Transformer 架构由 Vaswani 等人在 2017 年发表的里程碑式论文《Attention Is All You Need》中首次提出,如今已被广泛认为是过去十年间最具开创性的科学突破之一。注意力机制是 Transformer 的核心创新,它为人工智能模型提供了一种全新的方法,使模型能够根据具体任务的需求,灵活地聚焦输入序列的不同部分,从而更深入地理解复杂的语言和结构。
最初在自然语言处理领域崭露头角,Transformer 架构的卓越性能很快吸引了跨学科的关注,其应用迅速扩展到语音识别、计算机视觉、强化学习、生物信息学等多个前沿领域,展现出令人瞩目的学科交叉潜力。然而与其革命性突破同时,注意力层的高计算复杂度也逐渐成为制约其进一步发展的瓶颈。随着模型规模的持续增长,注意力层的计算资源需求呈指数级上升,训练和部署成本也随之攀高。
寻找降低注意力层计算开销的有效策略,在提高基于 Transformer 的人工智能模型效率和可扩展性方面至关重要。本文将深入探讨在 PyTorch 生态系统中优化注意力层的多种技术路径,并将重点聚焦于那些在降低计算成本的同时能够保持注意力层精度的创新方法。这些方法包括 PyTorch SDPA、FlashAttention、TransformerEngine Attention、FlexAttention 以及 xFormer attention。
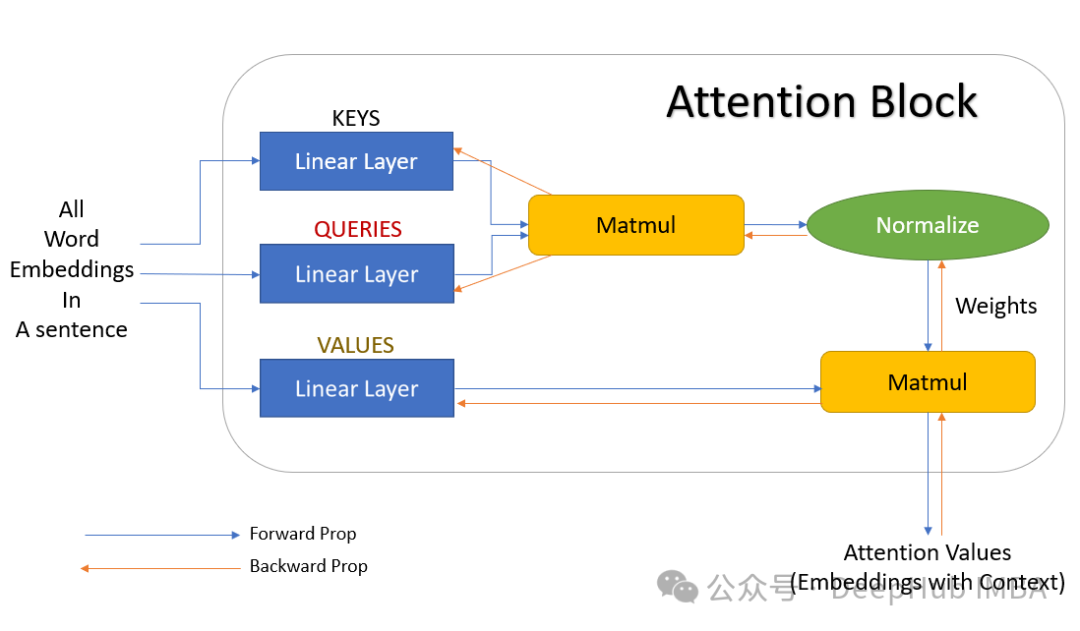
本文将排除通过近似注意力计算来减少计算成本的其他方法(如 DeepSpeed 的 Sparse Attention、Longformer、Linformer 等),同时也不会详细讨论通用的优化技术,尽管这些技术对注意力性能亦有积极影响,但它们并不专门针对注意力计算本身。
值得强调的是,注意力优化是一个极其活跃且快速发展的研究领域,新的方法和突破不断涌现。本文的目标并非提供一个详尽无遗的技术指南,而是希望通过梳理当前主流的优化路径,为读者提供一个清晰的技术概述,并为后续的深入探索和实践铺平道路。
https://avoid.overfit.cn/post/1d4e9a208695482e9187752d41c6a586