- HDFS简介
- HDFS(Hadoop Distributed File System)是一个分布式文件系统,是Hadoop生态系统的核心组件之一。它被设计用来在廉价的硬件设备上存储大规模的数据,并且能够提供高容错性和高吞吐量的数据访问。
- 例如,在一个大型的互联网公司,每天会产生海量的用户行为数据,如浏览记录、购买记录等。这些数据的规模可能达到PB级别的大小,HDFS可以很好地存储和管理这些数据。
- HDFS的架构
- NameNode
- NameNode是HDFS的主节点,它管理着文件系统的命名空间(namespace)。命名空间包括了文件和目录的层次结构,就像一本书的目录一样,记录了每个文件的位置信息。
- 例如,当用户想要访问一个文件时,首先会向NameNode询问该文件的位置,NameNode会返回文件块(block)存储在哪些DataNode上的信息。NameNode还负责处理文件系统的命名空间操作,如创建、删除和重命名文件或目录等操作。
- DataNode
- DataNode是HDFS的从节点,它们负责实际的数据存储。数据在HDFS中是以数据块(block)的形式存储的,默认的数据块大小是128MB(这个大小可以配置)。
- 例如,一个1GB的文件会被分成8个数据块(假设数据块大小为128MB),这些数据块会被存储在不同的DataNode上。DataNode会定期向NameNode发送心跳(heartbeat)消息,报告自己的状态和存储的数据块信息,这样NameNode就能知道哪些DataNode是存活的,哪些数据块是可用的。
- Secondary NameNode
- Secondary NameNode并不是NameNode的备份,它主要的功能是定期合并NameNode的编辑日志(edit log)和镜像文件(fsimage)。
- 例如,NameNode在运行过程中会不断地记录文件系统的更改操作,这些操作记录在编辑日志中。镜像文件则是文件系统的一个快照。随着时间的推移,编辑日志会变得很大,这会影响NameNode的性能。Secondary NameNode会定期将编辑日志和镜像文件合并成一个新的镜像文件,这样可以减少编辑日志的大小,提高NameNode的性能。
- NameNode
- HDFS的工作原理
- 文件写入过程
- 当客户端(client)想要向HDFS写入一个文件时,首先会向NameNode请求上传文件。NameNode会根据DataNode的状态(如可用空间、网络带宽等)选择一些DataNode来存储文件块。
- 例如,假设要写入一个384MB的文件,在默认数据块大小为128MB的情况下,文件会被分成3个数据块。NameNode可能会选择DataNode1、DataNode2和DataNode3来存储这3个数据块。客户端会先将第一个数据块发送给DataNode1,DataNode1接收并存储这个数据块后,会将数据块复制一份发送给DataNode2(这是HDFS的数据冗余策略,默认是每个数据块有3个副本)。然后客户端再发送第二个数据块,以此类推,直到文件的所有数据块都被存储并复制完成。
- 文件读取过程
- 当客户端想要读取一个文件时,首先会向NameNode询问文件的位置信息。NameNode会返回存储文件块的DataNode列表。
- 例如,客户端想要读取之前写入的384MB文件,NameNode会返回存储该文件3个数据块的DataNode列表。客户端会选择距离自己较近或者网络带宽较好的DataNode来读取数据块,比如先从DataNode1读取第一个数据块,从DataNode2读取第二个数据块等,最后将这些数据块组合成完整的文件内容。
- 文件写入过程
- HDFS的优势
- 高容错性
- 由于数据块有多个副本,即使某个DataNode出现故障,数据仍然可以从其他副本所在的DataNode获取。例如,在一个包含10个DataNode的集群中,存储的数据块有3个副本,即使有3个DataNode同时出现故障,数据仍然可以正常访问。
- 可扩展性
- HDFS可以很容易地通过添加新的DataNode来扩展存储容量。当数据量增加时,只需要添加更多的硬件设备并将其配置为DataNode,就可以增加整个文件系统的存储容量。
- 适合大数据处理
- 它能够高效地处理大规模的数据,为数据密集型应用(如大数据分析、数据挖掘等)提供了良好的存储基础。例如,在进行大规模的数据分析时,Hadoop的Map - Reduce等计算框架可以直接从HDFS中读取数据进行计算。
- 高容错性
- HDFS的应用场景
- 数据仓库
- 用于存储企业的数据仓库数据,如销售数据、客户数据等。这些数据可以用于企业的决策分析,如市场趋势分析、客户行为分析等。
- 日志存储和分析
- 存储服务器日志、应用程序日志等大量的日志数据。这些日志数据可以用于故障排查、性能分析等。例如,在一个大型网站中,每天会产生大量的访问日志,HDFS可以存储这些日志,并通过相关的日志分析工具进行分析,了解用户的访问行为和网站的性能情况。
- 数据仓库
分布式文件系统HDFS
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/854341.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

Windows-清除电脑(主文件夹)中“最近使用的文件”(痕迹)
如何清除电脑(主文件夹)中 “最近使用的文件”(痕迹)? (1)在任务栏这里点击 “三个点” 的图表,然后选择 “选项”。 (2)点击 “隐私” 选项卡下的“清除”按钮。 然后点击 “刷新” 按钮,即可清除 “最近使用的文件” 。 (3)设置不记录 “最近使用的文件” 。
第…

OpenHarmony测试RS232/RS485串口方法,触觉智能SBC3528工控主板演示
为大家介绍在鸿蒙系统下,没有串口工具的情况下如何测试RS232/RS485,触觉智能SBC3528工控主板演示教大家介绍在OpenHarmony系统,没有串口工具的情况下如何测试RS232/RS485,使用触觉智能SBC3528工控主板演示,搭载了瑞芯微RK3568四核处理器,板载2路RS232+4路隔离RS485,集成…

天虎程序Phone APP下载设置定位失败怎么解决
天虎程序Phone的APP拨号软件怎么下载呢?首先用浏览器扫描二维码,点击下载,然后按照提示安装就可以,这个非常简单。下载后,点击软件界面按####加拨号连接蓝牙,蓝牙连接好后就可以正常使用了。请联系图片上电话或微心 2081003456 索取下载phone程序APP 定位失败更换APP即可…
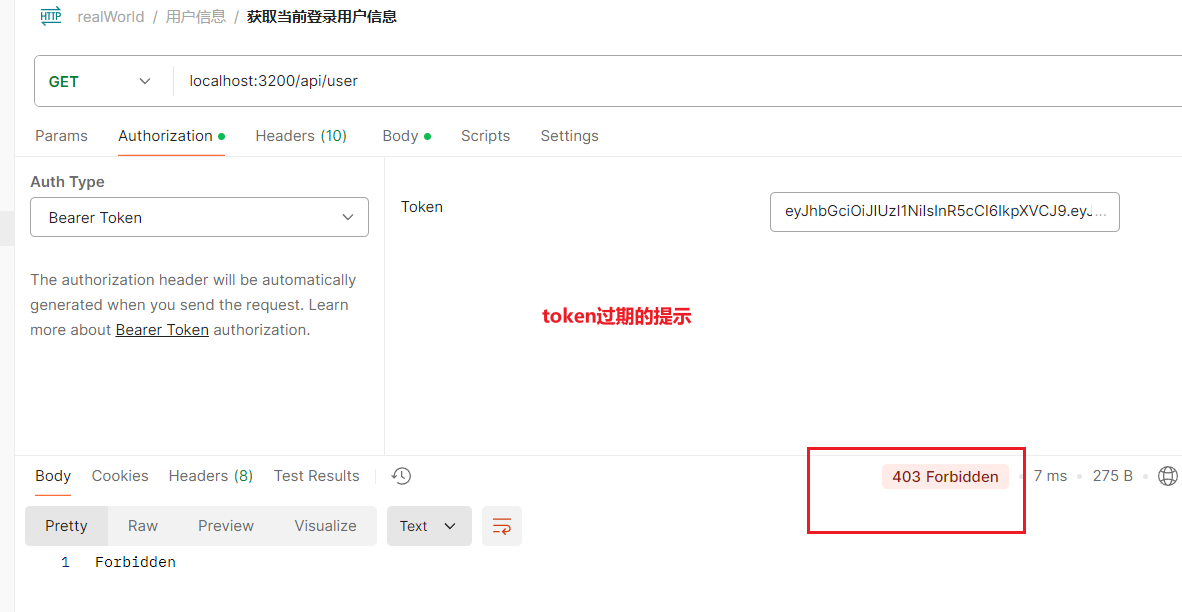
Express的使用笔记10 给登录接口添加返回token与其它接口进行token校验处理
按照常规,用户登录成功的时候是会返回一个token值,前端就可以将这个token存储到cookie中随后在其他接口使用的时候放置在Headers中进行传递。
实现这个功能,首先需要了解JWT Secret(密钥)与JWT(Token)。
JWT Secret (密钥):这是一个私有的字符串,仅在服务器端使用。
它…

ingsollrang英格索兰IC直流电动拧紧控制器维修
随着智能装配的概念逐渐在行业内推广,质量管理已成为实现智能装配过程中的一个重要环节,许多客户都有着数据记录、扭矩检测的需求,英格索兰的多种拧紧工具配合控制器,可以满足从基本拧紧到质量管理的一系列需求,真正实现高级装配。
一、ingsollrang英格索兰IC直流电动拧紧…
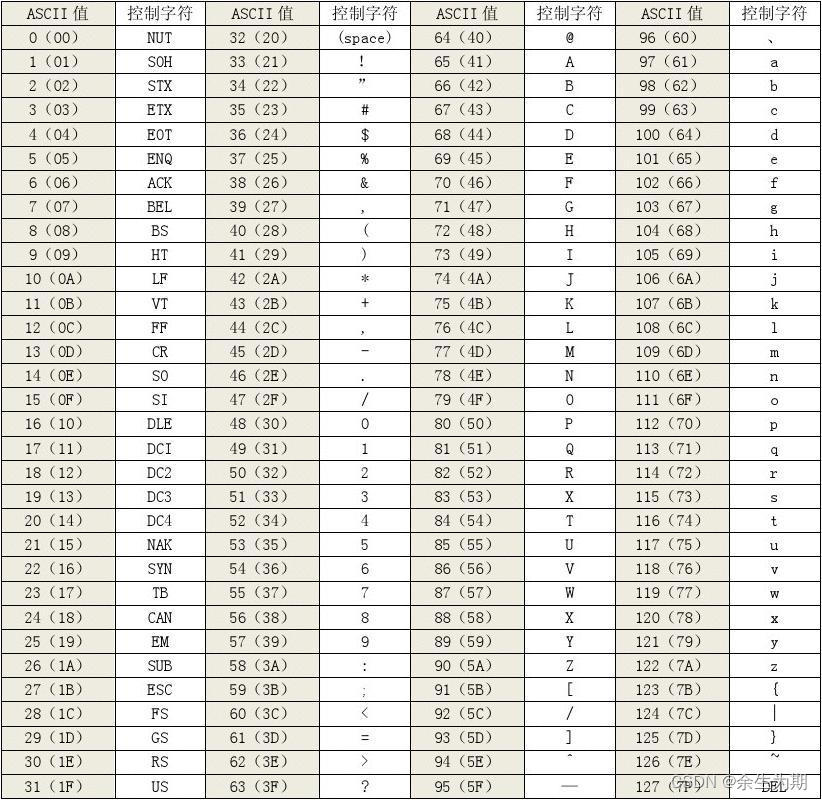
【笔记】一些简单、基础的东西
一些简单的东西存储大小bit:位,简写为 bbyte:字节,简写为 B;一个字节占 8 位。k:千(1000)K/Ki:千(1024)ASCII10:enter、32:space48:065:A97:a

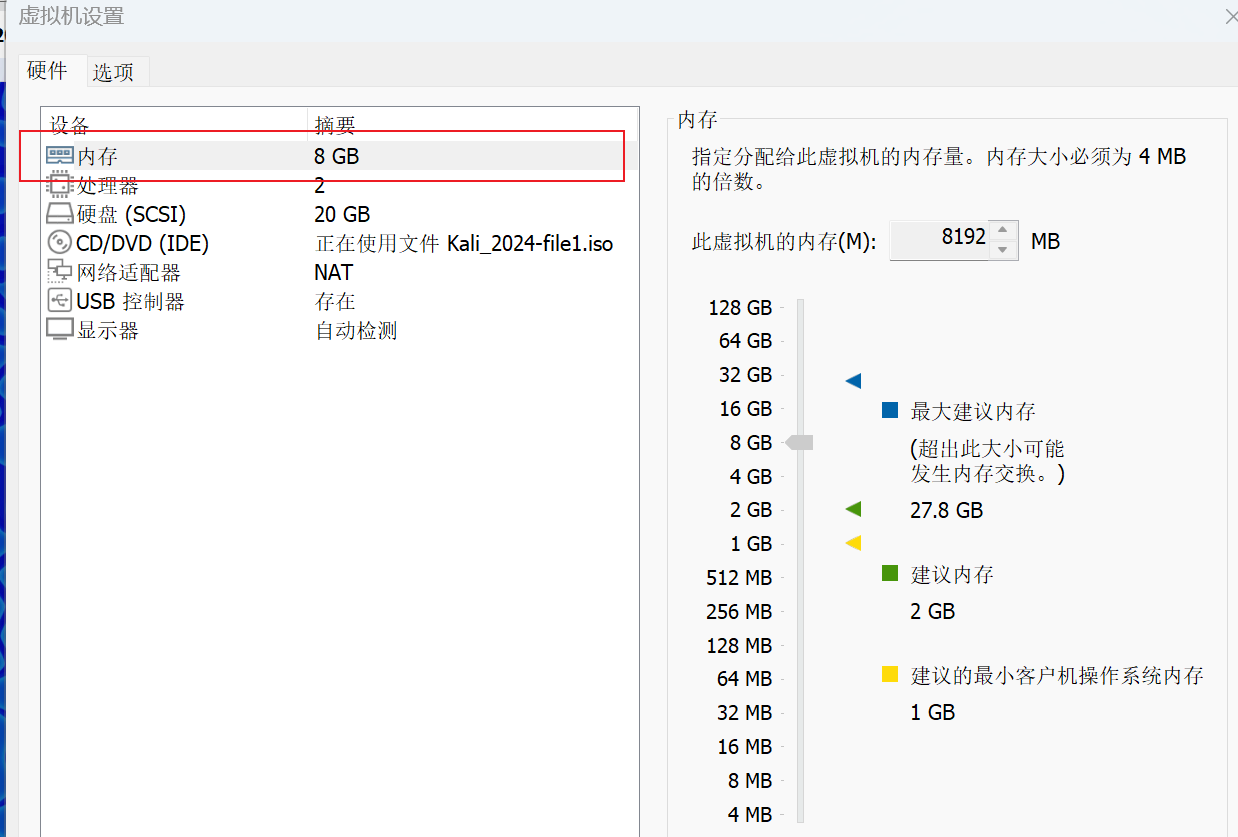
kali启动报“piix4_smbus 0000:00:07.3: SMBus Host controller not enabled”
问题:piix4_smbus 0000:00:07.3: SMBus Host controller not enabled 解决办法:增大内存