【人人都能学得会的NLP - 文本分类篇 05】使用LSTM完成情感分析任务
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
自然语言情感分析
人类自然语言具有高度的复杂性,相同的对话在不同的情景,不同的情感,不同的人演绎,表达的效果往往也会迥然不同。例如"你真的太瘦了",当你聊天的对象是一位身材苗条的人,这是一句赞美的话;当你聊天的对象是一位肥胖的人时,这就变成了一句嘲讽。
人类自然语言不只具有复杂性,同时也蕴含着丰富的情感色彩:表达人的情绪(如悲伤、快乐)、表达人的心情(如倦怠、忧郁)、表达人的喜好(如喜欢、讨厌)、表达人的个性特征和表达人的立场等等。利用机器自动分析这些情感倾向,不但有助于帮助企业了解消费者对其产品的感受,为产品改进提供依据;同时还有助于企业分析商业伙伴们的态度,以便更好地进行商业决策。
简单的说,我们可以将情感分析(sentiment classification)任务定义为一个分类问题,即指定一个文本输入,机器通过对文本进行分析、处理、归纳和推理后自动输出结论,如图1所示。

通常情况下,人们把情感分析任务看成一个三分类问题,如 图2 所示:

- 正向: 表示正面积极的情感,如高兴,幸福,惊喜,期待等。
- 负向: 表示负面消极的情感,如难过,伤心,愤怒,惊恐等。
- 其他: 其他类型的情感。
在情感分析任务中,研究人员除了分析句子的情感类型外,还细化到以句子中具体的“方面”为分析主体进行情感分析(aspect-level),如下:
这个薯片口味有点咸,太辣了,不过口感很脆。
关于薯片的口味方面是一个负向评价(咸,太辣),然而对于口感方面却是一个正向评价(很脆)。
我很喜欢夏威夷,就是这边的海鲜太贵了。
关于夏威夷是一个正向评价(喜欢),然而对于夏威夷的海鲜却是一个负向评价(价格太贵)。
使用LSTM完成情感分析任务

我们借助长短时记忆网络(LSTM)提取句子特征,可以非常轻松地完成情感分析任务。
对于每个句子,我们首先通过截断和填充的方式,把这些句子变成固定长度的向量。然后,利用长短时记忆网络,从左到右开始阅读每个句子。在完成阅读之后,我们使用长短时记忆网络的最后一个输出记忆,作为整个句子的语义信息,并直接把这个向量作为输入,送入一个分类层进行分类,从而完成对情感分析问题的神经网络建模。

接下来让我们看看如何实现一个基于长短时记忆网络的情感分析模型。不同深度学习模型的训练过程基本一致,流程如下:
- 数据处理:选择需要使用的数据,并做好必要的预处理工作。
- 网络定义:定义好网络结构,包括输入层,中间层,输出层,损失函数和优化算法。
- 网络训练:将准备好的训练集数据送入神经网络进行学习,并观察学习的过程是否正常,如损失函数值是否在降低,也可以打印一些中间步骤的结果出来等。
- 网络评估:使用测试集数据测试训练好的神经网络,看看训练效果如何。
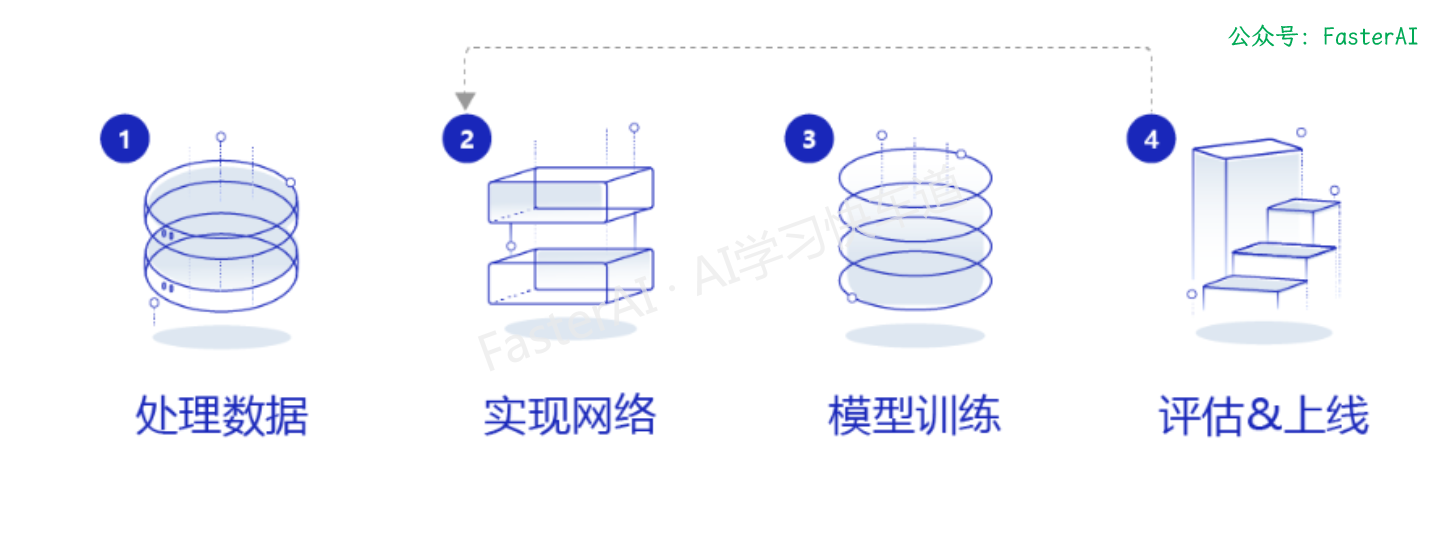
基于LSTM情感分析模型的核心代码
添加 paddlepaddle 依赖:
# encoding=utf8
import re
import random
import tarfile
import requests
import numpy as np
import paddle
from paddle.nn import Embedding
import paddle.nn.functional as F
from paddle.nn import LSTM, Embedding, Dropout, Linear
数据处理
首先,需要下载语料用于模型训练和评估效果。我们使用的是IMDB的电影评论数据,这个数据集是一个开源的英文数据集,由训练数据和测试数据组成。每个数据都分别由若干小文件组成,每个小文件内部都是一段用户关于某个电影的真实评价,以及观众对这个电影的情感倾向(是正向还是负向),数据集下载的代码如下:
def download():# 通过python的requests类,下载存储在# https://dataset.bj.bcebos.com/imdb%2FaclImdb_v1.tar.gz的文件corpus_url = "https://dataset.bj.bcebos.com/imdb%2FaclImdb_v1.tar.gz"web_request = requests.get(corpus_url)corpus = web_request.content# 将下载的文件写在当前目录的aclImdb_v1.tar.gz文件内with open("./aclImdb_v1.tar.gz", "wb") as f:f.write(corpus)f.close()download()
接下来,将数据集加载到程序中,并打印一小部分数据观察一下数据集的特点,代码如下:
def load_imdb(is_training):data_set = []# aclImdb_v1.tar.gz解压后是一个目录# 我们可以使用python的rarfile库进行解压# 训练数据和测试数据已经经过切分,其中训练数据的地址为:# ./aclImdb/train/pos/ 和 ./aclImdb/train/neg/,分别存储着正向情感的数据和负向情感的数据# 我们把数据依次读取出来,并放到data_set里# data_set中每个元素都是一个二元组,(句子,label),其中label=0表示负向情感,label=1表示正向情感for label in ["pos", "neg"]:with tarfile.open("./aclImdb_v1.tar.gz") as tarf:path_pattern = "aclImdb/train/" + label + "/.*\.txt$" if is_training \else "aclImdb/test/" + label + "/.*\.txt$"path_pattern = re.compile(path_pattern)tf = tarf.next()while tf != None:if bool(path_pattern.match(tf.name)):sentence = tarf.extractfile(tf).read().decode()sentence_label = 0 if label == 'neg' else 1data_set.append((sentence, sentence_label)) tf = tarf.next()return data_settrain_corpus = load_imdb(True)
test_corpus = load_imdb(False)for i in range(5):print("sentence %d, %s" % (i, train_corpus[i][0])) print("sentence %d, label %d" % (i, train_corpus[i][1]))
一般来说,在自然语言处理中,需要先对语料进行切词,这里我们可以使用空格把每个句子切成若干词的序列,代码如下:
def data_preprocess(corpus):data_set = []for sentence, sentence_label in corpus:# 这里有一个小trick是把所有的句子转换为小写,从而减小词表的大小# 一般来说这样的做法有助于效果提升sentence = sentence.strip().lower()sentence = sentence.split(" ")data_set.append((sentence, sentence_label))return data_settrain_corpus = data_preprocess(train_corpus)
test_corpus = data_preprocess(test_corpus)
print(train_corpus[:5])
print(test_corpus[:5])
在经过切词后,需要构造一个词典,把每个词都转化成一个ID,以便于神经网络训练。代码如下:
# 构造词典,统计每个词的频率,并根据频率将每个词转换为一个整数id
def build_dict(corpus):word_freq_dict = dict()for sentence, _ in corpus:for word in sentence:if word not in word_freq_dict:word_freq_dict[word] = 0word_freq_dict[word] += 1word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)word2id_dict = dict()word2id_freq = dict()# 一般来说,我们把oov和pad放在词典前面,给他们一个比较小的id,这样比较方便记忆,并且易于后续扩展词表word2id_dict['[oov]'] = 0word2id_freq[0] = 1e10# 添加word2id_dict['[pad]'] = 1word2id_freq[1] = 1e10for word, freq in word_freq_dict:word2id_dict[word] = len(word2id_dict)word2id_freq[word2id_dict[word]] = freqreturn word2id_freq, word2id_dictword2id_freq, word2id_dict = build_dict(train_corpus)
vocab_size = len(word2id_freq)
print("there are totoally %d different words in the corpus" % vocab_size)
for _, (word, word_id) in zip(range(10), word2id_dict.items()):print("word %s, its id %d, its word freq %d" % (word, word_id, word2id_freq[word_id]))
打印语料库中出现次数前十的单词信息:
there are totoally 252173 different words in the corpus
word [oov], its id 0, its word freq 10000000000
word [pad], its id 1, its word freq 10000000000
word the, its id 2, its word freq 322174
word a, its id 3, its word freq 159949
word and, its id 4, its word freq 158556
word of, its id 5, its word freq 144459
word to, its id 6, its word freq 133965
word is, its id 7, its word freq 104170
word in, its id 8, its word freq 90521
word i, its id 9, its word freq 70477
注意:
在代码中我们使用了一个特殊的单词"[oov]"(out-of-vocabulary),用于表示词表中没有覆盖到的词。之所以使用"[oov]"这个符号,是为了处理某一些词,在测试数据中有,但训练数据没有的现象。
在完成word2id词典假设之后,我们还需要进一步处理原始语料,把语料中的所有句子都处理成ID序列,代码如下:
# 把语料转换为id序列
def convert_corpus_to_id(corpus, word2id_dict):data_set = []for sentence, sentence_label in corpus:# 将句子中的词逐个替换成id,如果句子中的词不在词表内,则替换成oov# 这里需要注意,一般来说我们可能需要查看一下test-set中,句子oov的比例,# 如果存在过多oov的情况,那就说明我们的训练数据不足或者切分存在巨大偏差,需要调整sentence = [word2id_dict[word] if word in word2id_dict \else word2id_dict['[oov]'] for word in sentence] data_set.append((sentence, sentence_label))return data_settrain_corpus = convert_corpus_to_id(train_corpus, word2id_dict)
test_corpus = convert_corpus_to_id(test_corpus, word2id_dict)
print("%d tokens in the corpus" % len(train_corpus))
print(train_corpus[:5])
print(test_corpus[:5])
接下来,我们就可以开始把原始语料中的每个句子通过截断和填充,转换成一个固定长度的句子,并将所有数据整理成mini-batch,用于训练模型。
处理变长数据
在使用神经网络处理变长数据时,需要先设置一个全局变量max_seq_len,再对语料中的句子进行处理,将不同的句子组成mini-batch,用于神经网络学习和处理。
1. 设置全局变量
设定一个全局变量max_seq_len,用来控制神经网络最大可以处理文本的长度。我们可以先观察语料中句子的分布,再设置合理的max_seq_len值,以最高的性价比完成句子分类任务(如情感分类)。
2. 对语料中的句子进行处理
我们通常采用 截断+填充 的方式,对语料中的句子进行处理,将不同长度的句子组成mini-batch,以便让句子转换成一个张量给神经网络进行计算,如 **图 ** 所示。
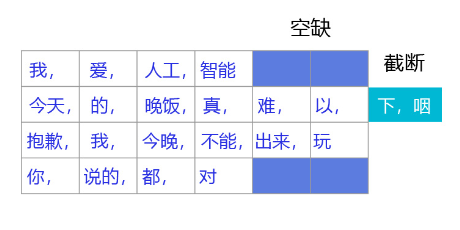
- 对于长度超过max_seq_len的句子,通常会把这个句子进行截断,以便可以输入到一个张量中。句子截断是有技巧的,有时截取句子的前一部分会比后一部分好,有时则恰好相反。当然也存在其他的截断方式,有兴趣的读者可以翻阅一下相关资料,这里不做赘述。
- 前向截断: “晚饭, 真, 难, 以, 下, 咽”
- 后向截断:“今天, 的, 晚饭, 真, 难, 以”
- 对于句子长度不足max_seq_len的句子,我们一般会使用一个特殊的词语对这个句子进行填充,这个过程称为Padding。假设给定一个句子“我,爱,人工,智能”,max_seq_len=6,那么可能得到两种填充方式:
- 前向填充: “[pad],[pad],我,爱,人工,智能”
- 后向填充:“我,爱,人工,智能,[pad],[pad]”
同样,不同的填充方式也对网络训练效果有一定影响。一般来说,后向填充是更常用的选择。
处理变长数据构建mini-batch,代码如下:
# 编写一个迭代器,每次调用这个迭代器都会返回一个新的batch,用于训练或者预测
def build_batch(word2id_dict, corpus, batch_size, epoch_num, max_seq_len, shuffle = True, drop_last = True):# 模型将会接受的两个输入:# 1. 一个形状为[batch_size, max_seq_len]的张量,sentence_batch,代表了一个mini-batch的句子。# 2. 一个形状为[batch_size, 1]的张量,sentence_label_batch,每个元素都是非0即1,代表了每个句子的情感类别(正向或者负向)sentence_batch = []sentence_label_batch = []for _ in range(epoch_num): #每个epoch前都shuffle一下数据,有助于提高模型训练的效果#但是对于预测任务,不要做数据shuffleif shuffle:random.shuffle(corpus)for sentence, sentence_label in corpus:sentence_sample = sentence[:min(max_seq_len, len(sentence))]if len(sentence_sample) < max_seq_len:for _ in range(max_seq_len - len(sentence_sample)):sentence_sample.append(word2id_dict['[pad]'])sentence_sample = [[word_id] for word_id in sentence_sample]sentence_batch.append(sentence_sample)sentence_label_batch.append([sentence_label])if len(sentence_batch) == batch_size:yield np.array(sentence_batch).astype("int64"), np.array(sentence_label_batch).astype("int64")sentence_batch = []sentence_label_batch = []if not drop_last and len(sentence_batch) > 0:yield np.array(sentence_batch).astype("int64"), np.array(sentence_label_batch).astype("int64")for batch_id, batch in enumerate(build_batch(word2id_dict, train_corpus, batch_size=3, epoch_num=3, max_seq_len=30)):print(batch)break
【动手学 RAG】系列文章:
- 【RAG 项目实战 01】在 LangChain 中集成 Chainlit
- 【RAG 项目实战 02】Chainlit 持久化对话历史
- 【RAG 项目实战 03】优雅的管理环境变量
- 【RAG 项目实战 04】添加多轮对话能力
- 【RAG 项目实战 05】重构:封装代码
- 【RAG 项目实战 06】使用 LangChain 结合 Chainlit 实现文档问答
- 【RAG 项目实战 07】替换 ConversationalRetrievalChain(单轮问答)
- 【RAG 项目实战 08】为 RAG 添加历史对话能力
- More...
【动手部署大模型】系列文章:
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 01 - 环境安装
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 02 - 推理加速
- 【模型部署】vLLM 部署 Qwen2-VL 踩坑记 03 - 多图支持和输入格式问题
- More...
【人人都能学得会的NLP】系列文章:
- 【人人都能学得会的NLP - 文本分类篇 01】使用ML方法做文本分类任务
- 【人人都能学得会的NLP - 文本分类篇 02】使用DL方法做文本分类任务
- 【人人都能学得会的NLP - 文本分类篇 03】长文本多标签分类分类如何做?
- 【人人都能学得会的NLP - 文本分类篇 04】层次化多标签文本分类如何做?
- 【人人都能学得会的NLP - 文本分类篇 05】使用LSTM完成情感分析任务
- 【人人都能学得会的NLP - 文本分类篇 06】基于 Prompt 的小样本文本分类实践
- More...
本文由mdnice多平台发布