🎉工作中遇到这样一个需求场景:由于ES数据库中历史数据过多,占用太多的磁盘空间,需要定期地进行清理,在一定程度上可以释放磁盘空间,减轻磁盘空间压力。
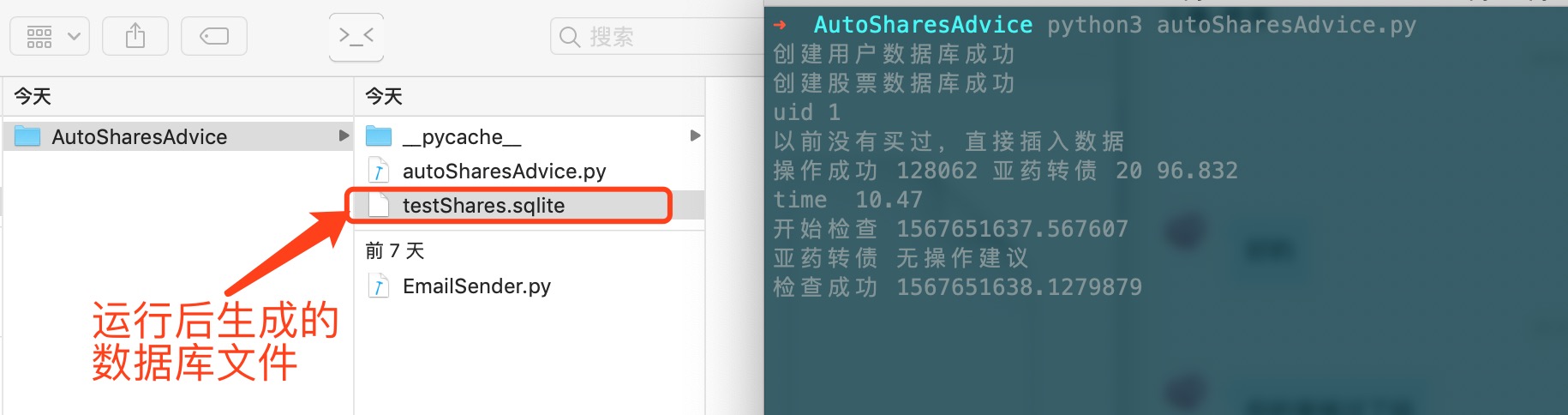
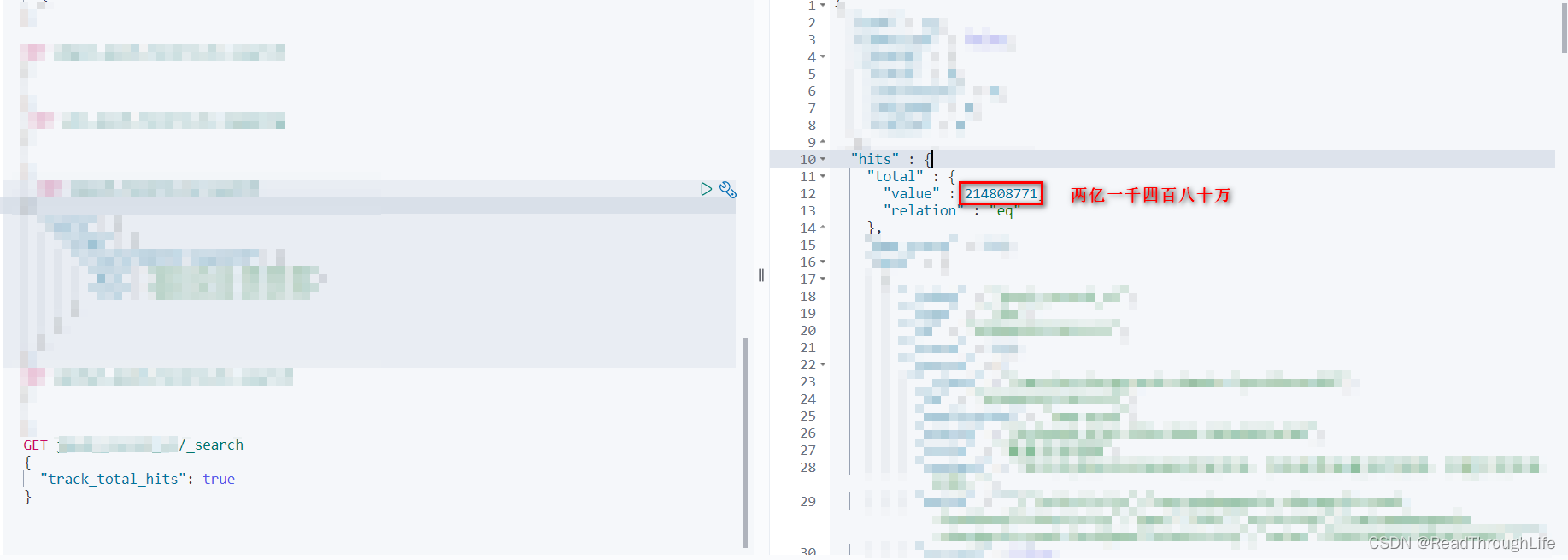
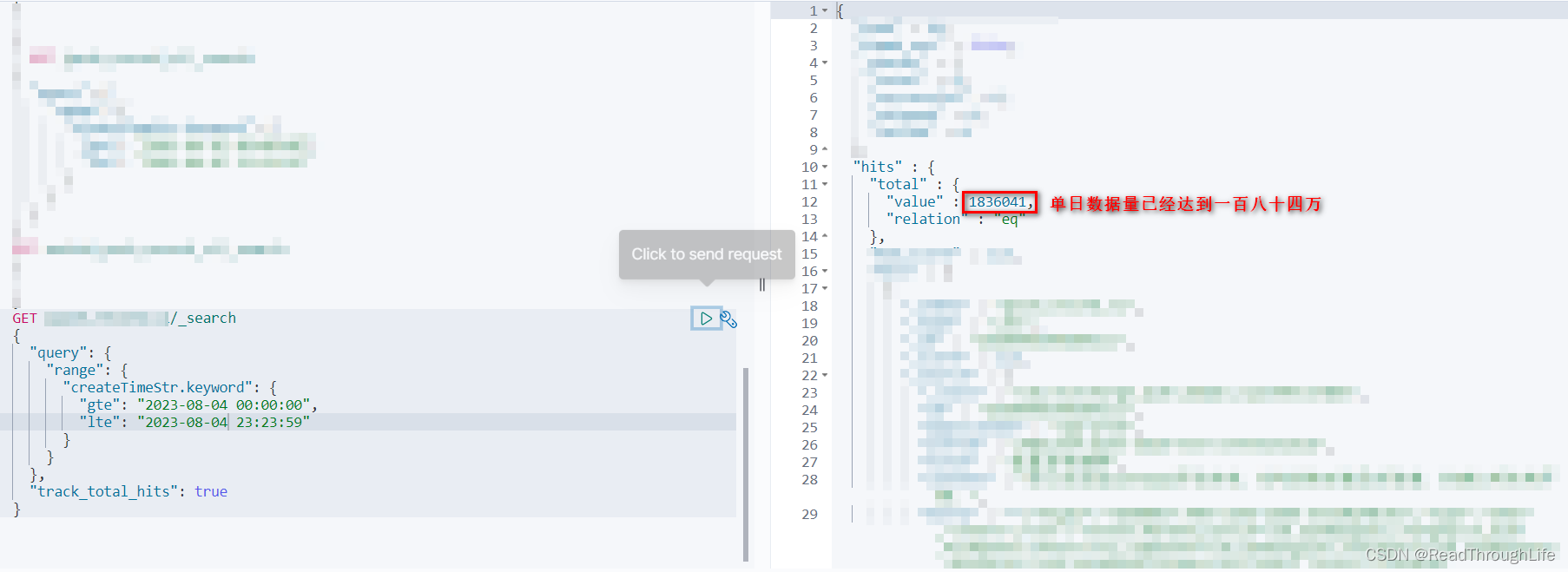
🎈在经过调研之后发现,某服务项目每周产生的数据量已经达到千万级别,单日将近能产生两百万的数据量写入到 ES 数据库中,平均每个小时最少产生 10w+ 条数据,加上之前的历史数据,目前生产环境 ES 数据量已经达到两亿一千四百八十万的数据。并且随着当前业务量的爆发式增长,数据增长量急剧飙升,在未来一年内每周产生的数据量有望达到 3kw-5kw 左右。

💡因此,对 ES 数据库中历史数据进行清理势在必行,为了能够释放磁盘空间,并且还要保证业务方能够进行日常问题的排查定位,决定从两个月前的数据开始清理,方案如下:
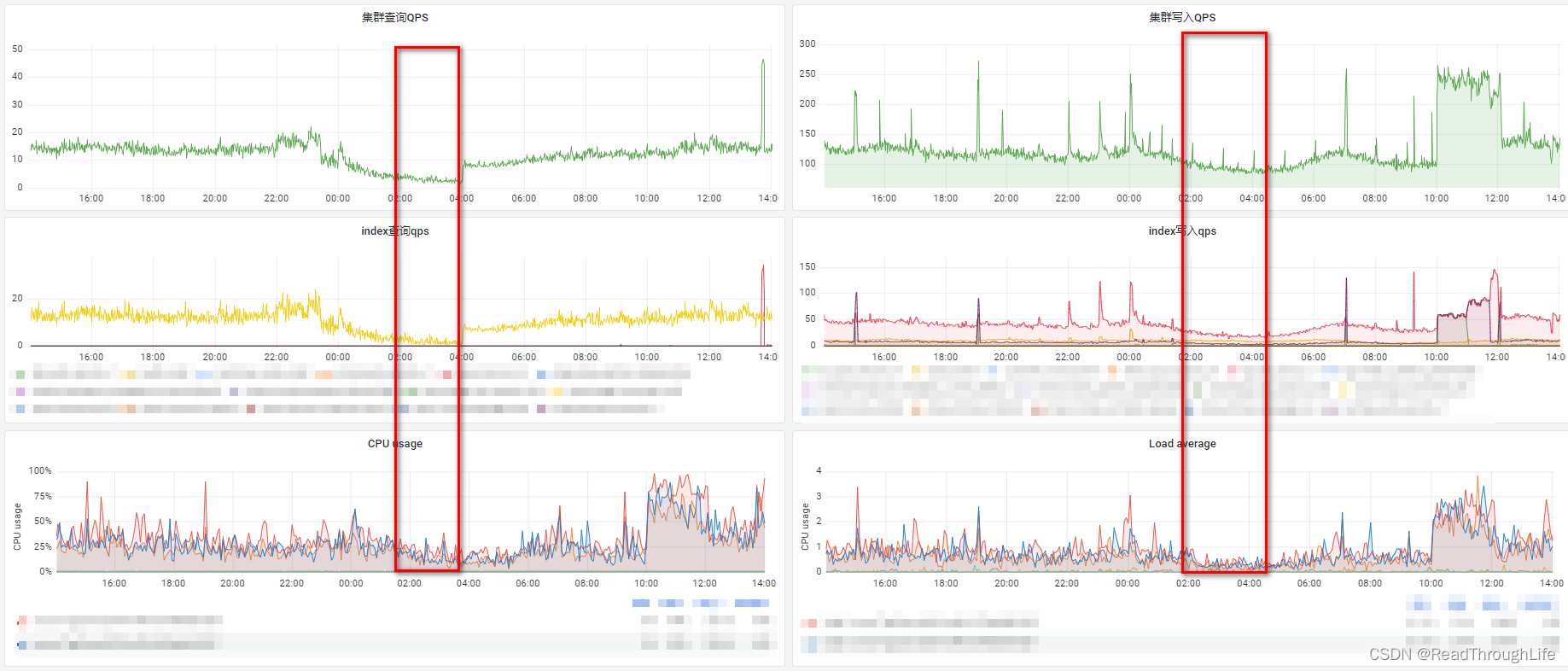
- 编写定时任务,每天凌晨三点清理两个月前的那一天数据,之所以选择凌晨三点是因为在 Grafana 查看了生产环境的集群监控情况,凌晨两点至四点之间的集群、索引的查询以及写入 QPS 都比较低。
- 清理一天的数据时,根据时间段进行清理,每个小时清理一次,避免内存中存放太多的数据,导致内存溢出。
- 清理 ES 数据时,需要先查询出数据,而 ES 默认最多只能查询 1w 条数据,如果当次需要删除的数据量超过 1w 条,普通的查询操作无法完全删除数据。因此,需要采用滚动查询的方式,滚动查询结果保持时间需要设置合理,不能太长,否则也可能会导致内存溢出。
根据以上的思路方案,设计的定时清理ES历史数据代码如下:
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.DateUtils;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.search.ClearScrollRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.search.SearchScrollRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.core.TimeValue;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.Scroll;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
import java.util.Date;
/**
-
清理ES历史数据定时任务
*/
@Component
public class CleanESHistoryDataTask {private static final Logger LOGGER = LoggerFactory.getLogger(CleanESHistoryDataTask.class);
@Resource
private RestHighLevelClient restHighLevelClient;/**
- 根据索引名称删除当前日期两个月前的那一天的历史文档数据
- @param jobContext
*/
@Scheduled
public void cleanESHistoryData(JobContext jobContext) {
// jobContext为定时任务中回传数据
String indexName = jobContext.getData();
if (StringUtils.isBlank(indexName)) {
LOGGER.warn(“ES索引名称不能为空!”);
return;
}
long startTimeMillis = System.currentTimeMillis();
String twoMonthsAgoDate = DateTool.format(DateUtils.addMonths(new Date(), -1), DateTool.DF_DAY);
try {
String startTimeStr = twoMonthsAgoDate + " 00:00:00";
// 初始化时间,形如2023-08-06 00:00:00
Date initialStartTime = DateTool.parse(startTimeStr, DF_FULL);
// 每次循环清理一个小时历史文档数据,循环24次清理完一天的历史文档数据
for (int i = 0; i < 24; i++) {
Date startTime = initialStartTime;
startTime = DateUtils.addHours(startTime, i);
Date endTime = DateUtils.addHours(startTime, 1);
LOGGER.info(“正在清理索引:[{}],时间:{} 至 {}的历史文档数据…”, indexName, DateTool.format(startTime, DF_FULL), DateTool.format(endTime, DF_FULL));
long currentStartTimeMillis = System.currentTimeMillis();
// 指定操作的索引库
SearchRequest searchRequest = new SearchRequest(indexName);
// 构造查询条件,指定查询的时间范围,每次最多写入1000条数据至内存,减轻服务器内存压力
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(QueryBuilders.rangeQuery(“createTimeStr.keyword”)
.from(DateTool.format(startTime, DF_FULL))
.to(DateTool.format(endTime, DF_FULL)))
.size(1000);
// 设置滚动查询结果在内存中的过期时间为1min
Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1L));
// 将滚动以及构造的查询条件放入查询请求
searchRequest.scroll(scroll).source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 记录要滚动的ID
String scrollId = searchResponse.getScrollId();
SearchHit[] hits = searchResponse.getHits().getHits();
while (hits != null && hits.length > 0) {
// 创建批量处理请求对象
BulkRequest bulkRequest = new BulkRequest();
for (SearchHit hit : hits) {
DeleteRequest deleteRequest = new DeleteRequest(indexName, hit.getId());
bulkRequest.add(deleteRequest);
}
// 执行批量删除请求操作
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
// 构造滚动查询条件,继续滚动查询
SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);
scrollRequest.scroll(scroll);
searchResponse = restHighLevelClient.scroll(scrollRequest, RequestOptions.DEFAULT);
scrollId = searchResponse.getScrollId();
hits = searchResponse.getHits().getHits();
}
// 当前滚动查询结束,清除滚动,释放服务器内存资源
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
restHighLevelClient.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);
LOGGER.info(“清理索引:[{}],时间:{} 至 {}的历史文档数据成功,耗时{}ms”, indexName, DateTool.format(startTime, DF_FULL), DateTool.format(endTime, DF_FULL), (System.currentTimeMillis() - currentStartTimeMillis));
}
LOGGER.info(“[cleanESHistoryData] 定时任务-清理索引:[{}],时间:{}的历史文档数据成功,耗时{}ms”, indexName, twoMonthsAgoDate, (System.currentTimeMillis() - startTimeMillis));
} catch (Exception e) {
LOGGER.error(String.format(“[cleanESHistoryData] 定时任务-清理索引:[{}],时间:{}的历史文档数据失败,耗时{}ms”, indexName, twoMonthsAgoDate, (System.currentTimeMillis() - startTimeMillis)), e);
}
}
}
其中,需要注意以下几点:
- 在 Java 中对 ES 进行操作,这里使用的是 ES 的高级客户端组件
RestHighLevelClient。 @Scheduled注解为自研定时任务工具注解,外界无法使用,在使用定时任务时需要自己选择合适的定时任务框架。DateTool工具类为自研工具类,外界同样无法使用,在以上代码段中就是用于对java.util.Date类型进行转换为字符串,DF_FULL和DateTool.DF_DAY均是常量,它们的值分别为yyyy-MM-dd HH:mm:ss和yyyy-MM-dd。
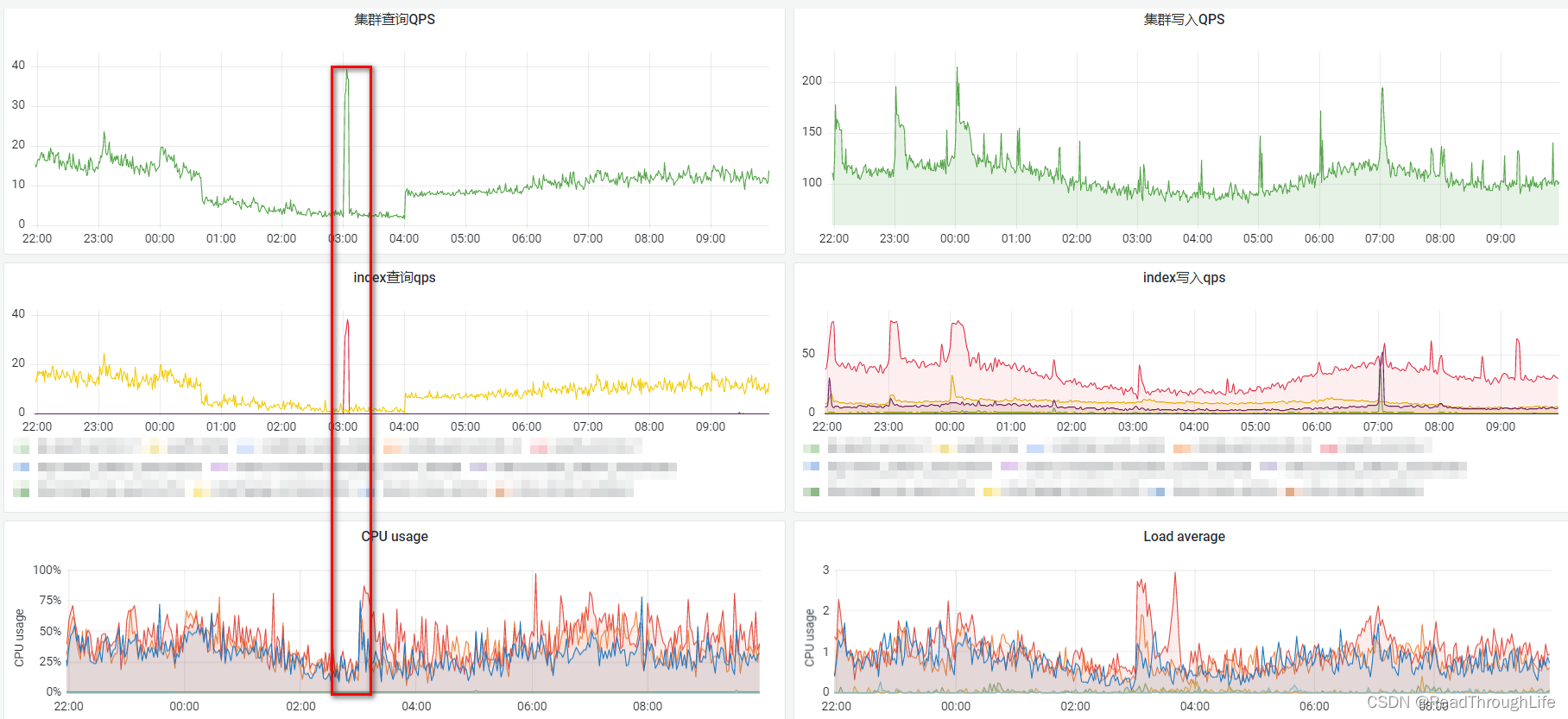
🎈通过观察监控可以发现,在凌晨三点执行定时任务清理 ES 历史数据期间,集群、索引查询 QPS 以及 CPU 利用率指标都明显飙升。因此,清理 ES 数据时一定要避开流量高峰期,避免在流量高峰期清理数据时造成资源实例宕机,造成生产事故。