- 理解执行计划的重要性
- 执行计划是数据库管理系统(DBMS)在执行SQL语句时所采取的步骤和方法的描述。它展示了数据库如何访问表、使用索引,以及以何种顺序连接表等信息。通过分析执行计划,可以找出SQL语句执行效率低下的原因,如全表扫描、不合适的索引使用等,从而有针对性地进行优化。
- 获取执行计划
- 不同数据库的获取方式:
- MySQL:可以使用
EXPLAIN关键字。例如,对于查询语句SELECT * FROM users WHERE age > 30;,在MySQL中可以通过EXPLAIN SELECT * FROM users WHERE age > 30;来获取执行计划。执行计划结果会显示诸如id(查询的标识符)、select_type(查询类型,如SIMPLE、SUBQUERY等)、table(涉及的表)、type(访问类型,如ALL表示全表扫描,ref表示通过索引查找等)、possible_keys(可能使用的索引)、key(实际使用的索引)、key_len(索引长度)、ref(连接时使用的列或常量)、rows(预估要扫描的行数)和Extra(额外信息,如Using where表示使用了WHERE条件过滤)等信息。 - Oracle:可以使用
EXPLAIN PLAN FOR语句来获取执行计划。例如,EXPLAIN PLAN FOR SELECT * FROM employees WHERE salary > 5000;。然后通过查询PLAN_TABLE视图(如SELECT * FROM TABLE(dbms_xplan.display);)来查看详细的执行计划。Oracle的执行计划包含操作(如TABLE ACCESS、INDEX RANGE SCAN等)、对象所有者、对象名称和操作的谓词等信息。 - SQL Server:可以使用
SET SHOWPLAN_ALL ON或SET SHOWPLAN_TEXT ON来显示执行计划。例如,SET SHOWPLAN_ALL ON; SELECT * FROM customers WHERE customer_id > 100; SET SHOWPLAN_ALL OFF;。执行计划会展示物理操作(如Clustered Index Scan、Nested Loops等)、逻辑操作(如Select)、估计的行数、估计的I/O开销等信息。
- MySQL:可以使用
- 不同数据库的获取方式:
- 分析执行计划中的关键元素
- 访问类型(type):
- 全表扫描(ALL):这是最基本的访问方式,当没有合适的索引或者查询条件无法有效利用索引时,数据库会扫描整张表。例如,在一个没有索引的
users表上执行SELECT * FROM users WHERE name LIKE '%abc%';通常会导致全表扫描。全表扫描会随着表数据量的增大而性能急剧下降,因为它需要读取表中的每一行数据。 - 索引扫描(index scan):数据库会按照索引的顺序扫描索引中的条目。如果只需要索引中的部分列,这种扫描方式可以避免访问表数据,提高性能。例如,有一个索引包含
users表中的age和id列,执行SELECT age FROM users WHERE age > 30;可能会进行索引扫描。 - 索引唯一扫描(index unique scan):当查询条件可以唯一确定索引中的一行时,会使用索引唯一扫描。例如,在
users表的user_id(主键)列上有索引,执行SELECT * FROM users WHERE user_id = 123;会进行索引唯一扫描,这种扫描方式效率很高。
- 全表扫描(ALL):这是最基本的访问方式,当没有合适的索引或者查询条件无法有效利用索引时,数据库会扫描整张表。例如,在一个没有索引的
- 预估行数(rows):
- 数据库会根据统计信息预估执行操作时要扫描的行数。如果预估行数和实际情况相差很大,可能会导致查询计划选择不合适的执行策略。例如,统计信息过时,可能会使数据库认为某个条件过滤后的数据量很大,从而选择全表扫描,而实际上如果统计信息准确,使用索引扫描会更高效。
- 实际使用的索引(key):
- 查看是否使用了预期的索引。如果没有使用期望的索引,可能是因为索引不适合查询条件,或者数据库认为使用索引的成本高于全表扫描。例如,在一个复合索引(如
(column1, column2))上,如果查询条件只涉及column2,数据库可能不会使用这个复合索引。
- 查看是否使用了预期的索引。如果没有使用期望的索引,可能是因为索引不适合查询条件,或者数据库认为使用索引的成本高于全表扫描。例如,在一个复合索引(如
- 额外信息(Extra):
- 如
Using filesort表示需要进行额外的排序操作。这通常发生在没有按照索引顺序获取数据,但查询中有ORDER BY子句的情况。排序操作可能会消耗大量的资源,尤其是在处理大数据量时。Using temporary表示需要使用临时表,这通常是因为查询中的分组(GROUP BY)或排序操作无法在内存中完成,需要借助临时表来实现,这也会影响性能。
- 如
- 访问类型(type):
- 基于执行计划进行优化
- 添加或调整索引:
- 如果发现有全表扫描,可以考虑为经常用于查询条件的列添加索引。例如,对于经常按
product_name查询产品信息的products表,添加product_name列的索引可以提高查询效率。同时,对于复合索引,要注意索引列的顺序,将选择性高(不同值的数量占比高)的列放在前面。
- 如果发现有全表扫描,可以考虑为经常用于查询条件的列添加索引。例如,对于经常按
- 优化查询条件和语句结构:
- 避免在查询条件中使用函数操作列,因为这会导致索引失效。例如,将
SELECT * FROM users WHERE UPPER(name) = 'ABC';修改为SELECT * FROM users WHERE name = 'ABC';(假设数据库存储的name列已经是大写形式)。如果有子查询,可以考虑将子查询转换为连接操作,以减少嵌套查询带来的性能开销。
- 避免在查询条件中使用函数操作列,因为这会导致索引失效。例如,将
- 更新统计信息:
- 定期更新数据库的统计信息,使数据库能够更准确地预估执行计划中的行数等信息。不同数据库有不同的更新统计信息的方式。在MySQL中,可以使用
ANALYZE TABLE语句来更新表的统计信息,如ANALYZE TABLE users;。在Oracle中,可以使用DBMS_STATS.GATHER_TABLE_STATS过程来收集表的统计信息,如DBMS_STATS.GATHER_TABLE_STATS('schema_name', 'table_name');。
- 定期更新数据库的统计信息,使数据库能够更准确地预估执行计划中的行数等信息。不同数据库有不同的更新统计信息的方式。在MySQL中,可以使用
- 添加或调整索引:
如何分析和优化SQL语句的执行计划?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/854713.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

智改数转,物联网创业者有哪些商业机会?
《智改数转,物联网创业者有哪些商业机会》
在当前的数字化转型浪潮中,“智改数转”(智能化改造和数字化转型)已成为企业发展的新趋势。物联网(IoT)作为这一转型的核心技术之一,为创业者提供了丰富的商业机会。以下是物联网创业者可以把握的几个关键商业机会:
1. 设备制…
中小团队必备工具:如何用协同管理软件提高效率
一、中小团队面临的工作效率挑战
中小团队通常面临以下几个主要的工作效率问题:
1.1 资源有限,工作繁重
与大型企业相比,中小团队往往资源有限,人员紧张,团队成员往往需要身兼数职,处理多种任务。这种情况下,如何有效分配工作、确保每项任务顺利推进,就成为了管理的关键…
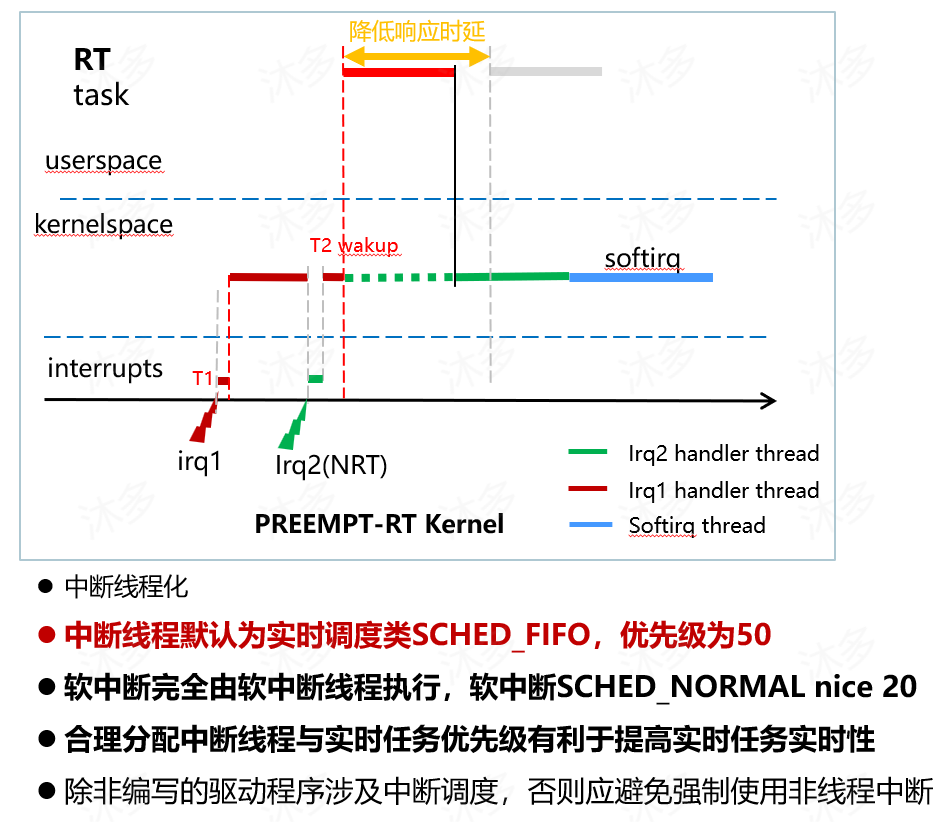
【原创】PREEMPT-RT中断线程化原理与中断线程优先级设置
本文介绍实时linux方案PREEMPT-RT提升系统实时性的机制之一--中断线程化,以及中断线程优先级如何配置,希望能对你有所帮助。PREEMPT-RT中断线程化与中断线程优先级设置
目录PREEMPT-RT中断线程化与中断线程优先级设置一、什么是中断线程化1. 普通Linux中断处理2. 实时性的不足…

NPM,可视化的Nginx管理工具
NPM,可视化的Nginx管理工具
前言
NPM,全称:Nginx Proxy Manager,是一款可视化的Nginx的管理工具。众所周知,Nginx的配置文件对于新手尤其是我这样的小白,还是很难上手配置的。虽然说现在可以使用AI,大大降低了理解,配置难度,但是可视化的配置仍然具有很大的优势,极大的…

汽车软件DevOps解决方案
经纬恒润汽车软件DevOps解决方案是专为现代汽车行业设计的一套集成化需求、开发、测试、部署、OTA与监控,旨在加速软件开发流程,提高软件质量和安全性,同时确保整个生命周期的高效性和灵活性。 经纬恒润汽车软件DevOps解决方案是专为现代汽车行业设计的一套集成化需求…

idea构建Build Project项目时一直卡在解析阶段解决办法
可能是内存不足,修改以下三个地方
1、help->Edit Custom VM Options-Xmx4096m
2、file->settings->Build,Execution,Deployment->Build Tools->Maven->Importing的VM options for importer写入参数-Xmx4096m3、file->settings->Build,Execution,Deplo…

PbootCMS 网站打开提示“No input file specified.”,如何解决?
当你在访问 PbootCMS 网站时,如果遇到“No input file specified.”的错误提示,这通常是由于服务器配置或文件缺失引起的问题。以下是一些常见的解决方法和步骤:检查根目录下的 user.ini 文件:这个问题的一个常见原因是根目录中存在 user.ini 文件。这个文件通常是服务器为…
在PbootCMS中如何优化图片的SEO属性?
在PbootCMS中优化图片的SEO属性对于提高网站的搜索引擎排名和用户体验至关重要。以下是一些具体的优化方法,帮助你更好地管理图片的alt和title属性:手动编辑图片描述:在PbootCMS后台,上传图片后,可以通过编辑器手动添加或修改图片的alt和title属性。
例如,当你插入图片时…
PbootCMS模板上传栏目缩略图时,图片宽度自动变成1000像素,如何解决?
在使用PbootCMS模板时,如果你发现上传的栏目缩略图在保存后自动变成了1000像素的宽度,这通常是由于系统配置中的缩略图最大宽度设置所致。你可以通过修改配置文件来解决这个问题。以下是详细的步骤和实现方法:理解问题原因:PbootCMS在上传图片时会根据配置文件中的设置自动…

Markdown study
Markdown 学习
组成
标题(#) (##) (###)
引用一切有为法,如梦幻泡影。如露亦如电,应做如是观(>)
分割线(***)(---)
字体hello world
hello world
hello world
图片()超链接预科02:Markdown语法详解_哔哩哔哩_bilibili
列表Ba
b
c图表代码
Z-BlogPHP遇到“error-5 非法访问”错误时,应该如何解决?
当您在使用 Z-BlogPHP 时遇到“error-5 非法访问”错误,通常是因为您尝试访问的资源或操作超出了您的权限范围,或者访问方式不符合系统的要求。以下是一些解决此问题的方法:检查用户权限:确认您当前使用的账户是否具有访问该资源或执行该操作的权限。某些页面或功能可能仅对…
Z-BlogPHP 如何选择合适的版本以适应不同的服务器环境?
Z-BlogPHP 提供了丰富的可定制性和灵活性,支持多种服务器环境和数据库格式。选择合适的版本对于确保系统的稳定性和性能至关重要。以下是选择合适 Z-BlogPHP 版本的方法和步骤:了解服务器环境:操作系统:确定您的服务器操作系统是 Windows 还是 Linux。大多数情况下,Linux …