概述
在 摩尔定律 的推动下,集成电路工艺取得了高速发展,单位面积上的晶体管数量不断增加。片上系统(System-on-Chip,SoC)具有集成度高、功耗低、成本低等优势,已经成为大规模集成电路系统设计的主流方向,解决了通信、图像、计算、消费电子等领域的众多挑战性的难题。随着片上系统SoC的应用需求越来越丰富,SoC需要集成越来越多的不同应用的IP(Intellectual Property)。另外,片上多核系统MPSoC(MultiProcessor-System-on-Chip)也已经成为必然的发展趋势。
随着SoC的高度集成以及MPSoC的高速发展,对片上通信提出了更高的要求。片上网络技术(Network-on-Chip,NoC)在这个时候也得到了极大的应用,它本质上就是提供一种解决芯片内不同IP或者不同核心之间数据传输的片上通信方案。
1.1 片上互连架构的发展
片上互联架构的发展主要经历了三个阶段: 共享总线 (Bus)、 Crossbar 以及 片上网络 (NoC)。
1.1.1 BUS 共享总线结构
传统的SoC片上通信结构一般采用共享总线的方式。在共享总线结构中,所有的处理器和 IP 模块共享一条或多条总线。当有多个处理器同时访问一条总线时候需要有仲裁机制来决定总线的所有权。共享总线片上通信系统结构一般比较简单,且硬件代价也小。 但是带宽有限,而且带宽也没法随着IP的增多而进行扩展 。1996年, ARM 公司提出的AMBA总线广泛应用于嵌入式微处理器的片上总线,现在已经成为事实上的工业标准。
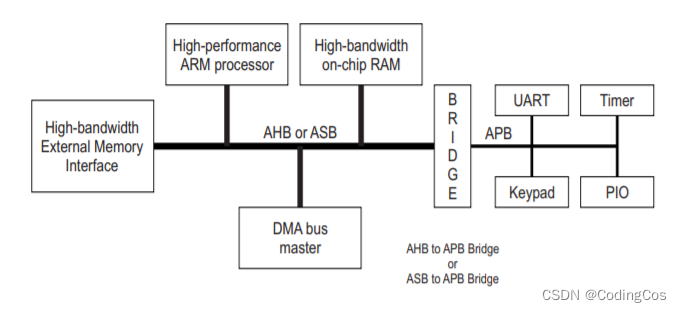
1.1.2 Crossbar 结构
对于传统的共享总线,当多个处理器同时去访问不同的 IP 的时候,因为需要仲裁机制去决定总线的所有权,所以传统的总线方式在这种情况下就会造成一定的瓶颈,最大的问题就是 访问的延时 。在这种情况下,为了满足多处理同时访问的需求和提高整个系统的带宽,一种新的解决方案 Crossbar 孕育而生,如下图 1-2 就是一个典型的 Crossbar 结构。
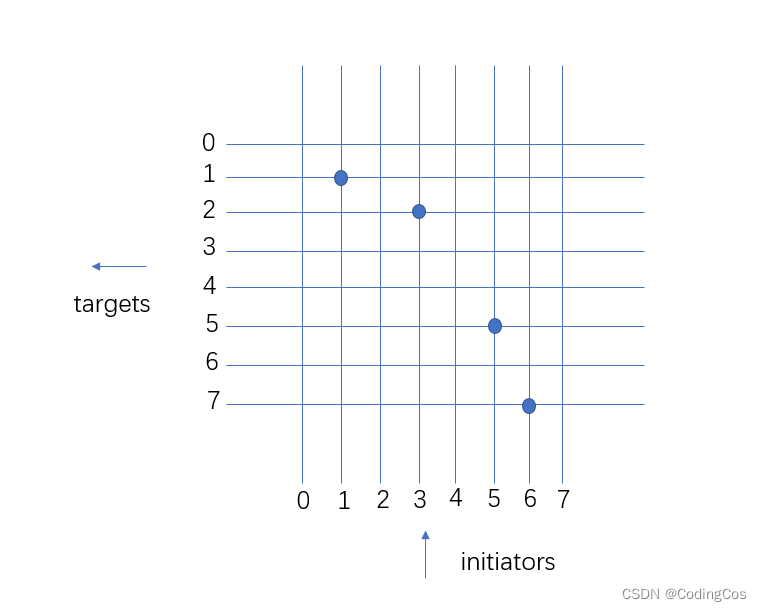
Crossbar 结构 可以同时实现多个主从设备的数据传输,也能实现一个主设备对多个从设备进行数据广播,如图1-3 所示。
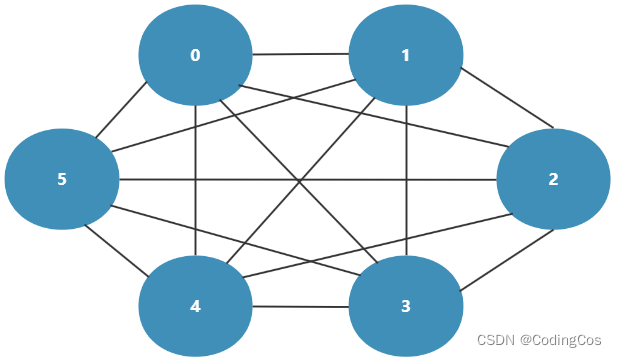
Crossbar 主要面向对超高带宽要求的系统,或者是主设备有经常向多个从设备发送广播数据需求的系统。如果互连组件太多,这种结构的内部走线会非常多,不利于物理实现,对数字后端设计带来很大挑战。
比较常见的 Crossbar 类型 IP 如 ARM 公司的 NIC-400 。
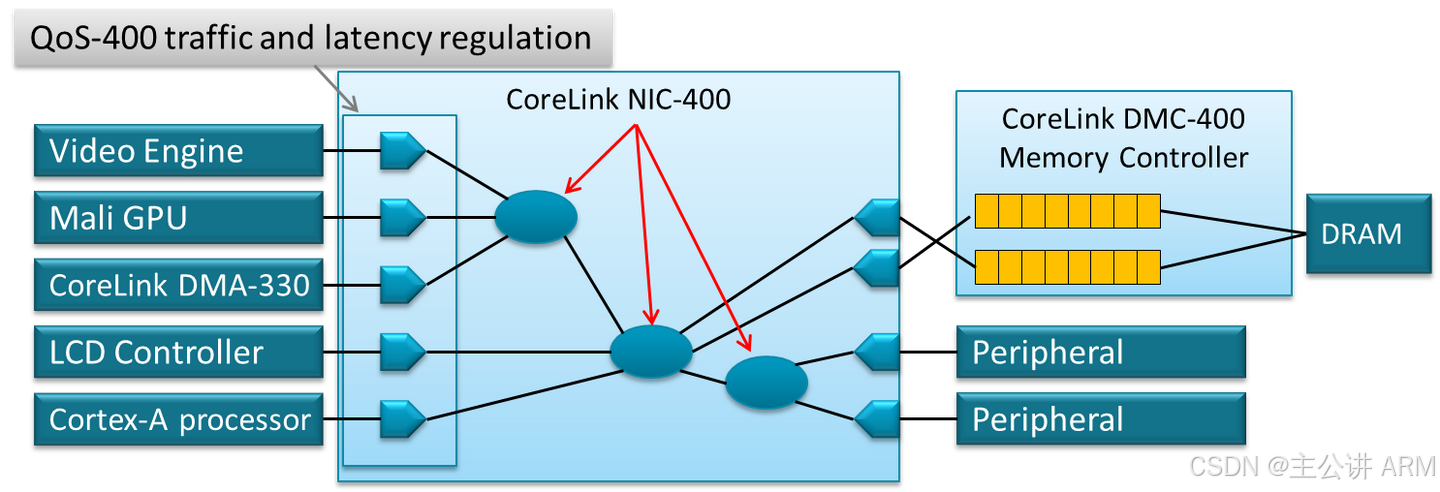
在28纳米制程上,5x4 的配置下,这个总线的频率可以跑到 300Mhz。如果进一步 增加主从对数量,那么由于扇出增加,电容和走线增加,就必须通过插入更多的寄存器来增加频率。但这样一来,从主到从的延迟就会相应增加 。要想进一步提高到频率,要么使用更好的工艺,要么插入寄存器,这样,读写延时就会增加。要知道处理器访问二级缓存的延迟通常也不过 10多 个处理器周期。所以,要达到更高的频率,支持更多的主从设备,就需要引入 环状总线CCN 系列,如下图:
1.1.3 Ring 结构
环型(Ring)结构 ,将网络中的节点首尾相连,形成一个环状,各个模块之间交互方便,不需要主控中转,功能单元通过网络接口将信息送上环,消息在环上逐个节点进行传递,每次只能前进一个节点,消息到达与目的功能单元连接的节点后被送下环,转到网络接口,进而传递给目的功能单元。
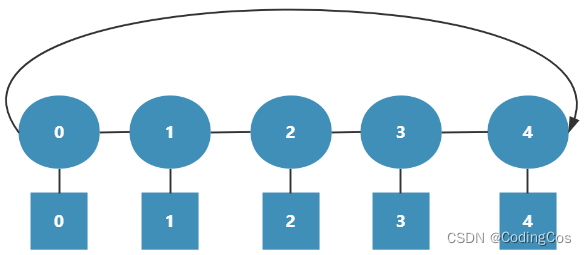
环型互联进一步划分为 单环 和 双环 ,单环只有一个方向(顺时针或逆时针),如图1-4所示,即使是相邻节点,也可能需要经过所有节点才能到达;
而双环有两个方向(顺时针和逆时针),如图1-5 所示:
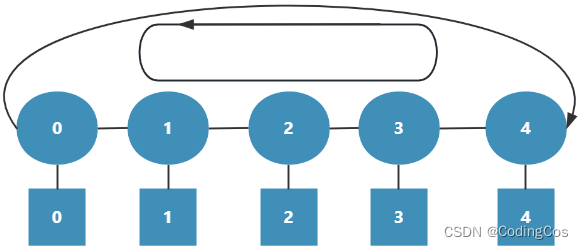
消息可以根据源和目的的距离自动选择最近的方向,这样的设计可以保证任意两个节点之间的距离不超过总数的一半。因此,有效降低延迟(相邻节点之间延迟不超过60ns),并极大提高性能(最高吞吐量可达数百G),同时方便扩展(只需在环上增加一个节点即可)。但随着内核数量的增加,环会越来越长,从而导致延迟越来越大,当内核数多于12个以后,整体性能下降明显。
比较常见的 Ring 类型 IP 如 ARM 公司的 CCN 系列 :
CCN 总线上的每一个节点,除了可以和相邻的两个节点通讯之外,还可以附加两个节点组件,比如处理器组,三级缓存,内存控制器等 。在节点内部,还是交叉的,而在节点之间,是环状的 。这样使得总线频率在某种程度上摆脱了连接设备数量的限制(当然,还是受布线等因素的影响)。当然,代价就是节点间通讯更大的平均延迟。 为了减少平均延迟,可以把经常互相访问的节点放在靠近的位置 。
在有些系统里,要求连接更多的设备,并且,频率要求更高。此时环状总线也不够用了。这时就需要 Mesh 结构出马了。## 概述
在 摩尔定律 的推动下,集成电路工艺取得了高速发展,单位面积上的晶体管数量不断增加。片上系统(System-on-Chip,SoC)具有集成度高、功耗低、成本低等优势,已经成为大规模集成电路系统设计的主流方向,解决了通信、图像、计算、消费电子等领域的众多挑战性的难题。随着片上系统SoC的应用需求越来越丰富,SoC需要集成越来越多的不同应用的IP(Intellectual Property)。另外,片上多核系统MPSoC(MultiProcessor-System-on-Chip)也已经成为必然的发展趋势。
随着SoC的高度集成以及MPSoC的高速发展,对片上通信提出了更高的要求。片上网络技术(Network-on-Chip,NoC)在这个时候也得到了极大的应用,它本质上就是提供一种解决芯片内不同IP或者不同核心之间数据传输的片上通信方案。
1.1 片上互连架构的发展
片上互联架构的发展主要经历了三个阶段: 共享总线 (Bus)、 Crossbar 以及 片上网络 (NoC)。
1.1.1 BUS 共享总线结构
传统的SoC片上通信结构一般采用共享总线的方式。在共享总线结构中,所有的处理器和 IP 模块共享一条或多条总线。当有多个处理器同时访问一条总线时候需要有仲裁机制来决定总线的所有权。共享总线片上通信系统结构一般比较简单,且硬件代价也小。 但是带宽有限,而且带宽也没法随着IP的增多而进行扩展 。1996年, ARM 公司提出的AMBA总线广泛应用于嵌入式微处理器的片上总线,现在已经成为事实上的工业标准。
1.1.2 Crossbar 结构
对于传统的共享总线,当多个处理器同时去访问不同的 IP 的时候,因为需要仲裁机制去决定总线的所有权,所以传统的总线方式在这种情况下就会造成一定的瓶颈,最大的问题就是 访问的延时 。在这种情况下,为了满足多处理同时访问的需求和提高整个系统的带宽,一种新的解决方案 Crossbar 孕育而生,如下图 1-2 就是一个典型的 Crossbar 结构。
Crossbar 结构 可以同时实现多个主从设备的数据传输,也能实现一个主设备对多个从设备进行数据广播,如图1-3 所示。
Crossbar 主要面向对超高带宽要求的系统,或者是主设备有经常向多个从设备发送广播数据需求的系统。如果互连组件太多,这种结构的内部走线会非常多,不利于物理实现,对数字后端设计带来很大挑战。
比较常见的 Crossbar 类型 IP 如 ARM 公司的 NIC-400 。
在28纳米制程上,5x4 的配置下,这个总线的频率可以跑到 300Mhz。如果进一步 增加主从对数量,那么由于扇出增加,电容和走线增加,就必须通过插入更多的寄存器来增加频率。但这样一来,从主到从的延迟就会相应增加 。要想进一步提高到频率,要么使用更好的工艺,要么插入寄存器,这样,读写延时就会增加。要知道处理器访问二级缓存的延迟通常也不过 10多 个处理器周期。所以,要达到更高的频率,支持更多的主从设备,就需要引入 环状总线CCN 系列,如下图:
1.1.3 Ring 结构
环型(Ring)结构 ,将网络中的节点首尾相连,形成一个环状,各个模块之间交互方便,不需要主控中转,功能单元通过网络接口将信息送上环,消息在环上逐个节点进行传递,每次只能前进一个节点,消息到达与目的功能单元连接的节点后被送下环,转到网络接口,进而传递给目的功能单元。
环型互联进一步划分为 单环 和 双环 ,单环只有一个方向(顺时针或逆时针),如图1-4所示,即使是相邻节点,也可能需要经过所有节点才能到达;
而双环有两个方向(顺时针和逆时针),如图1-5 所示:
消息可以根据源和目的的距离自动选择最近的方向,这样的设计可以保证任意两个节点之间的距离不超过总数的一半。因此,有效降低延迟(相邻节点之间延迟不超过60ns),并极大提高性能(最高吞吐量可达数百G),同时方便扩展(只需在环上增加一个节点即可)。但随着内核数量的增加,环会越来越长,从而导致延迟越来越大,当内核数多于12个以后,整体性能下降明显。
比较常见的 Ring 类型 IP 如 ARM 公司的 CCN 系列 :
CCN 总线上的每一个节点,除了可以和相邻的两个节点通讯之外,还可以附加两个节点组件,比如处理器组,三级缓存,内存控制器等 。在节点内部,还是交叉的,而在节点之间,是环状的 。这样使得总线频率在某种程度上摆脱了连接设备数量的限制(当然,还是受布线等因素的影响)。当然,代价就是节点间通讯更大的平均延迟。 为了减少平均延迟,可以把经常互相访问的节点放在靠近的位置 。
在有些系统里,要求连接更多的设备,并且,频率要求更高。此时环状总线也不够用了。这时就需要 Mesh 结构出马了。
1.1.4 Mesh 网格结构
二维网格(mesh),这种拓扑结构可以提供更大的带宽,而且是可以模块化,通过增加网格的行或列来增加更多的节点,ARM 的 CMN-600 就是基于 mesh 的互连 IP。
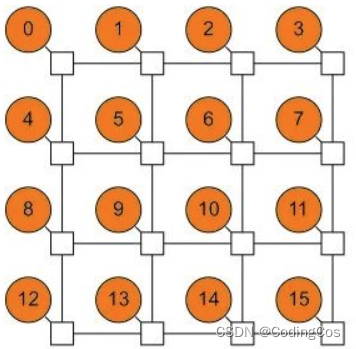
每个节点只与其同行和同列的相邻节点连接。如上图1-6所示,共有16个节点,每个节点连接一个网络接口,16个节点排列成4x4的网格。网格属于多维拓扑,至少是2维,并可以逐步扩展到3维或更高维。
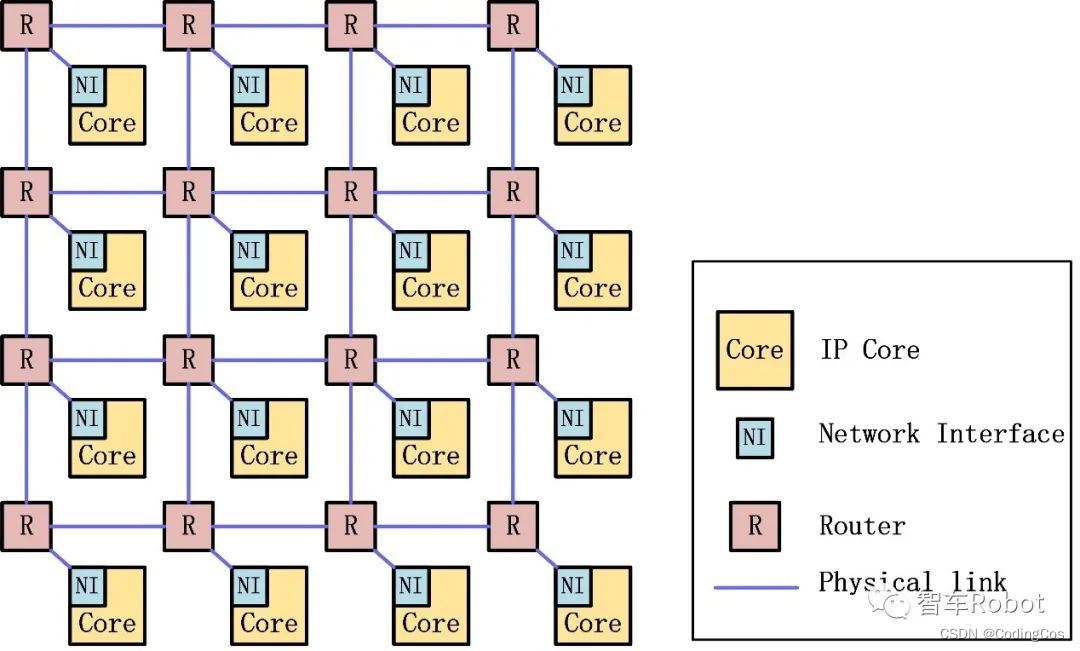
如图1-7所示,IP Core为NoC互连的组件,NI为接入NoC的接口,R为NoC中的路由器,物理链接(Physical link)为路由器之间的连接总线。
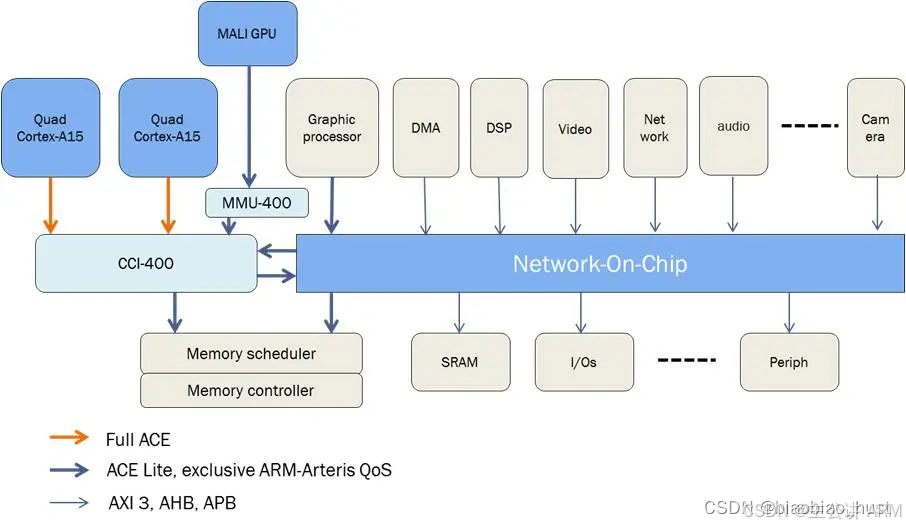
图 1-8 中,刚才提到的交叉矩阵,可以作为整个网络的某部分。而连接整个系统的,是位于NoC内的节点。每个节点都是一个小型路由, 它们之间传输的,是异步的包 。这样,就不必维持路由和路由之间很大数量的连线,从而提高频率,也能支持更多的设备。当然,坏处就是更长的延迟。并且它所连接每个子模块之间,频率和拓扑结构可以是不同的。可以把需要紧密联系的设备,比如CPU簇,GPU放在一个子网下减少通讯延迟。
NoC的优势 主要体现在如下两个方面。
- 高可扩展性。NoC类似 计算机网络 的结构,当互连的组件增加时,NoC的互连复杂度并不会增加很多。而传统的简单总线和交叉开关随着互连模块的增多,其互连复杂度呈指数级增加;
- 分层设计。NoC的物理层、传输层和接口是分开的,用户可以在传输层方便地自定义传输规则,而无须修改模块接口,传输层的更改对物理层互连的影响也不大,因此不会对NoC的时钟频率造成显著影响
AMBA 5 CHI协议可提供网络和数据中心等基础设施应用所需的性能和规模。AMBA 5 CHI协议可在单个片上系统扩展32个或更多处理器。
还有一种环面(Torus)拓扑,与网格类似,区别在于提供了同行和同列的最远端的两个节点的连线,即每行和每列都是一个环。
1.2 ARM 总线互联特点小结
在以 ARM 为主的 SoC系统,接口层和协议层采用AMBA协议标准、通信层可采用多种拓扑结构,如总线型、Ring型、Crossbar型和Mesh型等。
面向单核系统 :
- APB协议,采用总线结构,用于低速外设连接;
- AHB/AHB-Lite/AXI协议,采用总线结构,用于高速外设连
- 接。
面向多核系统 :
- NIC 技术,采用 Crossbar 结构(扩展性较强,latency比较小,因为是点到点,对memory controller对带宽分配不够灵活),没有固定拓扑, 不支持一致性 ,适用于简单场景;
- NoC 技术,采用 Mesh 结构,没有固定拓扑,采用小路由器作为节点,连线更少频率更高, 支持一致性 ,可以连接大量设备;
- CCI 技术,采用 Crossbar 结构,固定拓扑, 支持一致性 ,适用于少量处理器;
- CCN 技术,采用 Ring 结构,通过固定交叉点连成一个环,延迟大但频率高, 支持一致性 ,适用于16核以上处理器;
- CMN 技术,采用 Mesh 结构,通过固定交叉点形成 NxN 网络, 支持一致性 ,适用于更多处理器核。
1.2.1 NOC 总线互联的特点
- 无论所连接的外设是 AXI 的 CPU 或者其他CHI系列的设备,比如 DDR,或者更高协议的外设,NOC 都能够转化为内部的 packet,这些 packet 按照一定的格式在它到的拓扑结构里进行传输,也就是把标准的协议转化为内部的 package。Package 传输就会有一些特点,即使系统变的很复杂,它里面的绕线也比较少。
- NOC 总线在设计的时候就是为了解决高速信号的传输,因此很多NOC 总线都考虑到 physical awareness 的特性,也就是用工具生成NOC总线的时候,它能根据 Feature上的定义及需求 去做虚拟的 PR;
- NOC 总线对后端实现比较友好,比如支持多个 Clock domain,power domain,这些特性都是 cross bar 总线可能不具备的。所以NOC 总线可以跑在更高的频点上;
- NOC 内部 QoS 机制非常好,对带宽的分配,对不同应用场景的满足,相对于Crossbar 来讲更容易实现。
1.1.4 Mesh 网格结构
二维网格(mesh),这种拓扑结构可以提供更大的带宽,而且是可以模块化,通过增加网格的行或列来增加更多的节点,ARM 的 CMN-600 就是基于 mesh 的互连 IP。
每个节点只与其同行和同列的相邻节点连接。如上图1-6所示,共有16个节点,每个节点连接一个网络接口,16个节点排列成4x4的网格。网格属于多维拓扑,至少是2维,并可以逐步扩展到3维或更高维。
如图1-7所示,IP Core为NoC互连的组件,NI为接入NoC的接口,R为NoC中的路由器,物理链接(Physical link)为路由器之间的连接总线。




![[网鼎杯 2018]Fakebook 1](https://img2023.cnblogs.com/blog/3554714/202411/3554714-20241116120132444-1914726248.png)