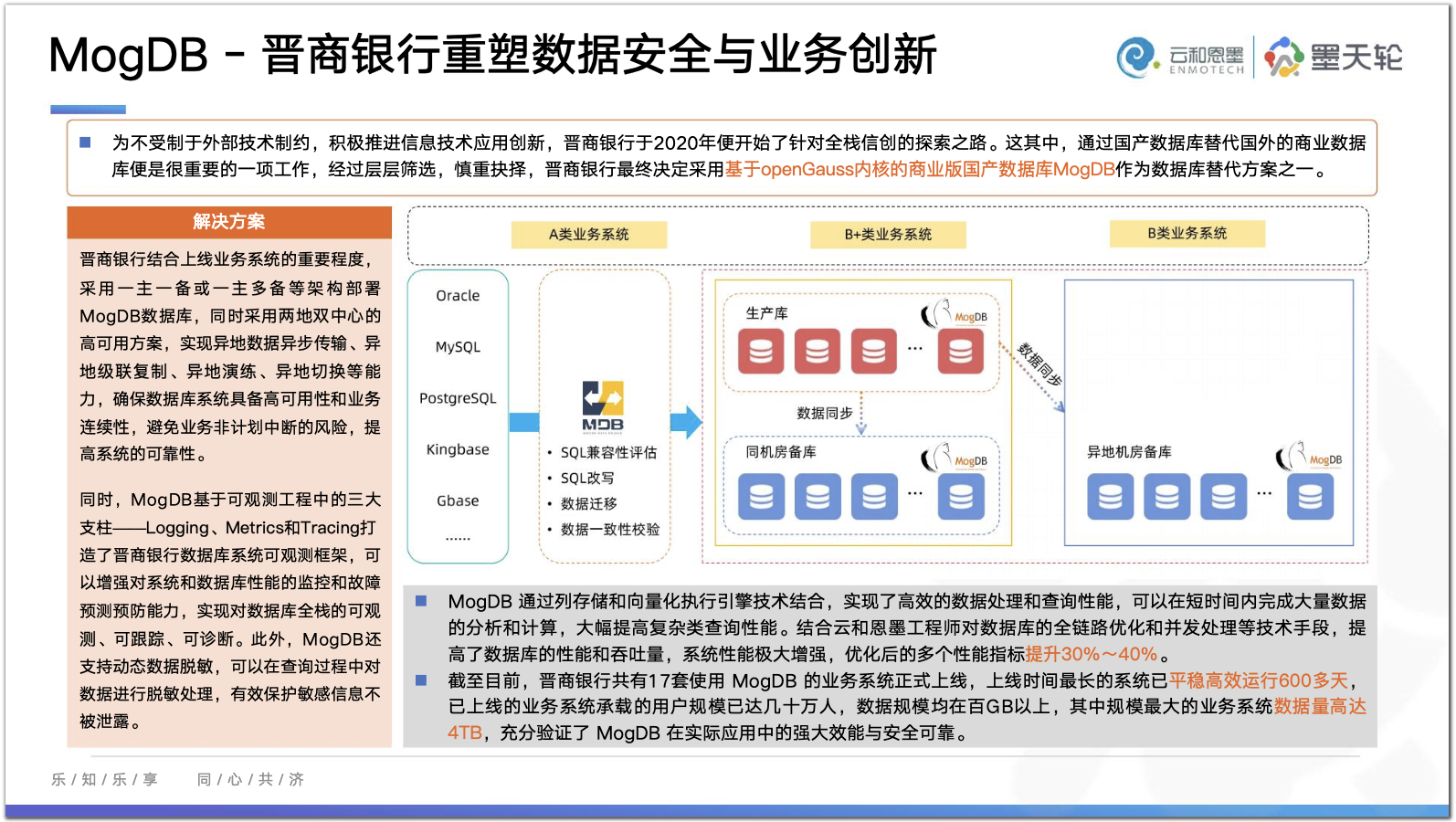
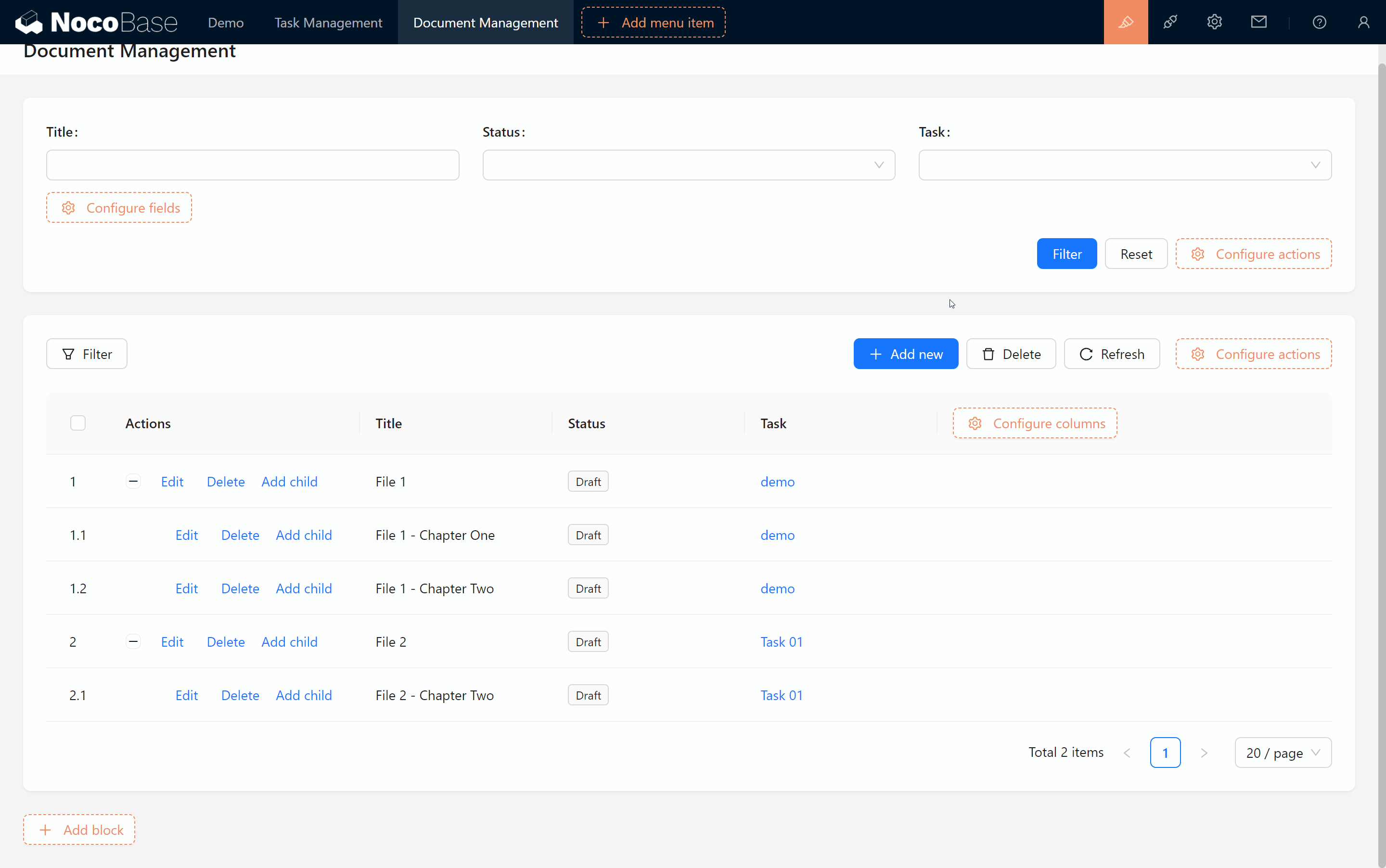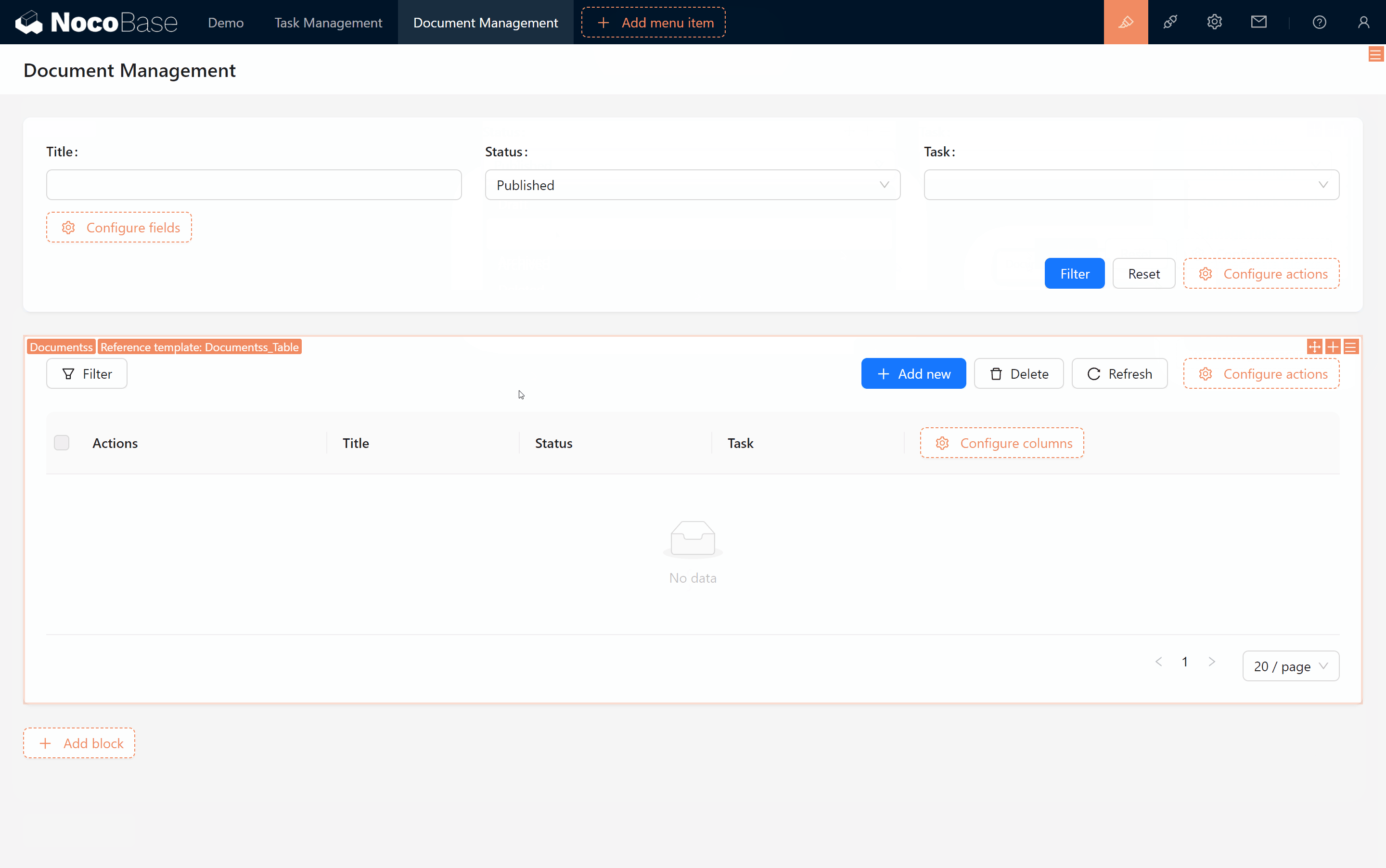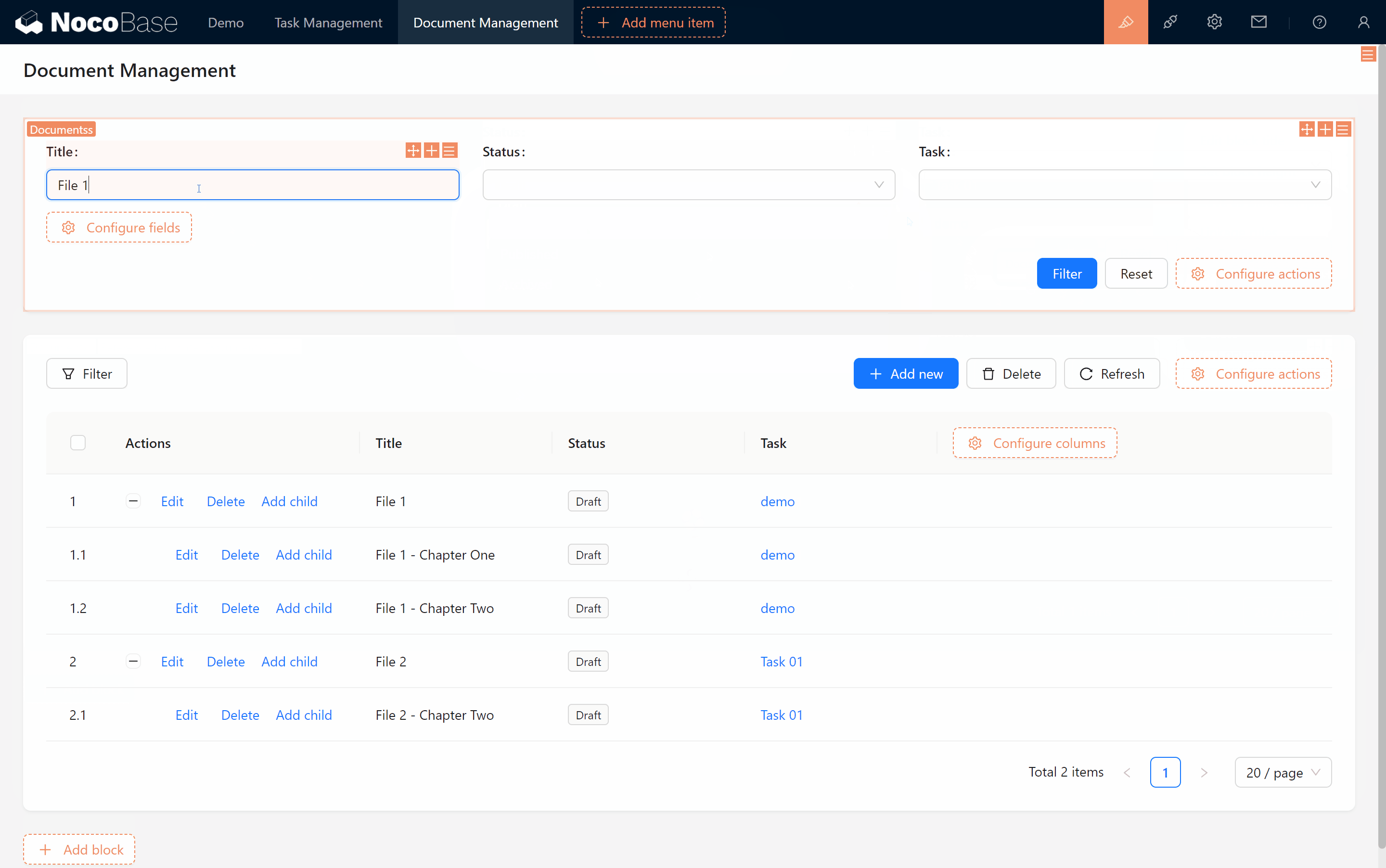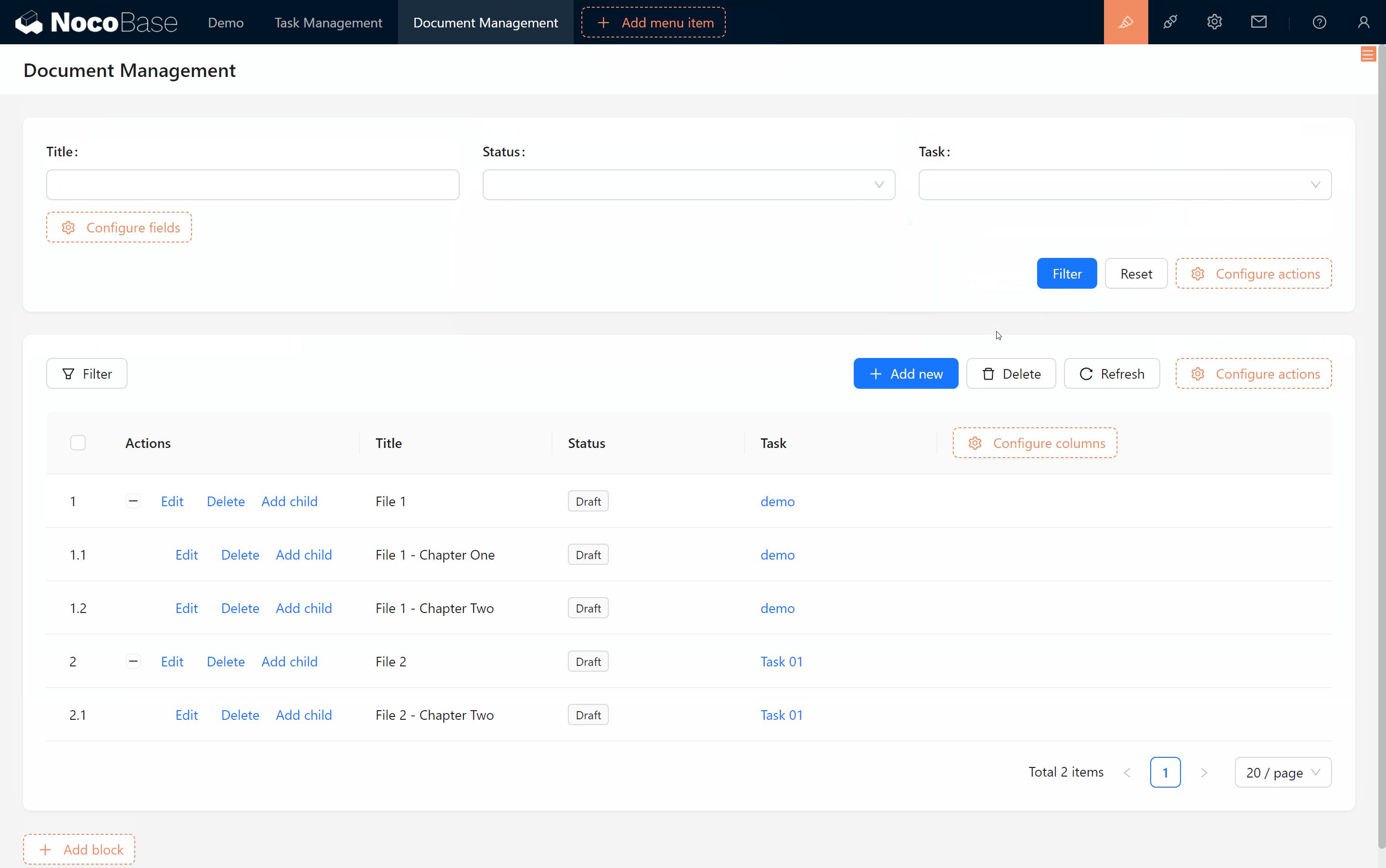
Leetcode28.找出字符串中第一个匹配项的下标
- 12.17.2024
问题描述:给你两个字符串haystack和needle,请你在haystack字符串中找出needle字符串的第一个匹配项的下标(下标从0开始)。如果needle不是haystack的一部分,则返回-1 。
1. 示例1:- 输入:haystack = "sadbutsad", needle = "sad"- 输出:0- 解释:"sad" 在下标 0 和 6 处匹配。第一个匹配项的下标是 0 ,所以返回 0 。
2. 示例2:- 输入:haystack = "leetcode", needle = "leeto"- 输出:-1- 解释:"leeto" 没有在 "leetcode" 中出现,所以返回 -1 。
提示:
1 <= haystack.length, needle.length <= 10000haystack和needle仅由小写英文字母组成
解法一:暴力(Brute Force)
最最容易的办法就是使用暴力的思想,时间复杂度为O(mn),思想十分简单,依次遍历比对即可,没什么好说的,比较简单,C++代码如下。
class Solution {
public:int strStr(string haystack, string needle) {for(int i = 0; i < haystack.size(); i++){bool match = true;for(int j = 0; j < needle.size(); j++){if(haystack[i + j] != needle[j]){match = false;break;}}if(match){return i;}}return -1;}
};
解法二:KMP算法
KMP算法的简要介绍
KMP算法是由Donald Knuth、Vaughan Pratt和James H.Morris独立发明的,并于1977年首次发表。KMP主要的特点是它避免了当模式串(即我们要查找的子串)和文本串(即被搜索的字符串)不匹配时对文本串的回溯,从而提高了效率。
KMP算法的核心思想
KMP算法通过先对模式串进行处理,构建一个前缀表,这个表格用于指示当模式串和文本串不匹配时,应该从模式串的哪个位置继续,而不是简单的把整个模式串从头开始重新进行比较,大大提高了效率。
NEXT数组(前缀表)的求解办法
-
什么是前缀表?
-
答:前缀表是记录下标i之前(包括i)的字符串中,相同的前后缀长度的大小。
-
为啥要用前缀表?
-
答:匹配失败的位置是在后缀子串的后面,那么我们找到和其相同的前缀后面重新匹配就可以了。
-
如何计算前缀表?
-
答:
- 首先初始化
next[0]为0 - 然后从模式串的第二个字符开始,看当前字符是否匹配前一个字符
- 如果匹配,则前缀长度
length加一,令next[i]为length,然后继续匹配下一个;如果不匹配,则更新length为之前的next值,或者如果前缀长度为0,直接令当前的next为0,然后移动到下一个字符比较即可
- 首先初始化
KMP的主函数
- 先使用辅助函数计算出next数组
- 遍历文本串
- 如果匹配,则文本串和模式串的指针都加一,继续
- 如果不匹配,则看模式串的指针
j是否为0,如果是0,则直接让文本串的i加一即可,如果不是,则直接调用next数组,从给定位置开始即可。
代码部分
// 计算部分匹配表(next数组)
void computeLPSArray(const std::string& pattern, std::vector<int>& lps) {int length = 0; // 前缀长度,初始化为0int i = 1; // 从模式字符串的第二个字符开始lps[0] = 0; // lps[0] 总是 0,因为单个字符没有前缀// 计算 lps[i] for i = 1 to M-1while (i < pattern.size()) {if (pattern[i] == pattern[length]) { // 如果当前字符匹配前缀字符length++; // 前缀长度增加lps[i] = length; // 记录 lps 值i++; // 移动到下一个字符} else { // 如果当前字符不匹配前缀字符if (length != 0) { // 如果前缀长度不为0length = lps[length - 1]; // 更新前缀长度为之前的 lps 值} else { // 如果前缀长度为0lps[i] = 0; // lps 值为0i++; // 移动到下一个字符}}}
}
// KMP算法搜索主函数
void KMPSearch(const std::string& text, const std::string& pattern) {int M = pattern.size();int N = text.size();// 创建 lps 数组,保存部分匹配表std::vector<int> lps(M);// 计算部分匹配表computeLPSArray(pattern, lps);int i = 0; // text 的索引int j = 0; // pattern 的索引while (i < N) {if (pattern[j] == text[i]) {i++;j++;}
cijif (j == M) {std::cout << "找到匹配位置: " << i - j << std::endl;j = lps[j - 1];} else if (i < N && pattern[j] != text[i]) {if (j != 0) {j = lps[j - 1];} else {i++;}}}
}