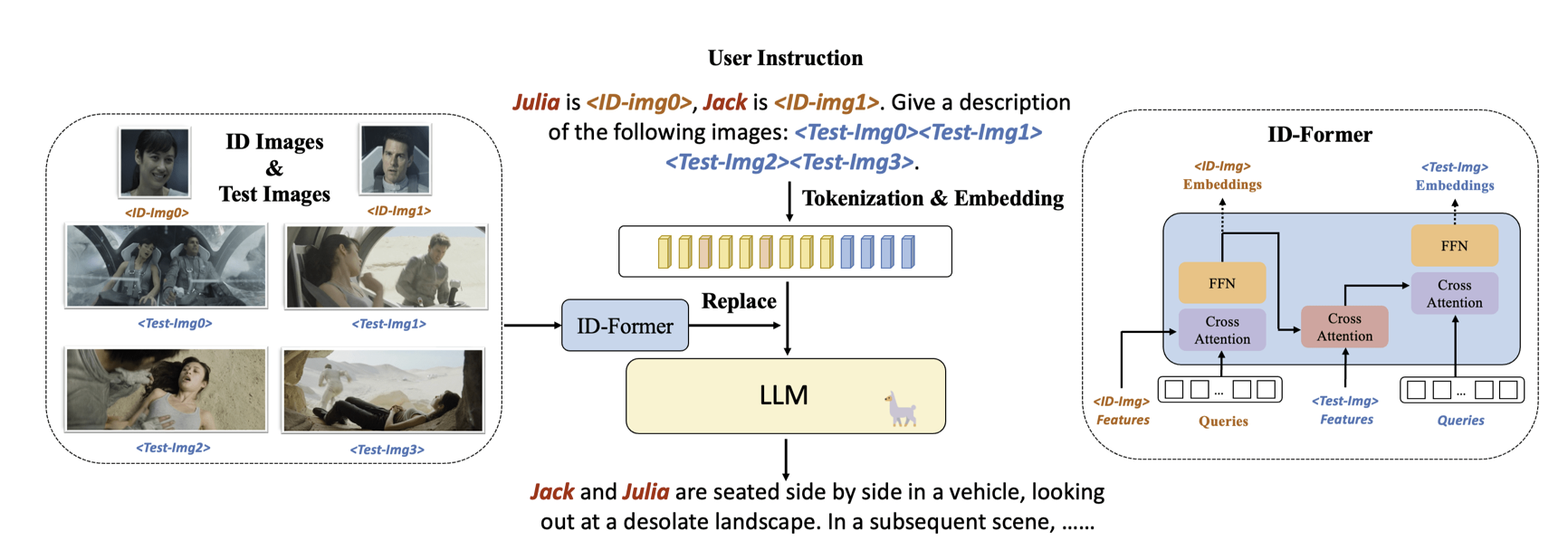
IDA-VLM: Towards Movie Understanding via ID-Aware Large Vision-Language Model
故事:现在的LVLM只能处理单场景,跨场景中关联实体的能力不行。比如电影中同一个角色在不同场景中出现,现有的LVLM不能把相同角色合并。所以本文提出了一个benchmark衡量跨场景角色对齐能力,并且提了一个简单的base model。
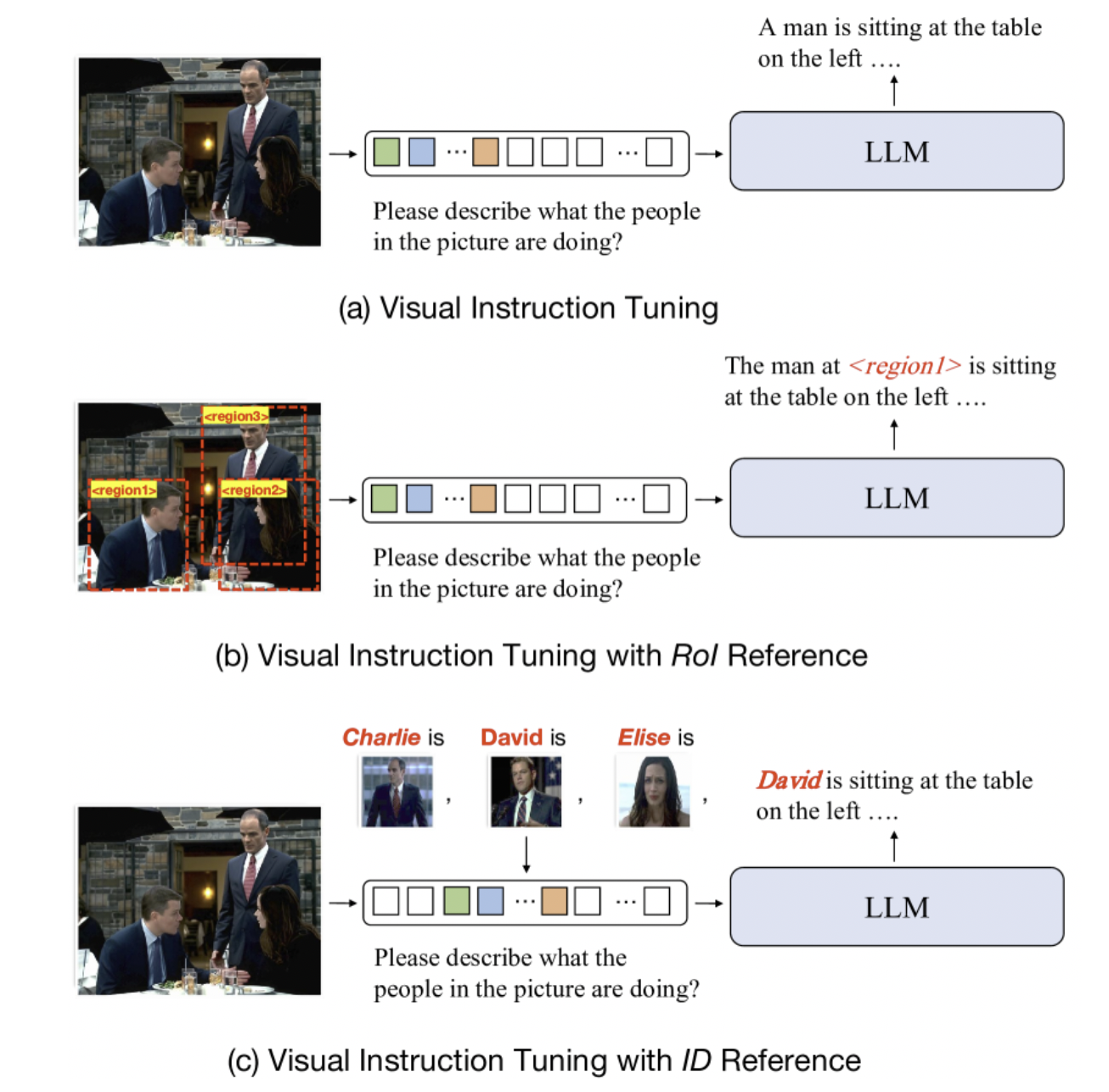
Intro里简单介绍了现有视觉指令调优的方法。普通的只能说出来"A man",加了layout 框的可以说出来"The man at region X",他们的可以把名字对上。
模型结构也比较简单: