来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: AlignSum: Data Pyramid Hierarchical Fine-tuning for Aligning with Human Summarization Preference

- 论文地址:https://arxiv.org/abs/2410.00409
- 论文代码:https://github.com/csyanghan/AlignSum
创新点
- 发现在文本摘要任务中,预训练语言模型在自动评估与人工评估中表现不一致,原因可能是低质量的训练数据。
- 考虑到标注成本,论文提出了一种新的人类摘要偏好对齐框架 \({\tt AlignSum}\) ,使用提取、
LLM生成和人工标注等多种方法构建数据金字塔,能够充分利用极其有限的高质量数据来提升预训练语言模型(PLMs)在摘要生成方面的能力极限。
内容概述
文本摘要任务通常使用预训练语言模型(PLMs)来适应各种标准数据集。尽管这些PLMs在自动评估中表现出色,但在人工评估中常常表现不佳,这表明它们生成的摘要与人类摘要偏好之间存在偏差。这种差异可能是由于低质量的微调数据集,或者是能反映真正的人类偏好的高质量人类标注数据有限。
注释大量高质量摘要数据集是不切实际的,论文希望不再依赖于对大量训练数据进行传统的简单微调,而是充分利用极其有限的高质量数据来提升预训练语言模型(PLMs)在摘要生成方面的能力极限。
为了解决这个挑战,论文提出了一种新的人类摘要偏好对齐框架 \({\tt AlignSum}\) 。该框架由三个部分组成:首先,构建一个数据金字塔,其中包含抽取式、生成式和人类标注的摘要数据。其次,进行高斯重采样,以去除极端长度的摘要。最后,在高斯重采样后实现两阶段的分层微调与数据金字塔的结合。
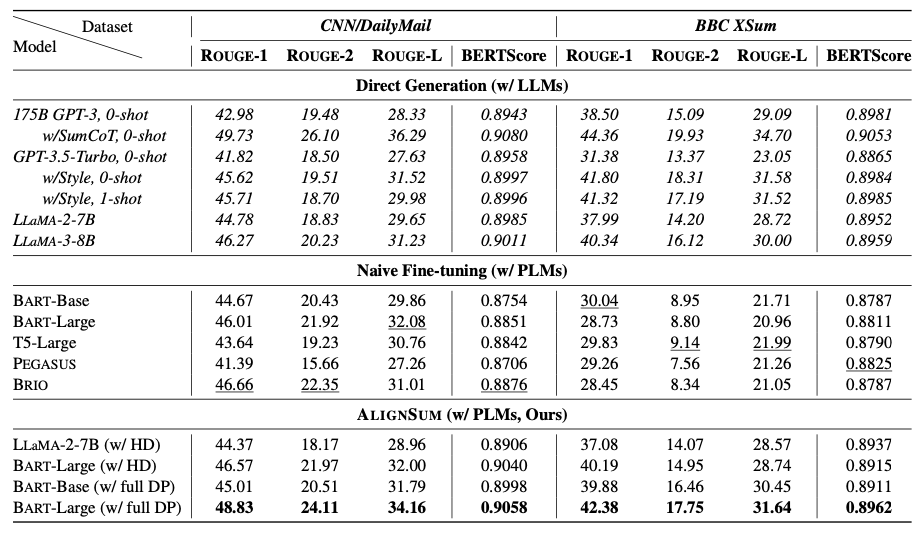
将 \({\tt AlignSum}\) 应用到人类标注的CNN/DailyMail和BBC XSum数据集中,像 BART-Large这样的PLMs在自动评估和人工评估中都超越了175B的GPT-3。这证明了 \({\tt AlignSum}\) 显著增强了语言模型与人类摘要偏好的对齐。
AlignSum
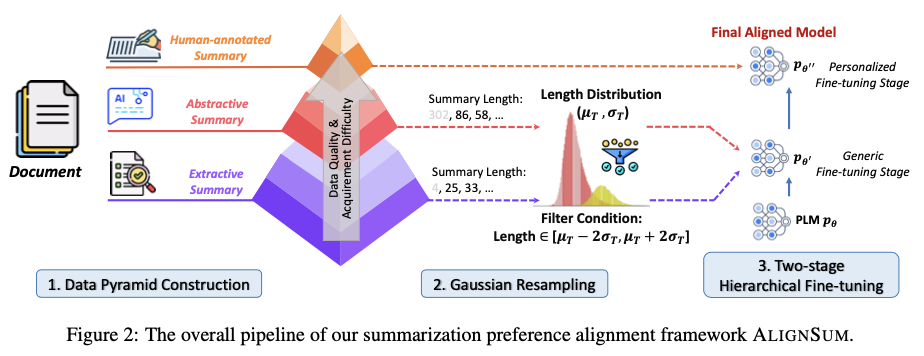
整体框架包含三个部分:
- 使用提取、
LLM生成和人工标注等多种方法构建数据金字塔(Data Pyramid)。 - 由于源数据具有不同的摘要长度,利用高斯重新采样来调整生成摘要的长度,以接近目标长度。
- 采用了两阶段的层次微调策略:初始阶段对
PLMs进行抽取式和生成式数据的训练,以适应一般领域,然后在人工标注数据上对刚刚微调过的PLMs进行进一步微调,以使其与人类偏好对齐。
构建数据金字塔

数据金字塔由三个层级组成,从下到上按质量和获取难度递增,而数量则递减。前两者是摘要生成领域中最常见的两种风格,将它们统称为通用数据。最后一层是用于对齐人类偏好的最关键部分,称之为个性化数据。
-
抽取式数据
抽取式数据构成了预训练语料库的主要部分,并且是最容易获得的。参考GSG,使用 ROUGE-1指标来计算相似性,并遍历整个文档以找到与之最相似的句子作为伪摘要 \(\hat{S}\) :
-
生成式数据
抽取式数据有助于识别文档中的重要句子,但不足以总结跨越多个句子的关键信息。相比之下,LLMs(大规模语言模型)是有效的零样本摘要生成器,能够提取跨句子及文档级别的摘要信息。
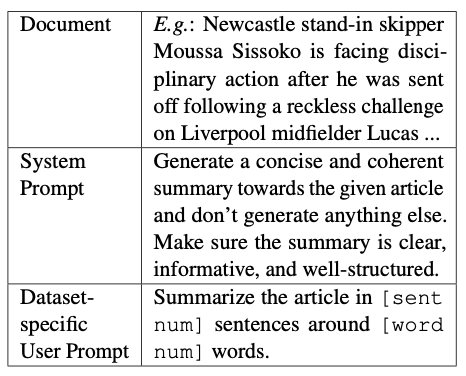
使用系统提示和用户提示引导LLMs对文档 \(D\) 进行摘要,并生成伪摘要 \(\hat{S}\) 。系统提示指定了准确摘要生成的一般要求,然后在用户提示之前插入文档,确保LLM能够阅读整个文档并遵循用户要求。用户提示是数据集特定的,设定所需的摘要长度和单词数量。
-
人类标注数据
通过使用上述两种数据进行训练,PLMs(预训练语言模型)获得了领域特定的知识。为了生成符合人类偏好的摘要,进一步在人类标注数据上进行微调是必要的。
为了避免随机注释的差异性,使用Element-aware数据集。该数据集遵循特定指令,结合了微观和宏观需求,确保一致且高质量的人类注释。
高斯重采样
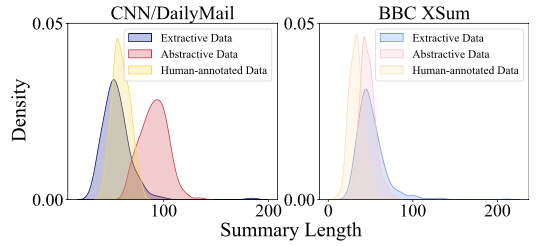
三个不同的数据源的伪摘要都有独特的标记长度分布,其中抽取式和抽象数据的摘要标记长度分布存在明显差异。因此,直接使用这些不同的分布进行训练可能会导致生成过长或过短的摘要。
为了解决这个问题,引入了高斯重采样技术,以使所有摘要长度与人类注释的摘要对齐。
将人类标注数据的标记长度分布建模为高斯分布。在95%概率的 [ \(\mu - 2\sigma\) , \(\mu + 2\sigma\) ]区间内对抽取式和抽象数据进行重采样,以去除具有过长或过短伪摘要的样本。
两阶段层级微调
直接对预训练语言模型(PLMs)进行微调可能会很具挑战性,因为少量的高熵数据对于对齐至关重要,但可能会受到大量低熵数据的信息干扰,从而导致数据金字塔的未充分利用。
为了避免这个潜在问题,论文提出两阶段的分层微调策略。给定一个预训练语言模型 \(p_{\theta}\):
- 首先通用微调阶段,使用抽取式和抽象数据对 \(p_{\theta}\) 进行微调,以增强其生成领域通用摘要的能力,从而获得模型 \(p_{\theta'}\) 。
- 接下来是个性化微调阶段,使用人类标注数据对 \(p_{\theta'}\) 进行微调,以创建与人类偏好对齐的最终模型 \(p_{\theta''}\) 。
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】