前两天有这么个小需求:
在cmd中运行某测试工具后/请求某个api后,会返回一个json结果,其中有一个参数的值每次都变且经常要用,正常情况复制粘贴就好了,但这个值非常长,配上cmd的标记+粘贴的行为,就很酸爽了。然后就想快速提取这个值,顺着cmd的这个思路,就走上了批处理的道路。
借这个机会,简单跟大家交流交流怎么通过批处理命令获取数据的内容。
案例中的几个元素:
cmd中用的测试工具:test_tool.exe
返回的json数据(示例):
{"random_id":"wojiushigechaochangdesuijizifuchuan…wojiushigechaochangdesuijizifuchuan…wojiushigechaochangdesuijizifuchuan…wojiushigechaochangdesuijizifuchuan…qishiwobizhegehaichang","begin_time":"2018-12-29","end_time":" 2018-12-30"}。random_id的值,就是我们要获取的内容。
咱们先来看看这简单的几行脚本:(真的很简单)
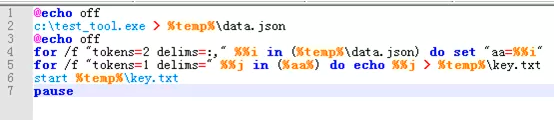
简单解释一下:
第2行:运行测试工具test_tool.exe,然后将数据保存到(清空已有内容的方式)系统临时目录(%temp%)的data.json中
第4行:将data.json中的数据按照“:”和“,”分列,取第二列的数据。结果如何呢?如下图:

第5行:去掉了上面结果中的双引号,然后将数据保存到(清空已有内容的方式)系统临时目录(%temp%)的key.txt中
第6行:打开key.txt,你就可以看到纯净版的key。好,到此为止,成功的跳过了cmd苦逼的标记+粘贴。
第7行:嗯…其实要它没用。
简单介绍一下这里面核心的“for /f”的这个批处理命令。“for /f”常用来解析文件,读取字符串。
通过其中的tokens和delims两个选项,能够获取一段字符串中的特定内容,delims负责切分字符串,tokens负责提取内容。
举例说明:
把下面的内容存个txt文件,如:“四大名著.txt”(注意保存为utf-8编码格式)
1.《三国演义》-罗贯中-明
2.《红楼梦》-曹雪芹-清
3.《水浒传》-施耐庵-明
4.《西游记》-吴承恩-明
输入不带tokens和delims的命令语句:

咱们来看看delims的作用
delims:用来告诉for每一行应该拿什么作为分隔符,默认的分隔符是空格和tab键,同时支持定义多个分隔符。
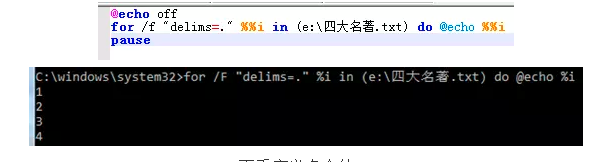
1. 先来看单个的:
新增”delims=.”,结果是按照“.”分隔,然后取前面的内容。
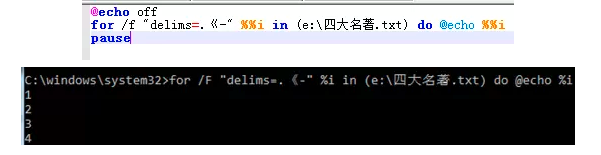
2.再看定义多个的:
改为"delims=.《-",结果按照“.”,“《”,“-”分成多列,然后取第一列的内容。
注:具体效果得结合tokens的应用来看
咱们再来看看token的作用
tokens:配合delims使用,用来告诉for应该获取哪列的数据,同时支持获取多列的数据。
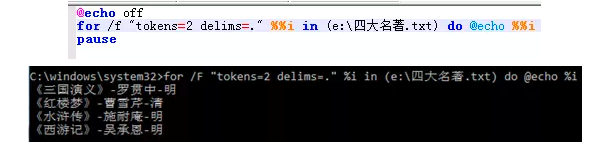
1.先来看单个的:
改为"tokens=2 delims=.",结果是按照“.”分隔,然后取第二列(也就是后面)的内容。
(由于按照“.”分隔只有两列,那么tokens大于2获取的数据就没有内容了)
2.再来看个复杂点的:
改为"tokens=2 delims=.《》-",结果按照“.”,“《”,“》”,“-”分成多列,然后取第二列的内容。
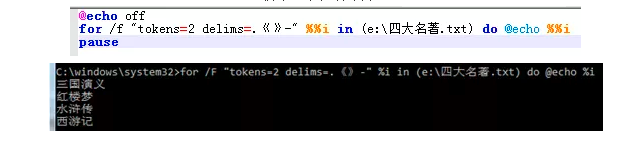
3.获取多列的数据:
按照“.”,“《”,“》”,“-”分列后,一共有4列,全部分别获取每一列的数据。

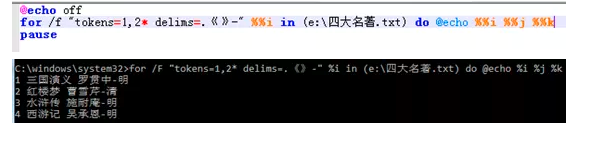
另外,tokens也可以支持一些其他用法,比如通配符:
按照“.”,“《”,“》”,“-”分列后,一共有4列,获取第1列、第2列的数据,然后“*”表示获取从第3列开始之后所有的内容(包含分隔符)
转自https://mp.weixin.qq.com/s/PZiAgFHlq0kq-tl1e7KmeA
参考:https://www.cnblogs.com/songzhenhua/p/10241401.html