key word:
阿里巴巴,广告点击率预测Motivation: 截至2018年,还没有相关的推荐算法考虑到用户兴趣的趋势。作者认为大多数的模型是直接将行为视为兴趣,无法直接提取用户真正的潜在兴趣特征。因此,作者提出了
DIEN模型,利用interest extractor layer通过用户历史行为序列捕捉用户的兴趣序列特征,通过interest evolving layer处理目标的兴趣演变过程。preface: 笔者认为这篇文章的模型创新关键点在于关注了
RNN的隐藏状态,通过一个辅助损失训练每一个隐藏状态,每一个隐藏状态对应一个行为序列的子兴趣,并基于这些子兴趣结合注意力机制进一步学习兴趣的演化发展。
一、模型设计
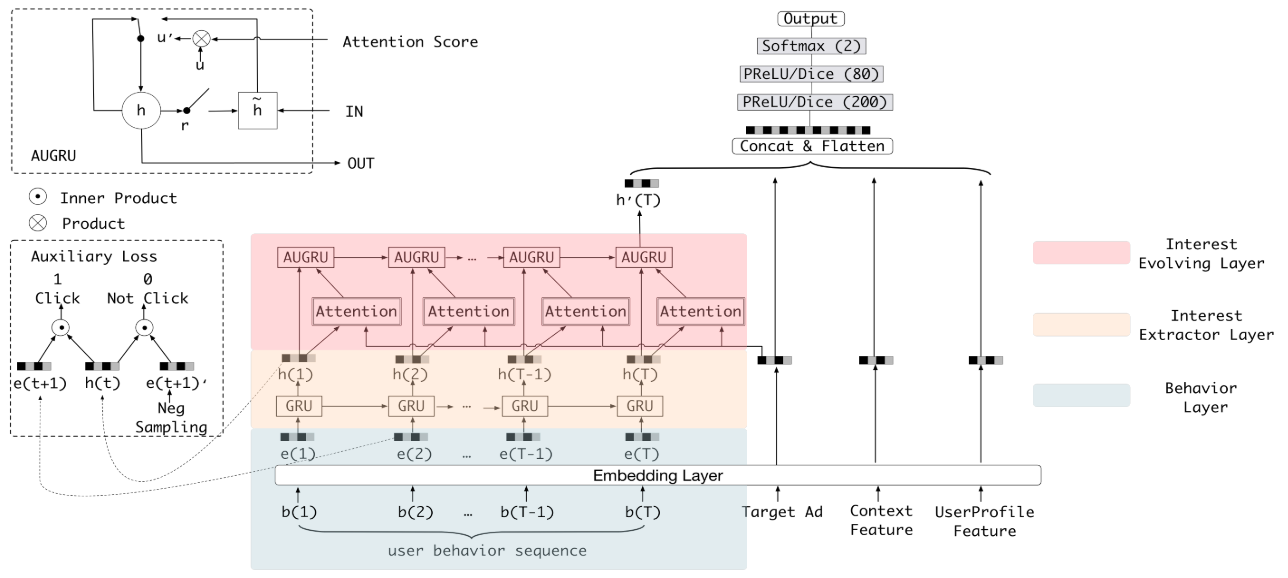
💡 Interest Extractor Layer
作者认为用户的行为序列发生变化时,兴趣也会跟着发生变化。因此通过Interest Extractor Layer提取用户的潜在兴趣特征。作者采用了
GRU作为时序模型处理长序列的行为数据,不采用RNN与LSTM,这是由于:GRU克服了RNN的梯度消失问题,比LSTM更快
作者认为只采用简单的RNN模型无法发挥隐藏状态的优势,这些隐藏状态在传统模型中只能捕捉行为之间的依赖性,而不能作为用户的潜在特征。因此,作者提出了auxiliary loss,利用t+1隐藏状态监督t隐藏状态的学习。负样本是除了当前行为序列t时刻的物品外的所有物品。训练的数据为一个正样本行为序列\(e_b\)和一个负样本行为序列\(e_b'\)。辅助损失函数的表达为:
其中,\(\sigma\)表示sigmoid激活函数,\(h_t^i\)表示第i个用户的第t个隐藏状态。
最终的损失为:
[!tip]
作者认为:在辅助损失的帮助下,每个隐藏状态都有足够的表达能力来表示用户采取行为后的兴趣状态。
Interest Evolving Layer
作者认为建立兴趣的发展的过程可以为最终的点击率预测提供更多的历史信息,更好的预测点击率。每个用户都有着不同的兴趣,并且每个兴趣都有不同的演变过程。基于
Interest Extractor Layer得到的隐状态兴趣表示,引入注意力机制,增加相关兴趣的影响关系,减弱不同兴趣之间的干扰。
注意力函数在论文中表达为:
其中,\(e_a\)表示候选广告的向量,\(W \in (n_h,n_a)\), \(a_t\)表示注意力得分
作者提出了三种注意力机制和GRU结合的方式:
- GRU with attentional input (AIGRU)
直接利用注意力得分作用在
Interest Evolving Layer上【弊端】:AIGRU 中使用注意力得分对输入兴趣进行加权,希望减小不相关兴趣的影响。但由于 GRU 的特性,即使输入为零,它的内部状态依然可能发生变化,不相关兴趣还是会对模型的学习过程产生影响,导致效果不好。
\(i_t'\)表示第二层GRU的输入。
- Attention based GRU(AGRU)
AGRU 在此前已经被人提出解决问答系统的问题,有效的提取了问句中的关键信息。这篇文章利用他提取相对兴趣,将注意力得分嵌入到更新门上
- GRU with attentional update gate (AUGRU)
注意力得分是一个标量,用其实现更新门忽略了不同维度的不同重要性,在AGRU的实现中,隐状态都是乘以一个固定的注意力得分,因此,提出了利用向量嵌入到更新门上
二、实验
数据集
Amazon Dataset: Using Books and Electronics to verify the effect of DIEN.
Industrial Dataset
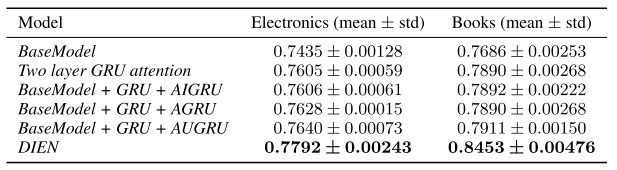
实验结果
可视化
时序模型的隐藏状态可以反映兴趣的发展过程。作者选取一个行为序列:Computer Speakers, Headphones, Vehicle GPS, SD & SDHC Cards, Micro SD Cards, External Hard Drives, Headphones, Cases, successively;并通过PCA降维至两维
- 黄色线:没有使用注意力得分;
- 蓝色线:使用了注意力得分但是目标物品是
Screen Protectors,行为序列没有出现过,因此和黄色线相似; - 红色线:目标是
Cases,隐状态的变化与最后一个物品有很强的相关性;