ComE(Community Embedding)
Learning Community Embedding with Community Detection and Node Embedding on Graphs
用社区检测和图上的节点嵌入学习社区嵌入
论文来源:CIKM 2017 https://www.sentic.net/community-embedding.pdf【2017】
项目地址:https://github.com/andompesta/ComE
论文原作者:Sandro Cavallari, Vincent W. Zheng, Hongyun Cai, et al.
单位:Advanced Digital Sciences Center, Nanyang Technological University
一、问题:
传统流水线方法:首先使用谱聚类来识别社区,然后对每个社区使用高斯混合模型。这种方法的问题在于它没有统一的目标函数,使得后期优化变得困难。
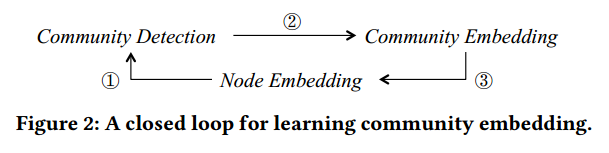
本文方法:每个社区可以被视为一个高斯分布,通过一个多元高斯分布来更好地表示社区的嵌入表达,在社区嵌入、社区检测和节点嵌入之间开发了一个闭环,最后共同优化这三个任务,以使它们相互加强。
因此,作者提出了一种新的社区嵌入框架,它联合地同时解决了社区嵌入、社区检测和节点嵌入等三个问题。
二、Model
1、社区检测和社区嵌入。
这篇论文比较创新的一点,就是将社区嵌入定义为低维空间中的多元高斯分布。即对于社区k来说( \(k∈{1,...,K}\) ),它在\(d\)维空间下的社区嵌入是一个多元高斯分布 $N(ψ_k,Σ_k) $,其中 \(ψ_k∈\mathbb R^d\) 表示的是社区内节点的平均向量(即中心点), \(Σ_k∈\mathbb R^{d∗d}\) 表示的是协方差矩阵。整篇文章最大的难点在于,如何用统一的目标函数来使得社区嵌入、社区检测和节点嵌入三者问题得到最优化的结果。由于社区嵌入是由多元高斯分布来表达的,因此就可以通过高斯混合模型来完成。考虑每个节点 \(v_i\)的嵌入 \(ϕ_i\)是由社区 \(z_i=k\)的多元高斯分布生成的。然后,对于所有节点在 \(V\) 中,有如下似然函数:
公式(1)是社区检测和嵌入问题中的似然函数,它描述了在给定社区分配和社区参数的情况下,观测到的节点嵌入的概率。这里的各个部分解释如下:
- \(\prod_{i=1}^{|V|}\) :表示对所有节点 \(i\) 从 1 到 \(|V|\) (图中节点的总数)的乘积。这个乘积遍历图中的每个节点,计算每个节点嵌入的概率。
- \(\sum_{k=1}^{K}\) :表示对所有可能的社区 \(k\) 从 1 到 \(K\) (社区的总数)的求和。这个求和考虑了每个节点属于每个社区的概率。
- $p(z_i = k) $:表示节点 \(v_i\) 属于社区 \(k\) 的概率,将这个概率表达为 \(π_{ik}\):$ π_{ik}∈[0,1]\(,\)∑_{k=1}^Kπ_{ik}=1$。在社区检测中,这个概率是未知的,需要通过优化来确定。
- \(p(v_i \mid z_i = k; \phi_i, \psi_k, \Sigma_k)=\mathcal N(ϕ_i|ψ_k,Σ_k)\) :表示在给定节点 \(v_i\) 属于社区 \(k\) 的条件下,节点嵌入 \(\phi_i\) 的条件概率。这个概率由多元高斯分布定义,其中 \(\phi_i\) 是节点 \(v_i\) 的嵌入向量(模型试图学习的表示); \(\psi_k\) 是社区 \(k\) 的均值向量, \(\Sigma_k\) 是社区 $ k$ 的协方差矩阵(社区嵌入的参数,需要通过优化来学习)。
整个似然函数是所有节点嵌入概率的乘积,每个节点嵌入的概率是其属于每个社区概率的加权和。这个似然函数是社区检测和嵌入过程中优化的目标,通过最大化这个似然函数,可以同时学习节点的社区归属概率和社区的嵌入参数。这种方法将社区检测和社区嵌入整合到一个统一的框架中,使得这两个任务可以同时进行,从而可能提高性能和准确性。
2、节点嵌入
本文在节点嵌入时,考虑了三种距离。
(1). 为了保持节点的一阶邻近性(直接相邻的节点在嵌入空间中也应该是相似的),用的是类似LINE算法的方法;为了保持节点的二阶邻近性,则是用了DeepWalk的想法。
一阶邻近性,$ \log \sigma(\phi_{j}^{T} \phi_{i}) $是对sigmoid函数的对数,sigmoid函数 $ \sigma(x) $定义为 $ 1 / (1 + \exp(-x)) $,它将任意实数映射到 (0, 1) 区间,通常用于将内积转换为概率值:
为了保持二阶邻近性,LINE和DeepWalk都强制两个共享许多“上下文”(即,在 \(\zeta\) 跳数内的邻居)的节点具有相似的嵌入。每个节点有两个角色:一个代表自身的节点,另一个是其他节点的上下文。为了区分这些角色,DeepWalk为每个节点 $ v_{j} $ 引入了一个额外的上下文嵌入 $\phi_{j}^{\prime} \in \mathbb{R}^{d} $。将 \(C_{i}\) 表示为 $ v_{i}$ 的上下文集合。采用负采样来定义一个函数,用于衡量 \(v_{i}\) 如何生成其上下文 \(v_{j} \in C_{i}\) :
其中,$ v_{l} \sim P_{n}(v_{l}) $ 表示根据概率 $P_{n}(v_{l}) $ 采样节点 \(v_{l}\) 作为 \(v_{i}\) 的“负上下文”。设置 $P_{n}(v_{l}) \propto r_{l}^{3/4} $,其中 \(r_{l}\) 是 \(v_{l}\) 的度数。总共有 m 个负上下文。通常,最大化方程4会强制节点 $v_{i} $ 的嵌入 $ \phi_{i} $最好地生成其正上下文 $\phi_{j}^{\prime} $,而不是其负上下文 $\phi_{l}^{\prime\prime} $。然后,通过最小化以下目标函数来保持二阶邻近性:
其中, $\alpha > 0 $是一个权衡参数,以学习能够保持二阶邻近性的节点嵌入。通过调整 \(\alpha\) 参数,可以在一阶和二阶邻近性之间进行权衡。
3、闭合循环
这部分介绍了如何在社区检测和节点嵌入之间建立反馈循环,以及如何通过统一不同阶的邻近性来优化节点嵌入。为了闭合图2中的循环,需要使社区检测和社区嵌入的反馈作用于节点嵌入。假设已经在第3.1节中识别了混合社区成员资格 $ \pi_{ik} $ 和社区嵌入 $(\psi_{k}, \Sigma_{k}) $。然后,可以重新使用公式1来实现这种反馈,通过将节点嵌入 \(\phi_{i}\) 视为未知数。有效地,优化公式1关于 \(\phi_{i}\) 会迫使同一社区内的节点 \(\phi_{i}\) 更接近相应的社区中心 $ \psi_{k}$ 。也就是说,共享一个社区的两个节点可能具有相似的嵌入。与一阶和二阶邻近性相比,这种设计在节点嵌入上实施了社区感知的高阶邻近性,这对于后续的社区检测和嵌入非常有用。
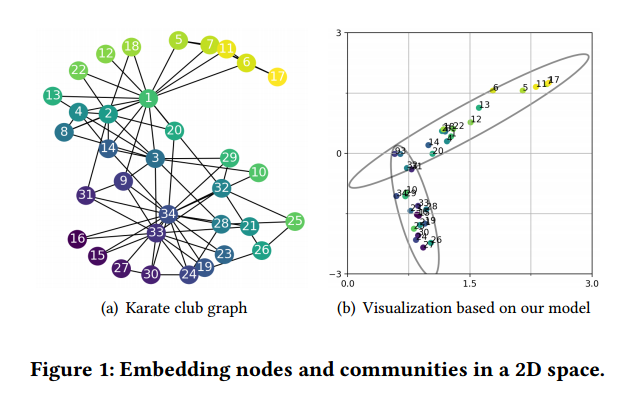
例如,在图1(a)中,节点3和节点10直接相连,但根据文献[35],它们倾向于属于两个不同的社区。因此,仅通过保持一阶邻近性,可能无法很好地区分它们的社区成员资格差异。另一个例子是,节点9和节点10共享许多一跳和两跳邻居,但与节点10相比,节点9更倾向于接近由节点1领导的社区。因此,仅通过保持二阶邻近性,可能也无法很好地区分它们的社区成员资格差异。
基于闭合的循环,共同优化社区检测、社区嵌入和节点嵌入。有三种类型的邻近性需要考虑用于节点嵌入,包括一阶、二阶和高阶邻近性。通常,有两种方法可以结合不同类型的邻近性用于节点嵌入:(1)“concatenation”,例如,LINE首先分别优化 $O_{1} $ 和$ O_{2} $,然后将每个节点的两个结果嵌入连接成一个长向量作为最终输出;(2)“unification”,例如,SDNE[29]学习每个节点的单一节点嵌入,以同时保持一阶和二阶邻近性。在本文中,为了鼓励节点嵌入统一多种邻近性,采用了统一方法,并将其他方法留作未来工作。因此,基于公式1,定义了社区检测和社区嵌入的目标函数,以及强制执行节点嵌入的高阶邻近性:
其中 $ \beta \geq 0 $ 是一个权衡参数。定义 $ \Phi = {\phi_{i}}, \Phi' = {\phi_{i}'}, \Pi = {\pi_{ik}}, \Psi = {\psi_{k}'} $和 $ \Sigma = {\Sigma_{k}}$ 对于 $i = 1, \ldots, |V| 和 k = 1, \ldots, K $。
然后,统一了节点嵌入的一阶和二阶邻近性。ComE的最终目标函数是:
最终优化问题变为:
三、推理
迭代优化过程。
固定 $(\Phi, \Phi') $,优化 $(\Pi, \Psi, \Sigma) $。由于在优化的时候,可能存在一些情况,使得高斯分量折叠到一个点,那么此时就会使得 \(O_3\) 变成负无穷。所以这里需要加一个限制条件,通过控制\(diag(\Sigma_k)>0\) ,使得\(O_3\) 不会变成负无穷。具体做法就是当遇到 $diag(\Sigma_k)=0 $的情况时,就随机重新设置一个合适的值即可。 之后通过EM算法进行优化求导。:
其中 $ \gamma_{ik} = \frac{\pi_{ik} N(\phi_i \mid \psi_k, \Sigma_k)}{\sum_{k'=1}^{K} \pi_{ik'} N(\phi_i \mid \psi_{k'}, \Sigma_{k'})} $ 且 $ N_k = \sum_{i=1}^{|V|} \gamma_{ik} \(。值得注意的是,实际上如果\) (\Phi, \Phi') $ 被合理初始化(例如,在的实验中通过DeepWalk),$ \operatorname{diag}(\Sigma_{k}) > 0 $的约束很容易满足,因此 $(\Pi, \Psi, \Sigma) $的推断可以快速收敛。
固定 $ (\Pi, \Psi, \Sigma)$,优化 $(\Phi, \Phi') $。由于 $O_3 $中对数项内的求和,计算 $\phi_i $的梯度不方便。因此,尝试最小化 $ \mathcal{L}(\Phi, \Phi' \mid \Phi, \Psi, \Sigma) $的上界。具体来说,引入:
很容易证明 $O_3'(\Phi \mid \Pi, \Psi, \Sigma) \geq O_3(\Phi \mid \Pi, \Psi, \Sigma) $由于以下对数凹性:
因此,定义:
并且,因此$ \mathcal{L}'(\Phi, \Phi' \mid \Pi, \Psi, \Sigma) \geq \mathcal{L}(\Phi, \Phi' \mid \Pi, \Psi, \Sigma) $。通过随机梯度下降(SGD)[17]来优化 $\mathcal{L}'(\Phi, \Phi') $。对于每个 $ v_i \in V $,有:
计算上下文嵌入的梯度:
算法和复杂度。在算法1中总结了ComE的推理算法。在第1行,对于每个 $v_i \in V $,在图 $G $ 上以长度 $\ell $从 $v_i $开始采样 $\gamma $条路径。在第2行,通过DeepWalk初始化 $ (\Phi, \Phi') \(。在第4-8行,固定\) (\Phi, \Phi') $并优化 $ (\Pi, \Psi, \Sigma) $ 以进行社区检测和嵌入。在第9-16行,固定 $ (\Pi, \Psi, \Sigma) $并优化 $ (\Phi, \Phi') $以进行节点嵌入。
特别是,通过一阶邻近性(第9-10行)、二阶邻近性(第11-14行)和社区感知的高阶邻近性(第15-16行)来更新节点嵌入。分析了算法1的复杂度。第1行的路径采样需要 $O(|V|\gamma \ell) $ 时间。第2行通过DeepWalk初始化参数需要 $O(|V|) $ 时间。第5行的社区检测和嵌入需要 $O(|V|K) $ 时间。第6-8行的约束检查需要 $ O(K) $ 时间。第9-10行的一阶邻近性节点嵌入需要 $O(|E|) $ 时间。第11-14行的二阶邻近性节点嵌入需要 $O(\ell |V|\gamma \ell) $ 时间。第15-16行的社区感知高阶邻近性节点嵌入需要 $O(|V|K) $ 时间。总的来说,复杂度是$ O(|V|\gamma \ell + |V| + T_1 \times (T_2|V|K + K + |E| + |V|\gamma \ell + |V|K)) $,这与图的大小(即, $|V| \(\) 和 \(\) |E|$ )线性相关。因此,算法1是高效的。

四、Conclusion
在本文中主要研究了在网络中对社区进行嵌入这个重要的问题。论文的亮点在于通过一个多元高斯分布来更好地表示社区的嵌入表达。之后,提出了算法ComE,使得在社区嵌入、社区检测和节点嵌入之间开发了一个闭环,最后共同优化这三个任务,以使它们相互加强。
参考:
https://zhuanlan.zhihu.com/p/36924789