1. 模型训练&存储的基本概念
1.1 M-P神经元模型
在生物神经网络中,每个神经元与其他神经元相连,当它“兴奋”时,就会向相连的神经元发送化学物质,从而改变这些神经元内的电位;如果某神经元的电位超过了一个“阈值”,那么它就会被激活,即“兴奋”起来,向其他神经元发送化学物质。
-
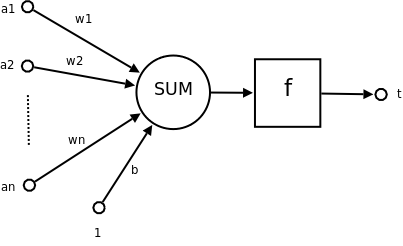
a_1,a_2 ~ a_n 为各个输入的分量
-
w_1,w_2 ~ w_n 为各个输入分量对应的权重参数
-
b 为偏置
-
f 为激活函数,常见的激活函数有tanh,sigmoid,relu
-
t 为神经元的输出
1.2 多层神经网络
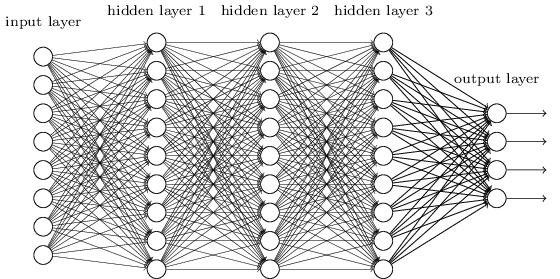
多层神经网络就是由单层神经网络进行叠加之后得到的,所以就形成了层的概念,常见的多层神经网络有如下结构:
-
输入层(Input layer),众多神经元(Neuron)接受大量输入消息。输入的消息称为输入向量。
-
输出层(Output layer),消息在神经元链接中传输、分析、权衡,形成输出结果。输出的消息称为输出向量。
-
隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。隐层可以有一层或多层。隐层的节点(神经元)数目不定,但数目越多神经网络的非线性越显著,从而神经网络的强健性(robustness)更显著。
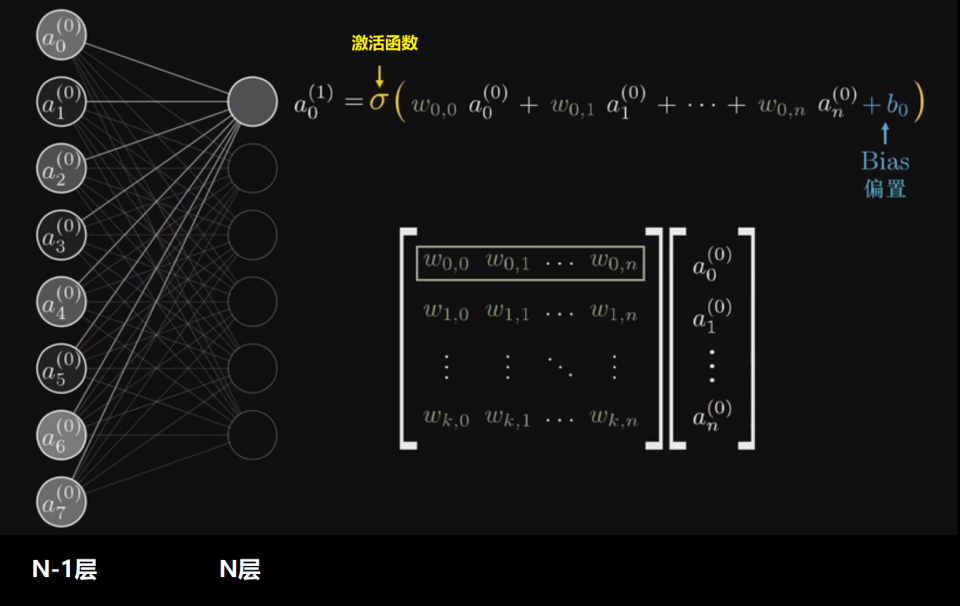
示意图如下:
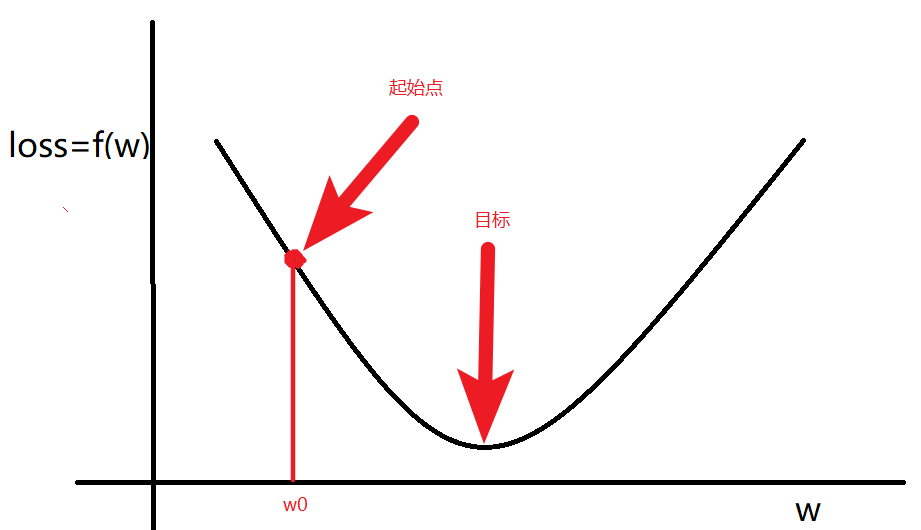
1.3 梯度下降
判断模型好坏的办法:
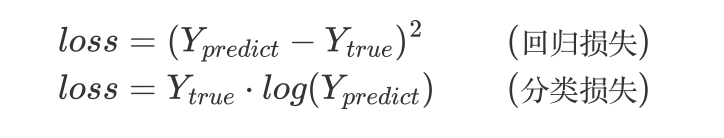
求梯度:
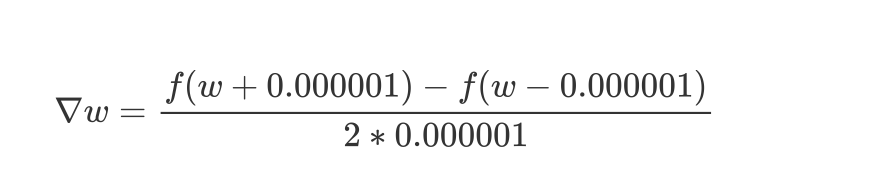
梯度就是多元函数参数的变化趋势(参数学习的方向),只有一个自变量时称为导数
梯度下降就是找出参数 W,使损失函数 loss最小
1.4 误差反向传播
误差反向传播(error BackPropagation,简称BP)算法。BP学习算法通常用在最为广泛使用的多层前馈神经网络中。在神经网络中,我们有非常多的参数,所以会导致∇ L(θ)向量很长,反向传播可以很好的处理这种情况。所以反向传播也是梯度下降,只不过它是一个比较有效率的演算法
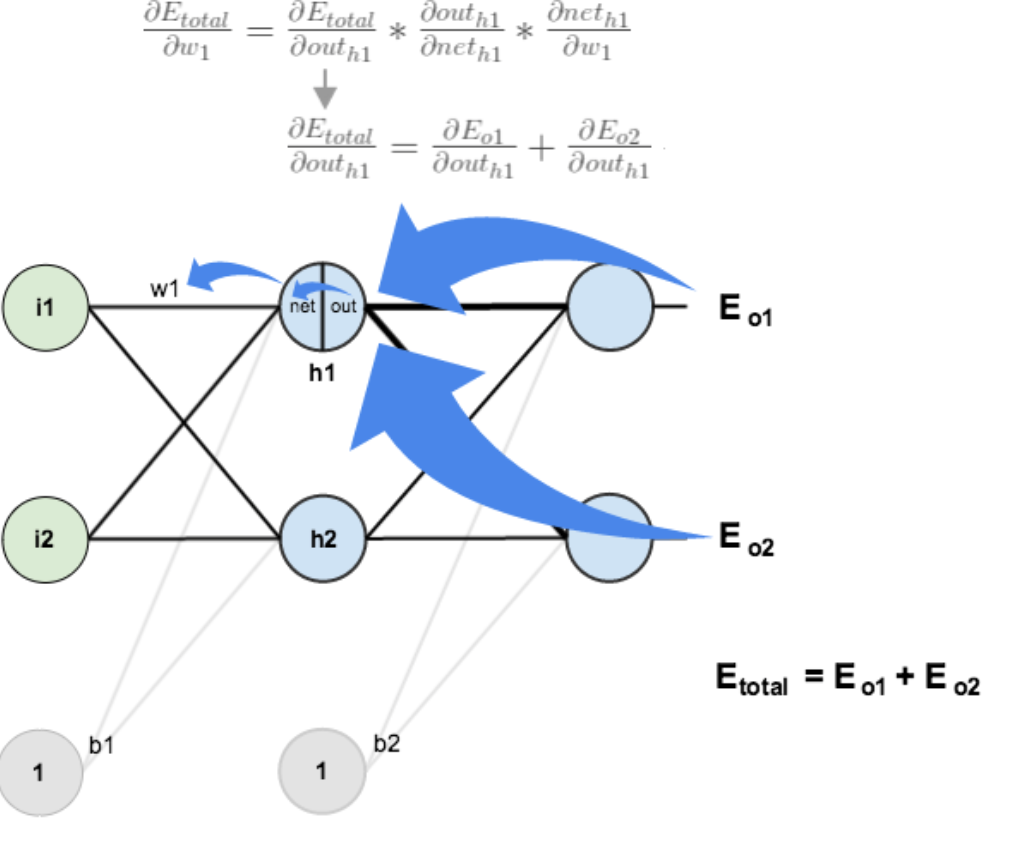
BP算法的主要流程可以总结如下:
输入:训练集D=(xk,yk)mk=1D=(xk,yk)k=1m; 学习率;
过程:
1. 在(0, 1)范围内随机初始化网络中所有连接权和阈值
2. repeat:
3. for all (xk,yk)∈D(xk,yk)∈D do
4. 根据当前参数计算当前样本的输出;
5. 计算输出层神经元的梯度项;
6. 计算隐层神经元的梯度项;
7. 更新连接权与阈值
8. end for
9. until 达到停止条件
输出:连接权与阈值确定的多层前馈神经网络
通过多轮反向传播训练,获得最好的模型效果
2. 需求背景
大模型/AIGC/多模态等技术的发展,已经逐步开始到了生产落地的时间节点,这些新的技术趋势不仅提高了算力的需求,也给底层基础设施带来了更大的挑战。
在存储方面,经典的微服务应用通过云原生化的方式,兼顾了性能和效率。但对于计算量增量最大的分布式 AI 训练、大数据等计算密集型应用,数据局部性直接影响了计算作业的运行效率与吞吐,网络 I/O 的消耗还间接拉高了带宽成本,且在可预见的场景中,数据集规模还会以较高的速率保持增长,如何加速数据访问,将是提升计算任务运行效率的同时降成本的关键。
大模型训练/多媒体等场景的数据集以图片和音频文件为主,天然适合将数据托管在 OSS 对象存储上,也是目前线上大多数计算作业的存储选型,以训练场景为例,具有以下读数据的特征:
- 数据集顺序的随机化处理造成传统的单机缓存策略失效;
- 多个 epoch 会对数据集进行多轮读取;
- 作业间可能复用同个数据集;
2.1 训练流程中的面临的挑战
如图展示了一个典型的 AI 训练过程。
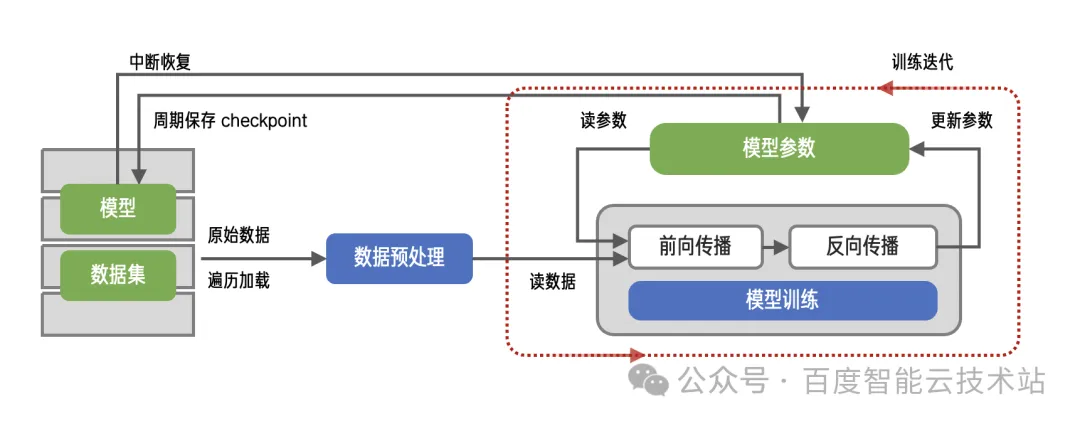
训练的计算会经过很多很多轮,每一轮称为一个 epoch,每一轮 epoch 重复以下过程:
-
shuffle:首先,为了让算法达到比较好的鲁棒性、加快收敛速度,把整个训练使用的数据集随机打散,类似于我们打牌前先把牌洗一遍,这个过程称之为 shuffle。至于样本集包含哪些样本,是从存储系统读取的。 shuffle 需要把整个数据集做一次打散,在这个打散完成前,其实是是没有数据可以计算的,也就意味着这是一个纯粹等待的时间。这个时间从根本上无法完全消除,只能通过更高效的实现方法、更好的存储性能,把它在整体时间中的占比降到一个可接受的比例。
-
读batch:shuffle 确定了数据集样本的读取顺序,接下来,数据会进一步分成很多个批次(batch),算法接下来就读取一个 batch 训练一次,直到整个样本集都处理完。这个过程涉及到大量的读操作。这个不断重复的过程,现代的一些训练框架其实已经做了很多的优化,目前在大部分框架里,“读 batch” 的这个过程,由所谓的 Data Loader 模块来完成,它的思路是让读的过程和计算本身并行起来。这对 GPU 训练的效果更明显一些。
-
checkpoint:一次训练持续的时间可能非常长,数个小时甚至数天数个月都有可能。所有的机器都没有办法保证在训练的过程百分之百没有故障发生,故障发生后,用户不会想从头开始计算,能恢复到一个较近时间点,从那个时间点重新开始计算是最理想的。因此需要有故障恢复的机制,通常的做法是周期性的把训练的状态保存下来,故障发生后,加载保存的状态继续计算。这个机制叫 checkpoint。checkpoint 对存储系统来说是写操作。checkpoint 不一定每个 epoch 都保存,且是对存储系统比较友好的顺序大 I/O,整体耗时占比较小,一般分析时会忽略它的影响。如果遇到 checkpoint 慢的情况,可以做细致的分析。

2.2 架构设计中面临的挑战
- 计算存储分离架构提升了数据访问与计算水平扩展的灵活度,但导致了数据访问高延时,对于训练等对数据缓存亲和性有显著诉求的场景延迟不友好:业务团队使用的机器学习任务在训练过程中要实时频繁访问 OSS 上的数据(以样本数据集与 checkpoint 为主),在 OSS 带宽受限或者压力较大时,访问 OSS 上数据速度比访问本地文件速度要慢 1~2 个数量级,且占据了用户大量的带宽成本;
- Kubernetes 调度器数据缓存无感知,同一数据源多次运行访问依旧慢:在现实应用中深度学习任务运行会不断重复访问同一数据,包括相同模型不同超参的任务、微调模型相同输入的任务、以及 AutoML 任务等。这种深度学习任务的重复数据访问就产生了可以复用的数据缓存。然而,由于原生 Kubernetes 调度器无法感知缓存,导致应用调度的结果不佳,缓存无法重用,性能难以提升;
- OSS 成为数据并发访问的瓶颈点,稳定性挑战大:大量机器学习任务在同时训练时都会并发访问后端 OSS 存储。这种并发机器学习训练造成的 IO 压力比较大,OSS 服务成为了性能单点,一旦 OSS 带宽出现瓶颈则会影响所有机器学习任务;
- 训练文件分散,文件规模大,元数据压力:机器学习任务的训练数据文件通常会分散在不同路径下,读取文件需要耗费大量的时间在 list 操作上。对象存储的 list 操作性能较差,在进行大规模 list 时对 OSS 元数据压力很大,经常出现超时或者 list 失败的情况。
- IO 稳定性对业务运行有直接影响:导致业务表现不稳定,甚至造成任务失败。基于 FUSE 的存储客户端更容易发生这样的问题,一旦这些问题无法自动修复,则可能中断集群训练任务。时刻保持 IO 的稳定性是保证业务顺利运行的关键途径之一。
我们发现 IO 性能问题会导致 GPU 等昂贵计算资源不能被充分利用。机器学习自身训练的特点导致了数据文件访问较分散,元数据压力较大。如果能够精细化地缓存元数据和文件数据,那么一方面可以提高缓存效率和磁盘利用率,另一方面也可以解决文件查找操作带来的元数据损耗。
3. 技术要点
| 技术点 | 解释 | 特点 |
|---|---|---|
| 减少元数据操作占比,转为顺序读写操作 | 进行数据集打包,削减文件规模 | 需要在应用层改造,推广性差 |
| 高性能硬件设施 | 存储介质:SSD、DRAM 等存储介质进行读取加速 网络:高性能网络(如 RDMA)提高网络 IO |
费用高、本方案不涉及该方向 |
| 计算能够充分利用本地化数据访问 | 缓存系统:利用数据集的只读特点,将元数据和数据缓存到计算节点,通过应用对于部分数据的本地读取,减小数据访问延时和降低对底层 OSS 的带宽压力。尽量减少 I/O 在计算流水线中的耗时,从而加速机器学习模型的训练速度,并提升集群的 GPU 使用率。 | |
| 提高系统扩展能力,缩短 IO 路径 | 并行文件系统,元数据和数据在存储节点上打散分布,内核客户端缩短软件 IO 路径 | |
| 充分发挥热点数据集的缓存节点优势 | 在对用户无感知的前提下,智能地将任务调度到数据缓存节点上,从而使得常用模型训练程序越来越快。 | |
| 元数据缓存和数据缓存分离 | 可单独对文件进行元数据缓存,缓存策略定制化。 | |
| 通过 POSIX 接口读取数据 | 统一数据访问接口。这样无需在模型开发和训练阶段使用不同的数据访问接口,降低开发机器学习模型程序的成本。 | |
4. 解决方案
4.1 Fluid 介绍
Fluid 运行在 Kubernetes 上,是一个可扩展的分布式数据编排和加速系统,由南京大学、阿里云、Alluxio 开源
社区联合发起并开源于 2020 年 9 月。2021 年 4 月 27 日,云原生计算基金会(CNCF)宣布通过全球 TOC 投票接纳 Fluid 成为 CNCF 官方沙箱项
目。Fluid 可以将分布式缓存系统(例如 Alluxio 和 JuiceFS)转换为可观察的缓存服务,具有自我管理、弹性伸缩和自愈能力,并通过支持数据集操作实现。同时,通过数据缓存位置信息,Fluid 可为使用数据集的应用程序提供数据亲和性调度。
在计算和存储分离的趋势中,Fluid 的目标是以高级抽象的方式使 AI/大数据应用能够更有效地使用来自任何存储的数据,而无需对应用程序本身进行更改。
与传统的基于 PVC 的存储抽象不同,Fluid 采用了面向应用的视角抽象“在 Kubernetes 上使用数据的过程”。它引入了弹性数据集的概念,并将其作为 Kubernetes 中的一等公民来实现数据集的 CRUD 操作、权限控制和访问加速。
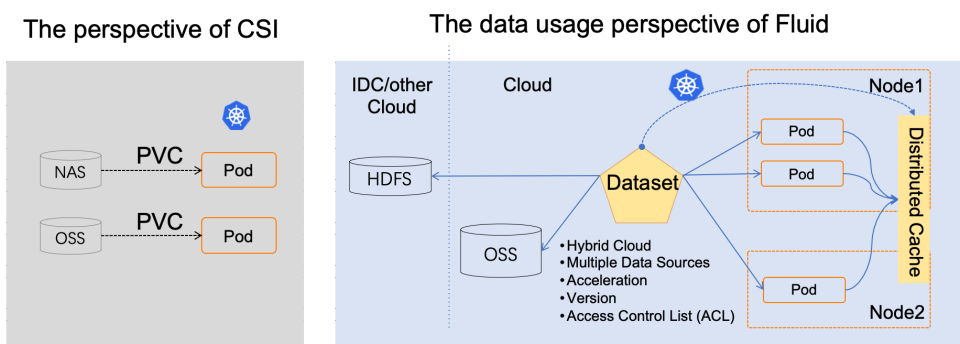
通过基于 Kubernetes 上的 Fluid 驱动的数据抽象层,数据就好像液体一样,在存储源(如 HDFS、OSS、Ceph)和 Kubernetes 上的云原生应用之间波动。它可以灵活地移动、复制、驱逐、转换和管理。此外,所有的数据操作对用户来说是透明的。用户不需要担心远程数据访问的效率,也不需要担心数据源管理的便利性。用户只需要访问从 Kubernetes 原生数据卷中抽象出来的数据,剩下的任务和细节都由 Fluid 处理。
Fluid 旨在通过提供 Fluid 的通用框架,将不同的分布式缓存系统(如 Alluxio、JuiceFS、Vineyard、CubeFS 等)转化为在 Kubernetes 中自管理、自扩展、自修复和可观察的缓存服务。
Fluid 在以下两个方面体现其价值:
-
利用 Kubernetes 平台的能力,通过每个分布式缓存提供程序的 Kubernetes Operator 交付其服务,并自动化管理员的任务:部署、引导启动、配置、提供、扩展、升级、监控、数据预取、数据迁移和资源管理。
-
帮助用户通过将第三方缓存系统与 Kubernetes 调度和弹性相结合,以及将其与特定应用程序数据使用场景和方法对齐,充分利用分布式缓存。
4.2 Fluid 架构
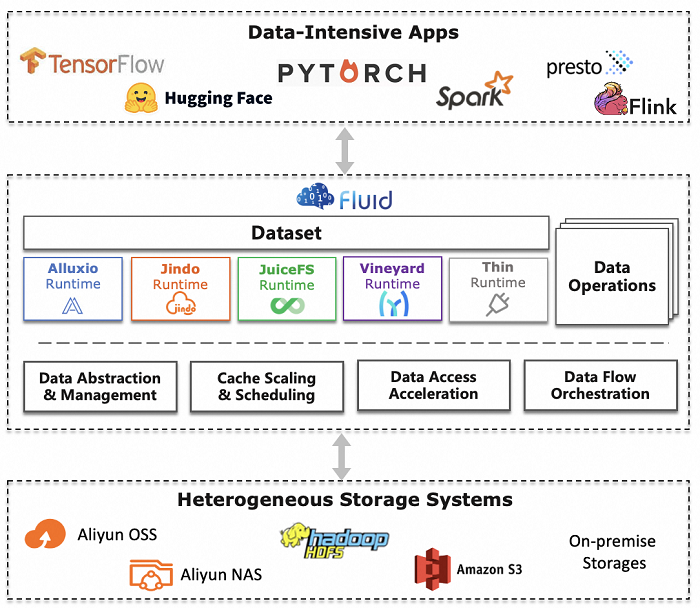
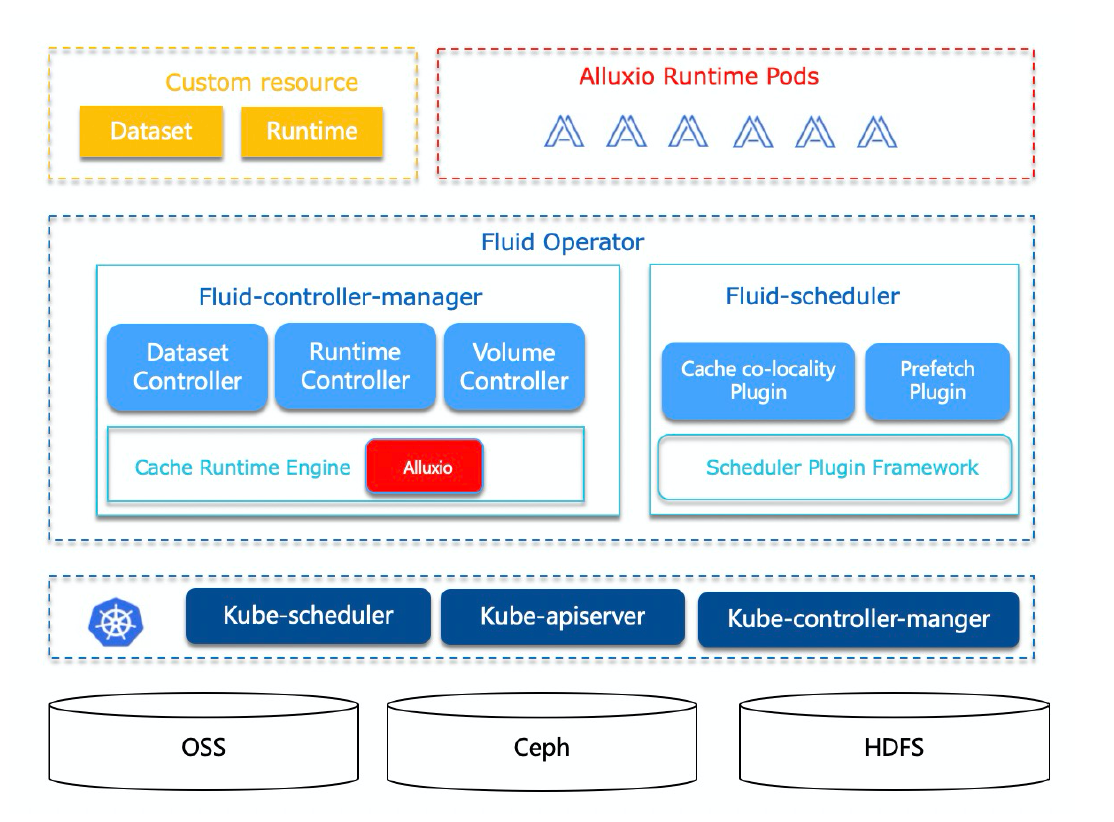
基本概念
- Dataset:数据集是逻辑上相关的一组数据的集合,会被运算引擎使用,比如大数据场景的 Spark,AI 场景的 TensorFlow。Dataset 的管理有安全性、版本管理、数据加速等多个维度。Fluid 通过 Kubernetes 自定义资源对象(CRD)扩展数据集资源对象(Dataset CRD),提供存储无感知的数据对象,实现对不同存储系统(如 HDFS、OSS、Ceph)的统一抽象定义与管理,支持可观测性和弹性伸缩。
- Runtime:实现数据集安全性、版本管理、数据加速等能力的执行引擎,定义了一系列生命周期的接口。通过这些接口,利用分布式缓存技术实现数据集的管理、加速数据集读写。Fluid 通过 Kubernetes 自定义资源对象(CRD)扩展执行引擎资源对象(Runtime CRD),自定义并管理分布式数据缓存引擎。Fluid 通过管理和调度 Runtime 实现数据集的可见性、弹性伸缩、数据迁移。Fluid 支持多种 Runtime
- UFS:底层文件系统
- Metadata:元数据信息,存储引擎需要维护一般在 Master 中,内容包括 UFS 的文件名、文件数量等基本信息。
- FUSE(Filesystem in Userspace):用户态文件系统,即用于访问存储引擎的服务端,使进程可想直接操作文件系统一样访问远程存储引擎的数据。
Pod -> Fuse(client) -> Cache(Server) -> UFS
4.3 Fluid 组件构成
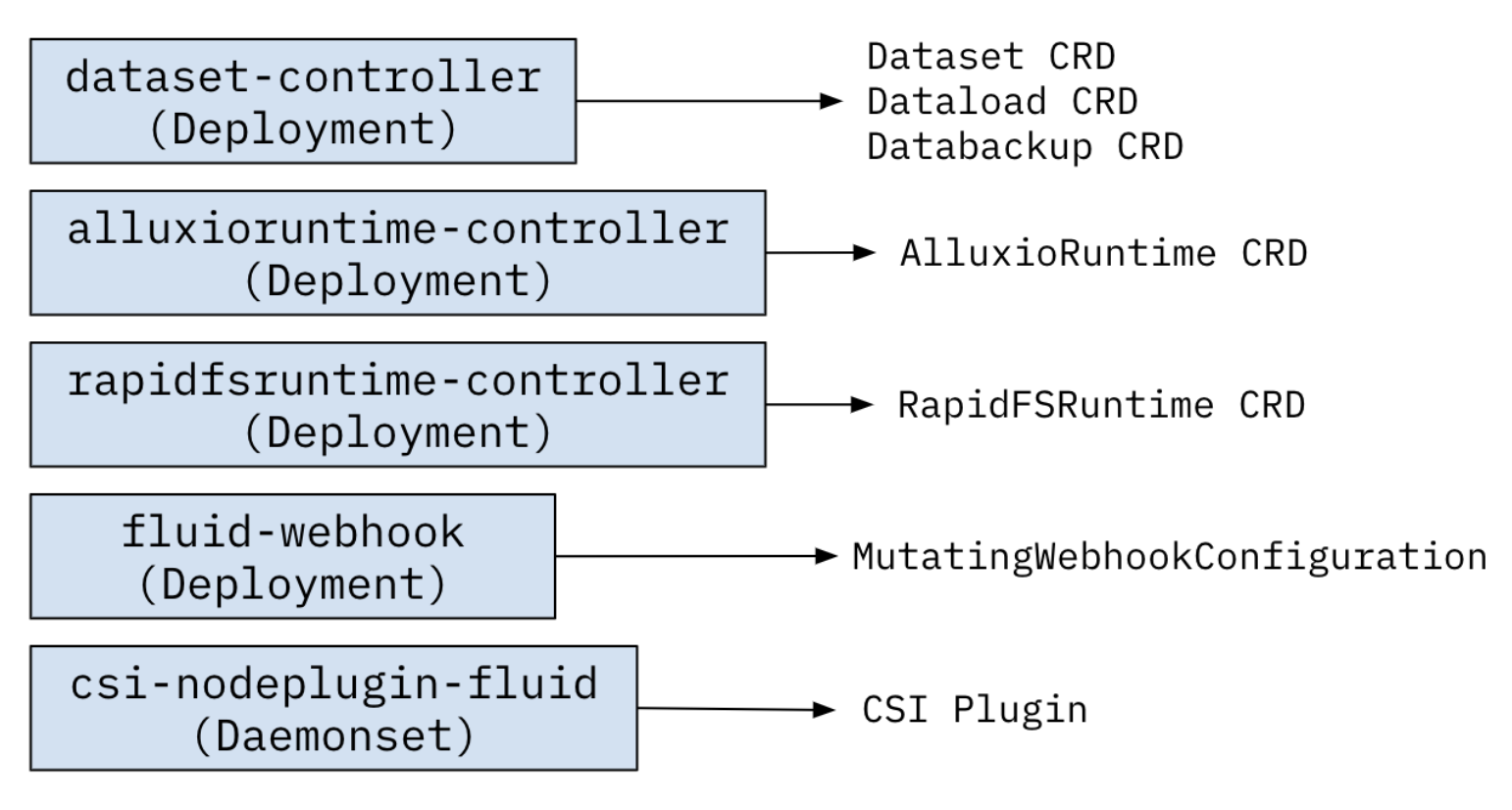
-
控制器(Fluid-controller-manager):从逻辑上,每个控制器都是单独的进程,为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
-
Dataset Controller:负责Dataset的生命周期管理,包括创建,与Runtime的绑定和解绑,删除。
-
Runtime Controller:负责Runtime的生命周期管理,包括创建,扩缩容,缓存预热和清理的触发,删除等操作。
-
Volume Controller:负责Dataset对应的数据卷的创建,删除。
-
-
调度器(Fluid-scheduler):负责在调度过程,结合数据缓存的信息,选择符合条件的节点。
-
Cache co-locality Plugin:结合Runtime中的数据缓存信息,对于使用数据集的应用进行调度。无需用户指定缓存节点。
-
Prefetch Plugin:在调度过程中,根据应用使用数据的特性触发Runtime进行数据预热。
-
-
CSI Node Plugin Deamonset
-
csi plugins 分别为 controller server 和 node server 的 CSI 标准 gGRPC Server
-
controller server 负责与与单机无关的逻辑处理,其中最主要的工作是为调度上的节点打一个 Label 用于 FUSE Deamonset 在该节点上部署客户端
-
node server 负责在节点上做一些 mount umount 操作然后 kubelet 将目标路径再挂载到容器内
-
-
fuse-recover 定时检查节点上的 Fuse 容器若有重启,需要对有使用到 Fluid 的 Pod 的目标 Volume 在节点上重新做 mount 操作
-
-
Webhook:主要用于亲和性调度,例如对 Dataset 配置了亲和性后,后续创建使用加速 PVC,会经过该 mutating webhook 并也被自动加上亲和性配置
4.4 Fluid Runtime 支持
Alluxio
Alluxio 自称是数据编排技术,简单的说,就是在计算节点之间和存储系统之间建立一个桥梁,在将不同存储系统整合到一个全局 Namespace,并提供多种统一的访问接口,屏蔽系统间的差异。当然,这只是理论上想要达到的效果,实际上在相同的接口下,不同系统的表现也会略有差异。Alluxio 最常见的用途就是当作一层分布式缓存,来加速对底层存储系统(对象存储、HDFS 等)的访问。
Alluxio 中主要包含 Master 和 Worker 两种角色,Master 负责集群管理以及元数据缓存,Worker 负责数据缓存。Master 通过 ZooKeeper 或者 Raft 来做 Failover。Worker 之间在工作上是独立的。
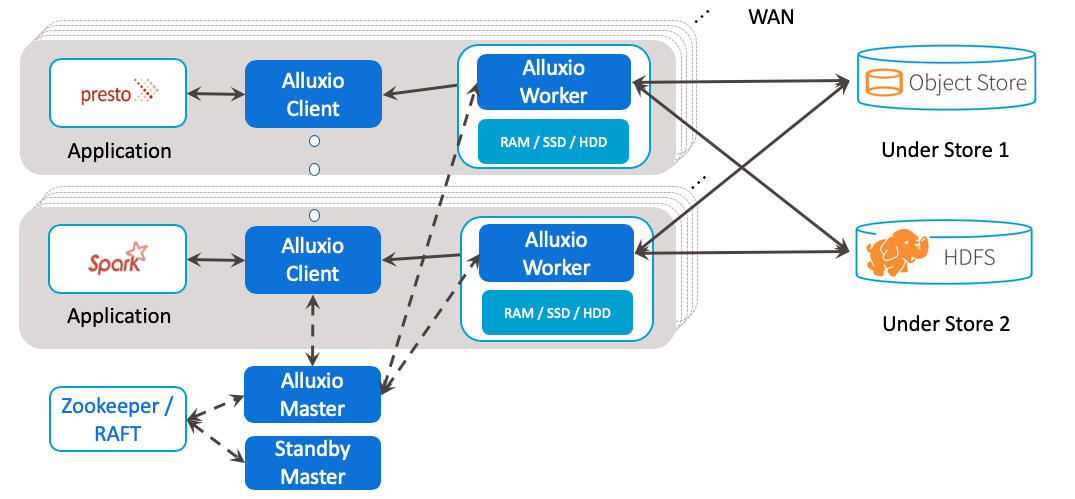
Alluxio 将对接的底层存储称为 Under Store。用户可以自己选择某个 Under Store 的目录被访问时的元数据加载策略,例如完全不缓存、缓存单个目录、缓存目录的整个子树。缓存子树官方推荐的性能比较好的模式。Alluxio 同时还提供了定期同步机制来发现 Under Store 中不经过 Alluxio 的变更。加载的缓存数据会写日志同步到从 Master。Alluxio 1.X 元数据只能存储到内存中,采用 Federation 来解决扩展性问题,2.X 版本支持了单点模式下元数据存放到 RocksDB。
Alluxio 中某一个具体的数据缓存存放在哪个 Worker 上,有很多种策略,有可能是触发访问的 Worker 本地缓存,也有可能是根据某个策略选出来的远端 Worker。不管是那种策略,最终位置信息都由 Master 进行记录。Alluxio 的缓存数据支持存放在内存、SSD、HDD 上,以及缓存多份。
Alluxio 的理念是比较好的,但时至今日已经很庞大,在工程实现细节上缺少精细的打磨,例如,基于 JNR 的 FUSE 性能一言难尽、处理数据缓存的过程中过多的和 Master 进行交互。
JuiceFS
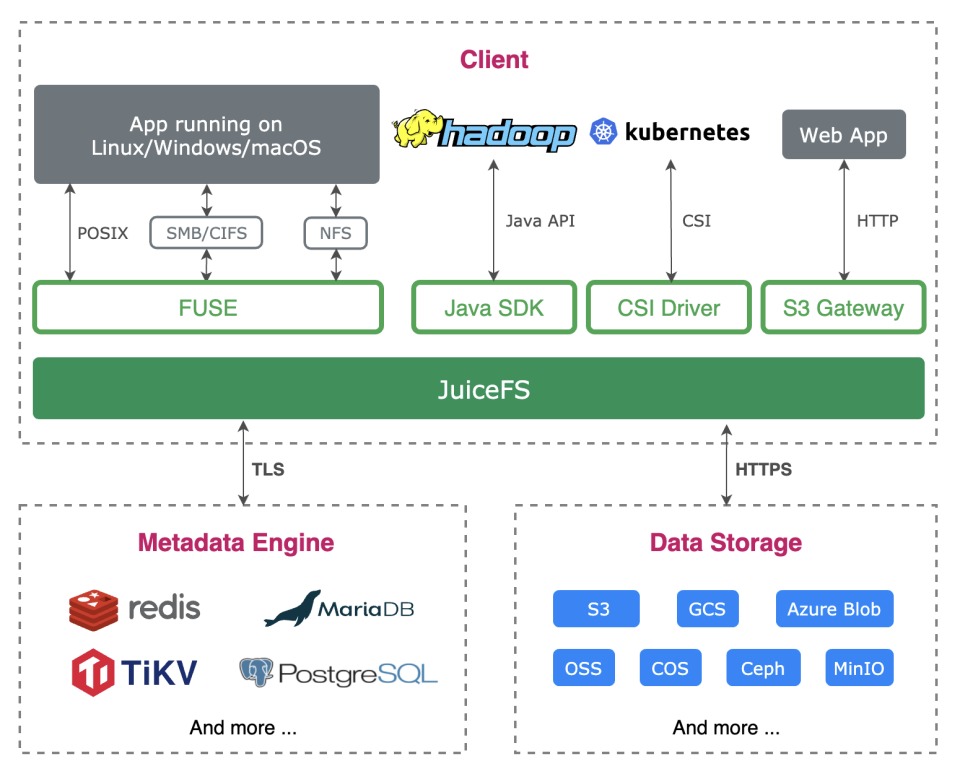
JuiceFS是构建于对象存储之上的 POSIX 兼容文件系统。系统将对象存储作为可靠的数据存储系统,自身只维护元数据和数据缓存。
对象存储有几个特点:
-
不支持随机写,一个对象写完无法部分修改
-
一个对象只有完整上传了才可见
这些特点导致 S3A 这类试图在对象存储上直接模拟 HDFS/POSIX 的粗糙封装和真正的文件系统行为相距甚远。为了解决这个问题,JuiceFS 在对象存储只上组织了一层数据结构,如下图所示:
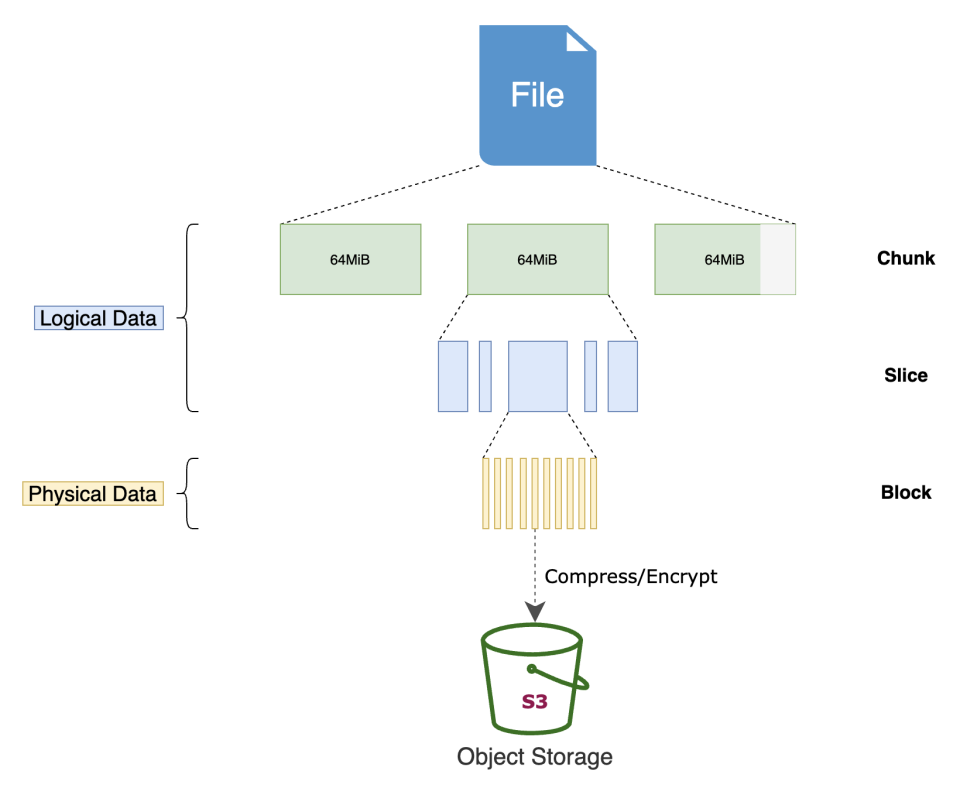
整个结构下包含以下几层:
-
Chunk:每一个文件的逻辑地址空间首先按照 64MB 切分成 Chunk
-
Slice:每一个 Chunk 有若干 Slice 索引,每个 Slice 代表一段有效的数据范围
-
Block:Slice 指向的数据被进一步切分成 4MB 的 Block,这些 Block 才是实际存储到对象存储中的数据,每一个是一个对象
举一个例子来说明这个数据结构是怎么工作的(仅用于说明原理):
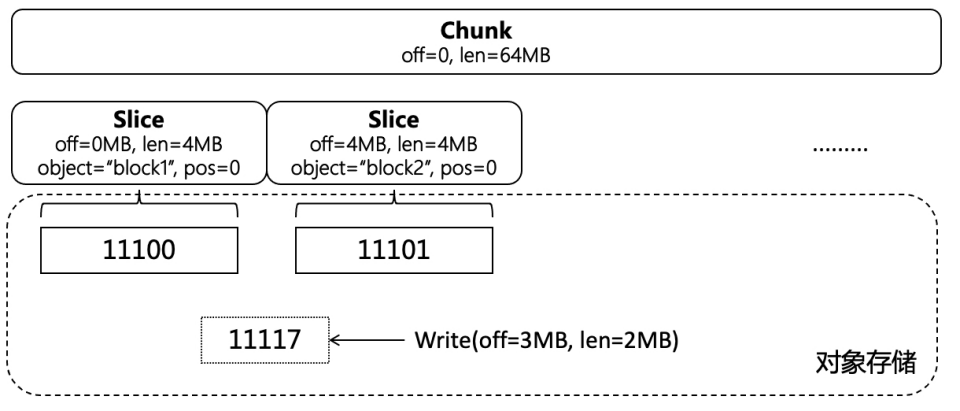
一开始的时候,每个 Slice 指向一个 4MB 的 Block,Block 中没有无效数据。然后,用户在 offset = 1MB、length = 2MB 的位置写入了新数据,数据写到对象存储持久化后,更新 Slice 列表,相邻范围的 Slice 也会同步更新,只指向部分有效的数据。
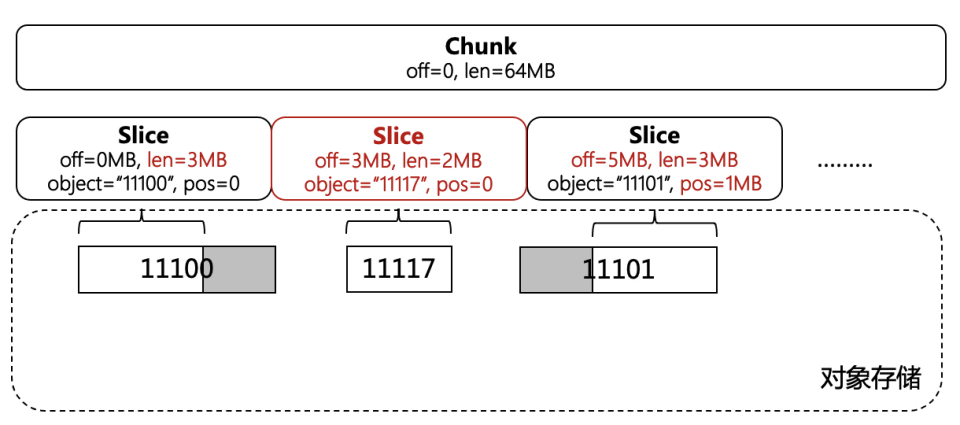
JuiceFS 有一个 3 副本的元数据节点服务,上述文件的组织结构在该服务中存储,目录树也在其中维护。这部分未开源,开源版本仅支持将元数据存放到 Redis 或 Mysql 兼容的数据库中,通过事务保证元数据的正确性,依赖 Redis 或数据库本身来保证可靠性。
JuiceFS 由于自己在对象存储上组织了一套数据结构,其存储的数据只能通过 JuiceFS 访问。
依赖底层对象存储的并发能力,延迟比较高,离本地计算节点距离较远,适合云原生、大数据等场景。
JindoFS
JindoFS 提供了 3 种模式:
-
SDK 模式:Hadoop HCFS S3A 的一个优化加强版,可以不依赖 JindoFS 集群当作一个纯粹、更好用的 S3A SDK 使用
-
Cache 模式:和 Alluxio 类似,提供分布式缓存能力
-
Block 模式:和 JuiceFS 提供的能力一样
JindoFS 的架构和 JuiceFS 比较类似,底层使用 C++ 实现,基于 brpc + braft,Namespace 本地存储使用了 RocksDB,可异步同步至 OTS。
JindoFS 的 SDK 和 Cache 模式包含一个针对对象存储优化的 Spark Job Commiter,取代原有基于 rename 的 Commiter。由于平坦目录的缘故,rename 版本 Job Commiter 使用 “拷贝+删除” 的方式来模拟 rename,代价极为昂贵。
该产品是阿里大数据、云原生 AI 生态的一个重要组件,属于 SmartData 的一部分,和阿里大数据、AI 解决方案的整合做得比较好。
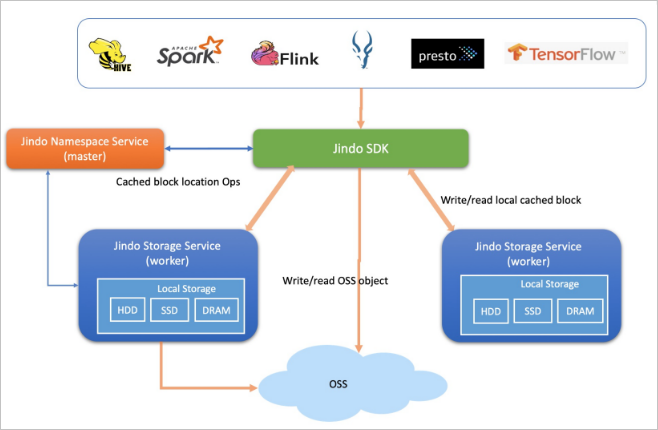
整体架构示意图:
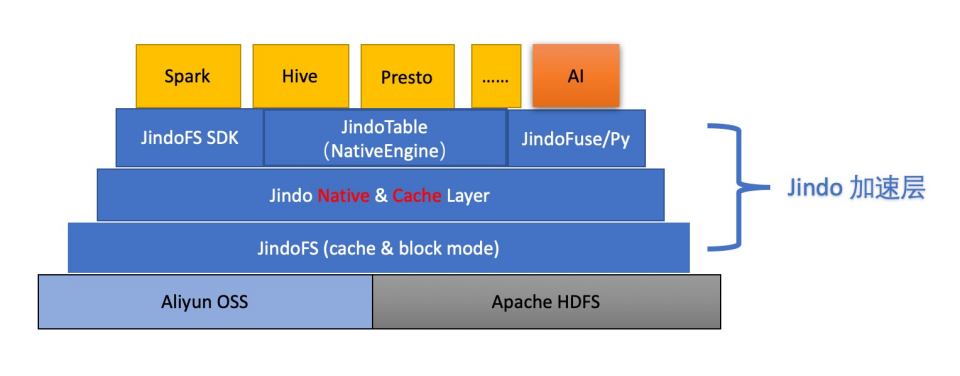
Cache 模式示意图:
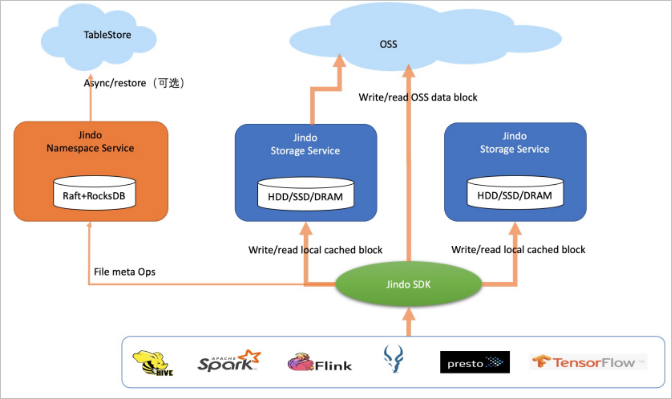
Block 模式示意图:
4.5 Fluid 如何选择Runtime
-
Alluxio 的理念是比较好的,但时至今日已经很庞大,在工程实现细节上缺少精细的打磨,例如,基于 JNR 的 FUSE 性能一言难尽、处理数据缓存的过程中过多的和 Master 进行交互。
-
JuiceFS 由于自己在对象存储上组织了一套数据结构,其存储的数据只能通过 JuiceFS 访问。数据安全性差,依赖底层对象存储的并发能力,延迟比较高,离本地计算节点距离较远,适合云原生、大数据等场景。
4.6 Fluid 数据集加速流程
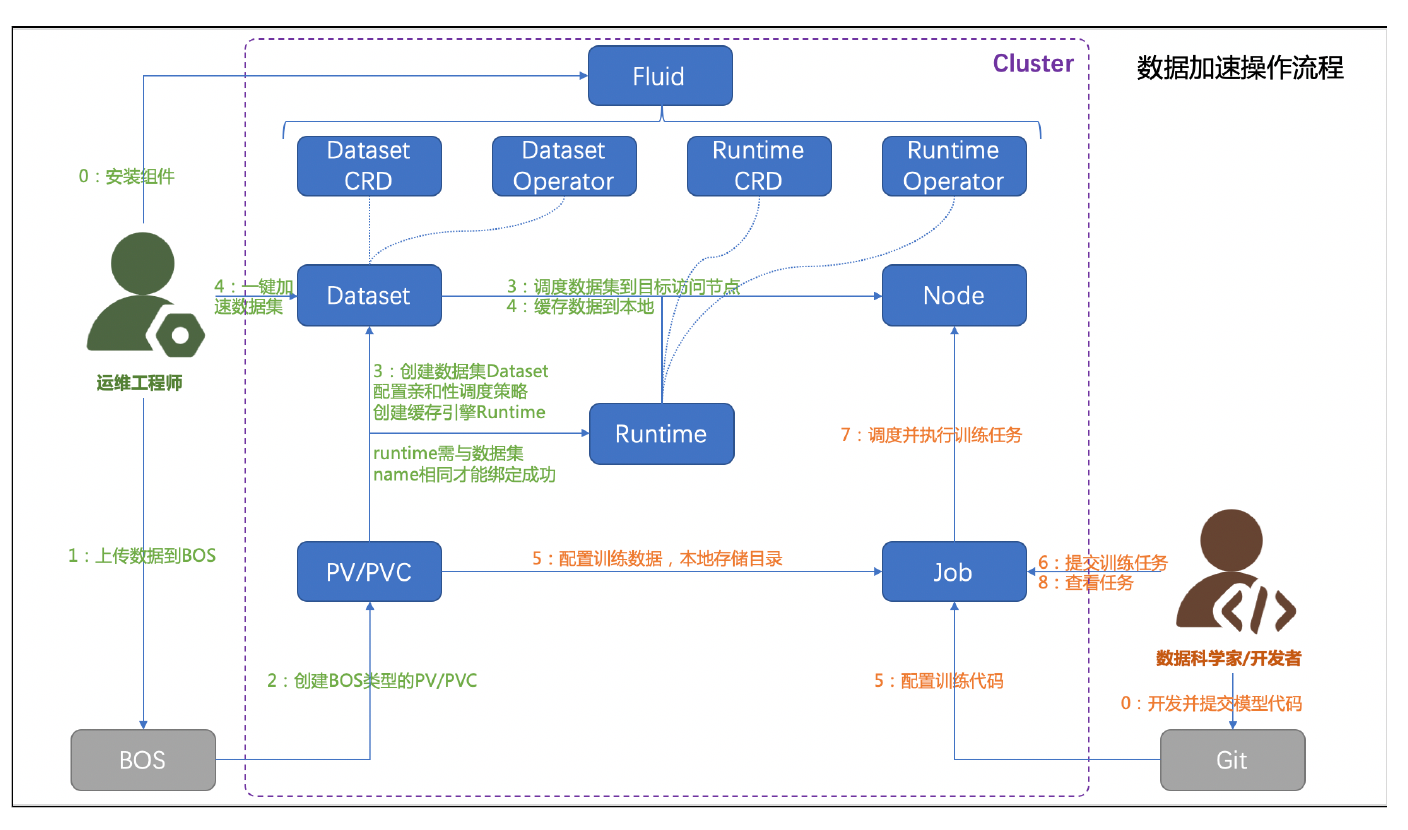
Fluid将整个训练的过程分成了两个阶段,一个阶段是用来做数据加载,另外一个阶段才是用来做真正的训练。这两个阶段拆分之后,在不同的任务之间 pipeline 并发起来。举个简单的例子,整个系统可能只有四张 GPU 卡,A 训练跟 B 训练都需要去用这四张卡来做训练,那在 A 训练跑 GPU 任务的时候,完全可以让 B 训练提前做数据预加载的工作,将数据提前预热到 PFS 或者 RapidFS 里。等到 A 训练任务完成的时候,就直接可以让调度器把 B 训练跑起来了。整体上看到的效果就是 B 的数据加载阶段被隐藏掉了,加载过程跟计算过程分阶段 pipeline 化了。对于那些训练任务很多的用户,GPU 等待时间变少了,利用率得到了很大的提高。PFS 和 RapidFS 统一都支持了 Fluid,在使用上体验接近,可灵活替换。在这个基础上,我们也会支持一些很细分的策略。那些对 I/O 延时不太敏感,但对元数据比较敏感的一些训练,可以只让它加载元数据。对元数据和数据访问要求都比较高的一些训练,在加载元数据的同时预热数据。所有的这些技术手段,目的都是让用户感受到比较好的使用体验。
4.7 Fluid 源码解析
Fluid Runtime 核心逻辑(统一接口实现)
- Runtime 需要实现 Fluid Engine 接口
pkg/ddc/base/engine.go:30
// Engine interface defines the interfaces that should be implemented// by a distributed data caching Engine.// Thread safety is required from implementations of this interface.type Engine interface { // ID returns the id ID() string // Shutdown and clean up the engine Shutdown() error // Setup the engine Setup(ctx cruntime.ReconcileRequestContext) (ready bool, err error) // Setup the Volume CreateVolume() (err error) // Destroy the Volume DeleteVolume() (err error) // Sync syncs the alluxio runtime Sync(ctx cruntime.ReconcileRequestContext) error // Validate checks all spec fields of the Dataset and the Runtime Validate(ctx cruntime.ReconcileRequestContext) (err error) // DataOperator is a common interface for Data Operations like DataBackup/DataLoad/DataMigrate etc. DataOperator}
- 实现 engine 是通过 pkg/ddc/base/template_engine.go 的NewTemplateEngine函数实现,主要是实现 Implement 接口
pkg/ddc/base/template_engine.go:41
type TemplateEngine struct {ImplementId stringclient.ClientLog logr.LoggerContext cruntime.ReconcileRequestContextsyncRetryDuration time.DurationtimeOfLastSync time.Time}// NewTemplateEngine creates template enginefunc NewTemplateEngine(impl Implement,id string,// client client.Client,// log logr.Logger,context cruntime.ReconcileRequestContext) *TemplateEngine {b := &TemplateEngine{Implement: impl,Id: id,Context: context,Client: context.Client,// Log: log,}b.Log = context.Log.WithValues("engine", context.RuntimeType).WithValues("id", id)// b.timeOfLastSync = time.Now()duration, err := getSyncRetryDuration()if err != nil {b.Log.Error(err, "Failed to parse syncRetryDurationEnv: FLUID_SYNC_RETRY_DURATION, use the default setting")}if duration != nil {b.syncRetryDuration = *duration} else {b.syncRetryDuration = defaultSyncRetryDuration}b.timeOfLastSync = time.Now().Add(-b.syncRetryDuration)b.Log.Info("Set the syncRetryDuration", "syncRetryDuration", b.syncRetryDuration)return b}
- 真实的引擎实现接口 Implement
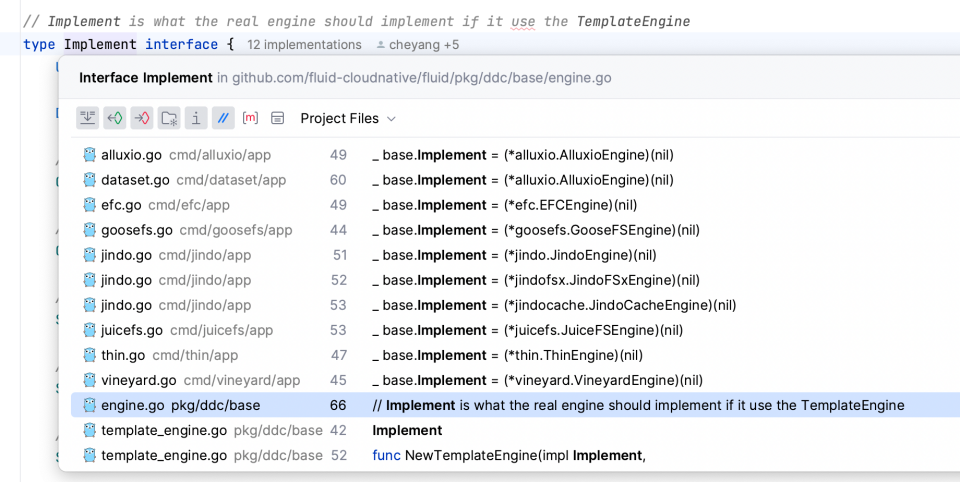
pkg/ddc/base/engine.go:67
// Implement is what the real engine should implement if it use the TemplateEnginetype Implement interface {UnderFileSystemServiceDataOperatorYamlGenerator// CheckMasterReady checks if the master readyCheckMasterReady() (ready bool, err error)// CheckWorkersReady checks if the workers readyCheckWorkersReady() (ready bool, err error)// ShouldSetupMaster checks if we need to setup the masterShouldSetupMaster() (should bool, err error)// ShouldSetupWorkers checks if we need to setup the workersShouldSetupWorkers() (should bool, err error)// ShouldCheckUFS checks if we should check the ufsShouldCheckUFS() (should bool, err error)// SetupMaster setup the cache masterSetupMaster() (err error)// SetupWorkers setup the cache workerSetupWorkers() (err error)// UpdateDatasetStatus update the status of Dataset according to the given phaseUpdateDatasetStatus(phase datav1alpha1.DatasetPhase) (err error)// PrepareUFS prepare the mounts and metadata if it's not readyPrepareUFS() (err error)// ShouldUpdateUFS check if we need to update the ufs and return all ufs to update// If the ufs have changed and the engine supports add/remove mount points dynamically,// then we need to UpdateOnUFSChangeShouldUpdateUFS() (ufsToUpdate *utils.UFSToUpdate)// UpdateOnUFSChange update the mount point of Dataset if ufs change// if an engine doesn't support UpdateOnUFSChange, it need to return falseUpdateOnUFSChange(ufsToUpdate *utils.UFSToUpdate) (ready bool, err error)// Shutdown and clean up the engineShutdown() error// CheckRuntimeHealthy checks runtime healthyCheckRuntimeHealthy() (err error)// UpdateCacheOfDataset updates cache of the datasetUpdateCacheOfDataset() (err error)// CheckAndUpdateRuntimeStatus checks and updates the statusCheckAndUpdateRuntimeStatus() (ready bool, err error)// CreateVolume create the pv and pvc for the DatasetCreateVolume() error// SyncReplicas syncs the replicasSyncReplicas(ctx cruntime.ReconcileRequestContext) error// SyncMetadata syncs all metadata from UFSSyncMetadata() (err error)// DeleteVolume Destroy the VolumeDeleteVolume() (err error)// BindToDataset binds the engine to datasetBindToDataset() (err error)// CheckRuntimeReady checks if the runtime is readyCheckRuntimeReady() (ready bool)// SyncRuntime syncs the runtime specSyncRuntime(ctx cruntime.ReconcileRequestContext) (changed bool, err error)// SyncScheduleInfoToCacheNodes Sync the scheduleInfo to cacheNodesSyncScheduleInfoToCacheNodes() (err error)// Validate checks all spec fields of the Dataset and the RuntimeValidate(ctx cruntime.ReconcileRequestContext) (err error)}
数据集编排核心原理(数据亲和性调度)
上层应用通过 pvc 来进行数据的读取,上层应用对 fluid 是无感知的,fluid 是怎么做的呢?
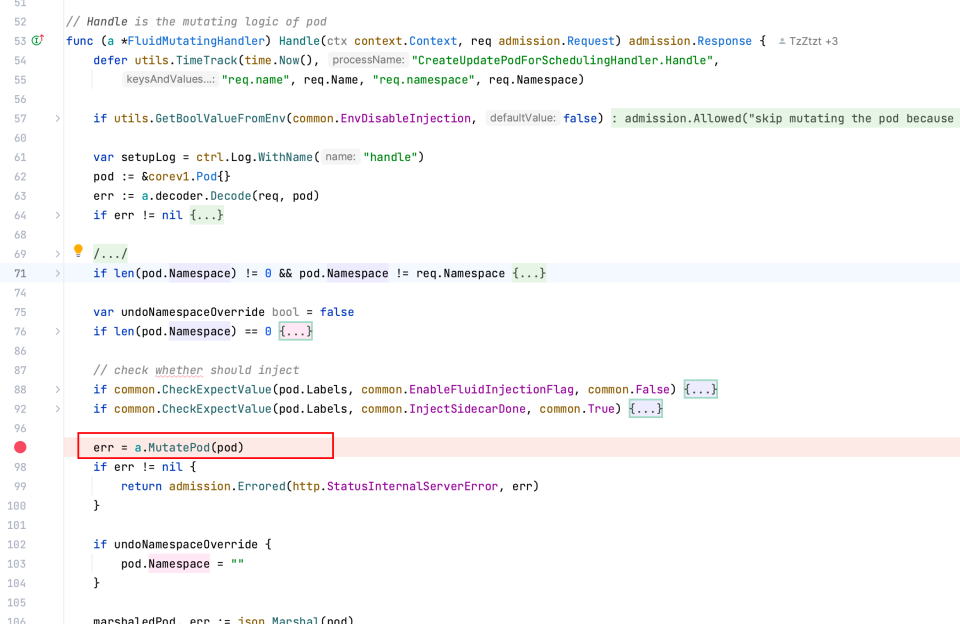
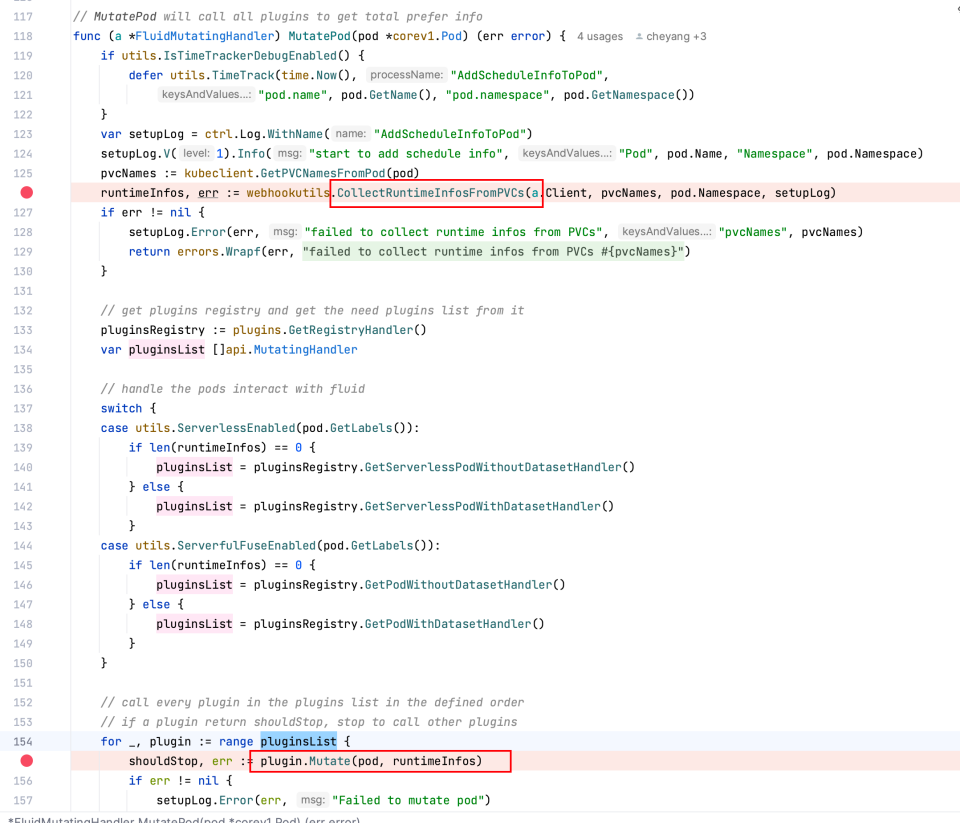
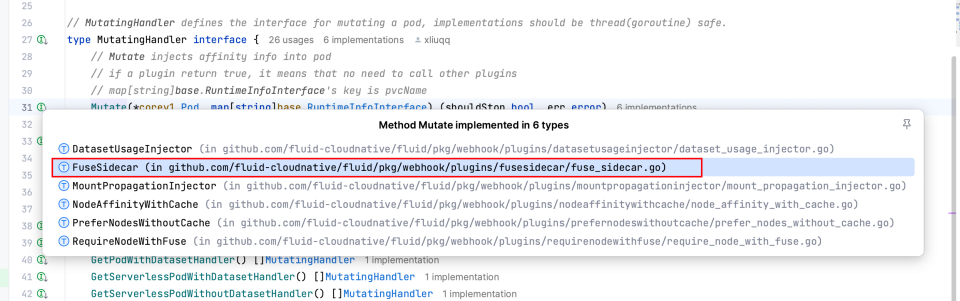
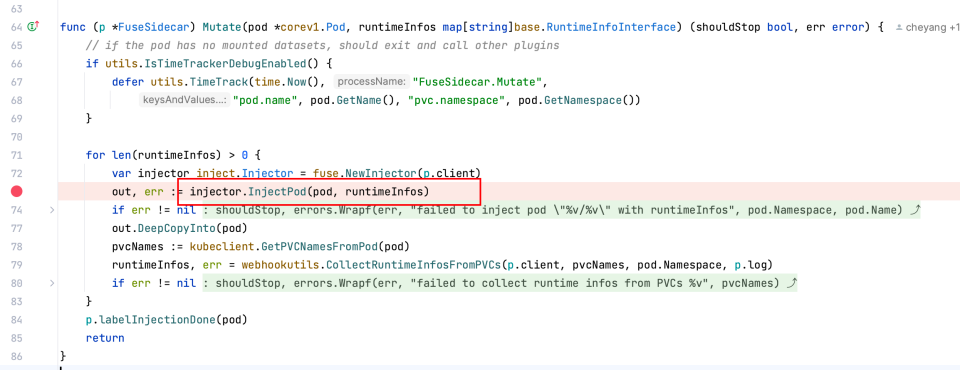
fluid 通过 webhook 劫持 pod 创建函数,并通过 pvc 进行 fliter,确认该 pod 是否是需要注入的,最后将 sidecar 注入该 pod 实现对pvc 的数据操作最后映射到 fuse sidecar 的 posix 接口操作上。
pkg/webhook/handler/mutating/mutating_handler.go:53
数据集加速核心原理(数据预热)
数据集创建时会将 dataload Reconciler 注册到 Fluid controller manager
cmd/dataset/app/dataset.go
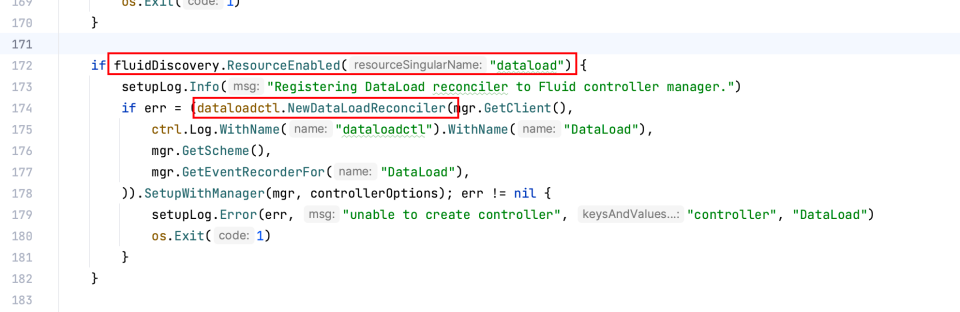
在 创建dataset、手动更新 dataload、或者资源状态变更时,都有可能触发 dataload
- dataload 的主要逻辑:
dataload 主要通过 pkg/controllers/v1alpha1/dataload/dataload_controller.go 进行管理
核心函数为[Reconcile]
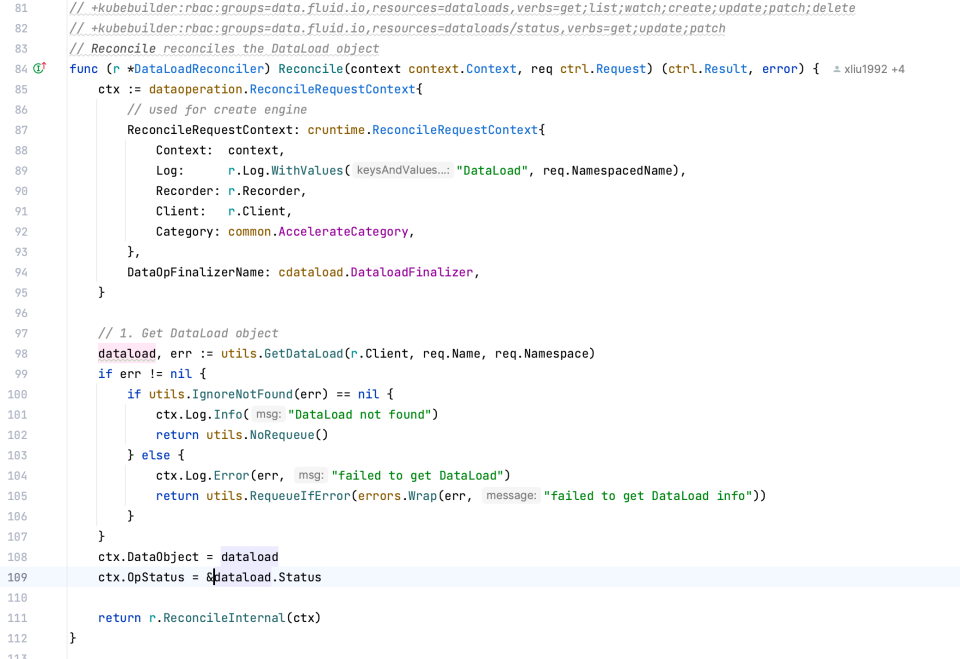
核心代码为调度 runtime engine 的 operate

操作分多种类型,其中只主要的load 操作是 reconcileExecuting
pkg/ddc/base/operation.go
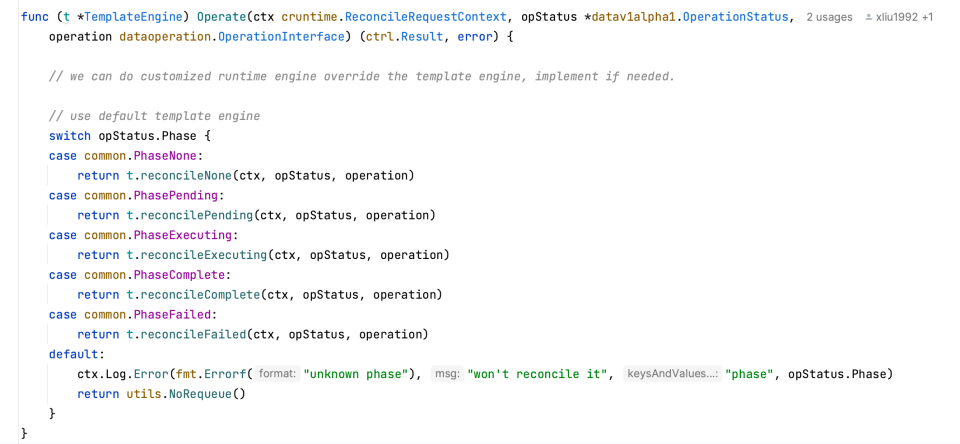
执行的原理为封装不同 engine 的 job helm,然后执行 helm 启动 job,进行数据的加载


不同的 runtime engine 均提供了不同的镜像:
image: jindo/jindofs:4.6.8image: juicedata/mount:1.0.0image: alluxio/alluxio:2.6.2
5. 互联网厂商的AI数据加速解决方案
5.1 阿里巴巴
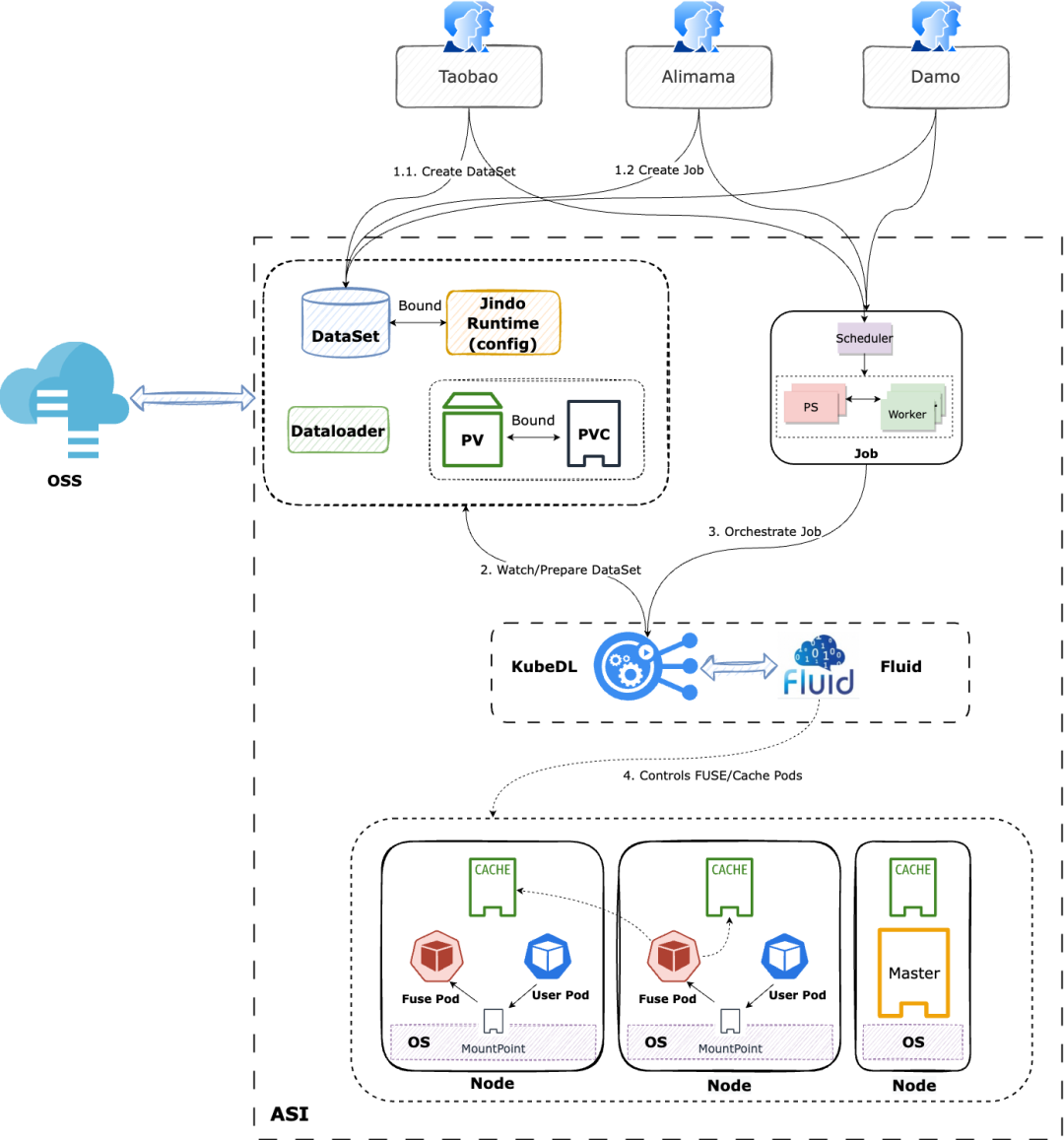
阿里巴巴使用基于 JindoCache 的 Fluid
- Fluid 可以将数据集编排在 Kubernetes 集群中,实现数据和计算的同置,并且提供基于 Persistent Volume Claim 接口,实现 Kubernetes 上应用的无缝对接。同时 JindoRuntime 提供对 OSS 上数据的访问和缓存加速能力,并且可以利用 FUSE 的 POSIX 文件系统接口实现可以像本地磁盘一样轻松使用 OSS 上的海量文件,pytorch 等深度学习训练工具可利用 POSIX 文件接口读取训练数据。
- 提供元数据和数据分布式缓存,可单独进行元数据缓存预热。
- 提供元数据缓存预热,避免训练文件在 OSS 上大量元数据操作、提供数据预热机制,避免在训练时刻拉取数据造成的数据访问竞争。
- 通过 KubeDL 调用 Fluid 数据亲和性调度能力,用户无需感知缓存存放的节点位置,以及弹性场景中不断随时可能迁移的节点环境,将有数据依赖的任务和已缓存的节点进行感知调度,实现尽可能的短路 short-circuit 读,最大化性能优势;
- JindoCache 提供多种分布式缓存能力,可以根据业务需要选择合适的缓存策略。在当前场景中我们选择 Cache-Aside (Lazy Loading) 的读缓存策略:当应用程序需要读取数据时,它首先检查缓存以确定数据是否可用。如果数据可用(缓存命中),则返回缓存的数据。如果数据不可用(缓存未命中),则会在底层存储查询数据,然后用从底层读取的数据填充缓存,并将数据返回给调用者。写缓存策略选择 Write-Through 即写时落缓存策略,应用程序向底层文件系统写入的文件,同时也会被写入缓存系统中,好处是下一次读取这部分数据的时候就可以直接从缓存系统中读取,大大提升了读取效率。
- Fluid 支持 FUSE 挂载点自愈能力,可以自动检查并恢复因 OOM 等异常原因导致的 FUSE 挂载点断裂问题,避免数据访问异常,保障 AI 平台在线业务稳定运行。
5.2 华为
https://www.huawei.com/cn/huaweitech/publication/202401/ai-data-lake-breaking-data-silos
华为AI数据湖解决方案的架构示意图中,总共分为三层:数据存储层、数据编织层、数据服务层
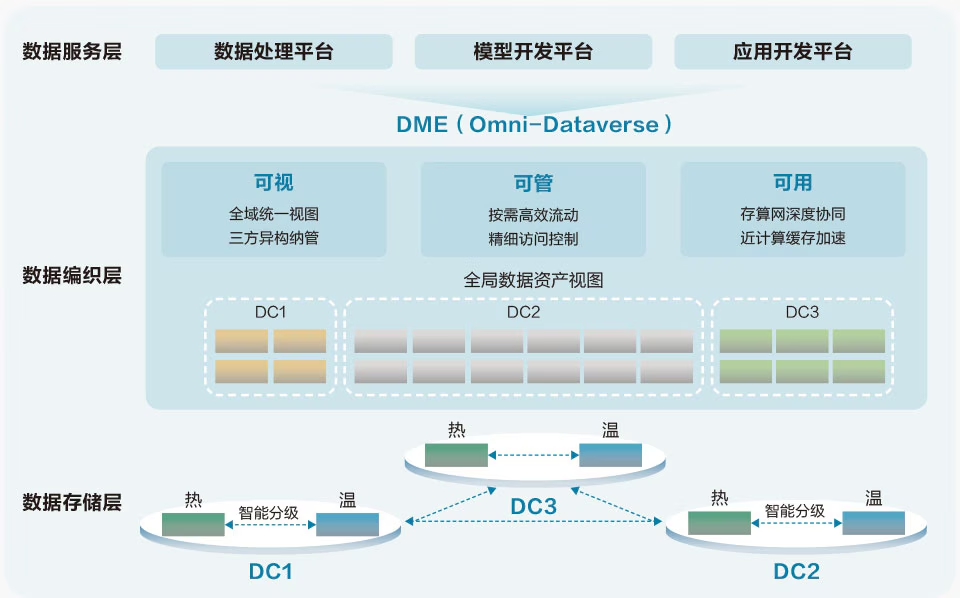
数据存储层
在这一层,数据分散存储于多个不同数据中心。
数据中心内部,数据在热、温两层被智能分级。热层实际为华为专为AI大模型训练业务场景打造的OceanStor A系列高性能存储,可横向扩展至上千节点;而温层则是华为的OceanStor Pacific系列分布式存储,用于海量非结构化数据。OceanStor A 系列和 OceanStor Pacific 系列之间,可以实现智能分级,即同一个存储集群内部,多个A系列节点形成高性能存储层,而Pacific系列节点形成大容量存储层,两层合二为一,对外展示出一个完整的文件系统或对象桶,支持多协议互通(一份数据可以被多种不同协议访问),对内则智能地、自动地执行数据分级,很好地同时满足了容量、性能、成本的和谐与自洽。
数据中心之间,可以在不同的存储集群之间创建数据复制关系,从而支持数据在跨数据中心之间高可靠地按需流动,为AI大模型训练的数据归集在数据设备层做好了支撑。
数据编织层
“数据编织”的意思,是为数据铺就一个“阡陌交通”的流动网络,让数据可视可管可用,进而在AI大模型训练过程中可以实现价值最大化。
华为通过一个软件层 Omni-Dataverse,实现了数据的可视可管可用。Omni-Dataverse 是华为数据管理引擎 DME(Data Management Engine)的一个重要组件,通过对不同数据中心的华为存储上的元数据进行统一纳管,形成了一个数据资产全局视图,并通过调用存储设备上的接口来控制数据的流动(Omni-Dataverse 基于用户定义的策略来执行相关动作)。此外,Omni-Dataverse还可以按需控制 GPU/NPU直通存储、文件智能预取等,让算力零等待训练数据。
借助这种方式,AI大模型训练的数据归集和模型训练阶段的效率得以提升,进而支撑了集群可用度的提升。
数据服务层
华为AI数据湖解决方案在数据服务层提供了常用的服务框架,包括数据处理、模型开发、应用开发。
5.3 字节
CloudFS
火山引擎云原生存储加速实战
字节内部 HDFS 演进而来的 File System 服务,命名为 CloudFS。CloudFS 的整体技术架构与内部 HDFS 架构本质上是同一套组件在云上做的一些产品化、小型化和多租户的封装。
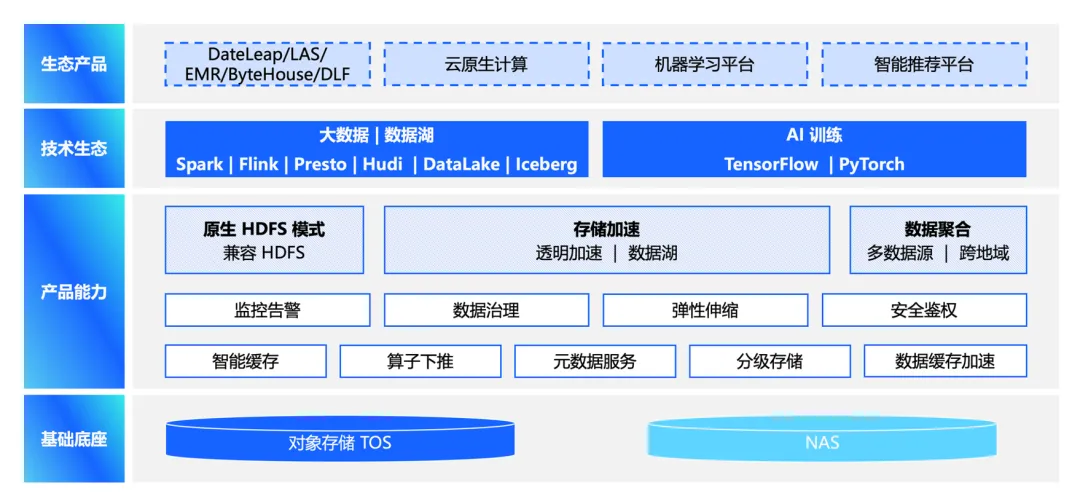
CloudFS 最多可以存储多少 iNode 元数据?规模上限是 50 亿。
6. Concepts
6.1 PFS 与 CFS 区别
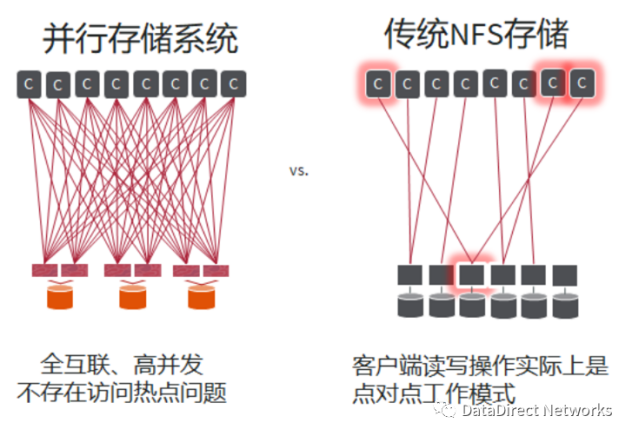
- 架构不同:并行文件存储是全互联、高并发的架构,不存在访问热点。NFS传统文件存储客户端读写操作实际上是点对点的工作模式,容易形成访问热点。
-
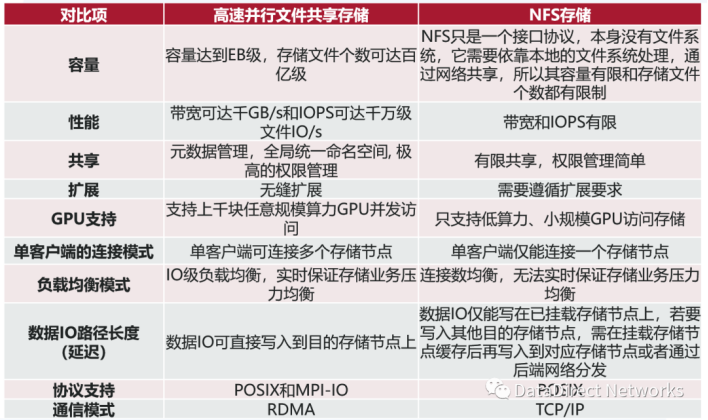
容量差异:容量有两层含义,数据量和文件个数。对于并行文件系统来说,它存储的数据量可以从PB级,到数百PB级,甚至可达到EB级。但NFS只是一个接口协议,本身没有文件系统,它需要依靠本地的文件系统处理,通过网络共享,所以其容量有限。现在的 AI 应用通常涉及数百万、数千万、甚至过亿的文件个数,并行文件存储可以存储数百亿的文件个数,但是NFS存储能够存储的文件个数却有限制。
-
性能差异:性能也包括两方面,带宽和IOPS (Input/Output Per Second,指单位时间内系统能处理的IO请求数量)。传统的HPC应用一般会有高性能、高带宽的要求。AI 应用有大量随机 IO, 对 IOPS 有较高要求。PFS并行文件系统带宽可达数千GB/s,IOPS 可达数千万文件 IO/s。但CFS文件存储的带宽和 IOPS 的性能都有限。
-
GPU支持程度:随着GPU在现代数据中心的广泛使用,存储系统能否很好地支持 GPU 也是一个重要的考虑因素。并行文件系统可以支撑任意规模的 GPU 并发访问,例如,DDN的并行文件系统支持了英伟达Selene 超级计算机上4000多块 GPU 的并发访问。而 NFS 存储只能支持小规模的 GPU 访问。
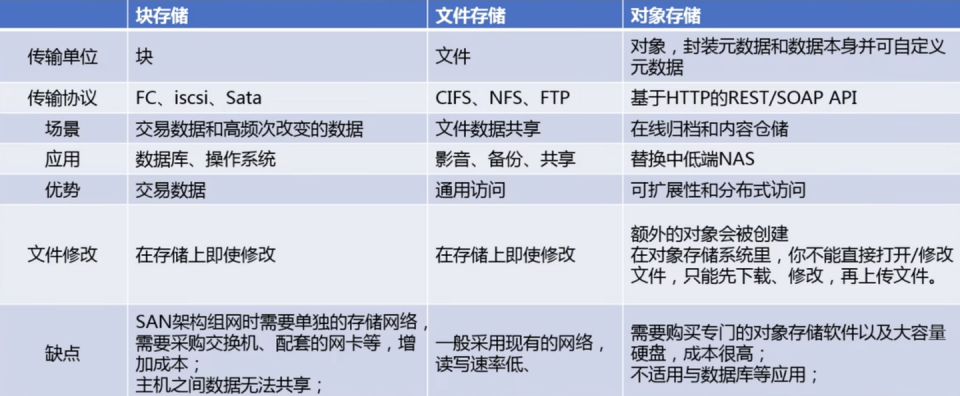
6.2 块存储、文件存储、对象存储的区别
-
文件存储
-
文件存储是一种数据存储方式,它涉及将数据以文件的形式保存在计算机系统或其他存储设备中。
-
文件存储采用分层存储的概念,数据被保存于文件和文件夹中,这种存储方式具有丰富的功能,几乎可以存储任何内容,它非常适合用来存储一系列复杂文件,并且有助于用户快速导航。
-
在文件存储系统中,数据以单条信息的形式存储在文件夹中,这些数据会根据数量有限的元数据来进行整理和检索,元数据相当于数据文件的目录,告诉计算机文件所在的确切位置。文件存储适用于直接和网络附加存储系统,是一种古老且运用广泛的数据存储系统,只要访问保存在个人计算机上的文件中的文档,就是在使用文件存储。
-
-
块存储:
-
块存储指的是块设备,一切以磁盘形式的存储都是块存储。
-
块存储强调的是裸磁盘,以磁盘形式直接提供给主机或服务器访问的都是块存储。
-
块存储会将数据拆分成块,并单独存储各个块。每个数据块都有一个唯一标识符,所以存储系统能将较小的数据存放在最方便的位置。这意味着有些数据可以存储在 Linux 环境中,有些则可以存储在 Windows 单元中。
-
-
对象存储:
-
对象存储呈现出来的是一个桶(Bucket),你可以往桶里放对象(Object),这个对象包括三个部分:
-
Key:文件名,该对象全局唯一标识符,用于检索对象,通过它找到对象,极大的简化了数据存储
-
Data:数据本体
-
MetaData:元数据,类似于数据标签,标签的条目类型和数量没有限制,可以是对象的各种描述信息。通过元数据可以更快地实现对象的分类,排序和查找
-
-
扁平化的存储结构
-
内置大容量硬盘的分布式服务器是对象存储的典型设备,对象存储最常用的方案,就是多台服务器内置大容量硬盘,再装上对象存储软件,然后再额外配置几台服务作为管理节点,安装上对象存储管理软件。管理节点可以管理其他服务器对外提供读写访问功能。
-
-
区别
-
存储设备不同:
-
对象存储:对象存储的对应存储设备为swift,键值存储。
-
文件存储:文件存储的对应存储设备为FTP、NFS服务器。
-
块存储:块存储的对应存储设备为cinder,硬盘。
-
-
特点不同:
-
对象存储:对象存储的特点是具备块存储的高速以及文件存储的共享等特性。
-
文件存储:文件存储的特点是一个大文件夹,大家都可以获取文件。
-
块存储:块存储的特点是分区、格式化后,可以使用,与平常主机内置硬盘的方式完全无异。
-
-
缺点:
-
块存储:①主机之间的数据无法共享;②不利于不同操作系统主机间的数据共享;③采用SAN架构组网时,需要额外为主机购买光纤通道卡,还要买光纤交换机,造价成本高;④扩展性差;
-
文件存储:①读写速率低,传输速率慢;②贷款低、延迟大,不利于在高性能集群中应用
-
对象存储:成本相较于文件存储略高;
-
-
优点:
-
块存储读:①操作简单。②磁盘提升了读写效率;③传输速度与读写速率得到提升;④磁盘存储容量较大;
-
文件存储:①不需要专用的SAN网络,造价成本低;②方便文件共享;
-
对象存储: ①对象存储同时兼具SAN高级直接访问磁盘特点及NAS的分布式共享特点;②对象存储软件是有专门的文件系统,解决了文件共享的难题;③分布式存储架构,文件读写速度更快;④多台OSD服务器同时对外传输数据,传输速度更快;
-
-