在大数据时代,数据的价值不言而喻。数据爬取是获取数据的第一步,但爬取后的数据往往包含噪声、缺失值
和不一致性,这就需要进行数据清洗。清洗后的数据可以用于进一步的分析,以提取有价值的信息和知识。本
文将介绍数据爬取后的数据清洗和分析流程,并提供代码示例。

数据清洗的重要性
数据清洗是数据分析的前提,其目的是确保数据的质量和一致性。清洗后的数据可以减少分析过程中的错误,
提高分析结果的准确性和可靠性。
数据清洗的步骤
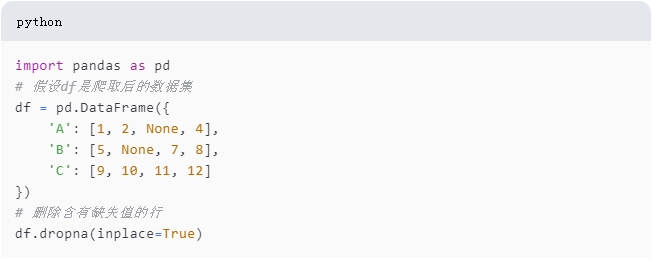
1. 删除缺失值
数据集中的缺失值可能会干扰分析结果。我们可以使用Pandas库中的dropna()方法删除含有缺失值的行或列。
2. 填充缺失值
有时候删除缺失值并不是最佳选择,我们可以选择填充缺失值。常见的填充方法包括使用均值、中位数、众数等。

3. 删除重复值
数据集中可能会有重复的记录,这些重复记录会影响分析结果。我们可以使用drop_duplicates()方法删除重复值。

4. 特征选择
特征选择是从原始特征中选择出对模型构建最有用的特征。在Python中,可以使用Scikit-learn库的SelectKBest
类进行特征选择。

数据分析的步骤
1. 数据可视化
数据可视化是理解数据分布和模式的重要手段。Matplotlib是Python中最常用的可视化库之一。

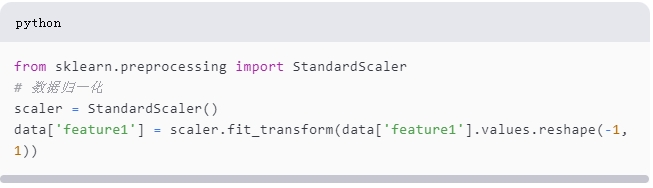
2. 数据变换
数据变换是将数据转换为适合分析的格式。Scikit-Learn库提供了许多用于数据预处理的功能,如特征缩放、编码和
归一化。
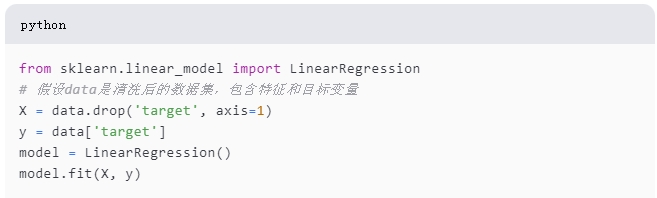
3. 构建模型
在数据清洗和变换后,我们可以构建模型来进行预测或分类。
结论
数据清洗和分析是数据科学中的关键步骤。通过有效的数据清洗,我们可以提高数据的质量,为后续的分析打下坚实的
基础。而数据分析则可以帮助我们从数据中提取有价值的信息,支持决策和发现知识。通过上述代码示例,我们可以看
到使用Python进行数据清洗和分析的流程是清晰和高效的。