RAG基础
RAG也在很多行业积极实践中,在【RAG行业交流中发现的一些问题和改进方法】提到了,RAG应该算是核心底层,适配各行各业,依然需要基础组件和各行业的适配应用:
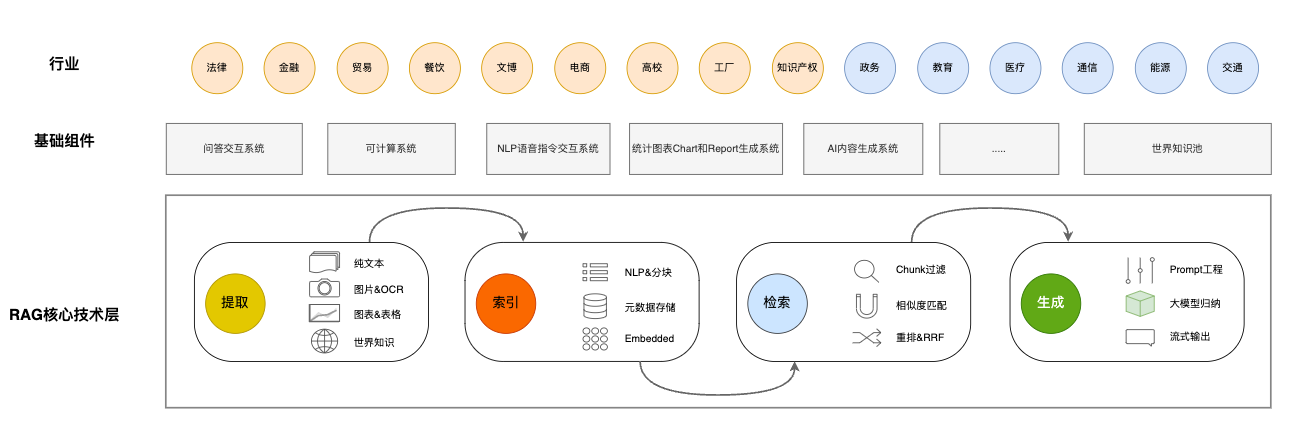
如果我们需要倾向于获取外部知识和重视透明度,RAG是我们的首选。另一方面,如果我们正在使用稳定的标记数据,并旨在使模型更接近特定需求,则微调是更好的选择。

RAG产品的用户旅程总结
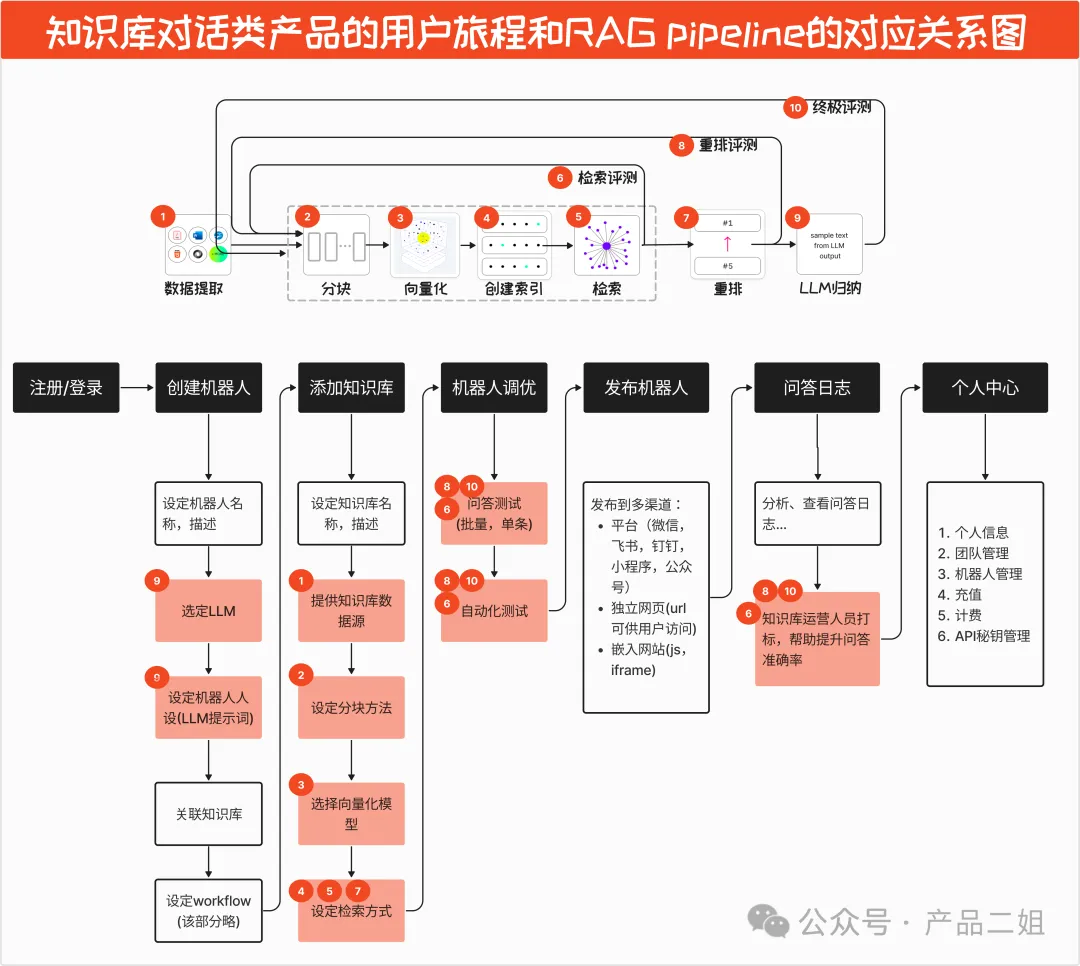
RAG 适用场景:
- 第一:私有数据存在一定频率的动态更新的;
- 第二:需要给出引用原文的;
- 第三:硬件资源(GPU)不是太充足的(即使用RAG也需要微调,但一次微调处处可用,远比每个企业私有库微调一个模型成本低的多)
RAG任务几个具体问题场景【RAG行业交流中发现的一些问题和改进方法】:
- 不擅长小范围的描述性问题回答。例如,哪个主体具有某些特征?
- 不擅长关系推理,即寻找从实体A到实体B的路径或识别实体集团。
- 不擅长时间跨度很长的总结。例如,“列出所有哈利波特的战斗”或“哈利波特有多少次战斗?”
RAG应用程序在这类任务上的表现很差,因为只有少数chunk可以输入到LLM中,而且这些chunk是分散的。LLM会缺少很多辅助信息,比如元数据和世界知识。为RAG寻找最适合的领域,避免强行进入错误的地方,比如千万别让RAG去写诗,它的算数能力也很差。
在【瀚海方舟:ChatGPT应用:如何征服市场眼中的“万能RAG”】一文中提到了非常多针对性的解决方式:
- 内容切片不够好,容易切碎,于是有了段落智能划分;
- 向量生成的质量不可控,于是有了可根据不同QA场景动态生成向量的Instructor;
- 隐式的动态向量不够过瘾,再用HyDE做个中间层:先生成一些虚拟文档/假设文档再做召回,提升召回率;
- 如果向量这一路召回不够,再上关键词召回,传统BM25+向量HNSW融合各召回通路;
- 召回的太多容易干扰答案生成,探究一下Lost in the Middle,搞一搞trick,或者用LLMLingua压缩;
- 嫌召回太麻烦?直接扩到100k窗口全量怼进大模型,LongLoRA横空出世;
- 刚才提到的各个环节需要改进的点太多,懒得手工做,直接交给大模型,用Self-RAG替你完成每个步骤
按照上述的内容全部撸一遍,但是仍然有非常多的问题,然后又需要:
- 要建立元数据过滤单元,不是一上来就全文检索,要有更精细化的索引,根据查询需求先做一遍过滤,比如时间、内容源等等;
- 要建立全文处理单元,解决由于切割带来的信息损耗,需要从离线、在线两部分同时考虑,离线预计算覆盖高频需求,在线覆盖长尾需求;
- 要建立数值计算单元,弥补大模型在做数学题上的缺陷,并且补充足够的金融行业计算公式或企业自定义计算公式;
- 要建立数据库查询单元,区别于“数值计算”,这里主要是指NL2Sql,有些信息查询需要走数据库而不仅仅是文章内容;
- 要建立意图澄清单元,我们允许用户发起五花八门的查询请求,但当查询需求不明确时,系统要有能力帮助用户改进查询语言
RAG应用难点
-
数据难点:文档种类多
有doc、ppt、excel、pdf,pdf也有扫描版和文字版,抽取出来的文字信息,呈现碎片化、不完整的特点。
-
数据难点:不同文档结构影响,需要不同的切片方式
这个可是老大难问题了,不好的切片方式会造成:
- 如果切片太大,查询精准度会低
- 一段完整的话可能被切成好几块,每一段文本包含的语义信息实际上也是不够完整的
- 一些鸡肋切片,其实可以删掉
-
数据难点:内部知识专有名词不好查询
目前较多的方式是向量查询,对于专有名词非常不友好;影响了生成向量的精准度,以及大模型输出的效果。
-
用户提问的随意性 + 大众对RAG的定位混乱
大部分用户在提问时,写下的query是较为模糊笼统的,其实际的意图埋藏在了心里,而没有完整体现在query中。使得检索出来的文本段落并不能完全命中用户想要的内容,大模型根据这些文本段落也不能输出合适的答案。
-
公域与私域知识混淆难定位
提问:乙烯和丙烯的关系是什么?大模型应该回答两者都属于有机化合物,还是根据近期产业资讯回答,两者的价格均在上涨?
-
新旧版本文档同时存在
-
多条件约束失效
提问:昨天《独家新闻》统计的化学制品行业的关注度排名第几?加上约束之后,如何让大模型读懂什么叫“昨天”,又有哪段内容属于《独家新闻》?
-
全文/多文类意图失效
提问:近期《独家新闻》系列文章对哪些行业关注度最高?受限于文档切割,遇到横跨多篇文章,或全篇文章的提问,基本上凉凉了 。
-
复杂逻辑推理
提问:近期碳酸锂和硫酸镍同时下跌的时候,哪个在上涨?除非原文中有显性且密集型相关内容,大模型可能能够直接回答正确,否则凉凉的概率极高。
而用户在提问这类问题时,往往是无法在某一段落中直接找到答案的,需要深层次推理。
-
金融行业公式计算
提问:昨天哪些股票发生了涨停?如何让大模型理解“涨停”意味着 (收盘价/昨日收盘价-1)≥10%
-
人工搜索效率低下
人类并不擅长在搜索系统中输入他们想要的东西,比如打字错误、模糊的查询或有限的词汇,这通常会导致错过明显的顶级搜索结果之外的大量信息。虽然RAG有所帮助,但它并没有完全解决这个问题。
-
长下文长度
检索内容过多,超过窗口限制怎么办 ?如果 LLMs 的上下文窗口不再受限制,RAG 应该如何改进?
-
向量检索的弊端
向量检索是基于词向量的相似度计算
如果查询语句太短,比如只有一个ID、一个哈希码或者一个产品名称,那么它们的词向量可能无法反映出它们的真实含义,也无法和其他相关的文档进行有效的匹配。这样就会导致向量检索的结果不准确,甚至出现一些完全不相关的内容。类似的,如果我们查询“8XLARGE64”,“99.9%”,这样的一些关键字时,向量搜索会得出一些毫不相干的内容,以至于让背后的大模型毫无用武之地,甚至可能被误导
解决方案
知识库文档预处理
在载入知识库文件的时候,直接上传文档虽然能实现基础的问答,但是,其效果并不能发挥到最佳水平。因此,我们建议开发者对知识库文件做出以下的预处理。 以下方式的预处理如果执行了,有概率提升模型的召回率。
-
使用
TXT / Markdown等格式化文件,并按照要点排版 -
减少文件中冲突的内容,分门别类存放数据
-
减少具有歧义的句子
-
减少单个文件的大小,减少文件中的特殊符号
-
结构复杂的先根据大模型以问答对的形式输出
-
对文档合理分块
不合理的分块会导致很多问题,过小的chunk导致上下文信息的缺失;连贯文章因为chunk而进行拆分
-
数据清洗
文档智能分块与解析
-
文档版面布局(Layout)分析
-
图片的信息抽取
-
PDF 解析
搜索架构、索引构建、Embedding
检索的主要方式还是这几种:
- 相似度检索:前面我已经写过那篇文章《大模型应用中大部分人真正需要去关心的核心——Embedding》种有提到六种相似度算法,包括欧氏距离、曼哈顿距离、余弦等。
- 关键词检索:这是很传统的检索方式,但是有时候也很重要。刚才我们说的元数据过滤是一种,还有一种就是先把chunk做摘要,再通过关键词检索找到可能相关的chunk,增加检索效率。据说Claude.ai也是这么做的;
- SQL检索:这就更加传统了,但是对于一些本地化的企业应用来说,SQL查询是必不可少的一步,比如我前面提到的销售数据,就需要先做SQL检索。
query改造、转换、意图识别
-
Query transformations:Query拆解,如果查询很复杂,LLM 可以将其分解为多个子查询。
-
HyDE,生成相似的,或者更标准的prompt模板,然后去检索文档chunk
-
Query向量化/文档向量化前加特定的Prompt,
-
query逻辑链的多跳实现
-
增加追问机制
这里是通过Prompt就可以实现的功能,只要在Prompt中加入“如果无法从背景知识回答用户的问题,则根据背景知识内容,对用户进行追问,问题限制在3个以内”。这个机制并没有什么技术含量,主要依靠大模型的能力。不过大大改善了用户体验,用户在多轮引导中逐步明确了自己的问题,从而能够得到合适的答案。
-
历史聊天融入成为统一的Prompt
-
意图识别模块
RAG的路由 + 代理
路由其实有一点意图识别 + 分发任务的意味,本节参考【RAG 高效应用指南 04:语义路由】,有几种路由方式:
- 组件路由:路由到不同的组件类型,比如将查询传递给 Agent、Vector Store,或者直接传递给 LLM 进行处理
- Prompt 路由:根据 question 的不同路由到不同的 prompt template
RAG路由的实现:
- 基于大语言模型(LLM)识别用户意图
- 基于传统的 NLP 技术,训练一个分类模型,对用户的查询类型进行分类
- 根据用户查询与预设话术模板的相似性进行匹配
-
LLM Prompt
基于 LLM Prompt,就是通过 prompt 来判断用户的 query 属于哪个意图,当然,我们不可能穷举用户 query 的所有意图,所以对于不在预设意图的用户 query,我们一般还会进行兜底处理。
响应合成Response synthesiser
这是任何 RAG 管道的最后一步 - 根据我们仔细检索的所有上下文和初始用户查询生成答案。
最简单的方法是将所有获取的上下文(高于某个相关阈值)与查询一起连接并立即提供给 LLM。
但是,一如既往,还有其他更复杂的选项,涉及多个 LLM 调用,以细化检索到的上下文并生成更好的答案。
响应合成的主要方法是:
- 通过将检索到的上下文逐块发送到 LLM 来迭代完善答案
- 将query的上下文一起丢进来以适应提示
- 根据不同的上下文块生成多个答案,然后连接或总结它们。
query 意图识别+意图补充+意图修复 环节
- 意图识别方式一:多关键词/主题词提取与检索
大致方案罗列:
-
基于传统 NLP 的成分句法分析,提取名词短语;再通过短语间的依存关系,生成关键词列表
-
从完整语句的 Embedding,切换为关键词 Embedding:
-
- 知识库构建时。基于单知识点入库,入库时提取关键词列表进行 Embedding,用于检索。
- 查询时。对用户的问题提取关键词列表进行 Embedding 后,从本地知识库命中多条记录。
-
将单问句中的多知识点拆解后检索,将召回的多条记录交付给 LLM 整合。
该方法的优势在于:
- 相比传统 Embedding,大幅提升召回精准度。
- 支持单次交互,对多知识点进行聚合处理。而不必让用户,手动分别查询单个知识点,然后让 LLM 对会话历史中的单个知识点进行汇总。
- 使用传统 NLP 在专项问题处理上,相比 LLM 提供更好的精度和性能。
- 减少了对 LLM 的交互频次;提升了交付给 LLM 的有效信息密度;大大提升问答系统的交互速度。
- 意图识别方式二:中心化大模型做语义识别
通过 System Role 告知LLM 需要提取槽位信息,让 LLM通过多轮对话引导用户给出所有槽位信息。
-
意图补充、修复、改写
-
多轮对话意图继承能力
-
过长提问的总结
-
拒绝回复
面对用户提问的内容并不是目前我们预期支持的领域,我们就需要进行拒绝,并给用户一些回复,让用户不至于那么不舒服。常见的策略一般有这些:
- 一句写死的回复:“哎呀,这方面的问题我还不太懂,需要学习下”。
- 用大模型生成,例如借助prompt引导生成一些安抚性的回复,“对不起,你问的[]问题,我好像还不太懂。你可以试试问问别的”。
- 使用推荐问或者追问的策略。(你是否在找以下几个问题XX;你描述的我好像不太懂,能再补充补充吗)