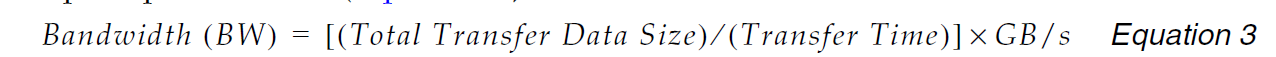内存结构
1、shared pool
缓存着sql、sql执行计划
查询shared pool大小:
select * from v$sga_dynamic_components;

2、buffer cache
缓存着数据文件里面的block
查看buffer cache里面的buffer:
select * from v$bh;

一行一个buffer
buffer里面有一个字段:TCH
用户登录上数据库以后,要访问buffer cache里面的buffer,访问的时候,访问这个buffer,访问一次,TCH就加一,对于一个buffer来说,它的TCH值越高,说明这个buffer越经常被访问,这个块就是一个热块
查看buffer cache:
select * from x$bh;

查询buffer cache大小:
select * from v$sga_dynamic_components;

3、log buffer
缓存着redo log
redo log(对数据库做的dml、ddl)
可以使用log minor这个工具去挖掘,redo log里面到底有什么
查看redo log buffer的大小:
SQL> show parameter log_buffer
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_buffer integer 6995968
4、各种pool
查看各种pool的大小:
select * from v$sga_dynamic_components;

5、SGA
SGA:就是shared pool、buffer cache、redo log buffer、各种pool加起来的一个总和(主要是shared pool和buffer cache的大小)当我们看到一种情况:就是shared pool增加的时候,buffer cache减少了,或者shared pool减少的时候,buffer cache增加,这时候说明SGA已经满了,在oracle数据库里面,默认shared pool只能增加,不能减少,所有,当PGA满了的时候,shared pool增加,buffer cache必然减少
查询SGA预算大小的剩余空间:
select * from v$sga_dynamic_free_memory;

SQL> show parameter sga_target; --查看SGA的预算值大小
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_target big integer 0SQL> show parameter sga_max; --查看SGA的最大值
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
sga_max_size big integer 1536M

图解:
假设:SGA给了10G(sga_target=10G),数据库刚启动的时候,shared pool占了500M,buffer cache占了3G,数据库刚启动的时候,一共用了3.5G,对于oracle来说,还剩6.5G的预算;随着数据库负载越来越重,shared pool会增加,因为还有预算,所以shared pool增加的时候,不会让buffer cache减少,又增加,shared pool增加到了3G,buffer cache增加到了5G,又随着时间的推移,shared pool增加到了4G,buffer cache增加到了6G,现在,10G的预算用完了,这时候还有一个参数:sag_max=12G,然后呢,shared pool用了4G,buffer cache用了6G,预算已经用完了,这时候shared pool还想增加,再要500M,但是oracle还不把buffer cache压缩,因为sag_max=12G,shared pool想再要500M,但是oracle给它200M,当shared pool和buffer cache到了12G的时候,到了最大值了,这时候,shared pool占了5G,buffer cache占了7G,shared pool再要的时候,buffer cache就要减少了,就收缩了,如果buffer cache再要呢,就不给buffer cache了
查看 SGA 大小的变化:
select * from v$sga_resize_ops;

查看buffer cache的变化情况:
select * from v$sga_resize_ops sga where sga.COMPONENT='DEFAULT buffer cache';

查看shared pool的变化情况:
select * from v$sga_resize_ops sga where sga.COMPONENT='shared pool';

6、PGA(oracle自动管理的)
用户登录上数据库以后,会产生server process,对于每一个server process,oracle都会分配一块工作空间内存给它,这块内存是server process独有的,这块内存叫PGA在oracle 9i之后的版本里,PGA是所有server process的内存合起来的一个总的内存空间每个server process在工作的时候,所需要的内存大小是不一样的,而且随着时间的变化,这块内存有时候大,有时候小,对于这种情况,oracle预算分配一个总的PGA,然后对于每一个server process来说,需要的内存不够时,oracle会分配,而内存多的话,就释放回去,需要的时候再分配;比如,现在有100个server process,每个server process需要多少内存就分配多少内存给,而如果有1000个server process的话,每个server process需要多少内存它就不会分配多少内存给了,需要10个G,可能它就分配你3个G了,相当于这个PGA超出了预算
PGA动态分配,隐含参数:pga_aggre、 workarea_size_policy
SQL> show parameter pga_aggre --查看PGA的预算值大小
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
pga_aggregate_target big integer 0

图解:
假设:PGA给了200M,用户连接上数据库以后,产生server process,每个server process分配一个PGA内存,每个PGA30M,随着时间的推移,这30M会增加,有时候会减少;比如增加到了40M,还有就是server process会越来越多(40个进程),这时候,这200M不够了,被分配完了,然后有一个进程再想要10M,但是预算已经到最大值了,oracle会给他5M,之后就不会增加那么快了,慢慢的就趋于平缓了
SQL> show parameter workarea -- 查看PGA是不是自动管理的状态
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fileio_network_adapters string
listener_networks string
workarea_size_policy string AUTO --自动
工作区:
户登录上数据库以后,会产生server process,对于每一个server process,oracle都会分配一块工作空间内存给它,这块内存是server process独有的,这块内存叫PGA,但是PGA里面最核心的是工作区,server process从buffer cache里面取出数据,先在工作区里面缓存着,缓存好以后要排好序,排序在PGA里面排,所以PGA也可以叫做server process的工作区
7、解析、执行、获取
启动当前会话对SQL语句的跟踪:
SQL> alter session set sql_trace = true;Session altered.
然后写一个sql语句,就会生成一个跟踪(trace)文件
最后关闭跟踪:
SQL> alter session set sql_trace = false;Session altered.
这样,对sql语句的一个跟踪就完成了
8、执行计划
查看shared pool里面缓存着的sql:
select * from v$sql;

查看 update sys.job$ set this_date=:1 where job=:2 这条SQL的执行计划:
SQL> select * from table(dbms_xplan.display_cursor('aq8yqxyyb40nn',0)); --aq8yqxyyb40nn:SQL语句对应的SQL_ID
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID aq8yqxyyb40nn, child number 0
-------------------------------------
update sys.job$ set this_date=:1 where job=:2Plan hash value: 2981428395---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
---------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | | | 1 (100)|
| 1 | UPDATE | JOB$ | | | |PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
|* 2 | INDEX UNIQUE SCAN| I_JOB_JOB | 1 | 5 | 0 (0)|---------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------2 - access("JOB"=:2)19 rows selected.
有了统计信息才能生成执行计划
9、统计信息
select object_name from t1 where object_id=110;
解析时候,需要知道表和索引的统计信息,默认是没有的,需要手工收集
10、参数文件
[oracle@db11g 11.2.0]$ cd $ORACLE_HOME[oracle@db11g db_1]$ cd dbs[oracle@db11g dbs]$ ls
hc_orcl.dat init.ora lkORCL orapworcl spfileorcl.ora --参数文件查看参数文件内容:
[oracle@db11g dbs]$ strings spfileorcl.ora
orcl.__db_cache_size=587202560
orcl.__java_pool_size=16777216
orcl.__large_pool_size=33554432
orcl.__oracle_base='/u01/app/oracle'#ORACLE_BASE set from environment
orcl.__pga_aggregate_target=654311424orcl.__sga_target=956301312
orcl.__shared_io_pool_size=0orcl.__shared_pool_size=301989888
orcl.__streams_pool_size=0*.audit_file_dest='/u01/app/oracle/admin/orcl/adump'
*.audit_trail='db'
*.compatible='11.2.0.4.0'
*.control_files='/oradata/orcl/control01.ctl','/oradata/orcl/control02.ctl'
*.db_block_size=8192
*.db_domain=''
*.db_name='orcl'
*.diagnostic_dest='/u01/app/oracle'
*.dispatchers='(PROTOCOL=TCP) (SERVICE=orclXDB)'
*.memory_target=1605369856
*.open_cursors=300
*.processes=1200
*.remote_login_passwordfile='EXCLUSIVE'
*.sessions=1325
*.undo_tablespace='UNDOTBS1'
11、控制文件
[oracle@db11g dbs]$ cd /oradata/orcl
[oracle@db11g orcl]$ ls
control01.ctl redo01.log redo03.log system01.dbf undotbs01.dbf --control01.ctl:控制文件
control02.ctl redo02.log sysaux01.dbf temp01.dbf users01.dbf
查看控制文件内容:
[oracle@db11g orcl]$ strings control01.ctl
}|{z
VORCL
t7ORCL
t7ORCL
j "6
orcl
orcl
/oradata/orcl/redo03.log
/oradata/orcl/redo02.log
/oradata/orcl/redo01.log
/oradata/orcl/users01.dbf
/oradata/orcl/undotbs01.dbf
/oradata/orcl/sysaux01.dbf
/oradata/orcl/system01.dbf
/oradata/orcl/temp01.dbf
/oradata/orcl/redo03.log
/oradata/orcl/redo02.log
/oradata/orcl/redo01.log
/oradata/orcl/users01.dbf
/oradata/orcl/undotbs01.dbf
/oradata/orcl/sysaux01.dbf
/oradata/orcl/system01.dbf
/oradata/orcl/temp01.dbf --数据库的物理结构
SYSTEM
SYSAUX
UNDOTBS1
USERS
TEMP
SYSTEM
SYSAUX
UNDOTBS1
USERS
TEMP
{Mu7
{Mu7
S>{7
S>{7-s
{Mu7
{Mu7
S>{7
S>{7-s
orcl
orcl
orcl
UNNAMED_INSTANCE_2
UNNAMED_INSTANCE_3
UNNAMED_INSTANCE_4
UNNAMED_INSTANCE_5
UNNAMED_INSTANCE_6
UNNAMED_INSTANCE_7
UNNAMED_INSTANCE_8
orcl
UNNAMED_INSTANCE_2
UNNAMED_INSTANCE_3
UNNAMED_INSTANCE_4
UNNAMED_INSTANCE_5
UNNAMED_INSTANCE_6
UNNAMED_INSTANCE_7
UNNAMED_INSTANCE_8
ACM unit testing operation
LSB Database Guard
Supplemental Log Data DDL
LSB Role Change Support
RFS block and kill across RAC
RAC-wide SGA
ACM unit testing operation
LSB Database Guard
Supplemental Log Data DDL
LSB Role Change Support
RFS block and kill across RAC
RAC-wide SGA
12、硬解析、软解析
递归SQL:
图解:
SQL A第一次执行,要硬解析A,但是要解析A之前,先解析了B,解析完B之后,然后再回来解析A,最后再执行A

所以查看解析总次数的时候,解析一条sql,总次数增加了2
13、物理读、内存读(select(consistant read)、dml(current read))
清空buffer cache里面的buffer:
SQL> alter system flush buffer_cache;
System altered.
清空buffer之后,任何一次从buffer cache里面读数据,都要产生物理读
进程结构
前台进程:server process
用户的每一个连接对应着一个server process
查看server process进程:
[oracle@db11g orcl]$ ps -ef |grep local
oracle 10071 8311 0 08:46 pts/0 00:00:00 grep local -- 本地连接的server process进程
在操作系统层面,server process是有一个进程编号的,叫:spid
在数据库层面,用户登录数据库以后,对数据库来讲,它是建立了一个会话,这个会话也有一个编号,是:sid和serial#
查看oracle有多少个会话:
select sid,serial#,username from v$session where username is not null;

查看会话对应的编号:
select spid,username from v$process where addr in (select paddr from v$session where username is not null);

PGA动态分配、隐含参数
PGA动态分配
SQL> show parameter workarea
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
workarea_size_policy string AUTO
查看PGA预算值大小:
SQL> show parameter pga_aggre
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
pga_aggregate_target big integer 0
查看每个会话分配的PGA大小:
select y.username,x.PGA_USED_MEM,x.PGA_ALLOC_MEM,x.PGA_MAX_MEMfrom v$process x,v$session ywhere x.addr=y.paddrand y.USERNAME is not null;

PGA隐含参数
此命令可以查PGA的隐含参数:
SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describFROM SYS.x$ksppi x, SYS.x$ksppcv yWHERE x.inst_id = USERENV ('Instance')AND y.inst_id = USERENV ('Instance')AND x.indx = y.indxAND x.ksppinm LIKE '%&par%'
1、_PGA_MAX_SIZE
The parameter _PGA_MAX_SIZE limits the maximum size of all work areas for a single process.
查看一个server process PGA最大的大小:
SQL> SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describ
FROM SYS.x$ksppi x, SYS.x$ksppcv y
WHERE x.inst_id = USERENV ('Instance')
AND y.inst_id = USERENV ('Instance')
AND x.indx = y.indx
AND x.ksppinm LIKE '%&par%';Enter value for par: _pga_max_size
old 6: AND x.ksppinm LIKE '%&par%'
new 6: AND x.ksppinm LIKE '%_pga_max_size%'NAME VALUE DESCRIB
------------- --------- ----------------------------------------------
_pga_max_size 209715200 Maximum size of the PGA memory for one process
一个用户登录数据库以后,每个server process的PGA大小:
1、_PGA_MAX_SIZE最大分配不能超过200M;
2、_PGA_MAX_SIZE不能超过预算的5%;
两者取最严格那个,也就是取小的那个
2、_SMM_MAX_SIZE
The parameter _SMM_MAX_SIZE limits the maximum size of an individual work area for a single process.
查看server process PGA一个工作区的最大大小:
SQL> SELECT x.ksppinm NAME, y.ksppstvl VALUE, x.ksppdesc describ
FROM SYS.x$ksppi x, SYS.x$ksppcv y
WHERE x.inst_id = USERENV ('Instance')
AND y.inst_id = USERENV ('Instance')
AND x.indx = y.indx6 AND x.ksppinm LIKE '%&par%';Enter value for par: _smm_max_size
old 6: AND x.ksppinm LIKE '%&par%'
new 6: AND x.ksppinm LIKE '%_smm_max_size%'NAME VALUE DESCRIB
-------------------- ------ ------------------------------------------------------
_smm_max_size_static 102400 static maximum work area size in auto mode (serial)
_smm_max_size 102400 maximum work area size in auto mode (serial)
SQL执行时,每个排序都分配一个工作空间,比如:一条SQL里有两个排序,就有两个工作空间,每个工作空间不能超过PGA工作空间的最大值
3、_SMM_PX_MAX_SIZE
_SMM_PX_MAX_SIZE限制的是:并行执行时所使用的最大内存大小当执行并行操作时,单个排序操作所能使用的最大内存受_SMM_MAX_SIZE限制,同时所有并行进程的所有排序操作所能使用的内存总和受_SMM_PX_MAX_SIZE参数的限制
![为什么需要[EnumeratorCancellation]?](https://img2024.cnblogs.com/blog/233608/202411/233608-20241118104208981-1418480728.png)