change_amount,stock_volume[:-1], stock_turnover[:-1], stock_amplitude.strip("%"), stock_highest,stock_lowest, stock_open_price,stock_close_price])conn.commit()print("数据已存入数据库")# 点击下一页按钮next_page_button = driver.find_element(By.XPATH, '//*[@id="main-table_paginate"]/a[2]')action = ActionChains(driver)time.sleep(5)action.move_to_element(next_page_button).perform()next_page_button.click()time.sleep(5)table_No=0
for url in urls:driver.get(url)parseData(driver,2,tables[table_No])table_No += 1conn.close()
# 关闭浏览器
driver.quit()
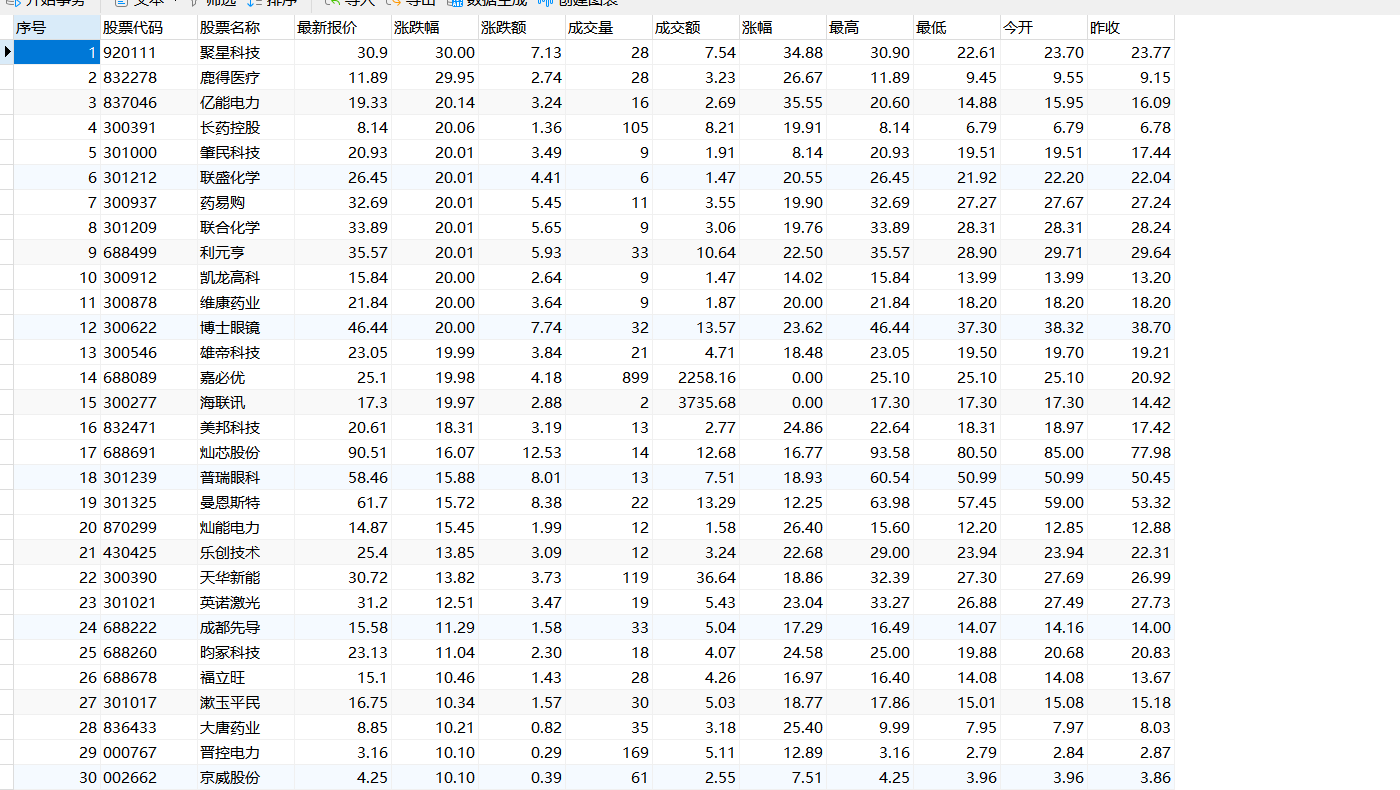
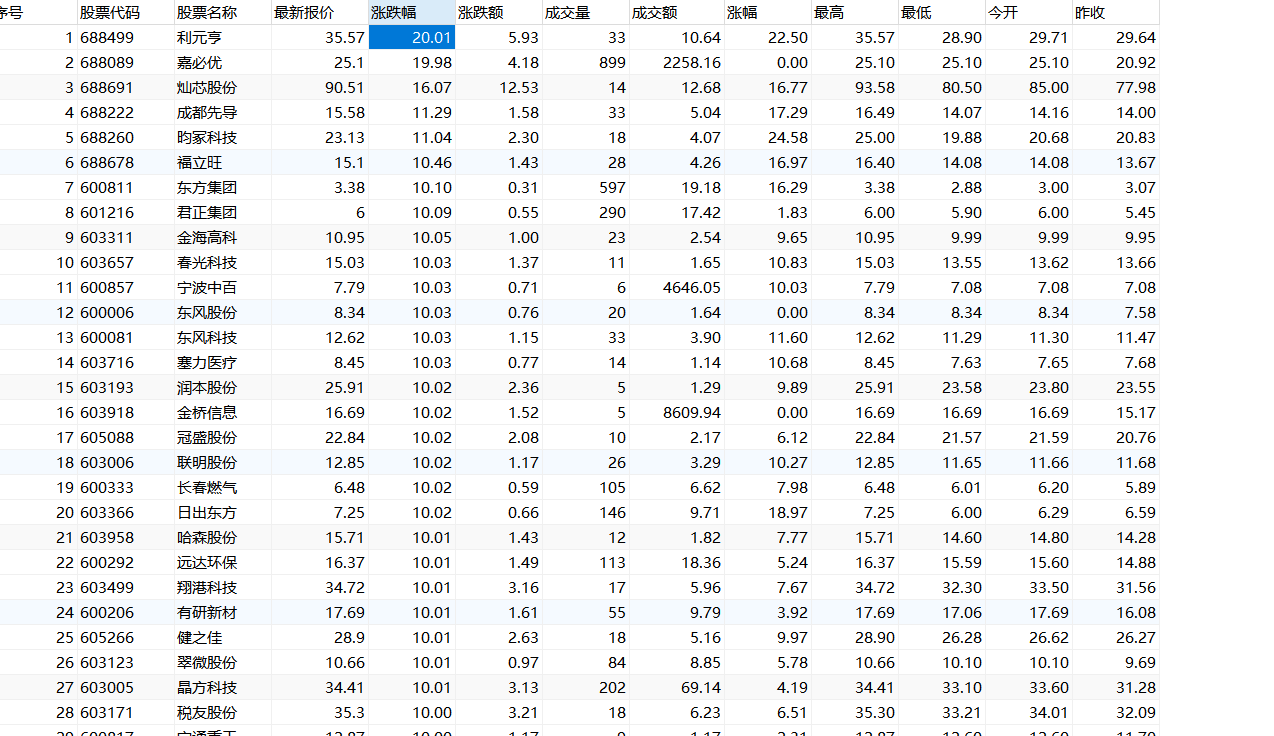
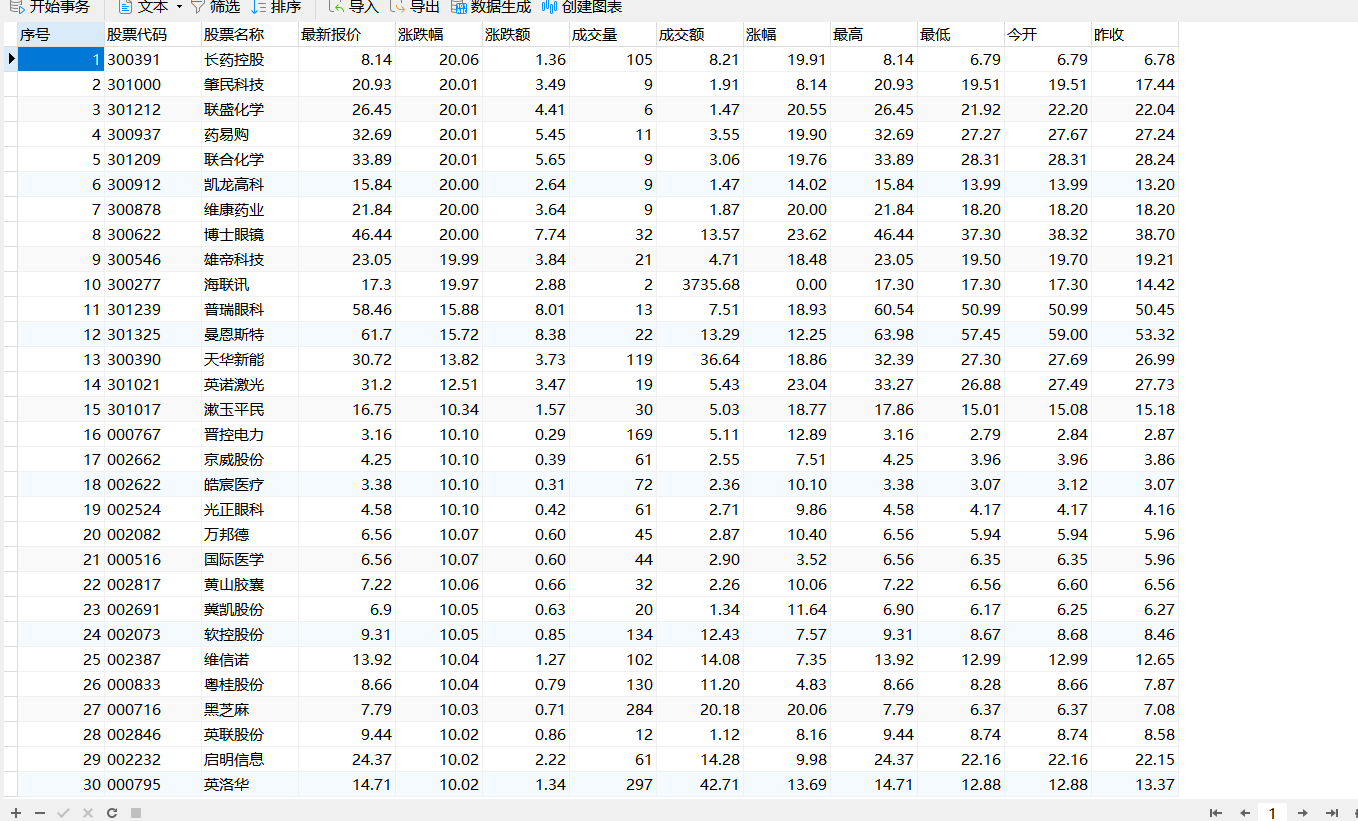
运行结果
husheng(沪深)
shangzheng(上证)
shengzheng(深证)
2)心得体会
学会了使用selenium爬取网页信息1,使用get获取网页信息,并模拟用户翻页,并可以结合Xpath等方式实现解析
作业②:
1)
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国 mooc 网:https://www.icourse163.org
代码
from time import sleepfrom selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium.webdriver.chrome.service import Service as ChromeService
import pymysql
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from scrapy.selector import Selector
from selenium.webdriver.common.keys import Keys
"""
链接数据库
"""
conn = pymysql.connect(host="127.0.0.1", port=3306, user='root', passwd='123456', charset='utf8', db='homework1')
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)"""
创建ChromeDriver
"""
# 显式指定Chrome二进制文件路径(根据实际安装路径进行修改)
chrome_binary_path = r"D:\noneprogramsoft\Google\Chrome\Application\chrome.exe"
#ChromeDriver
CHROMEDRIVER_PATH = r"C:\Users\supermejane\Desktop\爬虫实践\test4\chromedriver.exe"# 配置Chrome选项
options = webdriver.ChromeOptions()
options.binary_location = chrome_binary_path
#Service
service = ChromeService(executable_path=CHROMEDRIVER_PATH)# 创建一个WebDriver对象,并指定驱动程序路径
driver = webdriver.Chrome(service=service, options=options)"""
请求首页
"""
#请求
driver.get("https://www.icourse163.org/")"""
登陆
"""
#等待登录元素加载好再执行操作
WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located((By.XPATH, '//a[@class="f-f0 navLoginBtn"]'))).click()iframe = WebDriverWait(driver, 10, 0.5).until(EC.presence_of_element_located((By.XPATH, '//*[@frameborder="0"]')))
#切换到登录界面中
driver.switch_to.frame(iframe)
# 输入账号密码
driver.find_element(By.XPATH, '//*[@id="phoneipt"]').send_keys("19906912753")
time.sleep(3)
driver.find_element(By.XPATH, '//*[@class="j-inputtext dlemail"]').send_keys("Woshi2gouzi@")
time.sleep(3)
#点击登录按钮
driver.find_element(By.ID, 'submitBtn').click()time.sleep(5)
"""
搜索
"""
driver.switch_to.default_content()#等待输入框并输入’python‘
wait = WebDriverWait(driver, 10)
select_course = wait.until(EC.presence_of_element_located((By.XPATH,"//input[@class='ant-input']")))select_course.send_keys("python")
#输入回车
select_course.send_keys(Keys.ENTER)"""
解析数据
"""time.sleep(5)content = driver.page_source
print(content)
driver.quit()
selector = Selector(text=content)
rows = selector.xpath("//div[@class='m-course-list']/div/div")xuhao=0
#清空数据库
#cursor.execute("delete from course")# 爬取网站信息
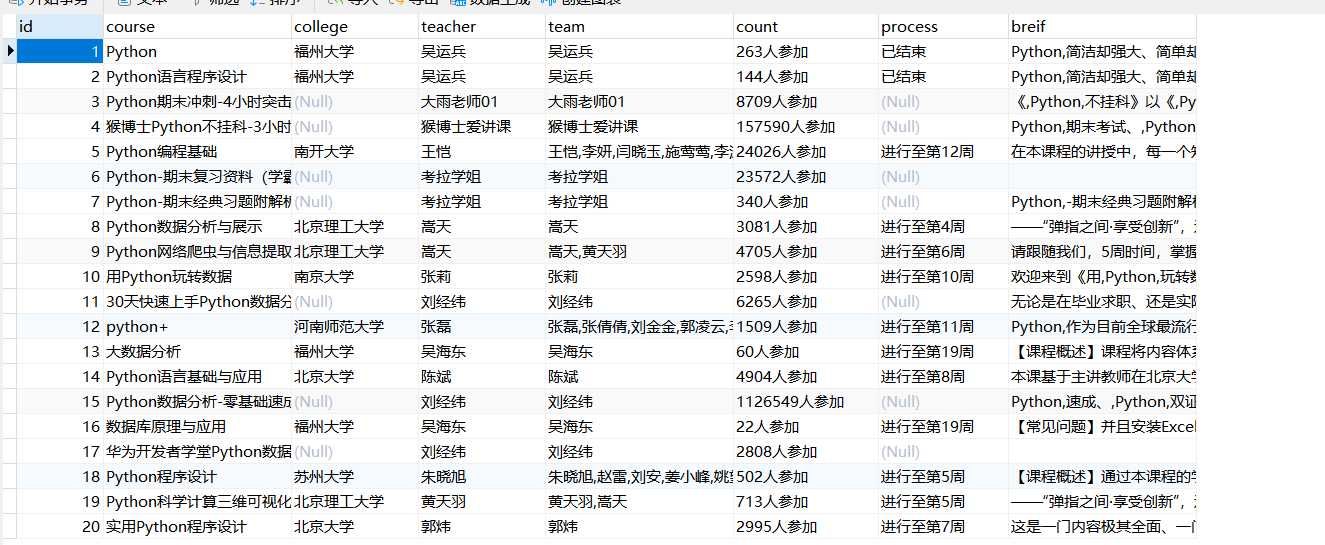
for row in rows:# 课程名称course1= row.xpath(".//span[@class=' u-course-name f-thide']//text()").extract()course="".join(course1)# 学校college=row.xpath(".//a[@class='t21 f-fc9']/text()").extract_first()# 主讲教师teacher=row.xpath(".//a[@class='f-fc9']//text()").extract_first()# 团队成员team1 = row.xpath(".//a[@class='f-fc9']//text()").extract()team=",".join(team1)# 参加人数count = row.xpath(".//span[@class='hot']/text()").extract_first()# 课程进度process = row.xpath(".//span[@class='txt']/text()").extract_first()# 课程简介brief1=row.xpath(".//span[@class='p5 brief f-ib f-f0 f-cb']//text()").extract()brief=",".join(brief1)xuhao+=1#sql插入数据sql = "INSERT INTO course VALUES (%s, %s, %s, %s, %s, %s, %s, %s)"cursor.execute(sql,[xuhao,course,college,teacher,team,count,process,brief])#提交
conn.commit()
print("数据已存入数据库")
运行结果
2)心得体会
学会了使用selenium的send_key填写表单实现登陆以及搜素,另外需要注意登陆时要查找Ifarme并使用selenium的driver.switch_to.frame(iframe)切换到对应的iframe
还有就是使用sleep配合wait.until(EC.presence_of_element_located())可以有效避免元素未加载的情况
作业③:
1)
完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
(一)Python脚本生成测试数据
① 登录MRS的master节点服务器
② 编写Python脚本
进入/opt/client/目录,使用vi命令编写Python脚本:autodatagen.py

③ 创建存放测试数据的目录

④ 执行脚本测试

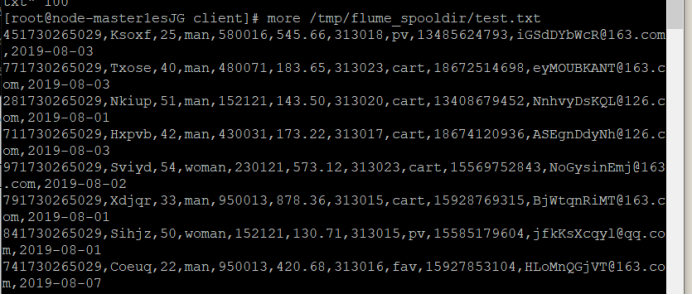
⑤ 使用more命令查看生成的数据
(二)下载安装并配置Kafka
1.上传kafka文件压缩包
① 使用PuTTY登录到master节点服务器上,进入/tmp/FusionInsight-Client/目录。

② 解压压缩包获取校验文件与客户端配置包

③ 执行命令,校验文件包。

界面显示如上信息,表明文件包校验成功。
2.安装Kafka运行环境
① 解压“MRS_Flume_ClientConfig.tar”文件。
② 查看解压后文件。
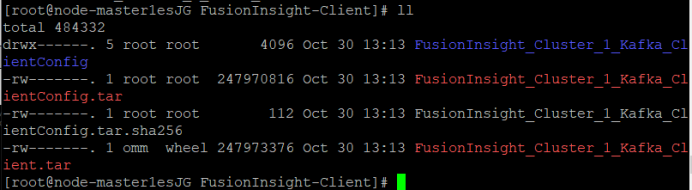
③ 安装客户端运行环境到目录“/opt/Kafka_env”(安装时自动生成目录)。
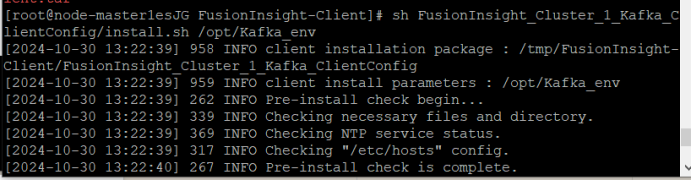
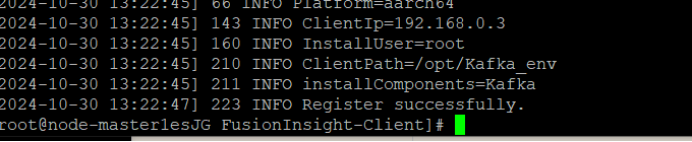
执行命令配置环境变量。
source /opt/Kafka_env/bigdata_env
3.安装Kafka客户端
① 安装Kafka到目录“/opt/KafkaClient”
系统显示以上结果表示客户端运行环境安装成功。
② 设置环境变量
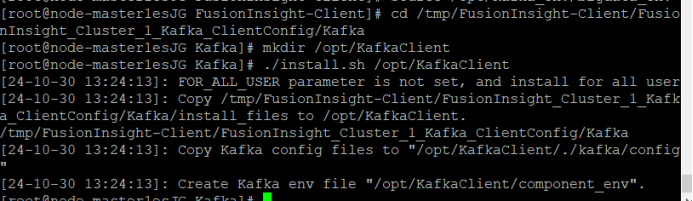
③ 在kafka中创建topic
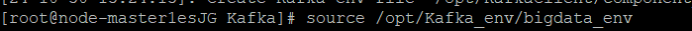
④ 查看topic信息

(三)安装Flume客户端
1.上传kafka文件压缩包
① 使用PuTTY登录到master节点服务器上,进入/tmp/FusionInsight-Client/目录。

② 执行以下命令,解压压缩包获取校验文件与客户端配置包

③ 执行命令,校验文件包。

界面显示如上信息,表明文件包校验成功。
2.安装Flume运行环境
① 解压“MRS_Flume_ClientConfig.tar”文件。
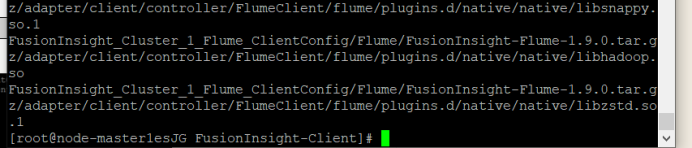
② 查看解压后文件。
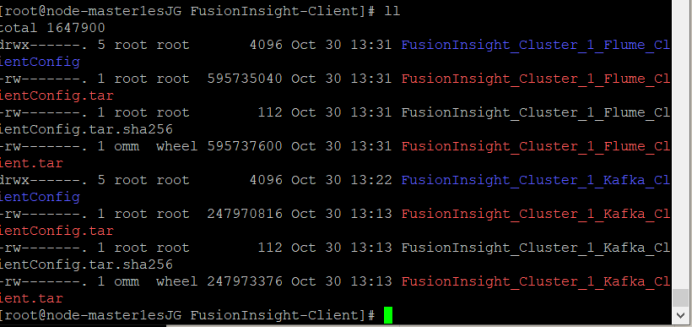
③ 安装客户端运行环境到目录“/opt/Flume_env”(安装时自动生成目录)。
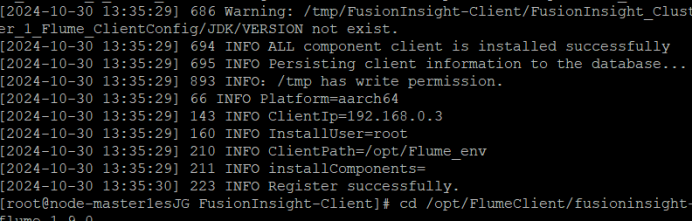
④ 执行命令配置环境变量。

3.安装Flume客户端
① 安装Flume到目录“/opt/FlumeClient”
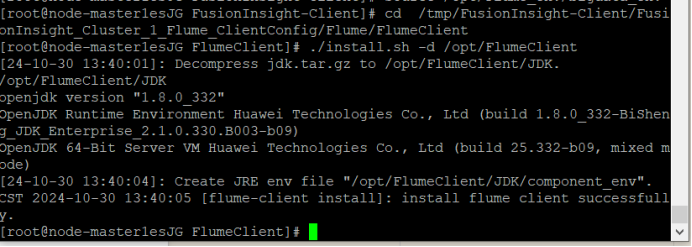
系统显示以上结果表示客户端运行环境安装成功。
② 重启Flume服务
执行以下命令重启Flume的服务。
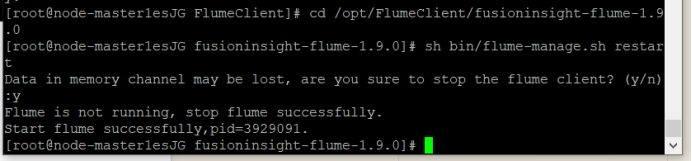
服务重启成功,安装结束!
(四)配置Flume采集数据
① 修改配置文件
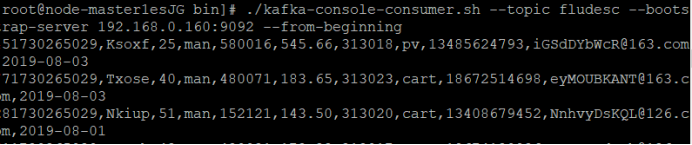
② 创建消费者消费kafka中的数据
使用PuTTY登录master节点后,执行命令(此处bootstrap-server的ip对应的是Kafka的Broker的IP):
新开一个PuTTY会话窗口。
在新弹出的会话窗口中输入用户名和密码登录。
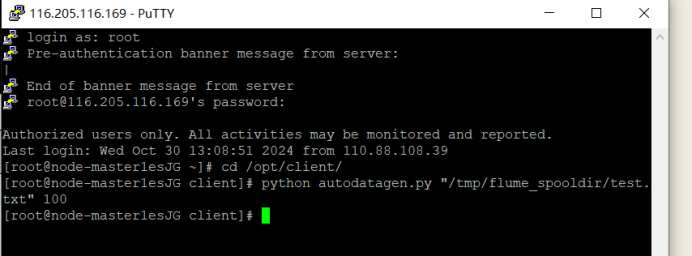
③ 进入Python脚本所在目录,执行python脚本,再生成一份数据。
查看原窗口,可以看到已经消费出了数据:
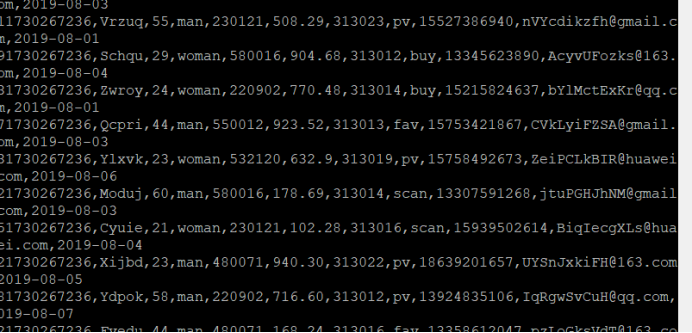
有数据产生,表明Flume到Kafka目前是打通的。
测试完毕,在新打开的窗口输入exit关闭窗口,在原窗口输入 Ctrl+c退出进程。
2)心得体会
1.学会了在华为云购买配置mrs服务器,并下载配置kafka和flink



![题解:[JOISC 2021 Day4] イベント巡り 2 (Event Hopping 2)](https://img-blog.csdnimg.cn/img_convert/3129570cb902ca18a01f509eb5799435.png)