我们很高兴迎来 Google 全新的视觉语言模型 PaliGemma 2,这是 PaliGemma 的一个新版本。与其前代产品一样,PaliGemma 2 使用强大的 SigLIP 进行视觉处理,但在文本解码部分升级到了最新的 Gemma 2。
模型规模和输入分辨率
PaliGemma 2 提供了新的预训练模型,参数规模包括 3B 、 10B 和 28B。所有模型均支持以下多种输入分辨率:
- 224x224
- 448x448
- 896x896
这种多样化的组合为不同的使用场景提供了极大的灵活性,使实践者能够根据质量和效率需求之间的平衡进行选择。与之相比,上一代 PaliGemma 仅提供 3B 版本。
预训练和微调能力
这些预训练模型被设计为更容易适配下游任务。首个 PaliGemma 模型因其广泛适配性被社区用于多种任务。本次迭代引入了更高质量的预训练模型和更多选择,进一步增强了灵活性。
DOCQI 数据集示例
Google 此次发布了一些基于 DOCCI 数据集的微调模型,展现了长篇、细致和富有表现力的图像描述能力。这些微调模型提供 3B 和 10B 两个版本,支持输入分辨率 448x448。
此次发布包含了所有开放的模型仓库、Transformers 框架的集成、微调脚本,以及我们基于 VQAv2 数据集 微调的视觉问答模型演示。这些资源为用户提供了全面的工具支持,助力探索和开发更多创新应用。
资源链接
本次发布包括开源模型库、transformers 集成、微调脚本以及视觉问答演示。以下是相关资源链接:
- 发布合集
- 微调脚本
- 微调模型演示 Demo
- 技术报告
PaliGemma 2 介绍
PaliGemma 2 是 PaliGemma 视觉语言模型 的一个新迭代,由 Google 于五月发布。
PaliGemma 2 将强大的 SigLIP 图像编码器与 Gemma 2 语言模型连接起来。
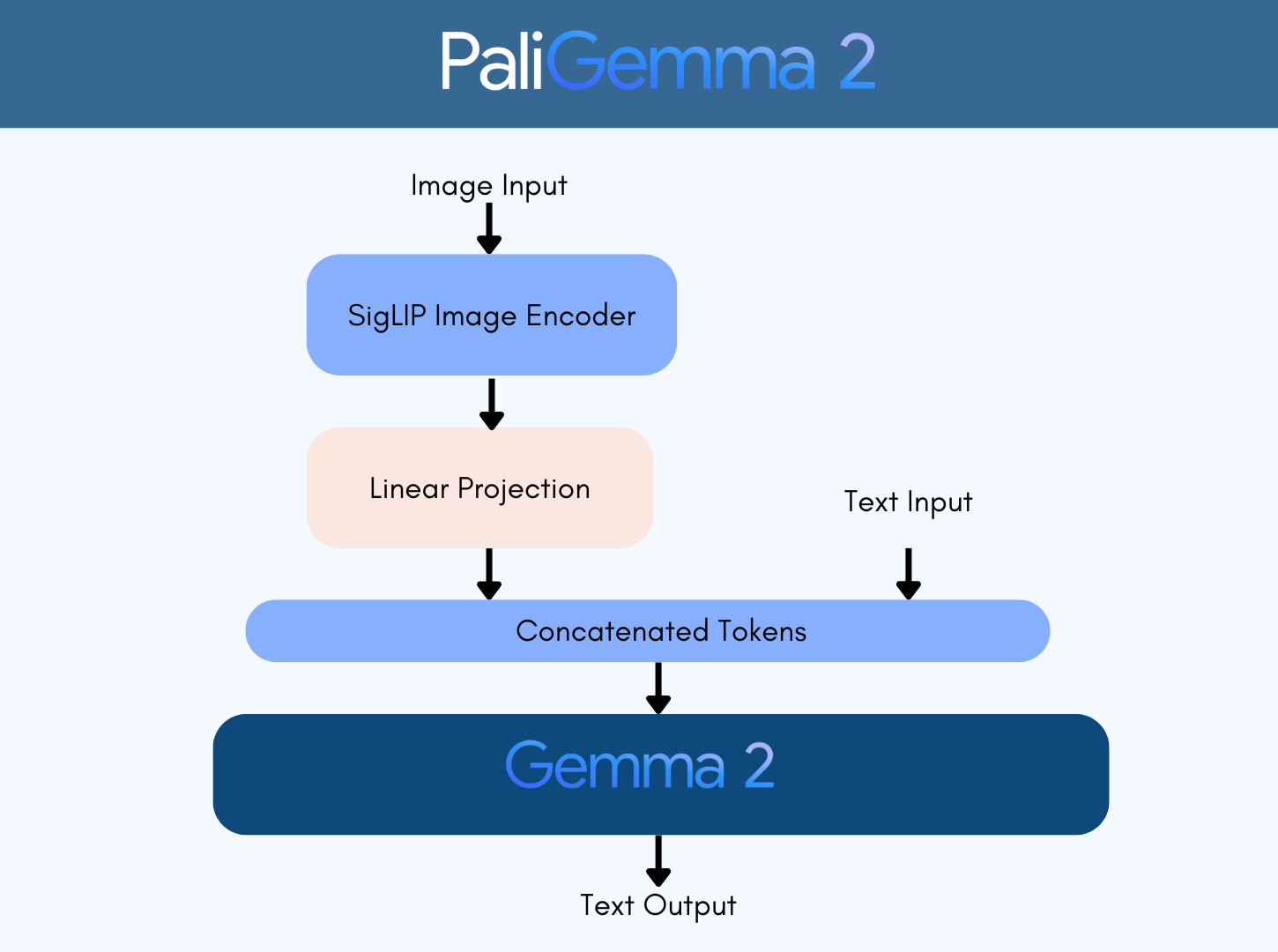
新的模型基于 Gemma 2 的 2B 、9B 和 27B 语言模型,分别对应 3B 、10B 和 28B 的 PaliGemma 2 变体。这些模型的名称考虑了紧凑图像编码器的附加参数。正如上文所述,这些模型支持三种不同的分辨率,为下游任务的微调提供了很大的灵活性。
PaliGemma 2 根据 Gemma 许可证 分发,该许可证允许重新分发、商业使用、微调以及创建模型衍生品。
此版本包含以下基于 bfloat16 精度的检查点:
-
9 个预训练模型: 3B、10B 和 28B,分辨率支持
- 224x224
- 448x448
- 896x896
-
2 个在 DOCCI 数据集上的微调模型: 基于 DOCCI 数据集 (图像-文本配对),支持 3B 和 10B 的 PaliGemma 2 变体,输入分辨率为 448x448。
模型能力
如同之前的 PaliGemma 发布一样,预训练 (pt) 模型在下游任务的微调中表现出色。
预训练数据集
pt 模型在以下数据混合集上进行了预训练。这些多样化的预训练数据集使模型能够在相似领域的下游任务中使用更少的示例进行微调。
- WebLI: 一个基于公共网络构建的大规模多语言图像 - 文本数据集。WebLI 数据集的多样化分割使模型具备了多方面的能力,如视觉语义理解、物体定位、视觉文本理解和多语言能力。
- CC3M-35L: 从网页上精心挑选的英语图像 - 替代文本数据集 (Sharma et al., 2018)。数据集的标签通过 Google Cloud Translation API 翻译成了 34 种额外的语言。
- Visual Question Generation with Question Answering Validation (VQ2A): 一个改进的问题回答数据集。该数据集也被翻译成了相同的 34 种语言,使用了 Google Cloud Translation API。
- OpenImages: 检测和物体感知的问答数据集 (Piergiovanni et al., 2022),通过手动规则生成,基于 OpenImages 数据集。
- WIT: 从 Wikipedia 收集的图像和文本数据集 (Srinivasan et al., 2021)。
微调模型与基准测试
PaliGemma 2 团队在多种视觉语言理解任务上对 PT 模型进行了内部微调,并提供了这些微调模型的基准测试结果。详细信息可以在 模型卡 和 技术报告 中找到。
PaliGemma 2 基于 DOCQI 数据集 微调,可以实现多种图像描述任务,包括文本渲染、捕捉空间关系以及包含世界知识的描述。
性能比较
以下表格展示了 DOCQI 微调模型与其他模型的性能对比 (数据来自 技术报告 中的 Table 6):
| 模型 | 参数量 | 字符数 (#char) | 句子数 (#sent) | NES ↓ |
|---|---|---|---|---|
| MiniGPT-4 | 7B | 484 | 5.6 | 52.3 |
| mPLUG-Owl2 | 8B | 459 | 4.4 | 48.4 |
| InstructBLIP | 7B | 510 | 4.0 | 42.6 |
| LLAVA-1.5 | 7B | 395 | 4.2 | 40.6 |
| VILA | 7B | 871 | 8.6 | 28.6 |
| PaliGemma | 3B | 535 | 8.9 | 34.3 |
| PaLI-5B | 5B | 1065 | 11.3 | 32.9 |
| PaliGemma 2 | 3B | 529 | 7.7 | 28.4 |
| PaliGemma 2 | 10B | 521 | 7.5 | 20.3 |
指标说明:
- #char: 生成的描述中平均字符数。
- #sent: 平均句子数。
- NES: 非蕴含句子数 (数值越低越好),用于衡量事实不准确性。
您可以在下面找到 DOCQI 检查点的部分模型输出,展示模型的多样性和灵活性。
| Input Image | Caption |
|---|---|
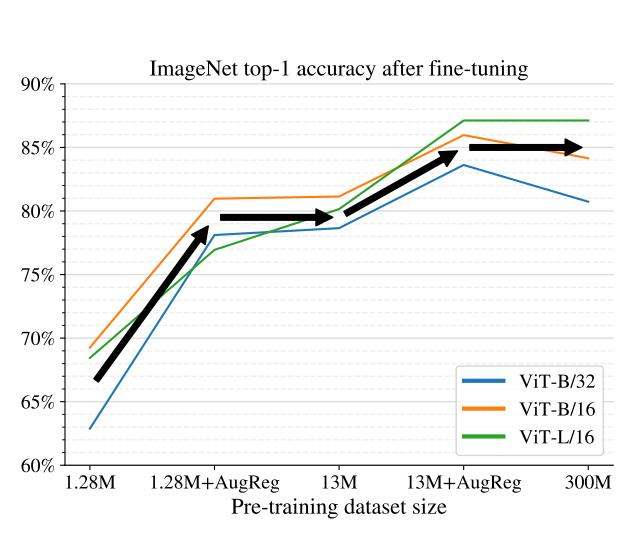 |
折线图展示了 ImageNet 模型在微调后的 Top-1 准确率表现。图中有四条不同颜色的线条: 蓝色、橙色、绿色和黑色。蓝色线条是四条线中最低的一条 ,它代表了表现最差的模型结果。 |
 |
一张白纸的特写镜头,上面用黑色的文字打印着内容。纸张中间稍微弯曲,文字使用打字机字体呈现。纸张顶部写着 "Ashley Hotel West Coast",其下是 "WiFi Internet Service"。再下面是 "Username: fqpp",最后是 "Password: aaeu"。 |
 |
一幅描绘大卫·鲍伊“Ziggy Stardust”造型的壁画被画在一面白墙上。壁画展示了三张并排的面孔,每张都有红色的头发,眼睛上画着蓝色的闪电图案。面孔的妆容包括蓝色眼影、粉红色腮红和红色嘴唇。中间的面孔上方有一个黑色的方形窗口,窗口内用白色文字写着 "JAM",字体为蓝色。画面的一侧停着一辆银色汽车。 |
 |
从上方俯瞰一张白色大理石台面,台面上放着四个咖啡杯。左边有两个灰色的杯子,左下角有一个白色的杯子,右侧则是另一个灰色的杯子。右上角放着一个带木质底座的金属水果篮,里面装满了橙子。左边还有一个装有水的透明玻璃水壶,画面中仅显示了部分内容。 |
 |
一张白色书本的特写,上半部分是白色区域,底部有一条蓝色条纹。白色部分印有黑色文字,内容为: "Visual Concept Learning from User-tagged Web Video" 。黑色文字下方有一个白色框,框内包含五张小图片。最左边的图片是一名站在草地中的人,右侧紧接的是一张蓝色海洋的图片。 |
演示
为了演示效果,Hugging Face 团队对 PaliGemma 2 3B 模型进行了微调,输入分辨率为 448x448,数据集使用的是 VQAv2 的一小部分。我们采用了 LoRA 微调 和 PEFT 方法,具体细节将在微调部分进行讲解。
下面的演示展示了最终结果。您可以自由查看 Space 中的代码了解其工作原理,或者克隆代码以适配您的自定义微调需求。
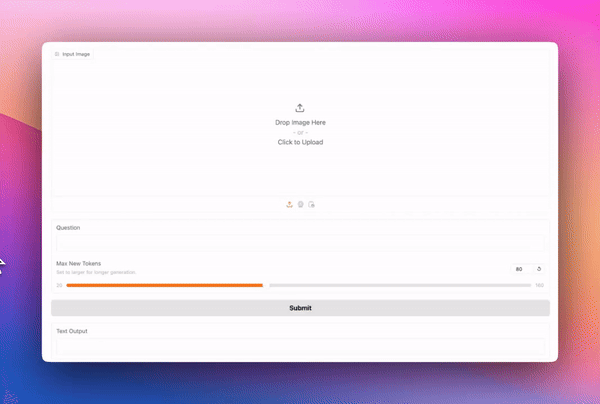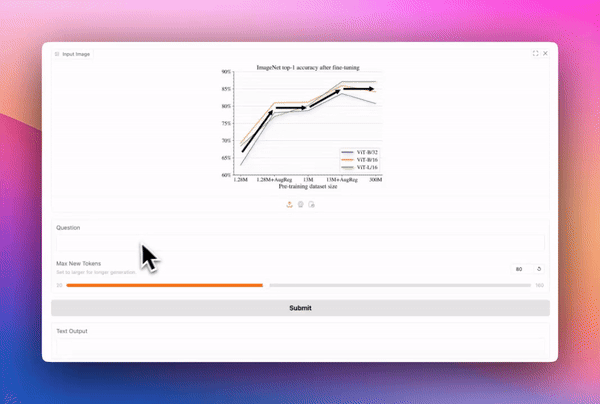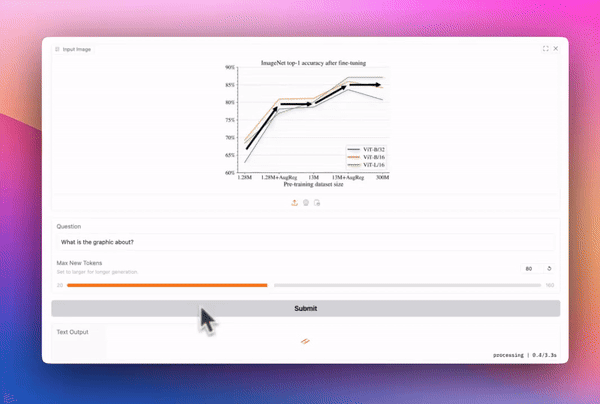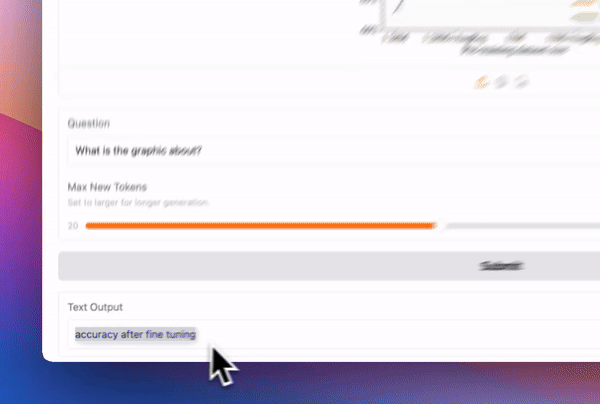
如何与 Transformers 一起使用
您可以使用 🤗 Transformers 库对 PaliGemma 2 模型进行推理,通过 PaliGemmaForConditionalGeneration 和 AutoProcessor APIs 实现操作。请确保您安装的 Transformers 版本为 4.47 或更高:
pip install transformers>=4.47
在安装完成后,您可以按照以下示例运行推理。同样重要的是,请确保遵循用于训练模型的任务提示格式,以获得最佳效果:
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requestsmodel_id = "google/paligemma2-10b-ft-docci-448"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
model = model.to("cuda")
processor = AutoProcessor.from_pretrained(model_id)prompt = "<image>caption en"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/cats.png"
raw_image = Image.open(requests.get(image_file, stream=True).raw).convert("RGB")inputs = processor(prompt, raw_image, return_tensors="pt").to("cuda")
output = model.generate(**inputs, max_new_tokens=200)input_len = inputs["input_ids"].shape[-1]
print(processor.decode(output[0][input_len:], skip_special_tokens=True))
# A medium shot of two cats laying on a pile of brown fishing nets. The cat in the foreground is a gray tabby cat with white on its chest and paws. The cat is laying on its side with its head facing the bottom right corner of the image. The cat in the background is laying on its side with its head facing the top left corner of the image. The cat's body is curled up, its head is slightly turned to the right, and its front paws are tucked underneath its body. There is a teal rope hanging from the fishing net in the top right corner of the image.您还可以使用 transformers 集成中的 bitsandbytes 来加载具有量化的模型。以下示例使用了 4-bit nf4:
from transformers import BitsAndBytesConfigbnb_config = BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.bfloat16
)
model = PaligemmaForConditionalGeneration.from_pretrained(model_id,quantization_config=bnb_config,device_map={"":0}
)我们快速测试了量化对性能的影响,通过评估一个 3B 微调检查点在 textvqa 数据集上的表现,使用 224x224 输入图像。这是我们在 5,000 个验证集条目上获得的结果:
- bfloat16,无量化: 60.04% 准确率。
- 8-bit: 59.78%。
- 4-bit,使用上面代码片段中的配置: 58.72%。
这些结果非常鼓舞人心!当然,量化对于更大的检查点更有意义,我们建议您始终在您所使用的领域和任务上测量结果。
微调
如果您之前已经微调过 PaliGemma,那么用于微调 PaliGemma 2 的 API 是相同的,您可以直接使用现有代码。我们提供了 微调脚本 和一个 notebook 来帮助您微调模型,冻结模型部分参数,或应用内存高效的微调技术,如 LoRA 或 QLoRA。
我们使用 LoRA 对 PaliGemma 2 模型在 VQAv2 验证集的一半进行了微调,以供演示。这项任务使用了 3 块 A100 显卡 (80GB VRAM),耗时半小时。
您可以在 这里 找到模型,此外 这个 Gradio 演示 展示了模型的效果。
结论
新发布的 PaliGemma 2 比之前的版本更加令人兴奋,具有不同的规模以满足各种需求,并提供更强大的预训练模型。我们期待看到社区能够构建出什么样的成果!
我们感谢 Google 团队发布了这一令人惊叹且开放的模型系列。特别感谢 Pablo Montalvo 将模型集成到 Transformers 中,以及 Lysandre、Raushan、Arthur、Yieh-Dar 和团队其他成员的努力,他们迅速完成了模型的评审、测试和合并工作。
资源
- 发布合集
- PaliGemma 博客文章
- 微调脚本
- 在 VQAv2 上微调模型
- 微调模型演示
- 技术报告
英文原文: https://hf.co/blog/paligemma2
原文作者: Merve Noyan, Andreas P. Steiner, Pedro Cuenca, Aritra Roy Gosthipaty
译者: xiaodouzi666