-
定义与重要性
- 定义:数据计算是指对数据进行各种数学、逻辑和统计运算,以提取有价值的信息、发现模式、进行预测或支持决策的过程。它涵盖了从简单的算术运算到复杂的机器学习算法应用等广泛的操作。
- 重要性:
- 数据洞察与分析:通过计算可以揭示数据中的隐藏信息,如计算平均值、中位数来了解数据的集中趋势,或者通过计算方差、标准差来了解数据的离散程度。这些统计指标帮助分析师和决策者更好地理解数据的特征。
- 业务决策支持:在企业运营中,数据计算用于预测销售趋势、评估风险、计算成本效益等。例如,通过回归分析计算销售与广告投入之间的关系,为营销决策提供依据。
- 数据挖掘与机器学习:复杂的数据计算是数据挖掘和机器学习的核心。从数据预处理阶段的特征缩放、归一化,到模型训练阶段的梯度下降、反向传播等算法,数据计算无处不在。
-
数据计算的类型
- 批处理计算:
- 定义与特点:批处理计算是对大量数据进行一次性或周期性处理的计算方式。数据被收集并存储起来,然后在特定的时间点或时间段内进行集中处理。例如,企业每天晚上对当天的销售订单数据进行汇总统计,包括计算总销售额、订单数量、各产品的销售数量等。
- 应用场景与工具:适用于对时效性要求不高,但数据量较大的任务,如数据仓库中的ETL(抽取、转换、加载)过程、定期的报表生成等。常见的工具包括Apache Hadoop MapReduce,它将数据处理任务分解为Map(映射)和Reduce(归约)两个阶段,适合大规模数据的批处理;还有Apache Spark,它在批处理方面也有出色的性能,并且提供了更丰富的编程接口。
- 流处理计算:
- 定义与特点:流处理计算是对实时产生的数据流进行连续处理的计算方式。数据像水流一样源源不断地进入系统,计算引擎需要在数据到达的瞬间或极短时间内进行处理。例如,对物联网设备产生的实时数据(如温度、湿度传感器数据)进行监控和分析,一旦发现异常(如温度过高)立即触发警报。
- 应用场景与工具:应用于对实时性要求很高的场景,如金融交易监控、网络流量分析、工业自动化中的实时控制系统等。Apache Flink是一款流行的流处理框架,它能够高效地处理无序或乱序的数据流,并且支持事件时间处理,保证计算结果的准确性;Apache Kafka Streams是构建在Kafka消息队列之上的轻量级流处理库,方便与Kafka集成进行流处理。
- 交互式计算:
- 定义与特点:交互式计算允许用户与数据进行实时交互,快速得到计算结果。用户可以通过输入查询语句、参数调整等方式即时获取数据反馈。例如,数据分析师在数据探索阶段,通过交互式的SQL查询工具,快速查询不同维度的销售数据,如按地区、时间、产品类别等查看销售情况。
- 应用场景与工具:主要用于数据探索和分析场景,帮助用户快速理解数据。工具方面,一些商业智能(BI)软件(如Tableau、PowerBI)提供了交互式的可视化界面,用户可以通过简单的操作(如拖拽、筛选)进行数据计算和可视化展示;在编程环境中,Python的Jupyter Notebook也是一种流行的交互式计算工具,用户可以在其中编写代码片段并即时查看结果。
- 批处理计算:
-
数据计算的架构与技术
- 单机计算架构:
- 架构特点:在单机计算架构中,所有的数据计算任务都在一台计算机上完成。数据存储在本地磁盘或内存中,计算过程通过本地的CPU和内存资源进行。例如,使用个人电脑上的电子表格软件(如Excel)进行简单的数据计算,如求和、平均值计算等。
- 适用场景与限制:适用于小规模的数据计算任务,如个人或小型团队的简单数据分析。但这种架构在处理大规模数据或复杂计算任务时会受到单机资源(如CPU核心数、内存大小)的限制,计算速度和可扩展性较差。
- 分布式计算架构:
- 架构特点:分布式计算架构将数据和计算任务分布在多个节点(计算机)上进行。通过网络将这些节点连接起来,协同完成计算任务。例如,在Hadoop分布式计算环境中,数据被分割成块存储在多个数据节点上,计算任务(如MapReduce任务)会被分配到不同的计算节点上并行执行。
- 适用场景与优势:适用于大规模数据计算和处理,能够利用众多节点的资源来提高计算效率和可扩展性。可以处理海量的数据,如大数据分析、机器学习中的大规模模型训练等任务。同时,分布式计算架构还具有较好的容错性,部分节点故障不会导致整个系统崩溃。
- 云计算架构:
- 架构特点:云计算架构是一种基于互联网的计算模式,用户通过云服务提供商提供的计算资源(如虚拟机、容器、存储服务等)进行数据计算。云平台可以根据用户的需求动态分配资源,用户只需按照使用量付费。例如,企业可以将数据存储在云存储中,然后使用云平台提供的计算服务(如AWS Lambda、Google Cloud Functions)进行数据处理。
- 适用场景与优势:适用于各种规模的企业和不同类型的数据计算任务。对于中小企业来说,可以快速获取强大的计算资源,而无需投资大量的硬件设备。对于创业公司和创新项目,云计算架构提供了灵活的资源配置和低成本的试错机会。同时,云平台通常还提供了一系列的数据处理和分析工具,方便用户使用。
- 单机计算架构:
-
数据计算中的关键技术与算法
- 数据处理算法:
- 排序算法:如快速排序、归并排序等,用于对数据进行排序,方便后续的数据分析和查询。例如,在数据库查询中,对查询结果进行排序可以提高数据的可读性和可分析性。
- 聚合算法:包括求和、平均值、最大值、最小值等计算,用于汇总数据。这些算法在统计分析和报表生成中经常使用,如计算销售数据的总销售额、平均单价等。
- 关联算法:用于处理多个数据集之间的关联关系,如数据库中的表连接操作(如内连接、外连接)。在数据仓库和关系型数据库中,通过关联算法可以将不同表中的相关数据组合在一起,以便进行更全面的分析。
- 机器学习算法(数据挖掘部分):
- 分类算法:如决策树、支持向量机(SVM)、朴素贝叶斯等,用于将数据划分到不同的类别中。例如,在垃圾邮件过滤中,使用分类算法将邮件分为垃圾邮件和非垃圾邮件两类。
- 回归算法:包括线性回归、多项式回归等,用于建立变量之间的数学关系,进行预测分析。例如,通过回归算法预测房价与房屋面积、房龄等因素之间的关系。
- 聚类算法:如K - means聚类、层次聚类等,用于将数据集中的数据点划分为不同的簇,使得同一簇内的数据点具有较高的相似性,不同簇之间的数据点具有较高的差异性。例如,在客户细分中,使用聚类算法根据客户的购买行为、消费金额等特征将客户分为不同的群体。
- 数据处理算法:
数据计算的类型、数据计算的架构与技术、数据计算中的关键技术与算法
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/854328.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
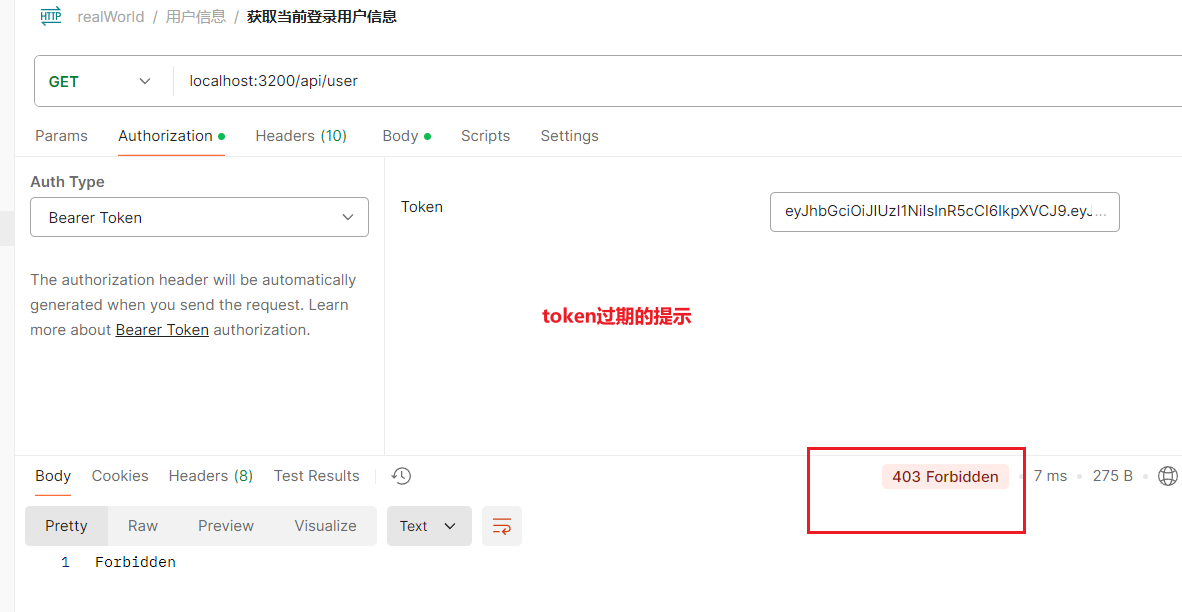
Express的使用笔记10 给登录接口添加返回token与其它接口进行token校验处理
按照常规,用户登录成功的时候是会返回一个token值,前端就可以将这个token存储到cookie中随后在其他接口使用的时候放置在Headers中进行传递。
实现这个功能,首先需要了解JWT Secret(密钥)与JWT(Token)。
JWT Secret (密钥):这是一个私有的字符串,仅在服务器端使用。
它…

ingsollrang英格索兰IC直流电动拧紧控制器维修
随着智能装配的概念逐渐在行业内推广,质量管理已成为实现智能装配过程中的一个重要环节,许多客户都有着数据记录、扭矩检测的需求,英格索兰的多种拧紧工具配合控制器,可以满足从基本拧紧到质量管理的一系列需求,真正实现高级装配。
一、ingsollrang英格索兰IC直流电动拧紧…
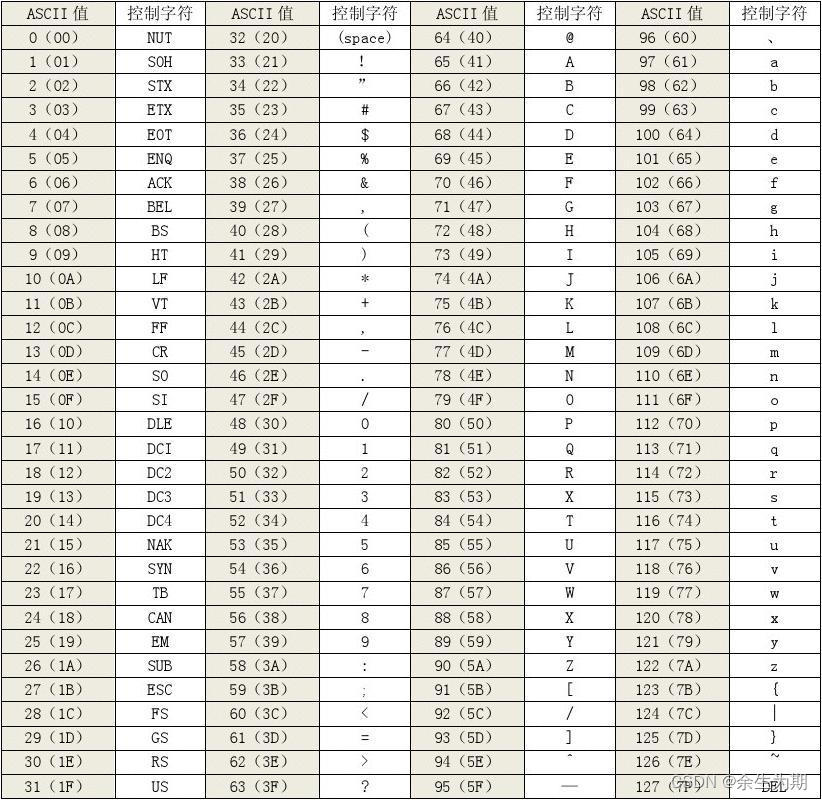
【笔记】一些简单、基础的东西
一些简单的东西存储大小bit:位,简写为 bbyte:字节,简写为 B;一个字节占 8 位。k:千(1000)K/Ki:千(1024)ASCII10:enter、32:space48:065:A97:a

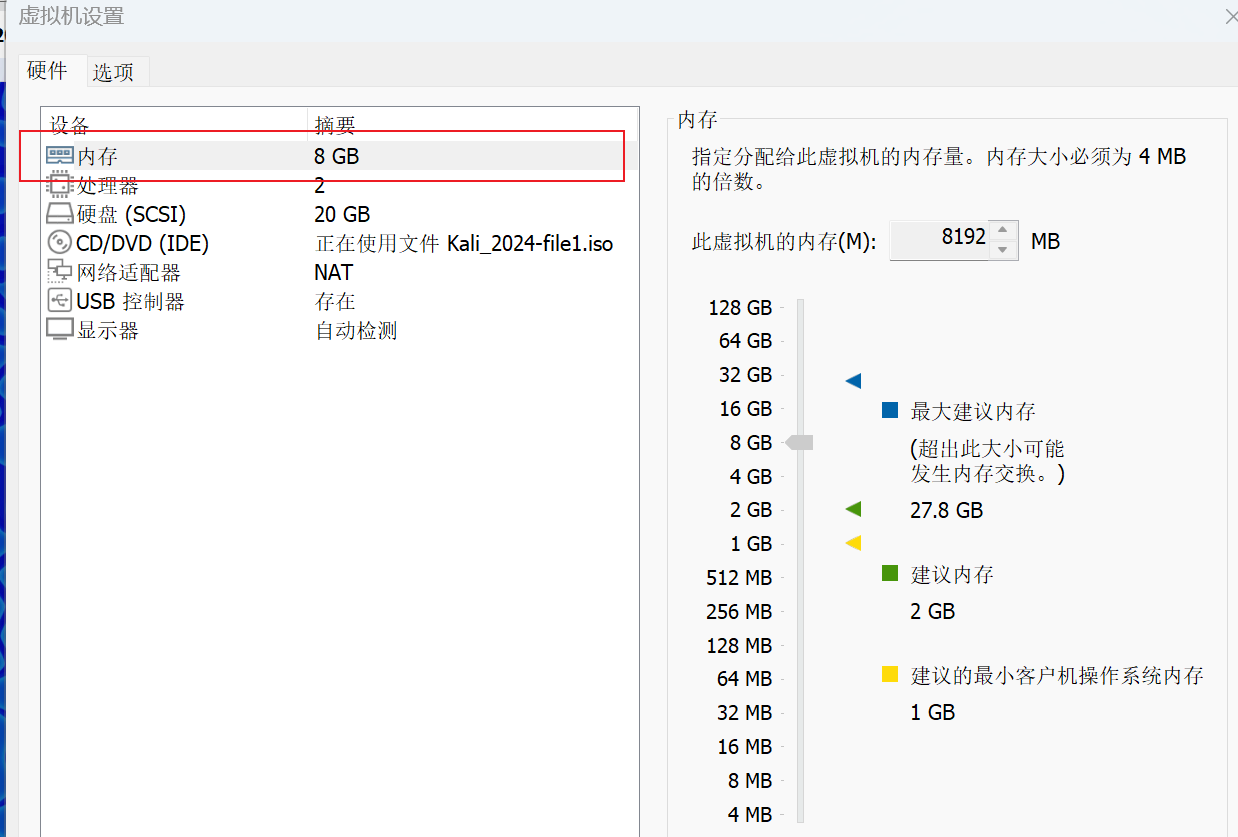
kali启动报“piix4_smbus 0000:00:07.3: SMBus Host controller not enabled”
问题:piix4_smbus 0000:00:07.3: SMBus Host controller not enabled 解决办法:增大内存

【实用指南】Zabbix服务器性能警告分析与解决方案:Zabbix server: Utilization of icmp pinger processes over
前言:在监控系统的日常运维中,Zabbix作为一个强大的开源监控工具,帮助我们实时监控网络和应用状态。然而,当Zabbix服务器性能出现警告时,如icmp pinger进程利用率过高,这可能会影响监控数据的准确性和及时性。本文将为您提供一个详细的分析和解决方案,帮助您快速定位问题…
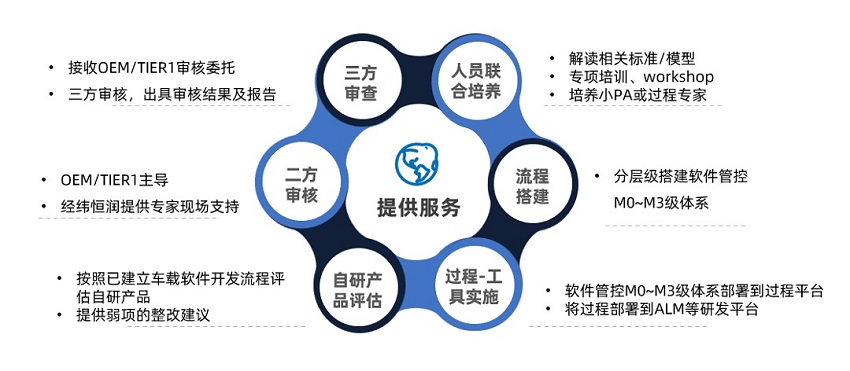
车企软件研发流程及质量把控解决方案
在“软件定义汽车”时代,车载软件的比重逐步提高,车载软件的研发流程决定着车载软件质量的稳定性和可控性。经纬恒润可面向OEM/TIER1结合多标准要求,如:ASPICE/CMMI/ISO26262/IATF16949质量体系,搭建、定义车载软件开发流程以及供方管控标准和流程。概述在“软件定义汽车”…
Springboot+Nacos项目
微服务
微服务(Microservices)是一种软件架构风格,他区别与单体架构,将拆分为多个小型的、独立的服务,每个服务都可以独立开发、部署和维护。这些服务通过轻量级的API进行通信。
Nacos简述
Nacos 用于发现、配置和管理微服务。nacos有2个核心功能,一个是注册中心,一个是…