本文深入探讨了谷歌 TPU v1 的架构和设计原理。我们将解析 TPU v1 芯片的关键元素,包括 DDR3 DRAM、矩阵乘法单元(MXU)、累加器和控制指令单元。重点介绍脉动阵列(Systolic Array)的工作原理,它是 TPU 的核心,通过数据的流水线式处理实现高效的矩阵乘法计算。此外,我们还将对比 TPU v1 与 CPU、GPU 在服务器环境中的性能差异,以及 TPU v1 在当时技术背景下的创新之处。
TPU v1 芯片架构
我们先来看一下谷歌的打印电路板(左图)和电路板的示意图(右图)
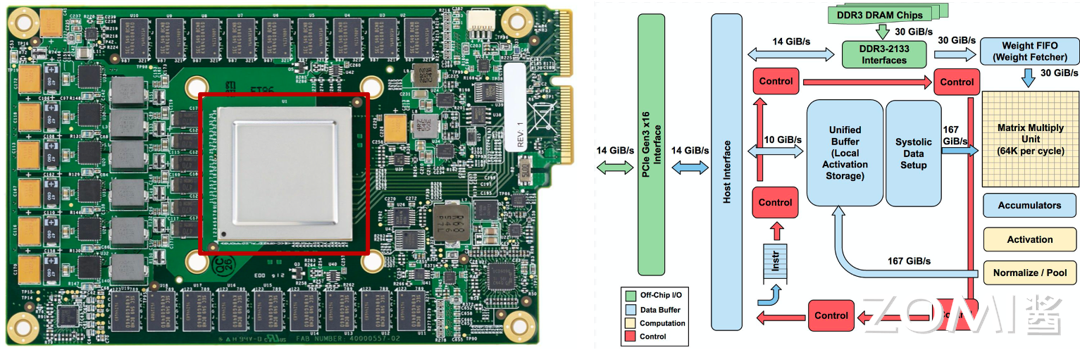
基于示意图,我们来解析一下 TPU v1 上几个关键的元素:
-
DDR3 DRAM / Weight FIFI: 第一个讲的是谷歌的 Weight FIFO,位于图像的右上角。在模型推理场景,通过 DDR3-2133 接口,模型权重会被存储在 TPU v1 上的 DDR3 RAM 内。这些权重通过 PCIe 从主机计算机的内存中“预加载”到这些芯片上,然后可以传输到芯片的 Weight FIFO 内存中,以便矩阵乘法单元(MXU)使用。
-
矩阵乘法单元 MXU(MMU): MXU 以脉动阵列的形式工作,能够提供 $256 \times 256 \times 8$ bit 的乘加计算,在每个时钟周期输出 256 个 16bit 的部分和计算结果。矩阵单元里面包含一个 64kb 的 Weight Tile 以及一个双缓存单元用于缓存回调。MXU 被谷歌的工程师们描述为“TPU 的心脏”,在本文后面的内容中,我们会更加细致的去剖析这一部分的设计。
-
累加器 Accumulators: 这是一个能够存储 4MiB 的 32-bit 数据的累加单元,用来存储 MXU 计算后的结果。这 4MiB 代表着 4096 个,每个含 256 个元素的 32 位累加器。为什么是 4096 呢?原因是谷歌的工程师注意到每字节的运算次数需要达到峰值性能大约是 1350,继而将其向上舍入到 2048,然后再翻倍让便编译器在运行至峰值性能时能使用双缓冲,这也就是为什么这个累加器被设计为 4MiB。
-
控制指令 Control: 每个芯片都需要一个控制模块,而在 TPU 中,整个控制单元采用了四级流水线设计。控制单元的主要任务是接收通过 PCIE 总线或主机(CPU)传递的指令,并将这些指令执行于 TPU。这些指令源自 CPU,而芯片的指令集为 CISC,共包含 12 条指令。TPU 采用 CISC 而非更简单的 WISC 指令集的原因是,谷歌定义的每条指令的平均执行周期为 10-20 个时钟周期,这使得每条指令相对复杂。特别是,TPU 中的各种单元,如 MXU、UB 和 AU,都定义了一些专门为神经网络设计的高级复杂指令:
- Read_Host_Memory: 从 CPU host 读取数据到 Unified Buffer
- Read_Weight: 从 Weight DRAM 读取数据到 Weight FIFO
- Matrix_Multiply/Convolve: 执行乘法或卷积运算
- Activate: 执行 ReLU,Sigmoid 等激活计算
- Write_Host_Memory: 把计算结果数据从 Unified Buffer 输出到 CPU host
通过这些指令,TPU 能够顺序地执行读取、写入、计算和激活操作,从而处理神经网络各层的具体计算需求。
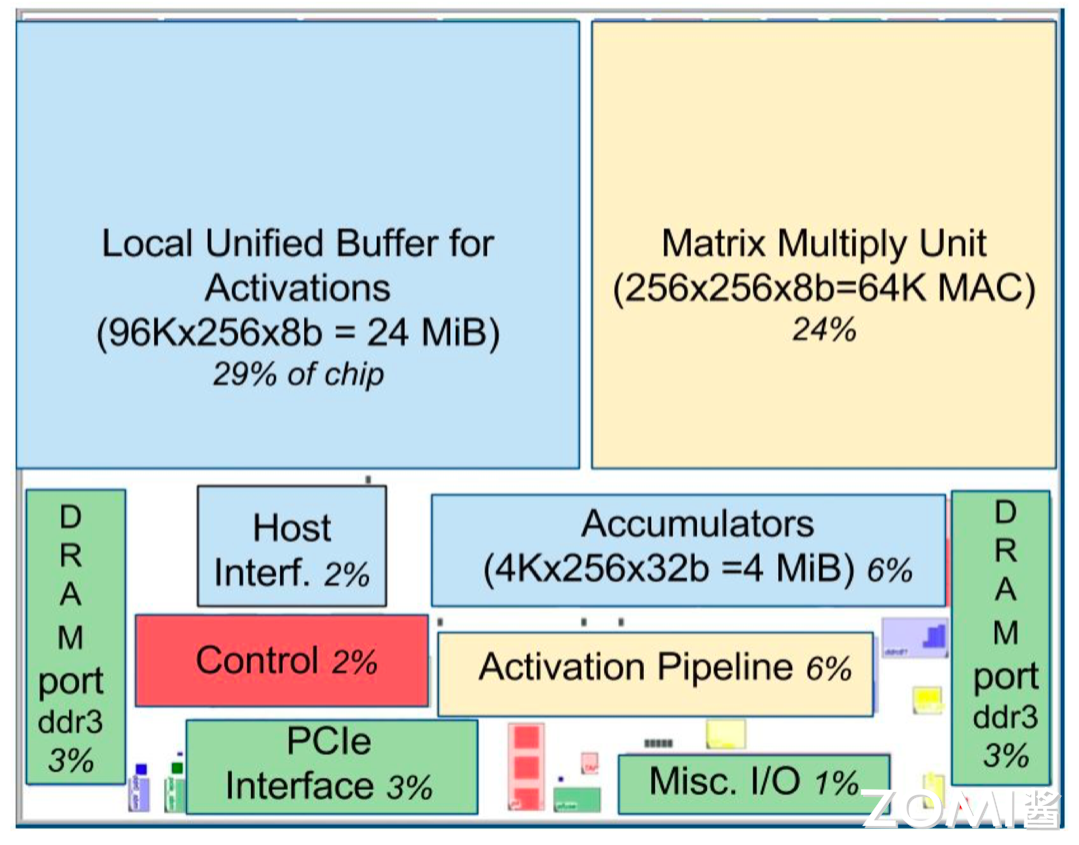
TPU v1 芯片布局图
通过下图,我们可以看到整个 TPU 属于一个专用的电路,里面最大的两个就是 Local Unified BUffeer 和 MXU,一个用于缓存,一个用于计算加乘计算。由于 TPU 是专门应用于矩阵计算的芯片,继而不需要极度复杂的控制单元,所以我们上文讲到的控制器只用了 2%的面积,给核心功能留下了更多的空间。
脉冲阵列 - Systolic Array
脉动阵列简介
脉冲阵列就是 TPU 的核心,也是本文最重要的内容。脉冲阵列的英文名 Systolic Array 就是源于它处理数据的节奏就像心跳一样,于是便有了这个名字。
在我们讲到具体的实现之前,我们需要先回顾一下 Img2Col 这个算法。我们知道,在推理场景,在 2017 年附近,卷积神经网络占据了当时场景的半壁江山。在卷积计算的时候,我们实际上不会对真正地对图片或者 feature map 进行卷积,而是会用 Img2Col 的方式把图片变成矩阵,把卷积换成矩阵相乘的方式。在我们之前推理系统里面我们讲过算法是怎么把卷积操作变成在数学上和卷积相同的矩阵乘法操作,再通过 Col2Img 返回来把计算结果变成 feature map。而自然而然,其中计算压力最大的部分便是我刚才提到的“矩阵乘法”操作。
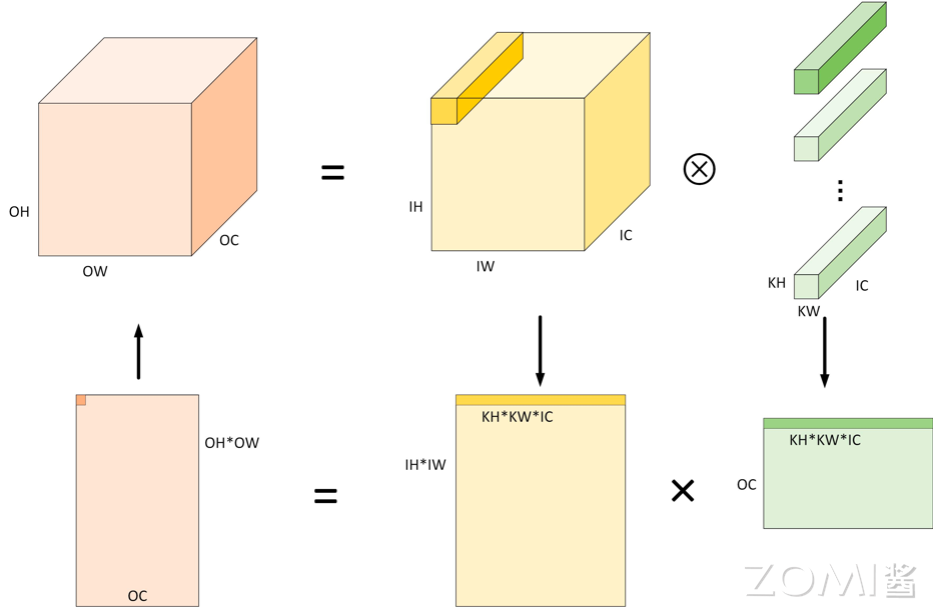
如下图所示,两个矩阵相乘实际上就是用矩阵 A 的一行去点乘矩阵 B 的一列,最终获得输出矩阵的某一个元素。

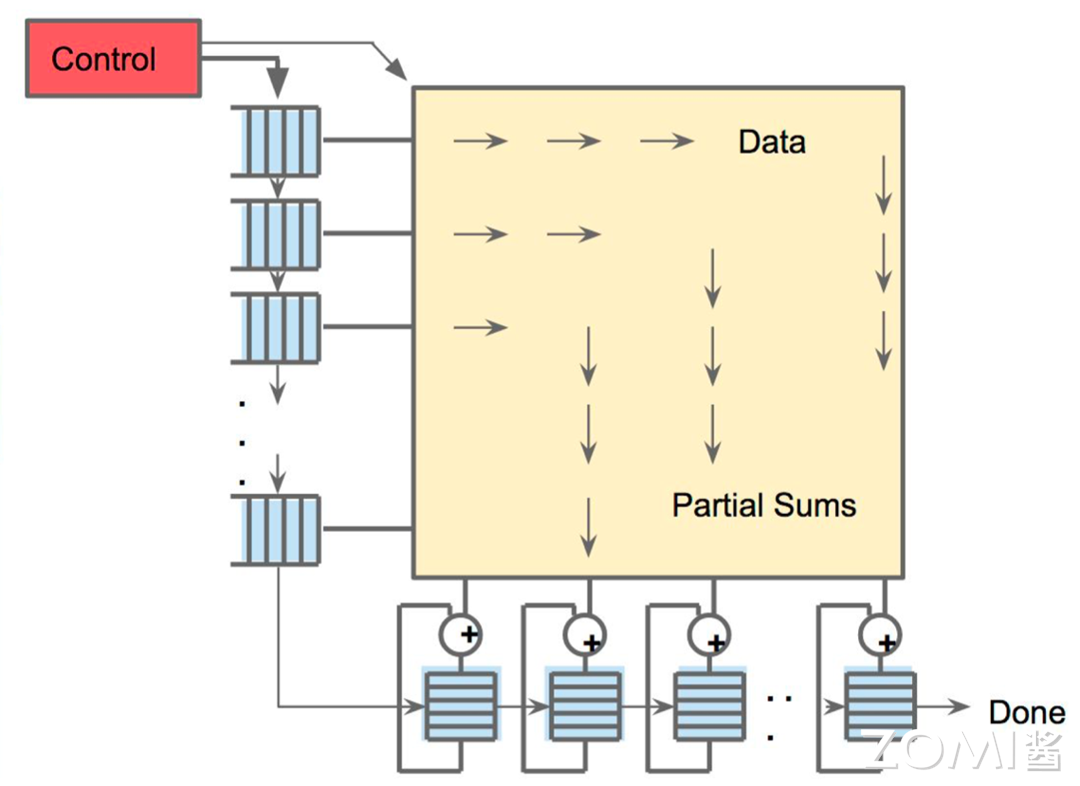
那脉动阵列的数据是怎么流动的呢?
下图是一个简单的图解,数据一波一波根据 FIFO(图最左边的蓝色方块)流入 MXU 进行计算,计算出来的结果会被存放在下方的寄存器中进行累加和输出。整个过程就像是心脏泵血,每一个时钟周期都会进行一次庞大的计算,并流入到下一个需要这个结果的地方。
那么在这里需要注意的是,因为 TPU 在一个时钟周期可以进行 $256 \times 256 = 65536$ 次计算,每次参与计算的逻辑单元又被串联在一起从而实现了计算结果的复用,这使得 TPU 能够在更少次访问芯片内存的情况下完成更高的计算,降低了内存和芯片带宽的压力,从而让 TPU 的能耗比在同时期达到了领先的状态。
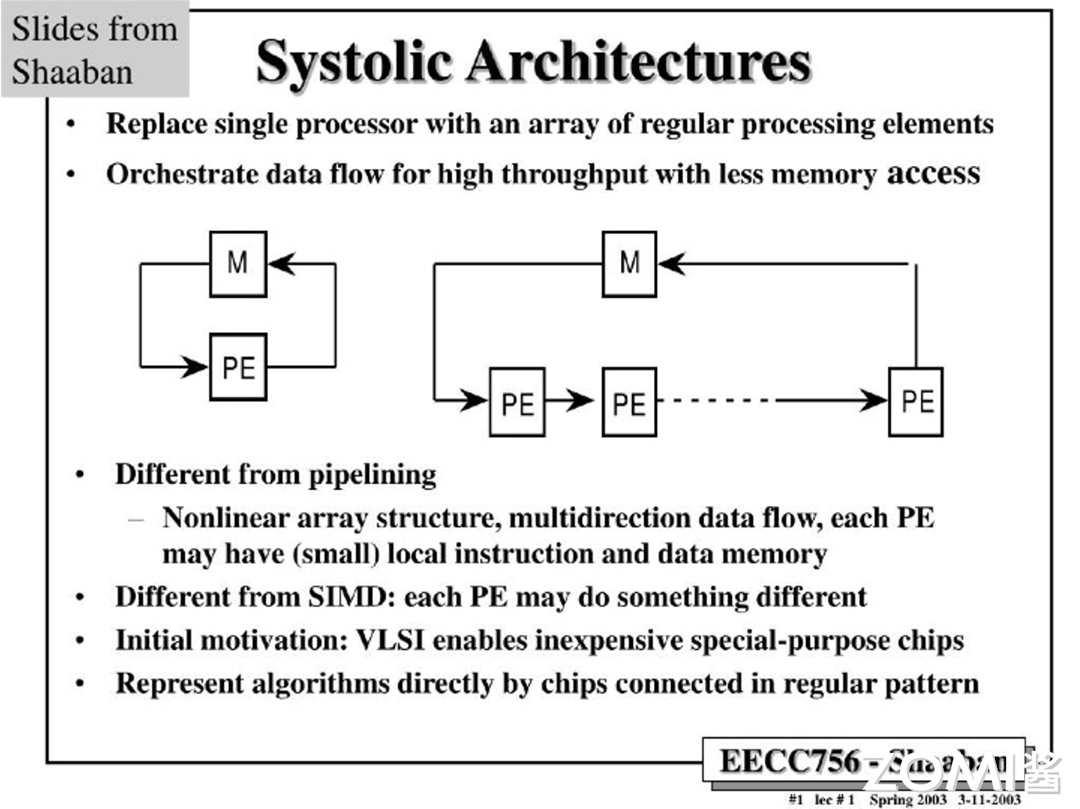
脉动阵列原理
终于讲到了脉动阵列的具体原理,或者说,为什么这种架构相比于传统的数据计算方式有这么大的优势。
下图中 M(Memory)我们可以理解为芯片上的寄存器,PE(Process Elements)则可以理解为进行数据计算的单元。
传统的计算方式(左图)是数据每计算一次就要存储一次,而下一次要调取计算结果的时候也要从存储器里面重新获得这个数据,往复循环。那么在脉动结构中,单一 PE 被替换成了一串 PE。数据在经手所有 PE 计算之后才会被存储,由于矩阵加乘计算需要大量的数据复用,这种数据计算流程大量地减少了数据被访问的次数,从而实现了更高的效率。
那么有了以上先验知识,我们就以两个 $3 \times 3$ 的矩阵,下图中的矩阵 A 和矩阵 B,去上手一下脉动阵列。首先我们要注意的就是脉动阵列数据的排序,相比于“矩形”的矩阵,数据被人工地进行了错位,以阶梯状输入阵列。可以仔细观察,矩阵 A 和矩阵 B 在不同的行列维度上被分开,原因是矩阵乘法需要 A 的每一行去点乘 B 的每一列,因此有了这种设计。可能在这里会有点一头雾水,但是只要仔细看了下面的每一步的拆解,我相信当你重新读这段话的时候会更容易理解。
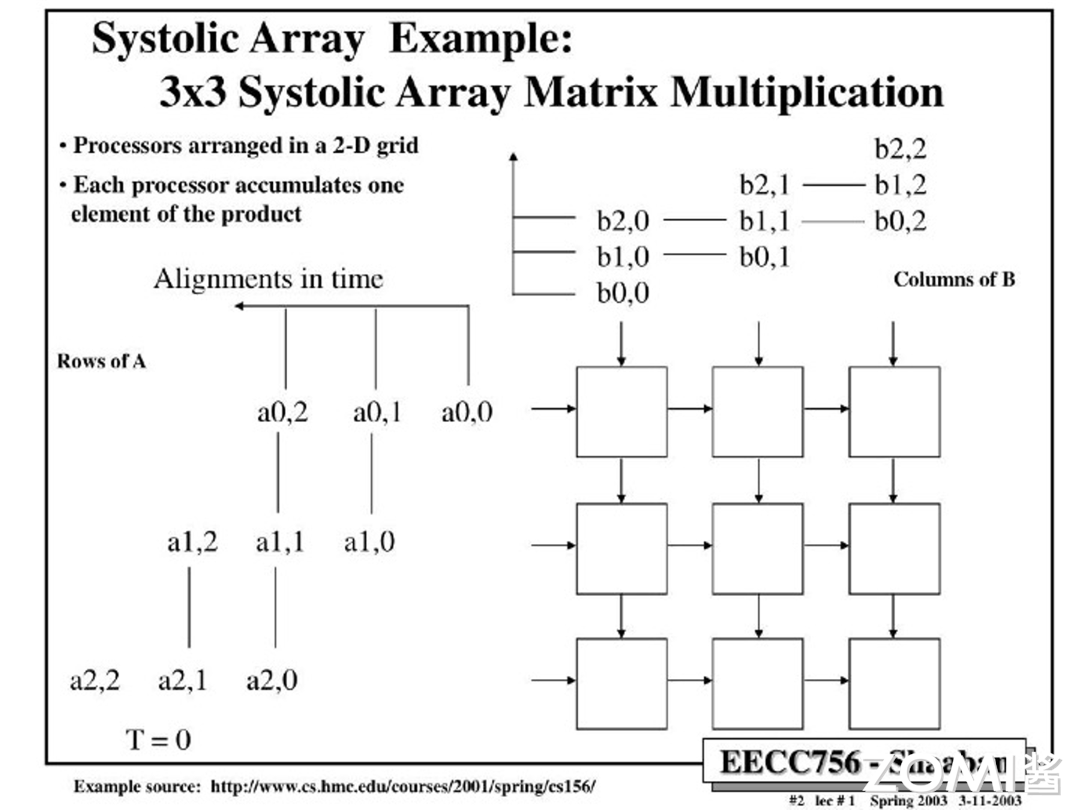
以下是脉动阵列每一步图解
第一步($T=1$): $a_{0,0}$ 和 $b_{0,0}$ 进入 MXU 在第一个处理器被计算,并等待下一轮的数据

第二步($T=2$):$a_{0,0}$ 和 $b_{0,0}$ 沿着原方向被传到下一个处理器,分别与新传入的 $a_{1,0}$ 和 $b_{0,1}$ 计算。同时 $a_{0,1}$ 和 $b_{1,0}$ 进入第一个处理器,和上一轮 $a_{0,0}$ 和 $b_{0,0}$ 的计算结果累加
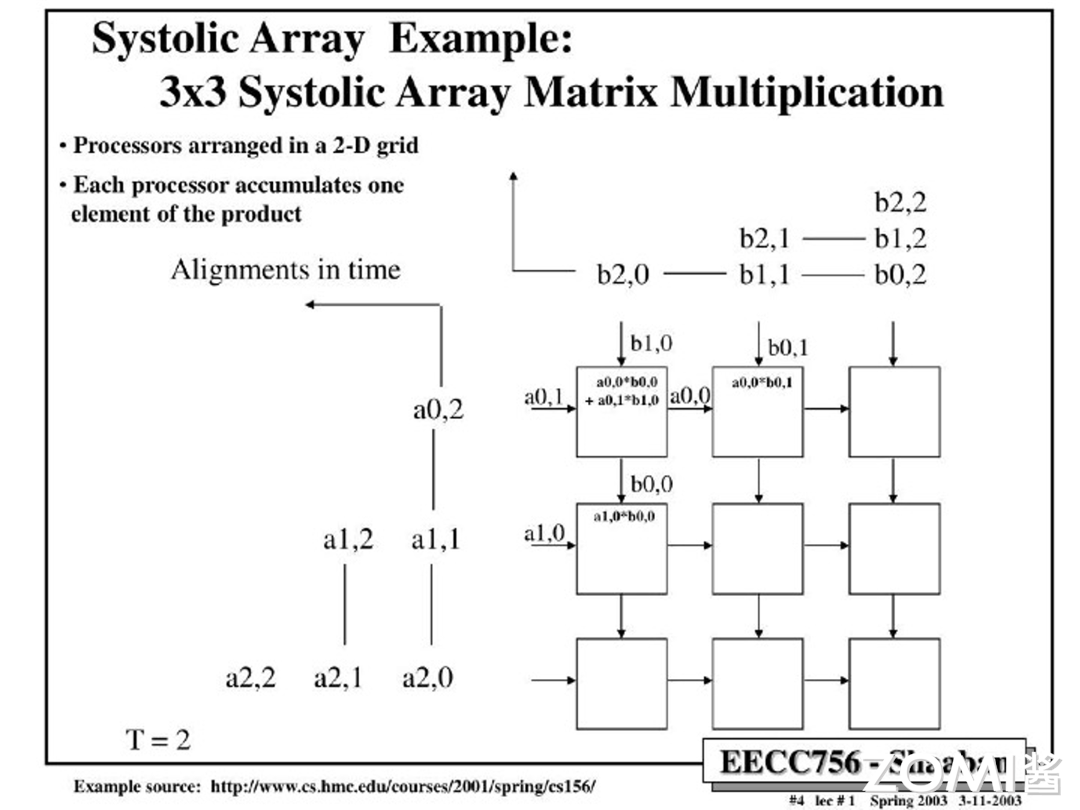
以此类推,反复应用这个计算逻辑,我们就能最终得到矩阵 A 每一行元素和矩阵 B 每一列元素的点乘,再最终将这些运算结果输出,就获得了最终的结果。以下是这个计算过程的的剩余流程展示:
$T=3$:
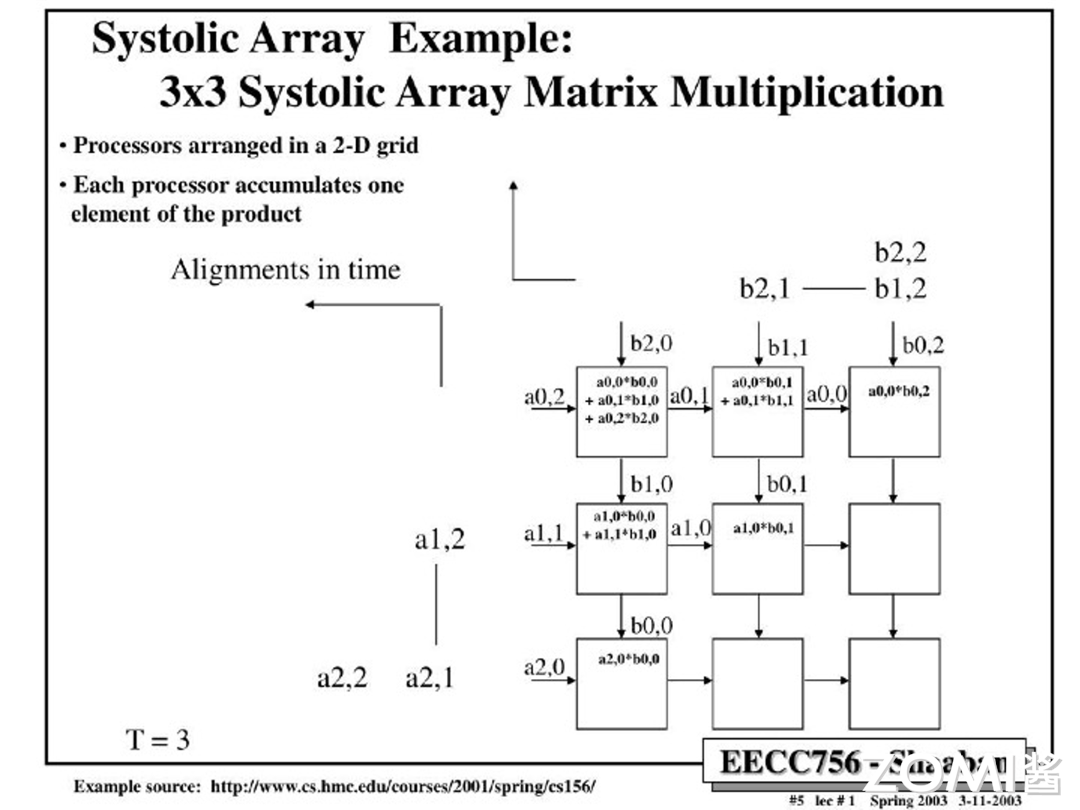
$T=4$:
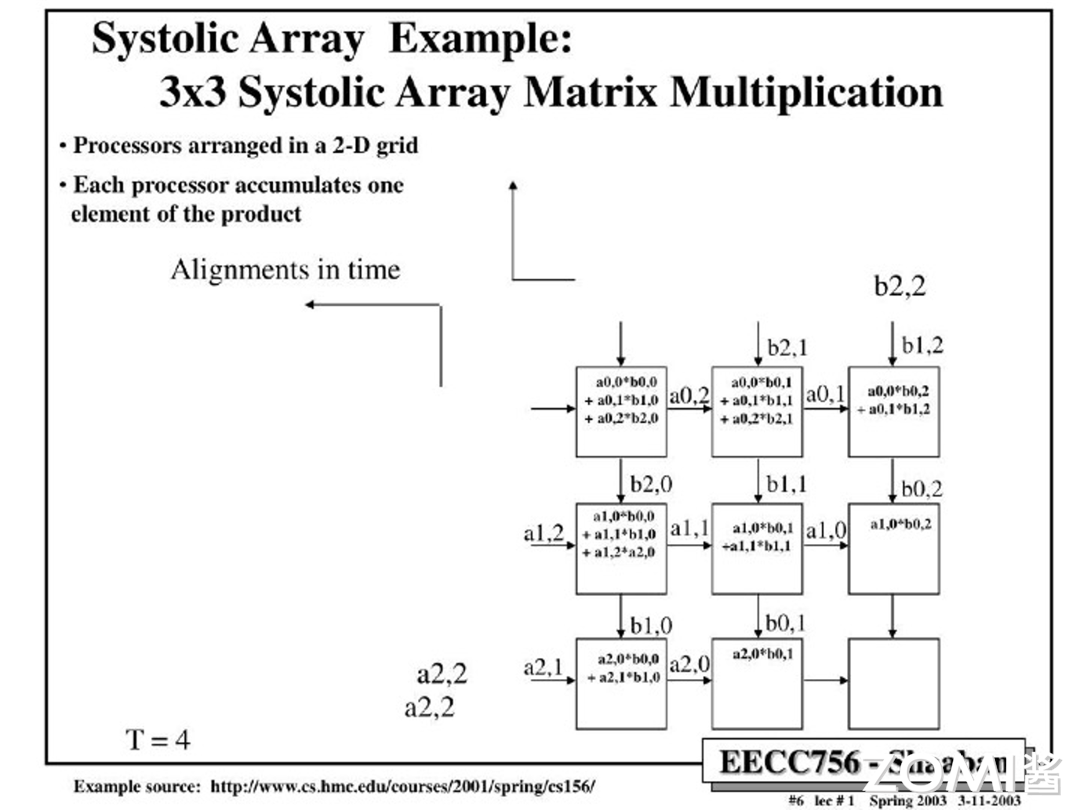
$T=5$:
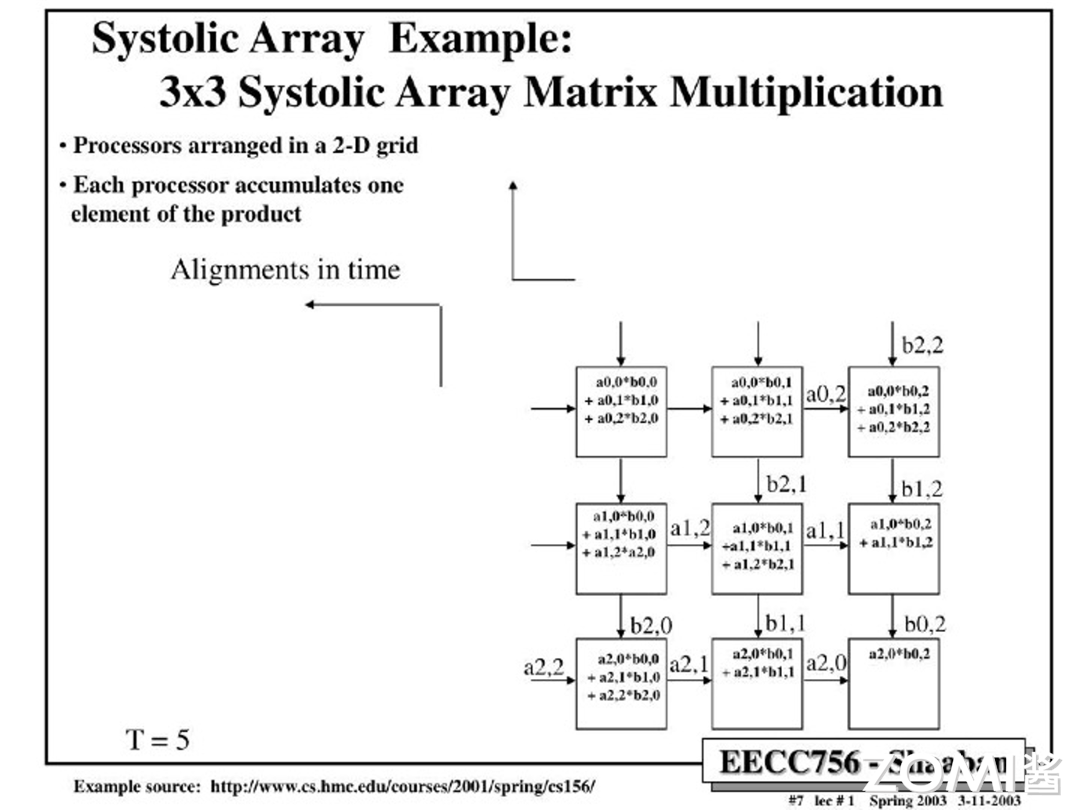
$T=6$:
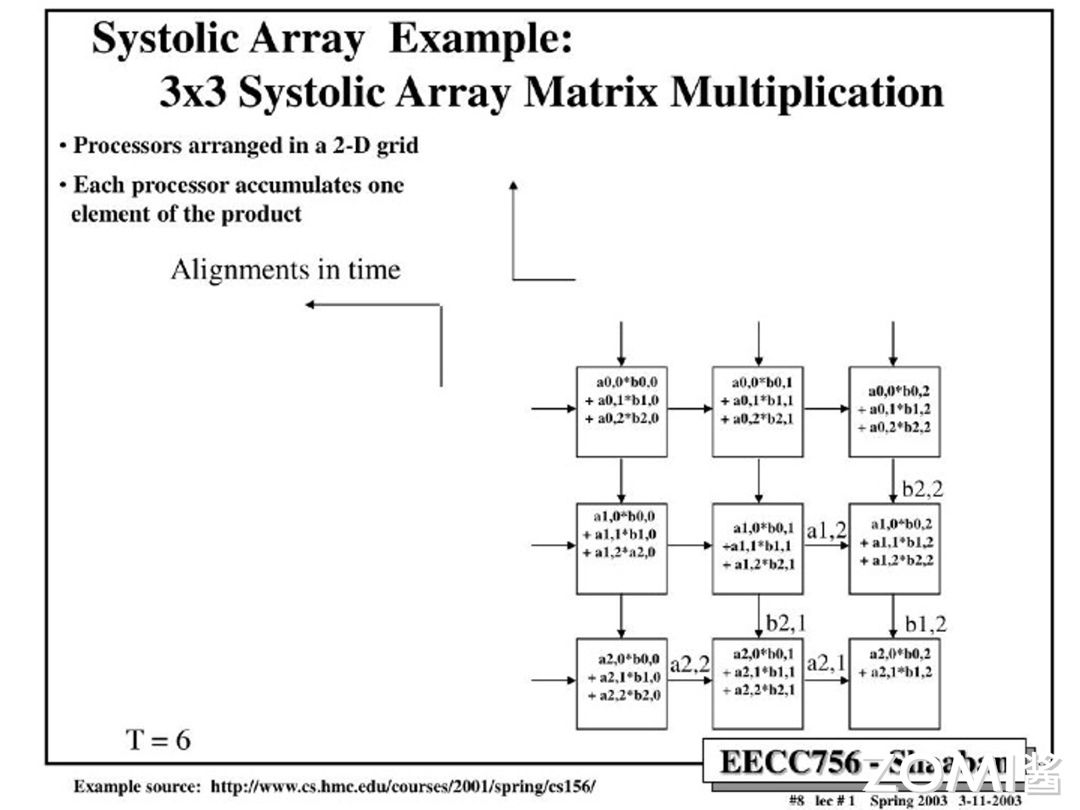
$T=7$:
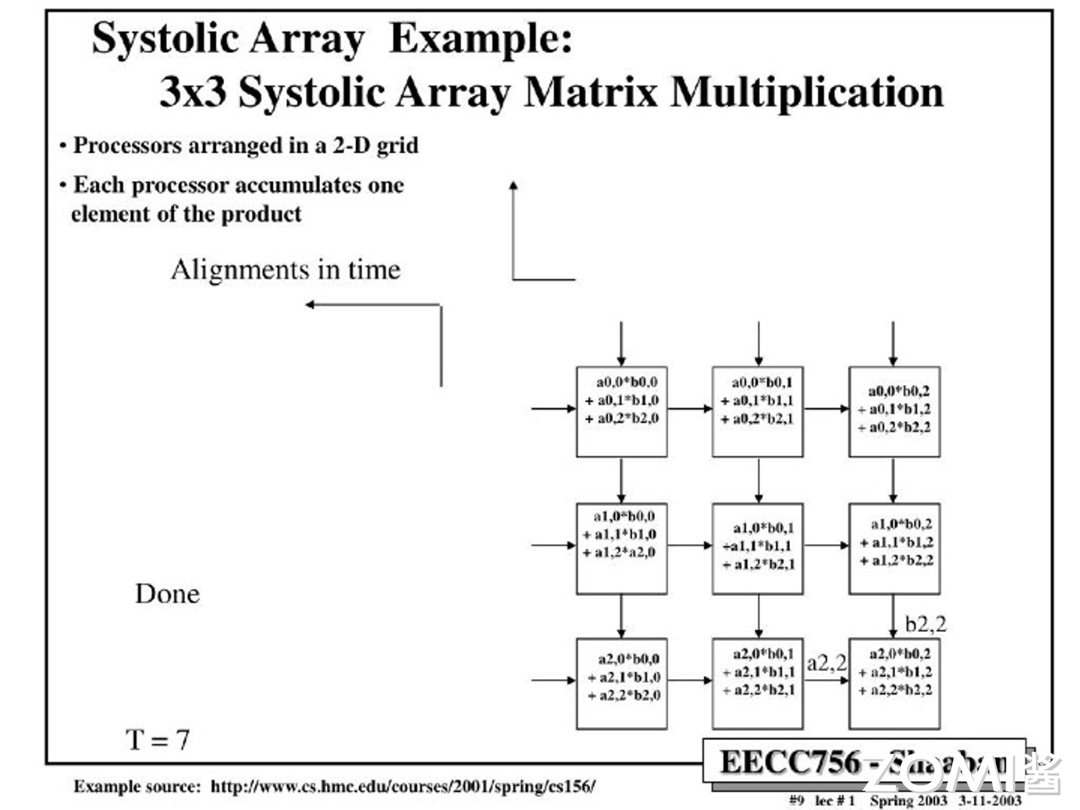
脉动阵列计算延迟
当我们讨论脉动阵列和 TPU 的计算延迟时,重要的是要明白如何有效地管理和优化这些延迟,以保持高效的计算流程。在 TPU 中,尤其是当数据需要通过一系列的计算单元进行传递时,每个单元的处理时间会对整体性能产生影响。
首先,TPU 的设计采用了流水线技术,这是一种典型的硬件加速技术,用于提高计算效率和吞吐量。在流水线操作中,不同的计算阶段被划分成多个小的步骤或级别,每个级别专注于完成特定的任务。TPU 的 CISC 使用了四级流水线来处理指令,其中上文介绍的 Matrix_Multiply,也就是数据在计算单元中被计算的指令,可能需要较长时间才能完成。为了不让这种计算延迟影响整体性能,TPU 利用指令重叠技术来隐藏延迟。也就是说,在一个计算指令还未完成前,已经开始准备或执行下一个计算任务,从而抵消掉计算的延迟。
脉动阵列小结
从数学和计算机科学的角度来看,脉动阵列是一种并行计算架构,它通过在阵列中的每个处理单元之间传递数据来实现高效的数据处理。那么 MXU 的本质上也就是一个由 $256 \times 256$ 个 PE 组成的二维网格,每个乘法器可以执行乘法和累加操作。在脉动阵列中,数据流是通过阵列的对角线方向进行的,这种流动方式类似于心脏的脉动,因此得名“脉动阵列”。
在脉动阵列中,矩阵 B 通常从上方加载,而矩阵 A 从左侧进入。每个处理单元负责计算矩阵 A 和 B 中对应元素的乘积,并将结果累加到其内部的累加器中。随着数据的流动,每个处理单元会将累加的结果传递给下一个处理单元,最终从阵列的下方输出一个最终的计算结果。
在实际应用中,脉动阵列的复杂性远超上述简化的描述。例如,在 CNN 的实现中,模型的权重会被预加载到每个计算单元中。当输入数据通过阵列时,每个处理单元会执行卷积操作,并将中间结果以对角波的形式通过阵列进行输出。这个过程涉及到数据的不断移动和累加计算,以实现高效的计算操作。
竞品对比
在硬件并行形态里面,TPU v1 使用了 SIMD 而 GPU 使用了 SIMT 的模式,即使 TPU v1 使用的 SIMD,但是由于 TPU 使用了我们上文中提到的多级流水隐藏时延的办法,减少缓存、乱序执行、多线程、多处理、预取等功能都有助于提高 TPU 的计算吞吐,使得 TPU 的运行更符合神经网络的计算逻辑。TPU 的目的是为了提高神经网络的计算吞吐,而 GPU 的技术确是通过多级缓存和计算核心去降低计算数据和计算的延迟,所以 TPU 的 GPU 的目的在本质上是有一定区别的。
谷歌的研究员通过屋顶线性能模型(Roofline Performance Model),基于三大类,每类两个的六个模型(MLP,LSTM,CNN)在 Haswell E5-2699 v3(CPU)、NVIDIA K80(GPU)和 TPU v1 上做了实验。实验结果表明,运行在 TPU v1 上的应用程序有着更低的时延,也就意味着对于用户有着更好的体验。
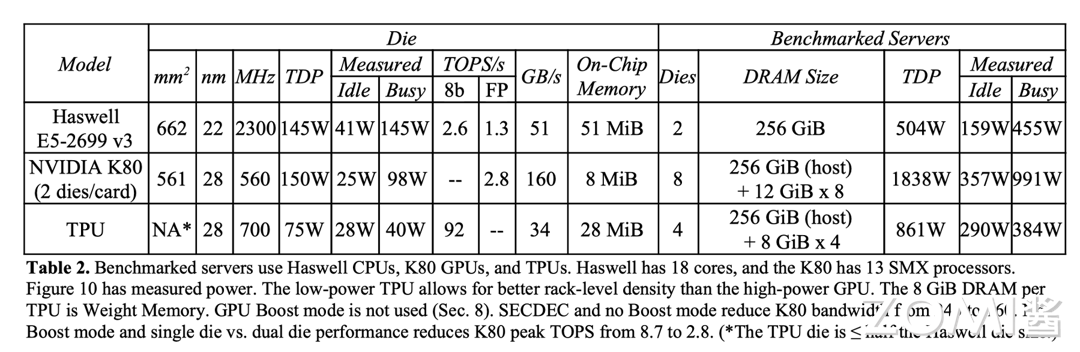
以下是这三个芯片每一个颗粒(Die)的对比,那么在这个环节,TPU 有着以下几个明显的优势:
-
计算性能优势:TPU v1 能够在每秒钟进行 $2 \times 65535 \times 7 \times 10^6 \approx 9.2 \times 10^{12} \rarr 92 ; TOPS$ 次计算。
-
片上缓存:TPU v1 选择做大片上缓存,从而大幅度减少片外访问消耗用来对抗 2015 年附近内存访问速度慢的情况。
-
量化:虽然模型的训练阶段使用了 FP32 的精度,TPU v1 在推理场景首次引入了 INT8 的量化,最大程度上利用了神经网络的鲁棒性。在大缓存和量化的帮助下,TPU 能够每次放入更大的 batch,从而加强神经网络的推理效率。
转载自:| https://www.cnblogs.com/ZOMI/articles/18557387 | header |
| ---------------------------------------------- | ------ |
| | |