🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
🦄 个人主页——🎐开着拖拉机回家_Linux,Java基础学习,大数据运维-CSDN博客 🎐✨🍁
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
感谢点赞和关注 ,每天进步一点点!加油!
目录
一、HDFS产出背景及定义
1.1.HDFS产生背景
1.2.HDFS简介
1.3.HDFS的优缺点
1、优点
2、缺点
二、HDFS的特点
三、HDFS组成架构
1、Client:客户端
2、NameNode
3、 DataNode
4、 Secondary NameNode
四、HDFS读写过程
4.1.写入流程
4.2.读取流程
五、HDFS客户端常用命令
5.1.HDFS客户端访问命令使用
5.2.HDFS客户端管理命令使用
1、报告文件系统的基本信息和统计信息
2、fs_image 文件导出解析到本地
3、安全模式
4、文件健康检查和租约释放
5、har 归档
5.3. HDFS 命令总体划分
一、HDFS产出背景及定义
1.1.HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
1.2.HDFS简介
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
1.3.HDFS的优缺点
1、优点
- 高容错性,自动保存 默认的副本数,某个副本或者机器宕机都会完成自动复制,使副本数保持在设置的个数;
- 适合处理大数据,能够存储和处理TB,甚至 PB级别的数据量;
- 可构建在廉价机器上,使用普通服务器便可建设大数据平台。
2、缺点
- 不适合低延时数据访问, 我们一般采用分布式的HBase 作为存储;
- 无法高效对大量小文件进行存储
a.大量 小文件会占用 NameNode 大量内存来存储文件索引信息
b.小文件增加访问和写入寻址时间,大量小文件的存在无论是读取或者写入数
据 都会都集群造成很大的压力
- 不支持并发写入、数据修改
a.一个文件只能一个写,不允许多个线程同时写。
b.仅仅支持数据append(追加),不支持文件的随机修改
二、HDFS的特点
高容错性:一个HDFS集群会包含非常多节点,HDFS将文件分块(Block)存储,并且会自动保存多个副本到不同的机器节点上以保证数据的安全,而且HDFS可以检测故障并且从故障中快速恢复。
高吞吐率:与一般文件系统的访问低延迟不同,HDFS的重点是存储和处理大量的数据,支持数据处理规模是GB、TB、甚至是PB的级别。因此,相比较用户交互式程序,HDFS更加适用批处理的应用程序。
一次写入多次读取模型:一个文件只支持单线程的文件写入,HDFS假定一个文件一旦被创建,写入完成之后除了追加和截断就不需要更改。这种设置简化了数据一致性的问题,从而也提高了数据访问的吞吐率,同时也不支持文件的随机修改。
大数据集:HDFS 中的典型文件大小为 GB 到 TB,对于大批量小文件HDFS无法做到高效存储,存储和检索会消耗NameNode内存。
可移植性:HDFS是由Java语言构建,任何支持Java的机器,都可以运行HDFS,因此HDFS可以轻松地从一个平台移植到另一个平台。
三、HDFS组成架构

1、Client:客户端
通过Client来访问文件系统,然后由Client与NameNode和DataNode进行通信。Client对外作为文件系统的接口
- 文件切分,上传HDFS文件的时候,Client将文件切分成一个一个 Block 然后进行上传;
- 负责与 NameNode 和 DataNode 交互,获取文件的位置信息;
- Client 提供一些命令来管理HDFS,比如:banlance 数据均衡、 fsimage 元数据获取和解析、NameNode 格式化、checkpoint 等;
- Clinet 提供一些命令来访问HDFS,比如:HDFS文件的增删改查
2、NameNode
管理者。 用于存储和管理文件元数据、维护文件系统的目录树形结构,记录写入的每个数据块(Block)与其归属文件的对应关系。
- 管理文件系统命名空间;
- 配置副本策略,默认3副本策略;
- 管理数据块的映射信息(Blockmap);
- 处理客户端的读写请求。
3、 DataNode
DataNode会通过心跳和NameNode保持通信,处理实际的操作。
- 存储实际的数据块;
- 执行数据块的读写操作。
4、 Secondary NameNode
Secondary NameNode的作用是消费EditsLog,定期地合并FsImage和EditsLog,生成新的FsImage文件,并推送给NameNode,降低了NameNode的压力。 在紧急情况下,可辅助恢复NameNode。
SecondaryNameNode机制:
- SecondaryNameNode不是NameNode挂了的备用节点
- 主要功能只是定期合并日志, 防止日志文件变得过大
- 合并过后的镜像文件在NameNode上也会保存一份
SecondaryNameNode工作过程:
- SNN向NameNode发起同步请求, 此时NameNode会将日志都写到新的日志当中;
- SNN向NameNode下载镜像文件和日志文件;
- SNN开始Merge这两份文件并生成新的镜像文件;
- SNN向NameNode传回新的镜像文件;
- NameNode文件将新的镜像文件和日志文件替换成当前正在使用的文件
四、HDFS读写过程
4.1.写入流程
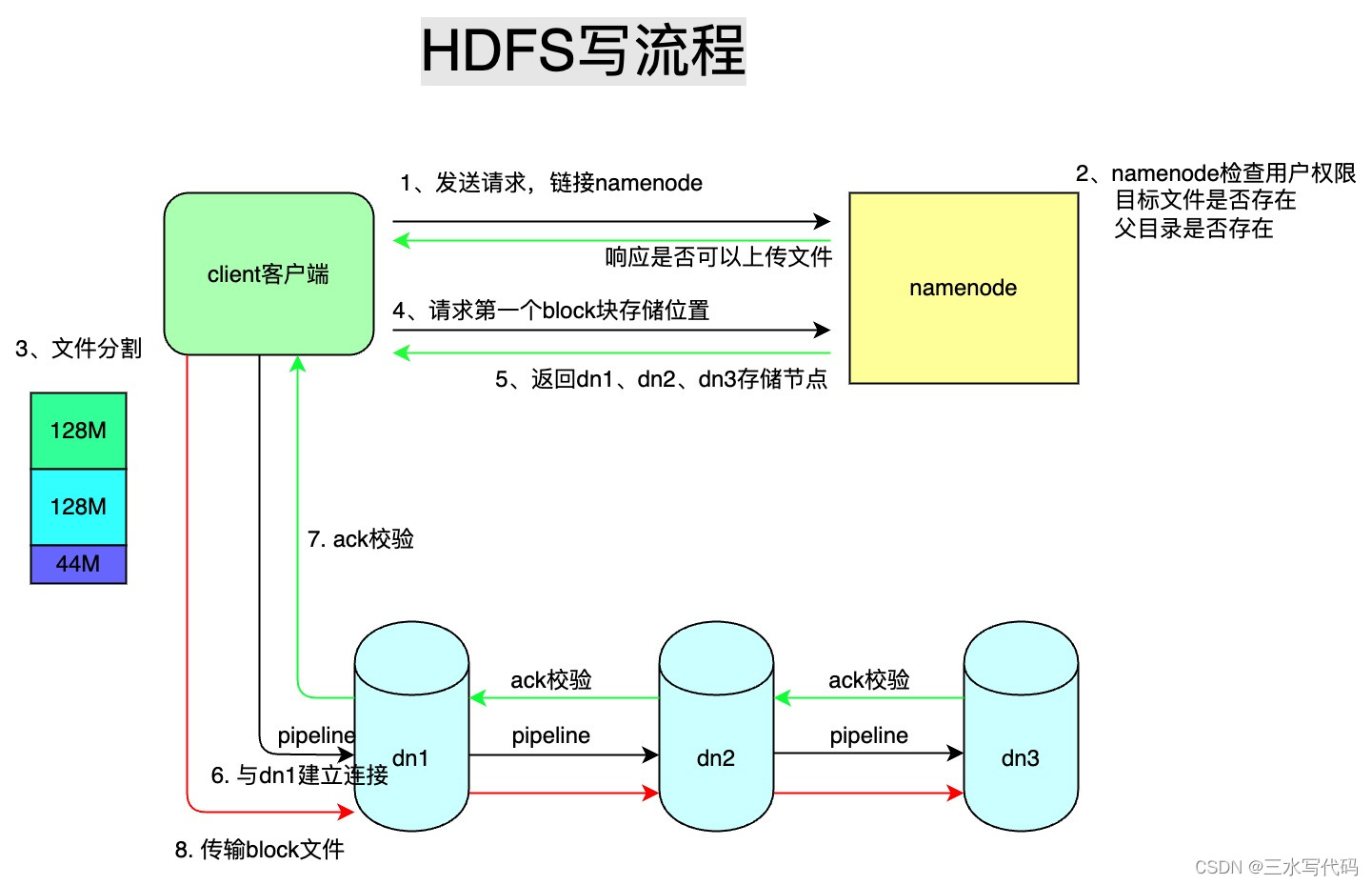
- client向namenode通信,请求上传文件
- namenode判断是否可上传: namenode检查用户是否有上传的权限、目标文件是否已存在、父目录是否存在
- 文件切分:client将文件切分成0~128M大小的block块(逻辑切分)
- client请求block块的存储位置
- namenode返回datanode地址dn1、dn2、dn3(默认三副本地址)
- client通过FSDataOutputStream模块请求dn1上传数据,建立连接管道(本质上是一个 RPC 调用,建立 pipeline)
- 当dn1收到请求后会继续调用dn2, dn2调用dn3,将整个通信管道建立完成,然后逐级返回client,即图中的ack校验
- client开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位(默认64k),dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
- 当一个Block传输完成之后,client再次请求NameNode上传第二个Block的服务器(重复执行4-8步)
- 传输完毕之后,客户端关闭流资源,并且会告诉hdfs数据传输完毕,然后hdfs收到传输完毕就恢复元数据
4.2.读取流程

- Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
- NameNode 会视情况返回文件的部分或者全部 block 列表,对于每个 block,NameNode 都会返回含有该 block 副本的 DataNode 地址;
- 这些返回的 DataNode 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离Client近的排靠前;心跳机制中超时汇报的 DataNode 状态为 STALE,这样的排靠后;
- Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是 DataNode,那么将从本地直接获取数据;底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
- 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向 NameNode 获取下一批的 block 列表;
- 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的 DataNode 继续读。
- read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回 Client 请求包含块的 DataNode 地址,并不是返回请求块的数据;
- 最终读取来所有的 block 会合并成一个完整的最终文件。(摘录博友)
五、HDFS客户端常用命令
5.1.HDFS客户端访问命令使用
对于客户端shell命令的具体使用可以查看 help 帮助, 熟悉Linux 常用命令的人可能一看这些命令就会有种很熟悉对的感觉。
[winner_spark@hdp105 root]$ hdfs dfs -help如下为常用的命令:
# 创建文件夹
hdfs dfs -mkdir -p /tmp/kangll # 上传文件 test.sh 到HDFS
hdfs dfs -put test.sh /tmp/kangll# 查看文件
hdfs dfs -ls /tmp/kangll# 下载到本地 /tmp 文件夹
hdfs dfs -get test.sh /tmp/kangll /tmp# 查看test.sh 文件内容 -less 或者 -more也可以
hdfs dfs -cat /tmp/kangll/test.sh# 查看 文件或者文件夹 大小
hdfs dfs -du -h /tmp/kangll#判断当前路径是否存在
hadoop fs -test -d /tmp/kangll# 文件权限修改
hdfs dfs -chmod 775 /tmp/kangll/test.sh
hdfs dfs -chown winner_spark:hadoop /tmp/kangll/test.sh# 删除test.sh 删除后的文件会先进入 垃圾桶
hdfs dfs -rm -r /tmp/kangll/test.sh# -cp:从HDFS的一个路径拷贝到HDFS的另一个路径
hdfs dfs -cp /tmp/kangll/test.sh /tmp/# 移动
hdfs dfs -mv /tmp/kangll/test.sh /tmp/
5.2.HDFS客户端管理命令使用
如下介绍几个常用的管理命令:
1、报告文件系统的基本信息和统计信息
hdfs dfsadmin -report执行部分结果如下:
[hdfs@hdp105 root]$ hdfs dfsadmin -report
Configured Capacity: 2253195592704 (2.05 TB)
Present Capacity: 2103420218371 (1.91 TB)
DFS Remaining: 1194928602115 (1.09 TB)
DFS Used: 908491616256 (846.10 GB)
DFS Used%: 43.19%
Replicated Blocks:Under replicated blocks: 172Blocks with corrupt replicas: 0Missing blocks: 0Missing blocks (with replication factor 1): 0Low redundancy blocks with highest priority to recover: 0Pending deletion blocks: 0
Erasure Coded Block Groups: Low redundancy block groups: 0Block groups with corrupt internal blocks: 0Missing block groups: 0Low redundancy blocks with highest priority to recover: 0Pending deletion blocks: 0-------------------------------------------------
Live datanodes (3): # 测试环境 3个datanodeName: 192.168.2.152:1019 (hdp103)
Hostname: hdp103
Decommission Status : Normal # 节点状态
Configured Capacity: 751065197568 (699.48 GB)
DFS Used: 302833778688 (282.04 GB)
Non DFS Used: 88004692992 (81.96 GB)
DFS Remaining: 359240115201 (334.57 GB)
DFS Used%: 40.32%
DFS Remaining%: 47.83%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 20
Last contact: Thu Aug 24 14:13:48 CST 2023
Last Block Report: Thu Aug 24 12:32:27 CST 2023
Num of Blocks: 382382、fs_image 文件导出解析到本地
获取Namenode元数据fsImage镜像文件,并且 解析为CSV文件。
# 获取 fsimage, 获取到的数据到二进制文件
hdfs dfsadmin -fetchImage $BASEDIR/data
# 解析,数据解析为 csv 文件 , -o 为输出路径, -p输出文件格式
hdfs oiv -i $BASEDIR/data/fsimage_* -o $BASEDIR/fs_distribution/fs_deli -p Delimited -delimiter ","#可以 查看命令参数解释 hdfs oiv -i -help解析结果

包含的信息有:路径,副本数,日期,权限 ,所属用户和组等信息。
3、安全模式
HDFS中,安全模式是一种保护机制,它可以在NameNode节点出现故障或异常情况时,防止数据丢失或损坏。在安全模式下,HDFS集群只允许读取数据,禁止写入数据,同时也禁止执行元数据修改操作。这意味着,当NameNode节点处于安全模式下时,HDFS集群的数据将处于只读状态,直到NameNode节点恢复正常并退出安全模式为止。
hdfs dfsadmin [-safemode enter | leave | get | wait | forceExit]hdfs dfsadmin 的其他命令:
| 命令选项 | 描述 |
| -report | 报告文件系统的基本信息和统计信息。 |
| -safemode enter | leave | get | wait | 安全模式维护命令。安全模式是Namenode的一个状态,这种状态下,Namenode |
| -refreshNodes | 重新读取hosts和exclude文件,更新允许连到Namenode的或那些需要退出或入编的Datanode的集合。 |
| -finalizeUpgrade | 终结HDFS的升级操作。Datanode删除前一个版本的工作目录,之后Namenode也这样做。这个操作完结整个升级过程。 |
| -upgradeProgress status | details | force | 请求当前系统的升级状态,状态的细节,或者强制升级操作进行。 |
| -metasave filename | 保存Namenode的主要数据结构到hadoop.log.dir属性指定的目录下的<filename>文件。对于下面的每一项,<filename>中都会一行内容与之对应 |
| -setQuota <quota> <dirname>...<dirname> | 为每个目录 <dirname>设定配额<quota>。目录配额是一个长整型整数,强制限定了目录树下的名字个数。 |
| -clrQuota <dirname>...<dirname> | 为每一个目录<dirname>清除配额设定。 |
| -help [cmd] | 显示给定命令的帮助信息,如果没有给定命令,则显示所有命令的帮助信息。 |
4、文件健康检查和租约释放
hdfs文件操作异常没有正确关闭连接,造成租约没有释放,而程序可以读取这个文件时获取不到租约就会报错。所以需要释放租约, -retries 3 表示重试三次。
# 健康检查
hdfs fsck /tmp/kangll/test.sh# hdfs文件操作异常没有正确关闭连接,造成租约没有方式 需要释放租约, -retries 3 重试三次
hdfs debug recoverLease -path $LINE -retries 3 执行结果

hdfs fsck 的其他命令:
| 命令选项 | 描述 |
| -move | 把损坏的文件移动到/lost+found |
| -delete | 直接删除损坏的文件 |
| -files | 打印被检测的文件 |
| -openforwrite | 打印正在被写入的文件,可能是文件写入关闭异常 |
| -includeSnapshots | 检测的文件包括系统snapShot快照目录下的 |
| list-corruptfileblocks | 打印出丢失的块和它们所属的文件列表 |
| -blocks | 打印block 信息 |
| -locations | 打印 block 的位置,即在哪个节点 |
| -racks | 打印block 所在的 rack |
| -storagepolicies | 打印 block 存储的策略信息 |
| -blockId | 打印 block所属块的位置信息 |
5、har 归档
Hadoop存档是特殊格式的存档。Hadoop存档映射到文件系统目录。Hadoop归档文件总是带有* .har扩展名
- Hadoop存档目录包含元数据(采用_index和_masterindex形式)
- 数据部分data(part- *)文件。
- _index文件包含归档文件的名称和部分文件中的位置。
hadoop archive -archiveName $fileName -p $src $subSrc $dest
归档启动MR任务执行完成后:

har 归档虽然对 文件进行了归档 减少了 block 数量,但是har 归档并没有压缩数据。
5.3. HDFS 命令总体划分

Admin Commands:
| 命令 | 描述 |
| cacheadmin | 配置 HDFS 缓存 |
| crypto | 配置HDFS加密区 |
| debug | 执行Debug Admin命令执行HDFS的Debug命令 |
| dfsadmin | 运行DFS管理客户端 |
| dfsrouteradmin | 管理基于路由的联邦 |
| ec | 运行HDFS ErasureCoding 客户端 |
| fsck | 运行DFS文件系统检查工具 |
| haadmin | 运行DFS HA 管理客户端 |
| jmxget | 从NameNode或DataNode获取JMX导出的值 |
| oev | an edits file 应用于 离线 edits viewer |
| oiv | an fsimage 应用于离线 fsimage viewer |
| oiv_legacy | apply the offline fsimage viewer to a legacy fsimage |
| storagepolicies | list/get/set block storage policies |
Client Commands:
| 命令 | 描述 |
| classpath | 打印获取hadoop jar和所需库所需的类路径 |
| dfs | 在文件系统上运行filesystem命令 |
| envvars | 显示计算的Hadoop环境变量 |
| fetchdt | 从NameNode获取一个委托令牌 |
| getconf | 从配置中获取配置值 |
| groups | 获取用户所属的组 |
| lsSnapshottableDir | 列出当前用户拥有的所有可快照目录 |
Daemon Commands:
| 命令 | 描述 |
| balancer | 运行集群平衡实用程序 |
| datanode | 运行DFS datanode |
| dfsrouter | 运行DFS路由器 |
| diskbalancer | 将数据均匀地分布在给定节点的硬盘上 |
| httpfs | 运行HttpFS server, HDFS的HTTP网关 |
| journalnode | 运行DFS journalnode |
| mover | 运行实用程序以跨存储类型移动块副本 |
| namenode | 运行DFS namenode |
| nfs3 | 运行NFS v3网关 |
| portmap | 运行portmap服务 |
对于命令的具体可以可以使用 help 帮助 查看具体使用,我们平时使用做多的就是 hdfs dfs :
[winner_spark@hdp105 root]$ hdfs dfs -help
Usage: hadoop fs [generic options][-appendToFile <localsrc> ... <dst>][-cat [-ignoreCrc] <src> ...][-checksum <src> ...][-chgrp [-R] GROUP PATH...][-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...][-chown [-R] [OWNER][:[GROUP]] PATH...][-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>][-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...][-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>][-createSnapshot <snapshotDir> [<snapshotName>]][-deleteSnapshot <snapshotDir> <snapshotName>][-df [-h] [<path> ...]][-du [-s] [-h] [-v] [-x] <path> ...][-expunge][-find <path> ... <expression> ...][-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>][-getfacl [-R] <path>][-getfattr [-R] {-n name | -d} [-e en] <path>][-getmerge [-nl] [-skip-empty-file] <src> <localdst>][-head <file>][-help [cmd ...]][-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]][-mkdir [-p] <path> ...][-moveFromLocal <localsrc> ... <dst>][-moveToLocal <src> <localdst>][-mv <src> ... <dst>][-put [-f] [-p] [-l] [-d] <localsrc> ... <dst>][-renameSnapshot <snapshotDir> <oldName> <newName>][-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...][-rmdir [--ignore-fail-on-non-empty] <dir> ...][-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]][-setfattr {-n name [-v value] | -x name} <path>][-setrep [-R] [-w] <rep> <path> ...][-stat [format] <path> ...][-tail [-f] <file>][-test -[defsz] <path>][-text [-ignoreCrc] <src> ...][-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...][-touchz <path> ...][-truncate [-w] <length> <path> ...][-usage [cmd ...]]

————————————————
参考链接:Hadoop --- HDFS介绍_hadoop hdfs_三水写代码的博客-CSDN博客
参考链接:Hadoop之HDFS简介_hadoop的hdfs_数新网络的博客-CSDN博客



![[MyBatis系列④]核心配置文件](https://img-blog.csdnimg.cn/bc3e9339d22f48d6a744edface62c793.png)