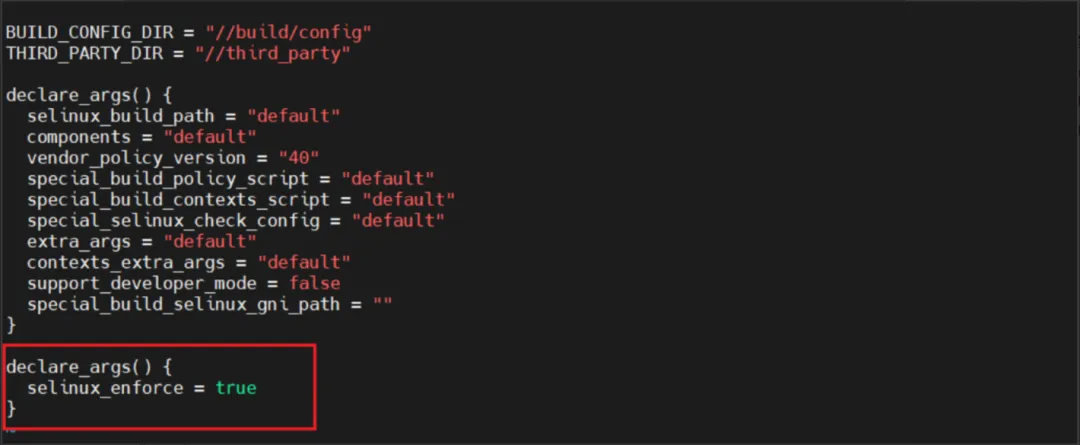
作业内容
作业①:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
Gitee文件夹链接https://gitee.com/xu-xuan2568177992/crawl_project/tree/master/4
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pymysql
chrome_driver_path = r"C:\Users\xxy\AppData\Local\Programs\Python\Python310\Scripts\chromedriver.exe"
service = Service(executable_path=chrome_driver_path)
options = Options()
options.add_argument('--disable-gpu')
options.add_argument('--disable-blink-features=AutomationControlled')
driver = webdriver.Chrome(service=service, options=options)
driver.maximize_window()# 连接scrapy数据库,创建表
try:db = pymysql.connect(host='127.0.0.1',user='root',password='xxy4113216923',port=3306,database='scrapy')cursor = db.cursor()cursor.execute('DROP TABLE IF EXISTS stockT')sql = '''CREATE TABLE stockT(num varchar(32),id varchar(12),name varchar(32),Latest_quotation varchar(32),Chg varchar(12),up_down_amount varchar(12),turnover varchar(16),transaction_volume varchar(16),amplitude varchar(16),highest varchar(32), lowest varchar(32),today varchar(32),yesterday varchar(32))'''cursor.execute(sql)
except Exception as e:print(e)def spider(page_num):cnt = 0while cnt < page_num:spiderOnePage()driver.find_element(By.XPATH,'//a[@class="next paginate_button"]').click()cnt +=1time.sleep(2)# 爬取一个页面的数据
def spiderOnePage():time.sleep(3)trs = driver.find_elements(By.XPATH,'//table[@id="table_wrapper-table"]//tr[@class]')for tr in trs:tds = tr.find_elements(By.XPATH,'.//td')num = tds[0].textid = tds[1].textname = tds[2].textLatest_quotation = tds[6].textChg = tds[7].textup_down_amount = tds[8].textturnover = tds[9].texttransaction_volume = tds[10].textamplitude = tds[11].texthighest = tds[12].textlowest = tds[13].texttoday = tds[14].textyesterday = tds[15].textcursor.execute('INSERT INTO stockT VALUES ("%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s")' % (num,id,name,Latest_quotation,Chg,up_down_amount,turnover,transaction_volume,amplitude,highest,lowest,today,yesterday))db.commit()# 访问东方财富网
driver.get('https://quote.eastmoney.com/center/gridlist.html#hs_a_board')
# 访问沪深京A股
driver.get(WebDriverWait(driver,10,0.48).until(EC.presence_of_element_located((By.ID,'menu_hs_a_board'))).get_attribute('href'))
# 爬取两页的数据
spider(2)
driver.back()# 访问上证A股
driver.get(WebDriverWait(driver,10,0.48).until(EC.presence_of_element_located((By.ID,'menu_sh_a_board'))).get_attribute('href'))
spider(2)
driver.back()# 访问深证A股
driver.get(WebDriverWait(driver,10,0.48).until(EC.presence_of_element_located((By.ID,'menu_sz_a_board'))).get_attribute('href'))
spider(2)try:cursor.close()db.close()
except:pass
time.sleep(3)
driver.quit()
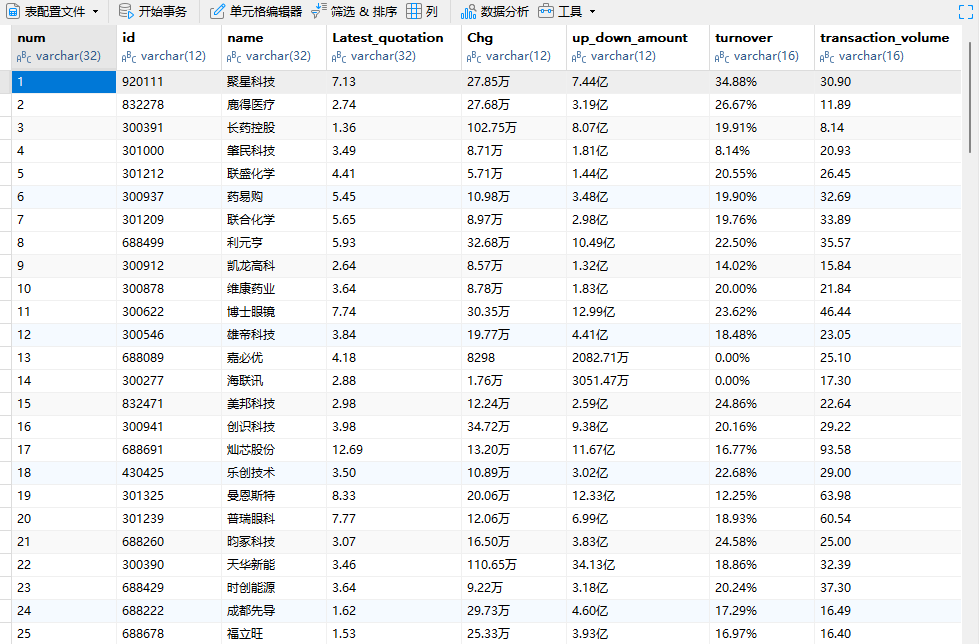
实验结果:
实验心得:
通过本次作业,我深入掌握了 Selenium 相关操作,包括查找元素、处理 Ajax 数据和等待元素。设计 MySQL 表头让我明白数据存储结构的重要性。过程有挑战,如东方财富网页结构变化和数据存储问题,但提升了编程和处理数据能力,对类似任务有很大帮助。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
Gitee文件夹链接https://gitee.com/xu-xuan2568177992/crawl_project/tree/master/4
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import pymysqlchrome_driver_path = r"C:\Users\xxy\AppData\Local\Programs\Python\Python310\Scripts\chromedriver.exe"
service = Service(executable_path=chrome_driver_path)
options = Options()
options.add_argument('--disable-gpu')
options.add_argument('--disable-blink-features=AutomationControlled')
driver = webdriver.Chrome(service=service, options=options)
driver.maximize_window()
# 连接MySql
try:db = pymysql.connect(host='127.0.0.1', user='root', password='xxy4113216923', port=3306, database='scrapy')cursor = db.cursor()cursor.execute('DROP TABLE IF EXISTS courseMessage')sql = '''CREATE TABLE courseMessage(cCourse varchar(64),cCollege varchar(64),cTeacher varchar(16),cTeam varchar(256),cCount varchar(16),cProcess varchar(32),cBrief varchar(2048))'''cursor.execute(sql)
except Exception as e:print(e)# 爬取一个页面的数据
def spiderOnePage():time.sleep(5) # 等待页面加载完成courses = driver.find_elements(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div')current_window_handle = driver.current_window_handlefor course in courses:cCourse = course.find_element(By.XPATH, './/h3').text # 课程名cCollege = course.find_element(By.XPATH, './/p[@class="_2lZi3"]').text # 大学名称cTeacher = course.find_element(By.XPATH, './/div[@class="_1Zkj9"]').text # 主讲老师cCount = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/span').text # 参与该课程的人数cProcess = course.find_element(By.XPATH, './/div[@class="jvxcQ"]/div').text # 课程进展course.click() # 点击进入课程详情页,在新标签页中打开Handles = driver.window_handles # 获取当前浏览器的所有页面的句柄driver.switch_to.window(Handles[1]) # 跳转到新标签页time.sleep(5) # 等待页面加载完成# 爬取课程详情数据# cBrief = WebDriverWait(driver,10,0.48).until(EC.presence_of_element_located((By.ID,'j-rectxt2'))).textcBrief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').textif len(cBrief) == 0:cBriefs = driver.find_elements(By.XPATH, '//*[@id="content-section"]/div[4]/div//*')cBrief = ""for c in cBriefs:cBrief += c.text# 将文本中的引号进行转义处理,防止插入表格时报错cBrief = cBrief.replace('"', r'\"').replace("'", r"\'")cBrief = cBrief.strip()# 爬取老师团队信息nameList = []cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')for Teacher in cTeachers:name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()nameList.append(name)# 如果有下一页的标签,就点击它,然后继续爬取nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')while len(nextButton) != 0:nextButton[0].click()time.sleep(3)cTeachers = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_con_item"]')for Teacher in cTeachers:name = Teacher.find_element(By.XPATH, './/h3[@class="f-fc3"]').text.strip()nameList.append(name)nextButton = driver.find_elements(By.XPATH, '//div[@class="um-list-slider_next f-pa"]')cTeam = ','.join(nameList)driver.close() # 关闭新标签页driver.switch_to.window(current_window_handle) # 跳转回原始页面try:cursor.execute('INSERT INTO courseMessage VALUES ("%s","%s","%s","%s","%s","%s","%s")' % (cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))db.commit()except Exception as e:print(e)# 访问中国大学慕课
driver.get('https://www.icourse163.org/')# 访问国家精品课程
driver.get(WebDriverWait(driver, 10, 0.48).until(EC.presence_of_element_located((By.XPATH, '//*[@id="app"]/div/div/div[1]/div[1]/div[1]/span[1]/a'))).get_attribute('href'))
spiderOnePage() # 爬取第一页的内容count = 1
'''翻页操作'''
# 下一页的按钮
next_page = driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')
# 如果还有下一页,那么该标签的class属性为_3YiUU
while next_page.get_attribute('class') == '_3YiUU ':if count == 3:breakcount += 1next_page.click() # 点击按钮实现翻页spiderOnePage() # 爬取一页的内容next_page = driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]')try:cursor.close()db.close()
except:passtime.sleep(3)
driver.quit()
实验结果:

实验心得:
此次作业让我对 Selenium 有了新认识,模拟登录很关键。爬取 mooc 网课程信息使我在数据提取和存储上有了更多实践经验,也提高了应对复杂网页结构的能力,有助于今后的爬虫工作。
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
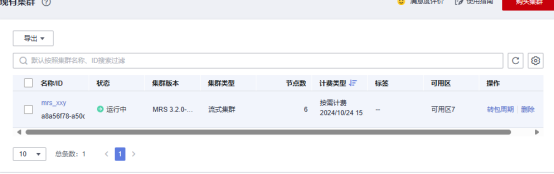
绑定弹性公网ip

实时分析开发实战:
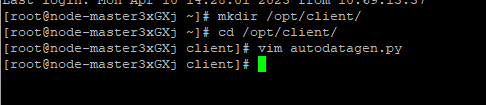
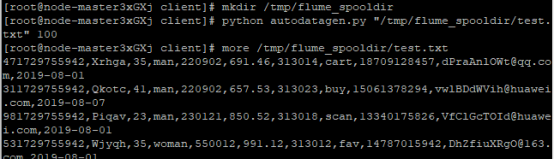
任务一:Python脚本生成测试数据
任务二:配置Kafka
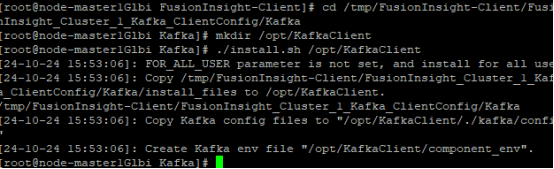
安装kafka客户端
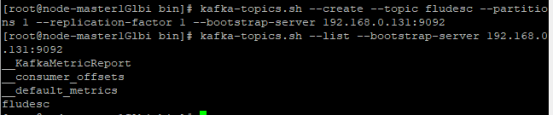
在kafka中创建topic
任务三: 安装Flume客户端
安装 flume运行环境


安装flume客户端
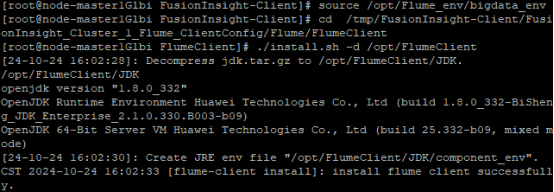
重启flume服务

任务四:配置Flume采集数据

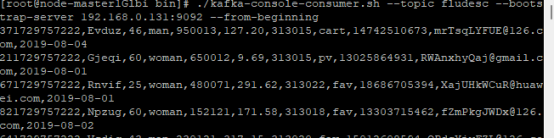
心得体会:
这次作业让我掌握了大数据相关服务和 Xshell 使用。环境搭建与实时分析开发实战的各项任务,如开通服务、脚本生成数据、配置 Kafka 和 Flume 等,让我熟悉了大数据处理流程,虽有困难,但收获巨大。