| 课程链接 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology |
|---|---|
| 作业链接 | https://edu.cnblogs.com/campus/fzu/2024DataCollectionandFusiontechnology/homework/13288 |
| gitee仓库链接 | https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践4 |
作业一
- 数据采集实验
gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践4/作业1
实验要求:熟练掌握 Selenium 查找HTML元素爬取Ajax网页数据等待HTML元素等内容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取沪深 A 股、上证 A 股、深证A股3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
源码链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践4/作业1/作业1.py
作业运行代码
点击查看代码
import sqlite3
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import os
def main():# 配置Chrome选项chrome_options = Options()chrome_options.add_argument('--disable-gpu')chrome_options.add_argument('--no-sandbox')chrome_options.add_argument('--disable-dev-shm-usage')chrome_options.add_argument('--window-size=1920,1080')# 使用Python38的Scripts目录chromedriver_path = r'C:\Python38\Scripts\chromedriver.exe'service = Service(chromedriver_path)driver = webdriver.Chrome(service=service, options=chrome_options)# SQLite数据库文件路径db_path = 'stock.db'try:# 创建数据库和表create_database_and_tables(db_path)# 爬取三个板块的数据urls = {'hs_a_stock': 'http://quote.eastmoney.com/center/gridlist.html#hs_a_board','sh_a_stock': 'http://quote.eastmoney.com/center/gridlist.html#sh_a_board','sz_a_stock': 'http://quote.eastmoney.com/center/gridlist.html#sz_a_board'}for table_name, url in urls.items():print(f"正在爬取{table_name}数据...")stock_data = get_stock_data(driver, url)if stock_data:save_to_sqlite(stock_data, table_name, db_path)time.sleep(3)except Exception as e:print(f"程序运行出错:{str(e)}")finally:driver.quit()
def create_database_and_tables(db_path):"""创建SQLite数据库和表"""conn = sqlite3.connect(db_path)cursor = conn.cursor()try:# 创建三个表tables = {'hs_a_stock': '沪深A股','sh_a_stock': '上证A股','sz_a_stock': '深证A股'}for table_name, description in tables.items():create_table_sql = f"""CREATE TABLE IF NOT EXISTS {table_name} (id INTEGER PRIMARY KEY AUTOINCREMENT,stock_code TEXT,stock_name TEXT,latest_price REAL,change_percent REAL,change_amount REAL,volume REAL,turnover REAL,amplitude REAL,high_price REAL,low_price REAL,open_price REAL,prev_close REAL,update_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP);"""cursor.execute(create_table_sql)print(f"表 {table_name} 创建成功")conn.commit()finally:cursor.close()conn.close()
def get_stock_data(driver, url):"""获取股票数据"""try:driver.get(url)time.sleep(5) # 等待页面加载# 等待表格元素出现wait = WebDriverWait(driver, 10)table = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'table_wrapper-table')))# 获取所有行rows = table.find_elements(By.TAG_NAME, 'tr')stock_data = []for row in rows[1:]: # 跳过表头cols = row.find_elements(By.TAG_NAME, 'td')if len(cols) >= 13:stock = {'stock_code': cols[1].text,'stock_name': cols[2].text,'latest_price': convert_to_float(cols[3].text),'change_percent': convert_to_float(cols[4].text.strip('%')),'change_amount': convert_to_float(cols[5].text),'volume': convert_volume(cols[6].text),'turnover': convert_volume(cols[7].text),'amplitude': convert_to_float(cols[8].text.strip('%')),'high_price': convert_to_float(cols[9].text),'low_price': convert_to_float(cols[10].text),'open_price': convert_to_float(cols[11].text),'prev_close': convert_to_float(cols[12].text)}stock_data.append(stock)return stock_dataexcept Exception as e:print(f"获取股票数据时出错:{str(e)}")return []
def save_to_sqlite(stock_data, table_name, db_path):"""保存数据到SQLite"""if not stock_data:returnconn = sqlite3.connect(db_path)cursor = conn.cursor()try:# 清空原有数据cursor.execute(f"DELETE FROM {table_name}")# 插入新数据insert_sql = f"""INSERT INTO {table_name} (stock_code, stock_name, latest_price, change_percent,change_amount, volume, turnover, amplitude,high_price, low_price, open_price, prev_close) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)"""values = [(stock['stock_code'], stock['stock_name'], stock['latest_price'],stock['change_percent'], stock['change_amount'], stock['volume'],stock['turnover'], stock['amplitude'], stock['high_price'],stock['low_price'], stock['open_price'], stock['prev_close']) for stock in stock_data]cursor.executemany(insert_sql, values)conn.commit()print(f"成功保存 {len(stock_data)} 条数据到 {table_name}")except Exception as e:conn.rollback()print(f"保存数据时出错:{str(e)}")finally:cursor.close()conn.close()
def convert_to_float(value):"""转换字符串为浮点数"""try:return float(value)except (ValueError, TypeError):return 0.0def convert_volume(value):"""转换成交量/成交额"""try:if '万' in value:return float(value.replace('万', '')) * 10000elif '亿' in value:return float(value.replace('亿', '')) * 100000000return float(value)except (ValueError, TypeError):return 0.0
if __name__ == "__main__":main()
数据库gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践4/作业1/stock.db
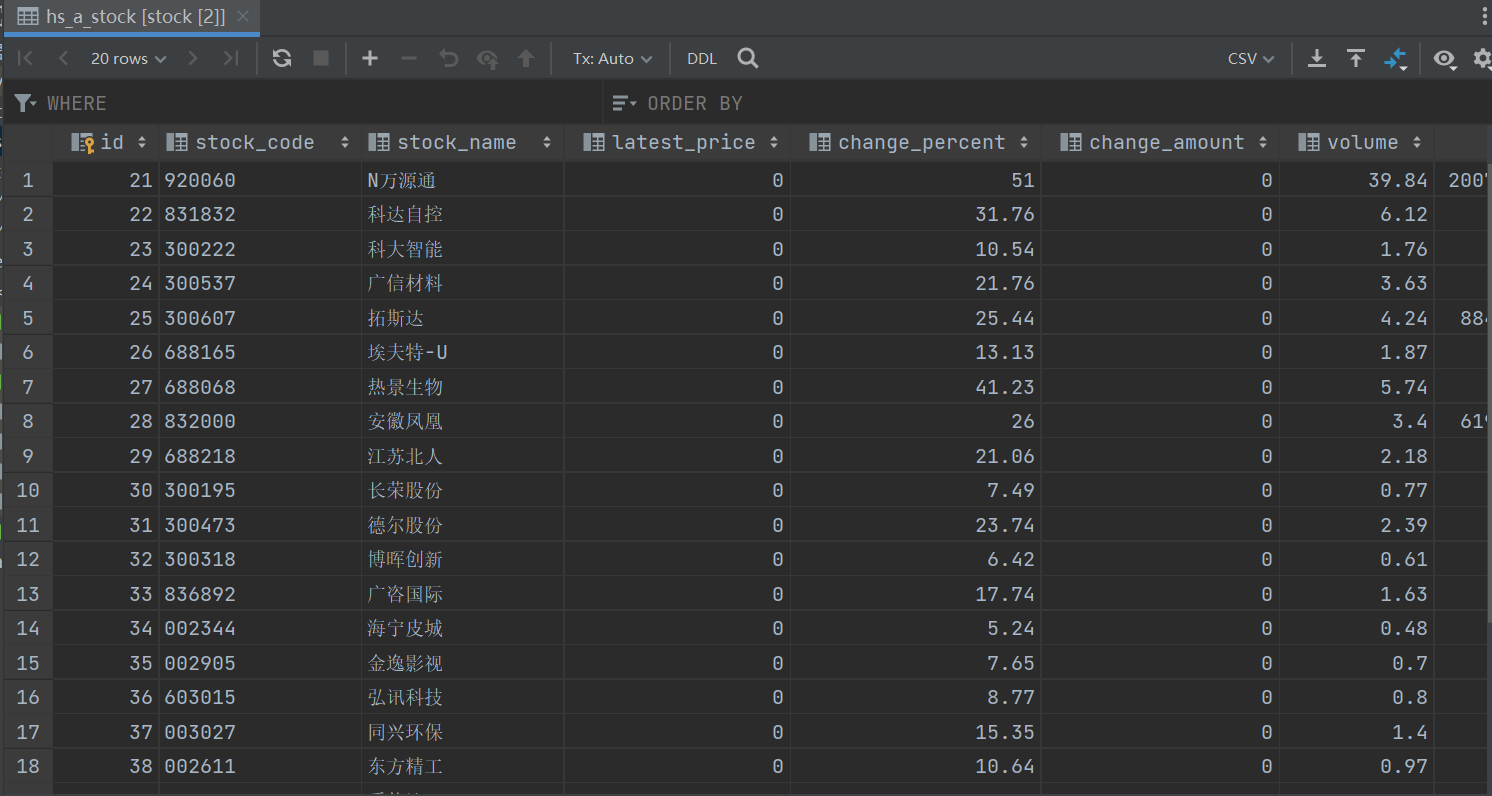
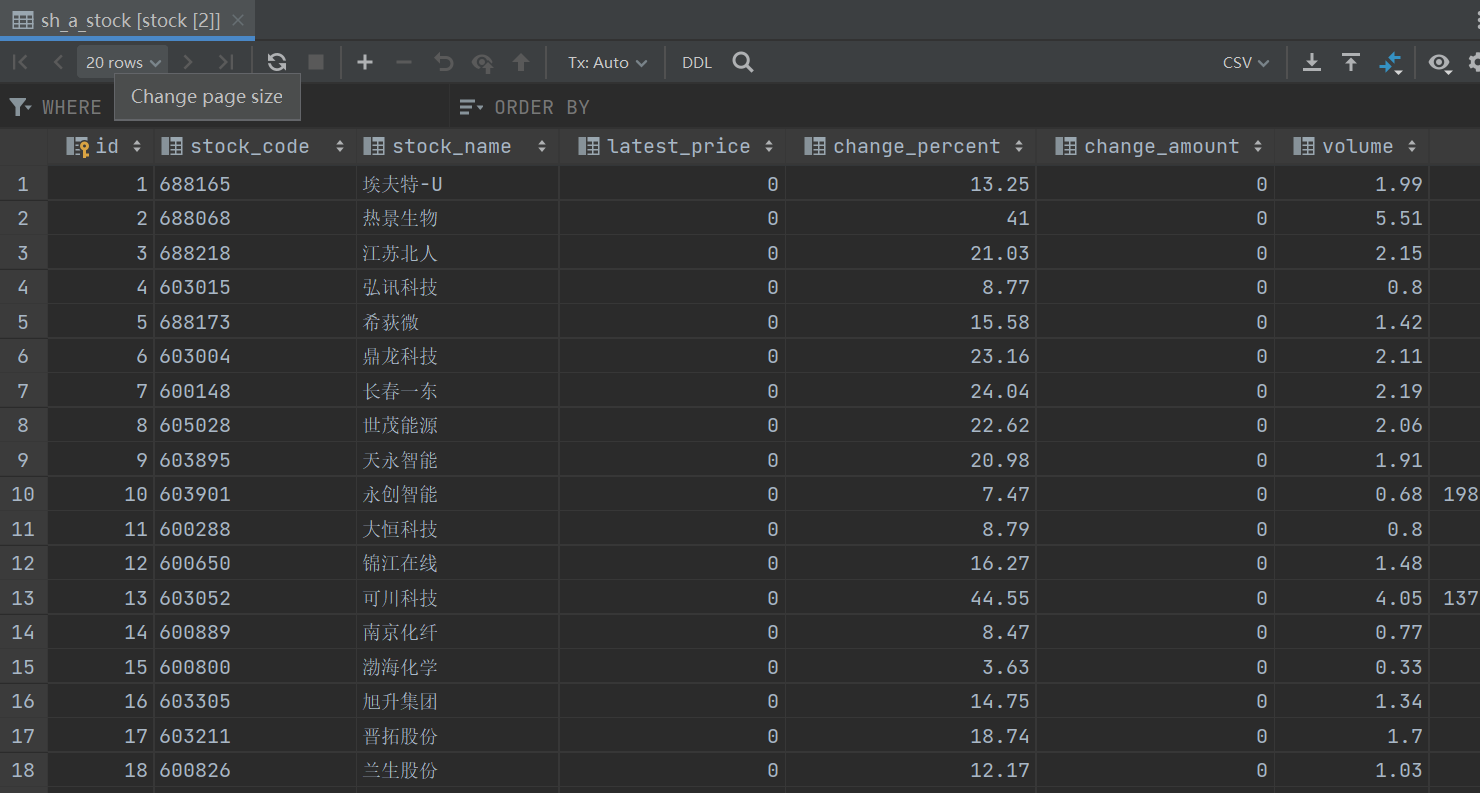
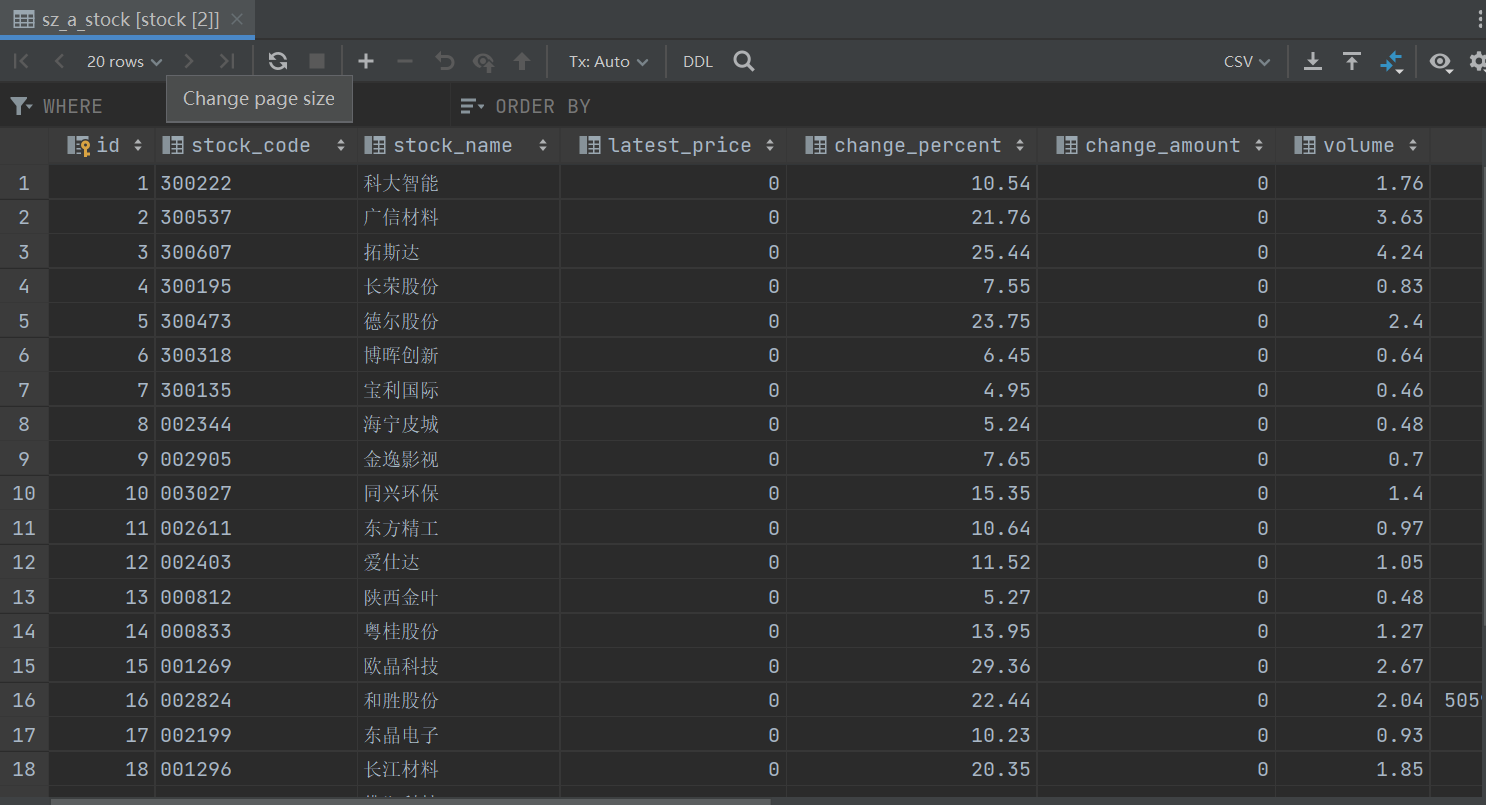
数据库显示数据截图
- 心得体会
学习了如何用selenium模拟网站访问相对应的网页,对selenium库丰富的方法和功能有初步了解
作业二
- 数据采集实验
gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践4/作业2
作业要求:等待HTML元素等内容。使用Selenium框架+MySQL爬取中国 mooc网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国 mooc 网:https://www.icourse163.org
输出信息:MYSQL 数据库存储和输出格式
爬取大数据相关课程
源码链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践4/作业2/作业2.py
作业运行代码
点击查看代码
from selenium import webdriver
from selenium.webdriver.common.by import By
import sqlite3
import time
driver = webdriver.Chrome()
driver.get('https://www.icourse163.org/')
time.sleep(1)
button = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
# 对查找到的登录按钮元素执行点击操作,模拟用户点击登录按钮的行为
button.click()
time.sleep(1)
frame = driver.find_element(By.XPATH, "//div[@class='ux-login-set-container']//iframe")
# 将浏览器的操作焦点切换到查找到的iframe元素内,后续在该iframe内查找和操作登录表单相关的元素
driver.switch_to.frame(frame)
account = driver.find_element(By.ID, 'phoneipt').send_keys('13995109082')
password = driver.find_element(By.XPATH, '//input[@placeholder="请输入密码"]').send_keys("Wang1007")
button1 = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
button1.click()
time.sleep(1)
url = 'https://www.icourse163.org/search.htm?search=%E5%A4%A7%E6%95%B0%E6%8D%AE#/'
driver.get(url)
# 连接到名为'courses.db'的SQLite数据库,如果数据库不存在则会创建一个新的数据库文件
conn = sqlite3.connect('courses.db')
cursor = conn.cursor()
cursor.execute('''create table ceb(id INTEGER,课程名称 text, 学校名称 text,老师 text,教师团队 text,参加人数 text, 课程进度 text, 课程简介 text)
''')
count = 0
link_list = driver.find_elements(By.XPATH, '//div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]')
# 遍历查找到的所有课程链接元素列表
for link in link_list:count += 1# 在当前课程链接元素内,通过XPATH定位方式查找课程名称元素,并获取其文本内容,即该课程的名称course_name = link.find_element(By.XPATH, './/span[@class=" u-course-name f-thide"]').text# 在当前课程链接元素内,通过XPATH定位方式查找学校名称元素,并获取其文本内容,即开设该课程的学校名称school_name = link.find_element(By.XPATH, './/a[@class="t21 f-fc9"]').text# 在当前课程链接元素内,通过XPATH定位方式查找主讲老师元素,并获取其文本内容,即主讲该课程的老师姓名teacher = link.find_element(By.XPATH, './/a[@class="f-fc9"]').texttry:# 在当前课程链接元素内,通过XPATH定位方式查找教师团队成员元素(可能是除主讲老师外的其他团队成员),并获取其文本内容team_member = link.find_element(By.XPATH, './/span[@class="f-fc9"]/span').text# 将获取到的教师团队成员姓名和主讲老师姓名拼接起来,用'、'隔开,形成完整的教师团队信息team_member = team_member + ' 、' + teacherexcept Exception as err:# 如果在获取教师团队成员信息时出现异常(比如没有找到相关元素),则将教师团队信息设置为'none'team_member = 'none'# 在当前课程链接元素内,通过XPATH定位方式查找参加人数元素,并获取其文本内容,然后去除其中的'参加'字样,只保留人数相关信息attendees = link.find_element(By.XPATH, './/span[@class="hot"]').textattendees.replace('参加', '')# 在当前课程链接元素内,通过XPATH定位方式查找课程进度元素,并获取其文本内容,即该课程的教学进度相关信息process = link.find_element(By.XPATH, './/span[@class="txt"]').text# 在当前课程链接元素内,通过XPATH定位方式查找课程简介元素,并获取其文本内容,即该课程的简要介绍内容introduction = link.find_element(By.XPATH, './/span[@class="p5 brief f-ib f-f0 f-cb"]').textcursor.execute('''insert into ceb(id,课程名称, 学校名称,老师,教师团队,参加人数, 课程进度, 课程简介)VALUES(?,?,?,?,?,?,?,?)''', (count, course_name, school_name, teacher, team_member, attendees, process, introduction))conn.commit()
cursor.close()
conn.close()
数据库gitee链接:https://gitee.com/wd_b/party-soldier-data-collection/blob/master/数据采集实践4/作业2/courses.db
数据库显示数据截图
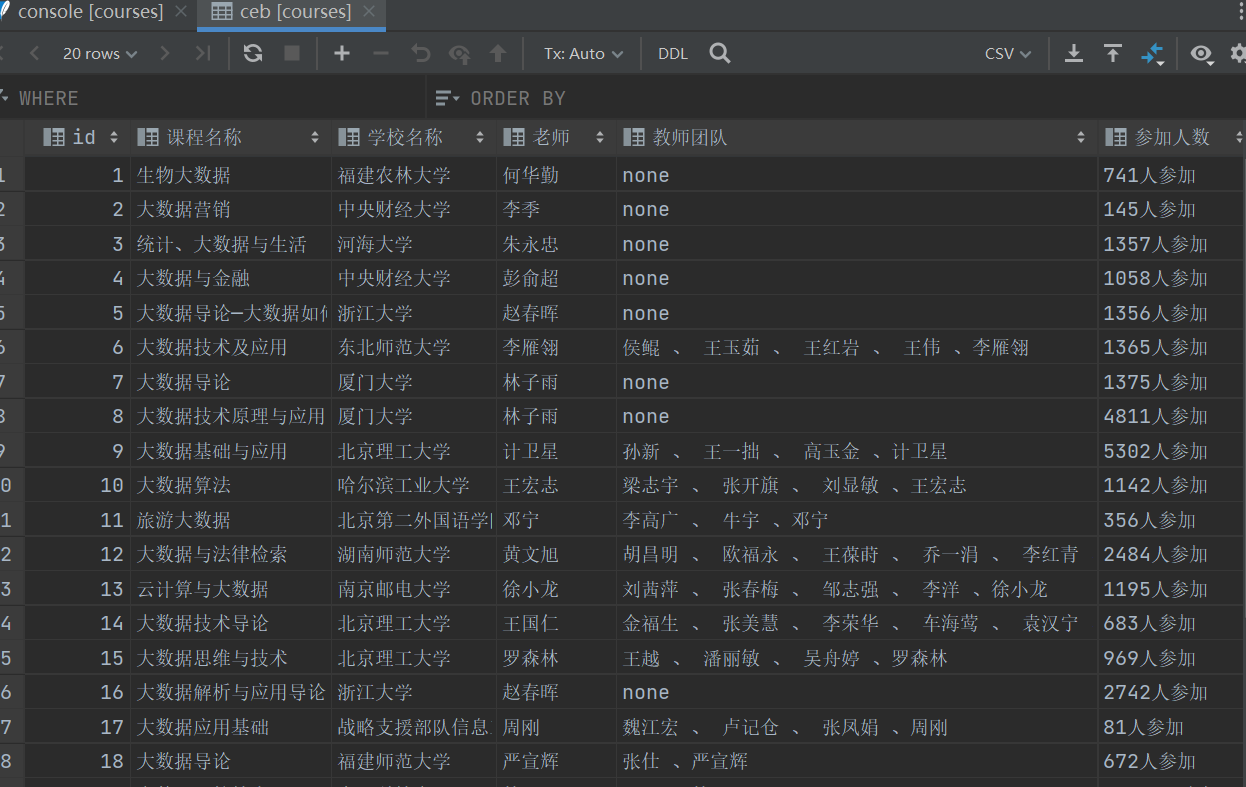
- 心得体会
使用 Selenium 自动化操作网页,从登录网易云课堂到获取课程搜索结果,经过自己的不断尝试,最终实现。通过 XPath 精准提取课程名称、学校、教师等多种信息,处理异常情况得当。利用 SQLite 数据库存储数据,结构清晰,代码整体展示出高效获取和存储网页数据的能力,让我体会到利用合适工具和方法实现复杂功能的魅力。
作业三
- 数据采集实验
gitee文档链接:https://gitee.com/wd_b/party-soldier-data-collection/tree/master/数据采集实践4/作业3
实验要求:掌握大数据相关服务,熟悉 Xshell 的使用,完成文档华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面 5 个任务
环境搭建
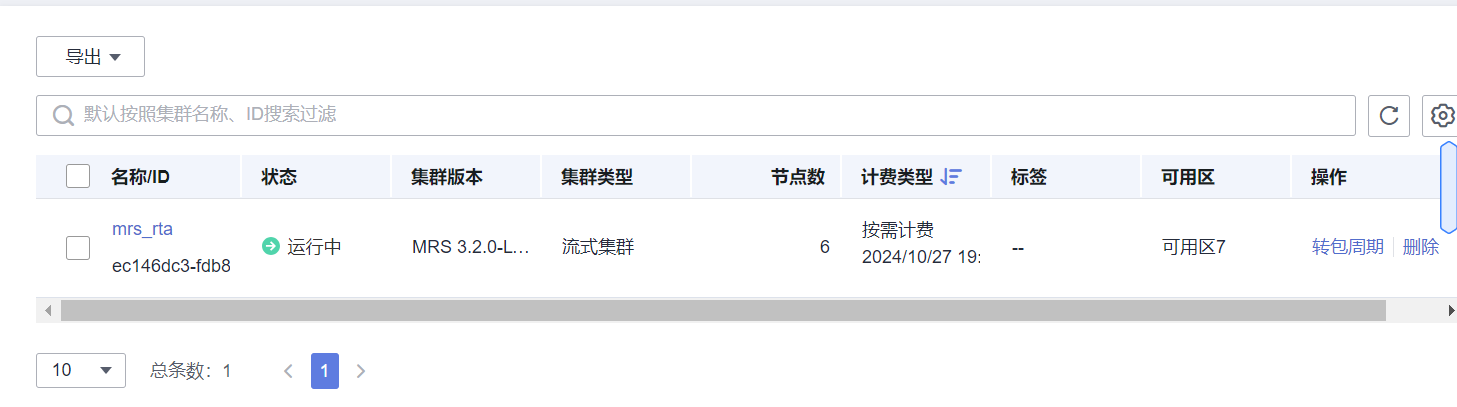
- 任务一:开通 MapReduce 服务,截图如下
实时分析开发实战
- 任务一:Python 脚本生成测试数据
Python脚本生成测试数据
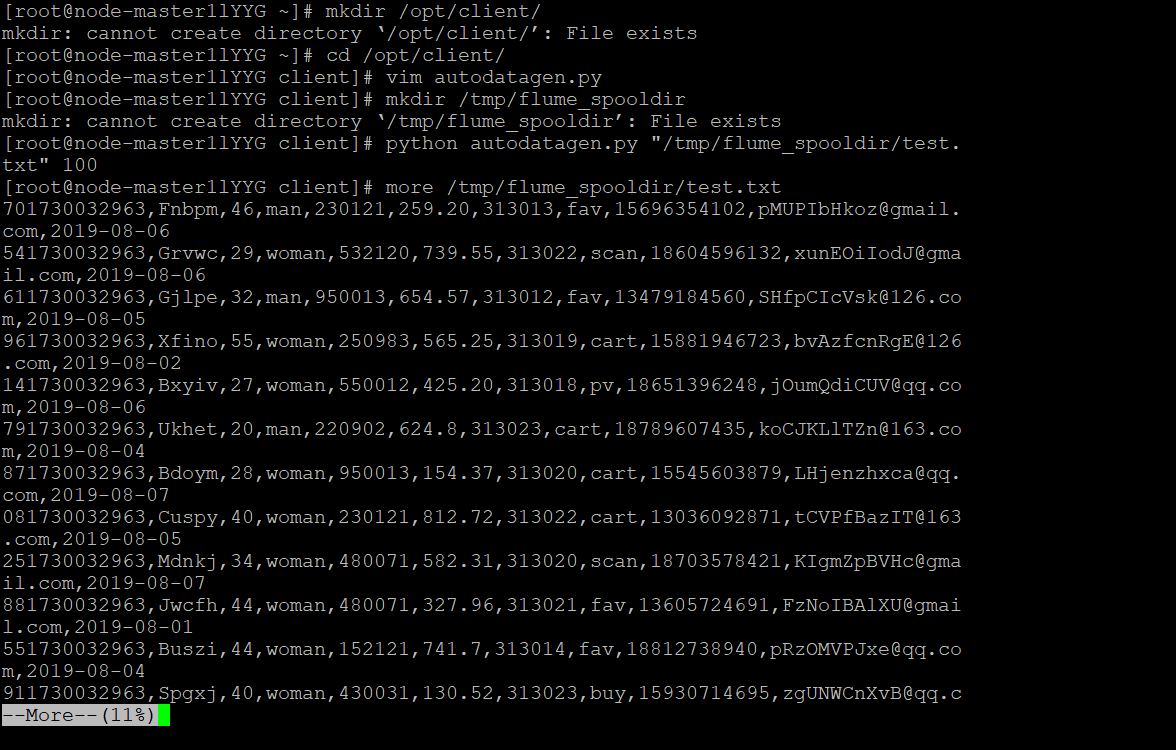
使用more命令查看生成的数据
- 任务二:配置 Kafka
下载Kafka客户端
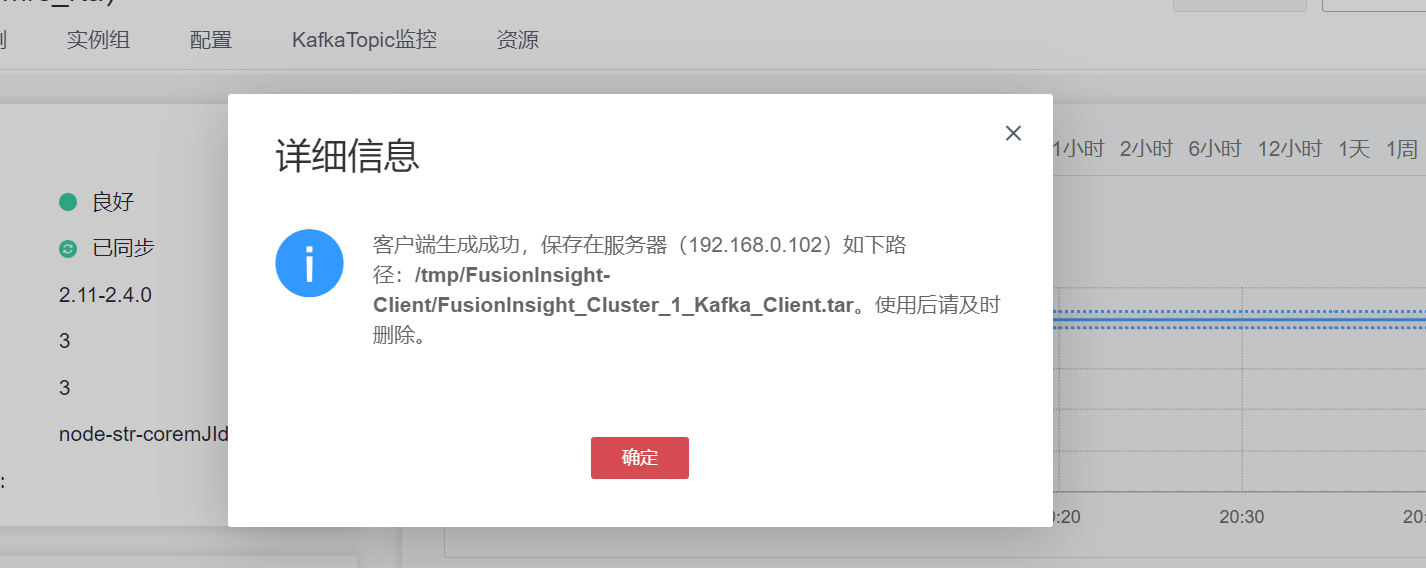
安装Kafka客户端
配置Kafka

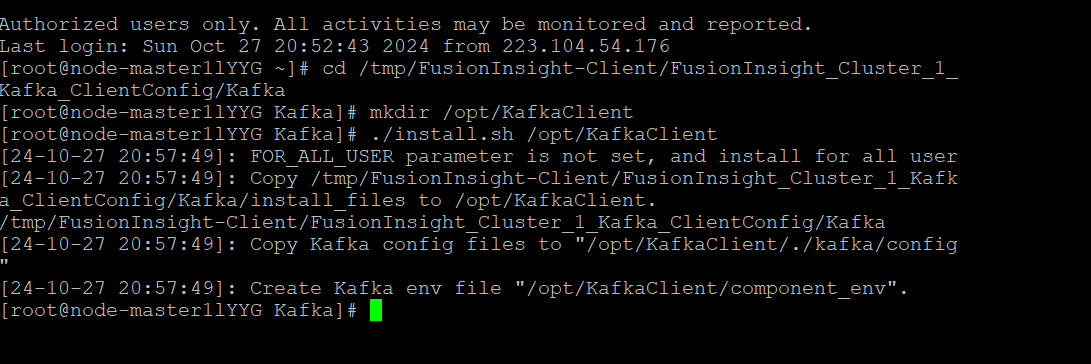
- 任务三: 安装 Flume 客户端
安装Flume客户端
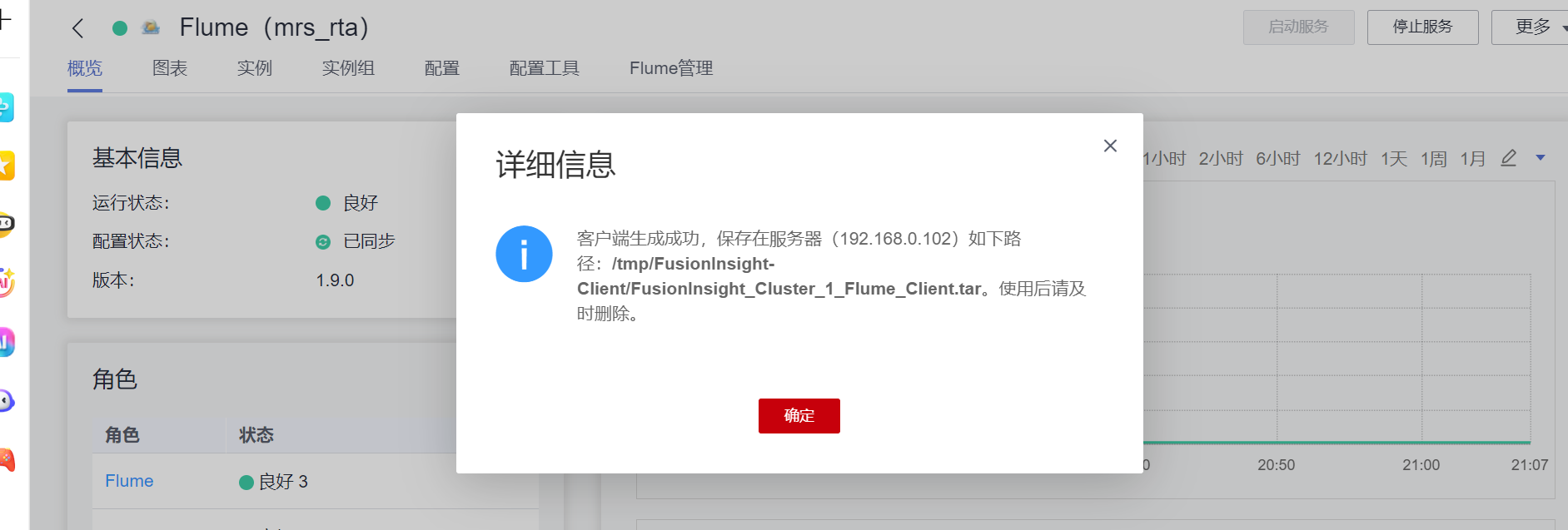
客户端运行环境安装成功

- 任务四:配置 Flume 采集数据,截图如下
- 心得体会
1.申请服务器时要认真配置服务器,尽快做实验并及时释放资源避免产生过多额外费用
2,实验内容是跟着实验书一步一步做的,还算顺利,了解了Python脚本生成测试数据、配置Kafka、安装Flume客户端、配置Flume采集数据这四个过程。