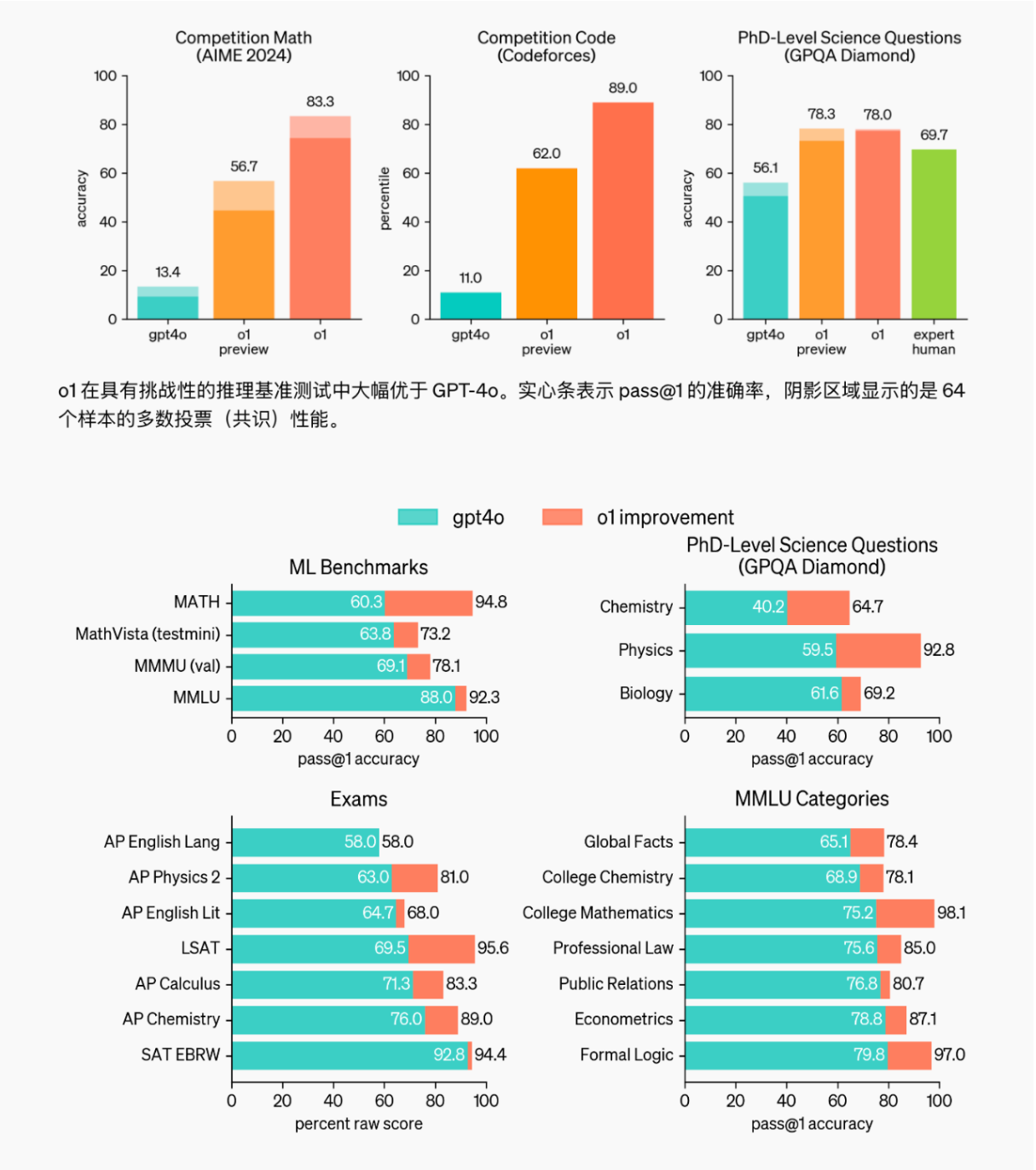
- 安装torch, transformers, loguru(本代码实现为下方版本,其余版本实现可比葫芦画瓢自行摸索)
pip install torch==1.13.1 transformers==4.44.1 numpy==1.26.4 loguru -i https://pypi.tuna.tsinghua.edu.cn/simple/
- RNN:Recurrent Neural Network,网络结构如下图所示:
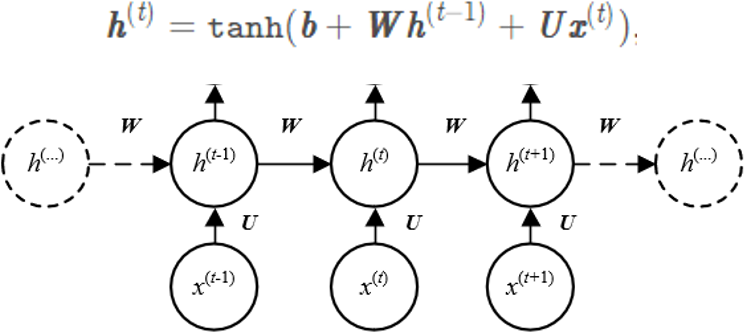
import numpy as np
import torch
import torch.nn as nn
from loguru import loggerclass RNNNet(nn.Module):def __init__(self, input_size, output_size):super(RNNNet, self).__init__()self.rnn = nn.RNN(input_size, output_size, batch_first=True)def forward(self, x):return self.rnn(x)class DiyRnn:def __init__(self, input_size, output_size, w_ih, w_hh, b_ih, b_hh):self.input_size = input_sizeself.output_size = output_sizeself.w_ih = w_ihself.w_hh = w_hhself.b_ih = b_ihself.b_hh = b_hhdef forward(self, x):h = np.zeros(self.output_size)output = []for x_t in x:wh = np.dot(self.w_hh, h)+self.b_hhux = np.dot(self.w_ih, x_t)+self.b_ihh = np.tanh(wh + ux)output.append(h)return output, hif __name__ == '__main__':np.random.seed(0)x = np.random.rand(2, 3)logger.info(x)# [[0.5488135 0.71518937 0.60276338]# [0.54488318 0.4236548 0.64589411]]output_size = 4rnn_net = RNNNet(input_size=x.shape[-1], output_size=output_size)config = rnn_net.state_dict()logger.info(config)# OrderedDict([('rnn.weight_ih_l0', tensor([[-0.0457, -0.4071, 0.2976],# [-0.0054, -0.0933, 0.0067],# [0.3260, 0.2038, 0.2182],# [0.4280, -0.4157, 0.2622]])),# ('rnn.weight_hh_l0', tensor([[-0.2899, 0.4229, 0.4570, 0.0994],# [-0.2007, -0.0576, -0.3966, -0.2938],# [0.4743, -0.1752, -0.1097, -0.3806],# [0.4464, 0.0088, 0.0849, -0.2520]])),# ('rnn.bias_ih_l0', tensor([0.0525, -0.2808, 0.0765, -0.4127])),# ('rnn.bias_hh_l0', tensor([0.0074, -0.1029, -0.2717, 0.3444]))])# 拿出相关权重w_ih = config['rnn.weight_ih_l0'].numpy()w_hh = config['rnn.weight_hh_l0'].numpy()b_ih = config['rnn.bias_ih_l0'].numpy()b_hh = config['rnn.bias_hh_l0'].numpy()diy_rnn = DiyRnn(input_size=x.shape[-1], output_size=output_size, w_ih=w_ih, w_hh=w_hh, b_ih=b_ih, b_hh=b_hh)logger.info(rnn_net.forward(torch.FloatTensor([x])))# (tensor([[[-0.0768, -0.4213, 0.2552, 0.0274],# [0.0182, -0.4553, 0.2057, 0.1342]]], grad_fn= < TransposeBackward1 >), tensor(# [[[0.0182, -0.4553, 0.2057, 0.1342]]], grad_fn= < StackBackward0 >))logger.info(diy_rnn.forward(x))# ([array([-0.07679531, -0.42131666, 0.25521276, 0.02736465]),# array([0.01821601, -0.45531428, 0.20569796, 0.13417281])],# array([0.01821601, -0.45531428, 0.20569796, 0.13417281]))
-
LSTM: LONG SHORT-TERM MEMORY
-
LSTM参考:
LONG SHORT-TERM MEMORY

- 如图,相较于RNN,LSTM引入了三个门(forget:遗忘门; input:输入门; output:输出门)以及一个cell(细胞状态)
- 遗忘门
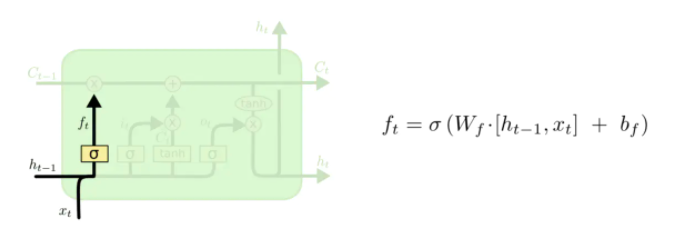
- 输入门

- 细胞状态
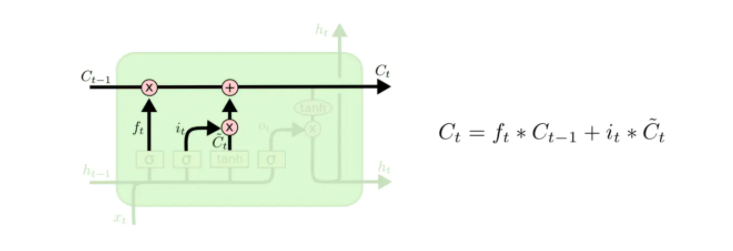
- 输出门

- 如下所示(来自pytorch官方文档), pytorch将四个门的权重拼接存储, 使用时应将权重拆分
pytorch-LSTM

import numpy as np
import torch
import torch.nn as nn
from loguru import loggerclass LSTMNet(nn.Module):def __init__(self, input_size, output_size):super(LSTMNet, self).__init__()self.lstm = nn.LSTM(input_size, output_size, batch_first=True)def forward(self, x):return self.lstm(x)def sigmoid(x):return 1 / (1 + np.exp(-x))class DiyLSTM:def __init__(self, input_size, output_size, params):self.input_size = input_sizeself.output_size = output_sizeself.params = paramsdef forward(self, x):c_state = np.zeros((1, self.output_size))h_t = np.zeros((1, self.output_size))output = []for x_t in x:# 拼接h_t-1和x_tx_t = x_t[np.newaxis, :]hx = np.concatenate([h_t, x_t], axis=1)# 遗忘门f_gate = sigmoid(np.dot(hx, self.params['w_f'].T) + self.params['b_f'])# 输入门i_gate = sigmoid(np.dot(hx, self.params['w_i'].T) + self.params['b_i'])c_t = np.tanh(np.dot(hx, self.params['w_g'].T) + self.params['b_g'])# 细胞状态c_state = f_gate * c_state + i_gate * c_t# 输出门o_gate = sigmoid(np.dot(hx, self.params['w_o'].T) + self.params['b_o'])h_t = o_gate * np.tanh(c_state)output.append(h_t)return output, (h_t, c_state)if __name__ == '__main__':np.random.seed(0)x = np.random.rand(2, 3)logger.info(x)# [[0.5488135 0.71518937 0.60276338]# [0.54488318 0.4236548 0.64589411]]output_size = 4lstm_net = LSTMNet(input_size=x.shape[-1], output_size=output_size)config = lstm_net.state_dict()logger.info(config)# OrderedDict([('lstm.weight_ih_l0', tensor([[-4.9427e-01, 1.9967e-01, -2.3552e-01],# [-3.9925e-01, -4.3527e-01, -4.3788e-01],# [2.3260e-01, -3.4320e-01, -1.9645e-01],# [4.6990e-02, -1.0843e-01, -3.7759e-01],# [-4.7427e-01, 1.4113e-01, 9.9269e-02],# [-1.1028e-01, -2.8063e-02, -1.9031e-01],# [4.0165e-02, 3.4149e-01, -4.2790e-01],# [8.7034e-02, 2.1281e-01, 1.7534e-02],# [-1.1237e-01, 3.0430e-01, -1.5539e-01],# [-1.9999e-01, 3.9918e-01, 3.5223e-01],# [3.9140e-01, -4.7726e-01, 3.8438e-02],# [-4.8784e-01, -4.0153e-01, -1.4178e-01],# [-4.8935e-01, 5.2839e-02, -2.2023e-01],# [4.2617e-04, 1.0101e-01, -1.0125e-01],# [3.0032e-01, -4.1422e-01, -1.5690e-02],# [-2.1115e-01, 4.1811e-01, 1.2737e-01]])),# ('lstm.weight_hh_l0', tensor([[-0.0955, 0.1711, 0.0808, -0.3968],# [0.4032, 0.0011, -0.3469, 0.2721],# [0.3867, 0.3623, 0.4939, -0.3715],# [0.3079, 0.3738, -0.2541, -0.0634],# [0.4938, -0.3674, -0.4637, -0.3214],# [0.0966, 0.2149, 0.0437, -0.0785],# [-0.2184, 0.2239, -0.1109, -0.1011],# [0.2706, -0.0714, 0.0262, -0.3305],# [-0.0541, -0.0007, -0.3030, 0.1019],# [-0.1091, -0.0877, 0.2487, -0.3302],# [-0.1562, 0.2569, 0.4448, 0.4016],# [0.2281, 0.4276, 0.0385, -0.2319],# [-0.1003, -0.2430, 0.3855, 0.0251],# [0.4021, 0.3176, 0.3161, -0.4141],# [-0.0311, -0.1515, -0.1146, -0.0086],# [-0.4698, -0.0452, 0.1368, -0.3899]])),# ('lstm.bias_ih_l0', tensor([0.0064, 0.4618, -0.3796, -0.0715, -0.1619, -0.3431, -0.0426, 0.3353,# 0.3295, -0.2912, -0.2534, 0.0718, 0.4179, 0.0605, -0.2152, -0.0713])),# ('lstm.bias_hh_l0', tensor([0.2422, -0.4391, -0.4711, -0.0895, -0.2479, -0.4610, -0.4583, -0.4978,# 0.0348, 0.4443, 0.2497, 0.2130, 0.1853, -0.0892, -0.0290, -0.2548]))])# 拿出相关权重w_ih = config['lstm.weight_ih_l0'].numpy()w_hh = config['lstm.weight_hh_l0'].numpy()b_ih = config['lstm.bias_ih_l0'].numpy()b_hh = config['lstm.bias_hh_l0'].numpy()params = {}# 进行拆分w_ii = w_ih[0:output_size, :]w_if = w_ih[output_size:output_size * 2, :]w_ig = w_ih[output_size * 2:output_size * 3, :]w_io = w_ih[output_size * 3:output_size * 4, :]w_hi = w_hh[0:output_size, :]w_hf = w_hh[output_size:output_size * 2, :]w_hg = w_hh[output_size * 2:output_size * 3, :]w_ho = w_hh[output_size * 3:output_size * 4, :]b_ii = b_ih[0:output_size]b_if = b_ih[output_size:output_size * 2]b_ig = b_ih[output_size * 2:output_size * 3]b_io = b_ih[output_size * 3:output_size * 4]b_hi = b_hh[0:output_size]b_hf = b_hh[output_size:output_size * 2]b_hg = b_hh[output_size * 2:output_size * 3]b_ho = b_hh[output_size * 3:output_size * 4]# 再拼接params['w_i'] = np.concatenate((w_hi, w_ii,), axis=1)params['w_f'] = np.concatenate((w_hf, w_if), axis=1)params['w_g'] = np.concatenate((w_hg, w_ig), axis=1)params['w_o'] = np.concatenate((w_ho, w_io), axis=1)params['b_i'] = b_hi + b_iiparams['b_f'] = b_hf + b_ifparams['b_g'] = b_hg + b_igparams['b_o'] = b_ho + b_io# 验证output, (h_t, c_state) = lstm_net.forward(torch.Tensor([x]))diy_lstm = DiyLSTM(input_size=x.shape[-1], output_size=output_size, params=params)diy_output, (diy_h_t, diy_c_state) = diy_lstm.forward(x)logger.info(output)# tensor([[[0.1099, 0.0768, -0.0109, -0.0642],# [0.1214, 0.0942, -0.0036, -0.0610]]], grad_fn= < TransposeBackward0 >)# logger.info(diy_output)# [array([[0.10993756, 0.07675594, -0.01088845, -0.06423639]]),# array([[0.12144392, 0.09417902, -0.00356926, -0.06100272]])]logger.info('-'*30)logger.info(h_t)# tensor([[[0.1214, 0.0942, -0.0036, -0.0610]]], grad_fn= < StackBackward0 >)logger.info(diy_h_t)# [[0.12144392 0.09417902 - 0.00356926 - 0.06100272]]logger.info('-' * 30)logger.info(c_state)# tensor([[[0.2266, 0.1867, -0.0083, -0.1374]]], grad_fn= < StackBackward0 >)logger.info(diy_c_state)# [[0.22656548 0.18674521 - 0.00828899 - 0.13736903]]
- GRU: Gated Recurrent Unit
- GRU参考:
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
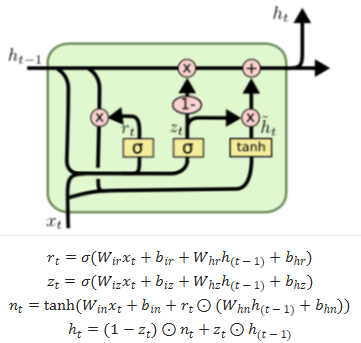
- 如图,相较于LSTM, GRU就只有重置门(reset gate)和更新门(update gate)。
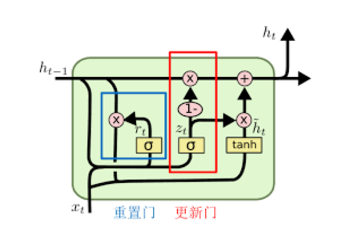
- 同LSTM, pytorch将GRU三个权重拼接存储,使用时应将权重拆分
pytorch-GRU

import numpy as np
import torch
import torch.nn as nn
from loguru import loggerclass GRUNet(nn.Module):def __init__(self, input_size, output_size):super(GRUNet, self).__init__()self.gru = nn.GRU(input_size, output_size, batch_first=True)def forward(self, x):return self.gru(x)def sigmoid(x):return 1/(1 + np.exp(-x))class DiyGRU:def __init__(self, input_size, output_size, params):self.params = paramsself.input_size = input_sizeself.output_size = output_sizedef forward(self, x):h_t = np.zeros((1, self.output_size))output = []for x_t in x:# 拼接h_t-1和x_tx_t = x_t[np.newaxis, :]hx = np.concatenate([h_t, x_t], axis=1)# 重置门z_gate = sigmoid(np.dot(hx, self.params['w_z'].T)+self.params['b_z'])# 更新门r_gate = sigmoid(np.dot(hx, self.params['w_r'].T)+self.params['b_r'])h = np.tanh(r_gate * (np.dot(h_t, self.params['w_hn'].T)+self.params['b_hn']) + np.dot(x_t, params['w_in'].T)+self.params['b_in'])h_t = (1 - z_gate) *h + z_gate * h_toutput.append(h_t)return output, h_tif __name__ == '__main__':np.random.seed(0)x = np.random.rand(2, 3)logger.info(x)# [[0.5488135 0.71518937 0.60276338]# [0.54488318 0.4236548 0.64589411]]output_size = 4gru_net = GRUNet(input_size=x.shape[-1], output_size=output_size)config = gru_net.state_dict()logger.info(config)# OrderedDict([('gru.weight_ih_l0', tensor([[0.3498, -0.2464, 0.1821],# [0.4983, 0.2338, 0.2775],# [0.3149, -0.1604, -0.3139],# [0.1033, -0.4810, 0.2286],# [0.4119, -0.0904, 0.0235],# [-0.2726, -0.1599, -0.1409],# [0.4868, 0.3642, -0.4094],# [0.3575, 0.3485, -0.0588],# [-0.4573, -0.1335, 0.2341],# [-0.3783, 0.4000, -0.4123],# [0.3719, -0.2910, -0.0990],# [0.4505, 0.2768, -0.4415]])),# ('gru.weight_hh_l0', tensor([[-0.3311, -0.4529, 0.2700, 0.0751],# [0.3137, -0.1595, -0.2992, -0.0155],# [-0.1653, -0.2416, -0.0491, 0.2202],# [0.0444, -0.2747, 0.3629, 0.3710],# [-0.1979, -0.3254, -0.2218, 0.4253],# [-0.0551, 0.3831, 0.4546, -0.2381],# [0.0586, 0.1298, 0.4931, 0.3256],# [0.3766, -0.4562, -0.3886, -0.0262],# [0.1932, 0.3176, -0.2126, 0.4094],# [-0.2687, -0.1186, -0.2640, 0.0742],# [0.4005, -0.4942, 0.0684, 0.4556],# [-0.2354, 0.4706, -0.0453, -0.3255]])),# ('gru.bias_ih_l0', tensor([0.2916, 0.3510, -0.3568, 0.2643, 0.2218, -0.2269, 0.4010, 0.4272,# 0.1880, 0.1084, 0.4999, -0.2438])),# ('gru.bias_hh_l0', tensor([0.4873, 0.1265, -0.4216, 0.3730, -0.1611, 0.4775, -0.1161, -0.4087,# -0.2695, -0.2110, -0.0021, 0.3299]))])# 拿出相关权重w_ih = config['gru.weight_ih_l0'].numpy()w_hh = config['gru.weight_hh_l0'].numpy()b_ih = config['gru.bias_ih_l0'].numpy()b_hh = config['gru.bias_hh_l0'].numpy()params = {}# 进行拆分w_ir = w_ih[0:output_size, :]w_iz = w_ih[output_size:output_size * 2, :]w_in = w_ih[output_size * 2:output_size * 3, :]w_hr = w_hh[0:output_size, :]w_hz = w_hh[output_size:output_size * 2, :]w_hn = w_hh[output_size * 2:output_size * 3, :]b_ir = b_ih[0:output_size]b_iz = b_ih[output_size:output_size * 2]b_in = b_ih[output_size * 2:output_size * 3]b_hr = b_hh[0:output_size]b_hz = b_hh[output_size:output_size * 2]b_hn = b_hh[output_size * 2:output_size * 3]# 再拼接params['w_r'] = np.concatenate((w_hr, w_ir), axis=1)params['w_z'] = np.concatenate((w_hz, w_iz), axis=1)params['b_r'] = b_hr + b_irparams['b_z'] = b_hz + b_izparams['w_in'] = w_inparams['w_hn'] = w_hnparams['b_in'] = b_inparams['b_hn'] = b_hn# 验证output, h_t = gru_net.forward(torch.Tensor([x]))diy_gru = DiyGRU(input_size=x.shape[-1], output_size=output_size, params=params)diy_output, diy_h_t = diy_gru.forward(x)logger.info(output)# tensor([[[-0.0910, -0.1133, 0.1485, 0.0547],# [-0.1427, -0.2251, 0.2752, 0.0393]]], grad_fn= < TransposeBackward1 >)logger.info(diy_output)# [array([[-0.09097601, -0.11329616, 0.14852062, 0.05474681]]), # array([[-0.14269054, -0.22514825, 0.27520506, 0.03929618]])]logger.info('-'*50)logger.info(h_t)# tensor([[[-0.1427, -0.2251, 0.2752, 0.0393]]], grad_fn= < StackBackward0 >)logger.info(diy_h_t)# [[-0.14269054 - 0.22514825 0.27520506 0.03929618]]