简介
Booking.com 利用复杂的排名系统优化每位用户的搜索结果。该系统采用先进的机器学习算法,并充分利用海量数据,包括用户行为、偏好和历史交互记录,为用户量身定制酒店列表和旅行推荐。
本文将带您深入了解支撑多个垂直领域(如住宿、航班等)个性化排名的排名平台架构。
排名平台在更广泛生态系统中的位置
以下图表展示了排名平台在更广泛生态系统中的位置概览。为简化说明,图中将多个系统合并为单个模块或省略,只突出了排名平台的作用。
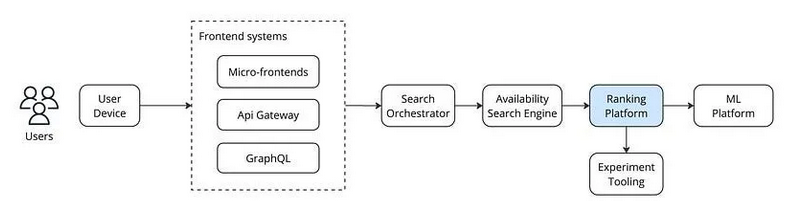
生态系统概览
一个典型的搜索流程如下:用户通过设备或浏览器发起调用,该调用会经过前端系统(包括微前端和网关),然后到达搜索协调器。核心搜索引擎负责协调搜索流程,并生成用于搜索结果页面和地图的物业列表。这一任务需要与可用性搜索引擎交互,该引擎负责追踪 Booking.com 上 数千万 物业的可用性数据。由于数据量庞大,可用性搜索引擎采用分片机制以高效处理复杂查询。协调器负责在可用性系统中分配工作负载并汇总结果。
排名平台位于可用性搜索引擎之后,利用机器学习模型对符合搜索条件的物业进行评分。
排名平台概览
在深入探讨排名平台的机器学习模型推断之前,我们先简要了解模型创建和部署相关的一些关键组件和工作流程。
模型创建与部署:总体视图
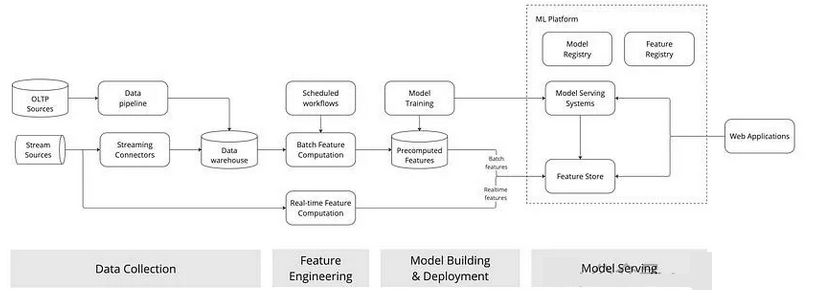
【图】机器学习生态系统概览
数据从不同来源(如 OLTP 表、Kafka 流)收集并存储在数据仓库中。机器学习科学家基于这些数据进行探索、预处理、特征工程,并选择合适的算法进行模型训练。在完成模型训练和超参数优化后,科学家会对模型进行离线测试,测试通过后部署以提供实际服务。
模型的特征主要分为以下几类:
1、静态特征
2、动态特征 - 缓慢变化的特征 - 实时特征
静态特征基于历史数据计算一次,在模型训练或推断过程中保持不变。为了保证数据的时效性,这些特征需定期重新计算(如每日、每周或每月)。典型示例包括住宿位置、设施和房型等。
动态特征则随着新数据的出现快速更新。例如当前房价和房间的实时可用性。
图中展示的特征工程部分清晰区分了这两类特征。批量特征是预先计算并存储在特征库中,其更新通过计划的工作流完成;实时特征则基于数据流实时计算并发送至特征库。
任何需要使用机器学习功能的应用程序都通过机器学习平台调用已部署的模型。
排名生态系统的扩展视图
在住宿领域,为大量用户对数百万物业进行排名是一个极具挑战的技术任务,需要复杂的算法和强大的计算能力。系统必须高效处理众多变量(如用户偏好、历史行为、物业属性以及实时数据如价格与可用性),并在毫秒级时间内提供个性化推荐,确保推荐结果的相关性和准确性。这种复杂性强调了强大的服务基础设施的重要性,如下图所示。这是之前生态系统图的扩展版本。
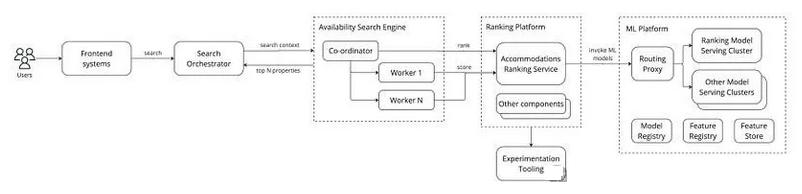
【图】ML 生态系统的扩展版本
如图所示,可用性搜索引擎与排名平台的交互分为两次:
从工作器分片处调用,为所有检索到的物业评分。
在协调器合并各分片的结果后,再次调用以调整最终排序。
排名平台为每个垂直领域或用例(如住宿排名、航班排名、住宿推荐等)提供专门服务。为了简化说明,图中仅保留了住宿排名服务,隐藏了其他服务。此外,排名平台广泛采用持续实验(如交叉排序和 A/B 测试)优化搜索结果。
模型推断由机器学习平台处理,该平台负责跟踪模型、特征及其表现。由于排名的规模庞大,机器学习平台中有一个专用集群服务所有排名相关的机器学习模型,从而确保资源隔离和性能稳定。
住宿排名服务设置
以下部分将探讨排名服务的设置以及其关键组件。
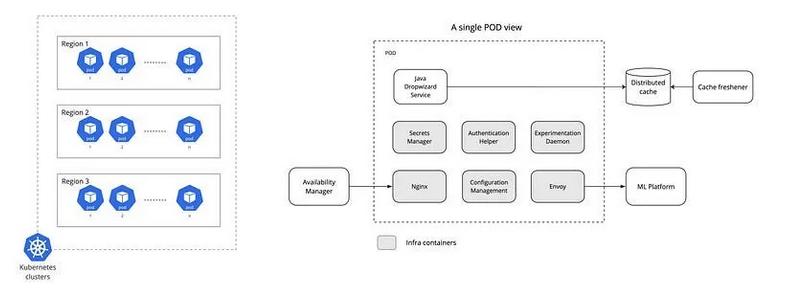
如上图所示,住宿排名服务部署在三个独立的 Kubernetes 集群中。每个集群包含数百个 Pod,用于处理搜索流量。右侧的图表展示了单个 Pod 内的关键组件。除了主要的 Java 服务之外,还有多个基础设施容器共同运行。Java 服务通过 Nginx 接收请求,从分布式缓存中检索特征后调用机器学习平台。分布式缓存在满足严格延迟要求方面至关重要(后文将详细讨论)。
深入分析 Java 服务后,可发现以下组件:
Dropwizard Resources:API 接口端点。
Feature Collector:从搜索上下文中收集特征,并从分布式缓存中检索静态特征。
Experiment Tracker:追踪正在运行的实验及其变体模型,确保不同变体生成的结果正确交错。
Model Executor:将请求分块处理,调用机器学习平台并汇总并行调用的评分结果。
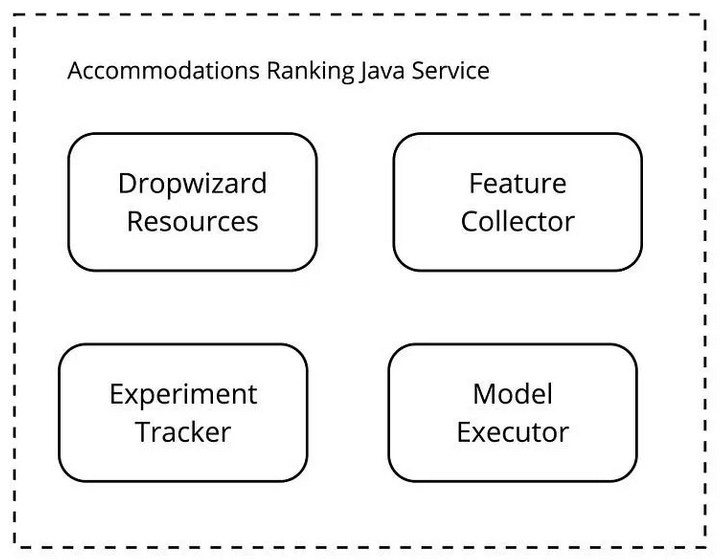
【图】排名服务内的组件
技术挑战
在大规模运营排名系统时,会面临以下技术挑战:
位于关键路径中
排名系统位于关键路径,因此需在 99.9% 的情况下(p999)在不到一秒内返回结果。这要求对复杂模型的操作进行深入优化,以满足严格的性能要求。
扇出问题
排名系统位于可用性搜索引擎的工作器或分片之后,因此 API 调用数量随着工作器数量的增加而成倍增长。
例如,如果搜索协调器每秒接收 K 个请求,而可用性搜索引擎有 N 个工作器,则排名服务每秒需处理 N * K 个请求。
极其多变的负载大小
根据某一地区内物业的密度和搜索范围的大小,待排名的物业数量可能从几十到数千不等。为应对这一挑战,排名服务会将负载拆分为可管理的小块,再向机器学习平台请求推断。这种方法虽能保证推断延迟的稳定性,但也引入了以下复杂性:
需要有效管理并行调用以防止内存泄漏。
加剧垃圾回收机制问题。
增加机器学习平台的负载。
如何解决这些挑战
静态评分回退
当服务因某些原因无法在规定时间内生成评分结果时,系统会回退到物业的静态评分。这些评分是预先计算的,存储于可用性搜索引擎中,并定期更新。尽管这些评分缺乏个性化,但在系统故障时,仍能为用户提供相关性较高的排名结果。
多阶段排名
多阶段排名通过将排名过程分解为多个阶段,每个阶段基于不同的标准或参数,从而实现更精确和细化的最终排名。这种方法使系统能够在不同阶段运行复杂程度、个性化水平及性能要求各异的模型。
性能优化
我们建立了全面的监控体系以评估各组件性能并持续优化。此外,通过在生产环境中维护镜像设置,处理影子流量,可以运行仅限生产环境的基准测试。
模型推断优化
机器学习平台持续优化模型推断以加速运行过程。具体优化技术包括:
模型量化:减少模型复杂性,提高推断速度。
模型剪枝:删除冗余模型权重以降低计算开销。
硬件加速:利用专用硬件(如 GPU 或 TPU)提升性能。
推断框架:采用专门设计的推断框架以优化资源使用。
这些技术在保持模型准确性的同时,显著降低了推断的延迟、内存使用和计算资源消耗。
结论
排名平台在 Booking.com 搜索架构的生态系统中占据核心地位。它通过复杂的机器学习模型和排名算法,为用户提供高度个性化的搜索结果。随着技术的不断演进和用户需求的增长,排名平台将继续推动创新,确保为全球用户带来相关性更高、更个性化的搜索体验。
原创 JavaEdge