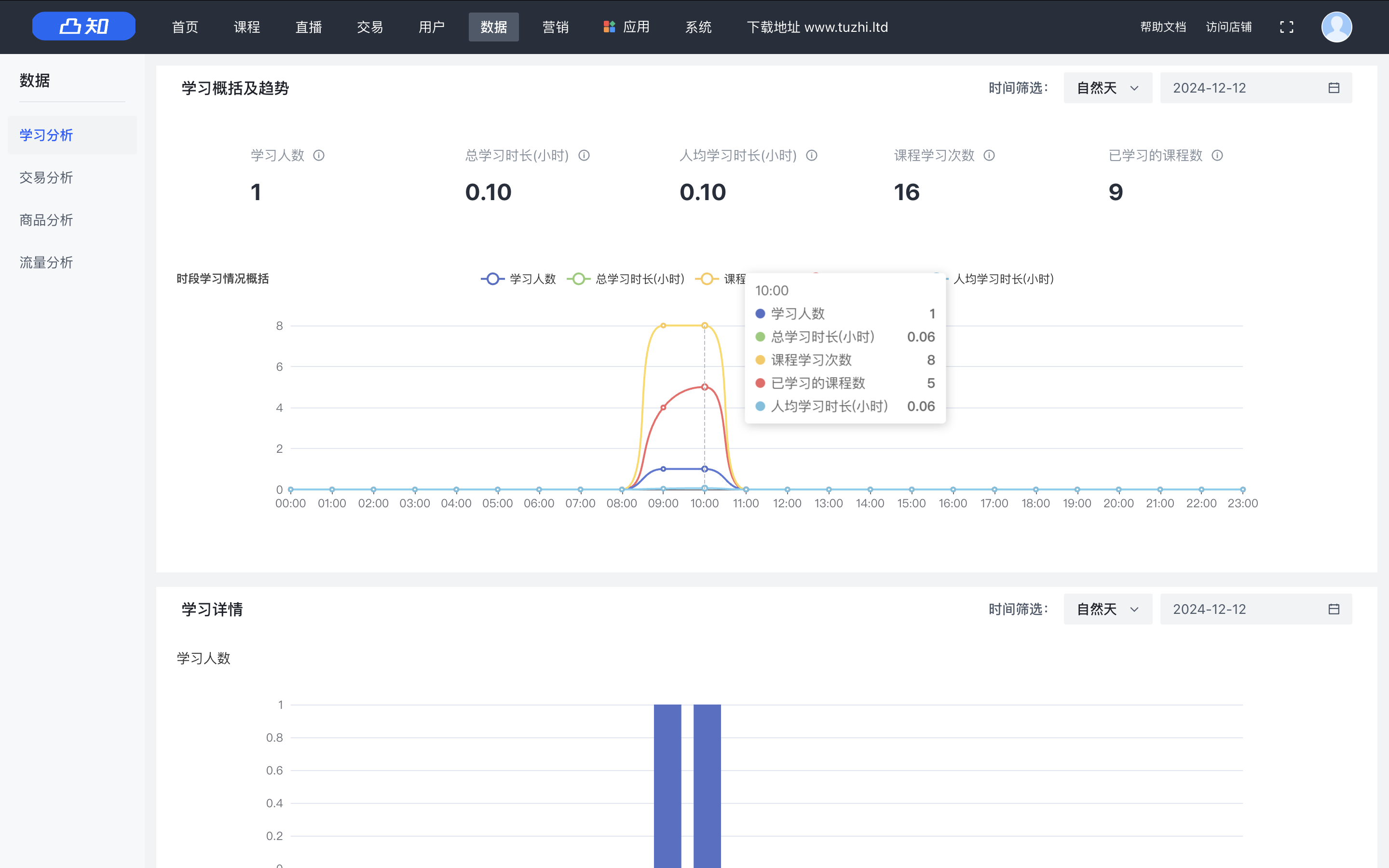
广义少镜头分割的视觉提示:一种多尺度方法
5.5.1 多尺度方法概述
基于注意力的变换器模型的出现,由于其优越的泛化和传递特性,在各种任务中得到了广泛的应用。最近的研究表明,当得到适当的提示时,这些模型对于少镜头推理来说是极好的。然而,对于语义分割等密集预测任务,这些技术的探索不足。在这项工作中,研究了用学习到的视觉提示提示Transformer解码器进行广义少镜头分割(GFSS)任务的有效性。目标是不仅在示例有限的新类别上实现强劲的表现,而且在基本类别上保持表现。
有研究者提出了一种通过有限示例学习视觉提示的方法。这些学习到的视觉提示用于提示多尺度变换器解码器,以促进准确的密集预测。此外,在用有限示例学习的新提示和用大量数据学习的基本提示之间引入了一种单向因果注意机制。该机制在不降低基类性能的情况下丰富了新的提示。总体而言,这种形式的提示有助于在两个不同的基准数据集上实现GFSS的最先进性能:COCO-20i和Pascal5i,而不需要测试时间优化(或转导)。
此外,利用未标记的测试数据进行测试时间优化可用于改进提示,称之为转换提示调优。
改进方法概述,提出用于广义少镜头分割的多尺度变换解码器,如图5-15所示。

图5-15 改进方法概述,提出用于广义少镜头分割的多尺度变换解码器
图5-15是一种简单的方法,允许测试时转换提示调谐(见红色箭头)。
5.5.2 广义少镜头分割的视觉提示:一种多尺度方法分析
在广泛的数据集、自然语言处理(如GPT-3)和视觉语言(如CLIP)中训练的基础模型的出现,在多个下游任务上表现出强大的泛化能力和强大的性能。这些模型已经通过不同的提示技术进行了调整,以便在少镜头场景中使用。
然而,尽管取得了成功,包括在本地化方面,但提示在密集预测中,特别是在语义分割任务中,允许很少的镜头演示,这方面的探索相对不足。
很少有镜头语义分割旨在通过很少的标记训练示例来分割新的(看不见的)类。大多数最先进的方法都依赖于元学习,利用丰富的训练数据作为一种数据增强的形式来构建许多类似于测试时间少镜头推理的任务。一般来说,少镜头学习方法可以分为归纳法或转导法。归纳法主要依赖于训练数据,而转换法则以无监督的方式利用未标记的测试数据来提高性能,例如通过利用熵先验而不是预测类分布。然而,这两个案例都主要关注创新类别的表现;这不是特别现实。最近提出的广义少镜头分割(GFSS)设置定义了一个更现实的场景,其目标是在所有类别(新颖和基础)上都表现良好。这更具挑战性。
提示已被证明对从少数演示中学习是有效的,正如在LLMs中看到的那样。还探索了视觉提示调谐,以有效地为新任务对视觉变换器进行微调。假设,在基于Transformer的架构中进行提示同样可以为GFSS提供一种有效且灵活的机制。这涉及学习提示,可用于与输入图像进行交叉关注以进行预测。虽然具有丰富数据的基类的学习提示相对简单,但对于例子很少的新类来说,它变得更具挑战性。
具体来说,必须确保从少数样本中学习到的新提示与基本提示完全不同,以避免新的基类错误分类。
为了应对上述挑战,开发了一种简单但高效的Transformer解码器视觉提示,用于多尺度的密集预测,该提示依赖于新颖的因果注意力,而无需元训练。将DETR风格架构中的查询视为一种视觉提示形式,并设计了一种初始化和学习新提示的机制。然后,创新对基础因果注意允许基础提示影响创新提示表征,但反之则不然。直观地说,这使得新颖的提示被基础提示所排斥和/或吸引。这种关注是跨尺度(Transformer的层)共享的,正如所示,这会导致更稳健的学习和性能的提高。提示的多尺度重构有助于在多个尺度上的图像特征之间进行交互和推理,从而有助于更好地进行密集预测。最后,在转换环境中扩展了这种架构,在这种环境中,可以在测试时根据无监督目标对新颖和基本提示进行精细调整,以进一步提高性能。改进的架构和方法如图1所示。
创新方法的内容包括如下:
(1)为GFSS设计多尺度视觉提示转换器解码器架构,其特征是可学习的提示,允许为新类创建新的提示,通过支持图像的掩码平均池(及其掩码)进行初始化。
(2)在这种架构中,提出并学习一种多尺度(共享)创新,以建立创新和基础提示之间的交叉注意力机制。
(3)提出了一种新的转导提示调谐,它允许在测试(未标记)图像上调谐视觉提示,因此被称为转导。
提出的多尺度变换解码器视觉提示的详细架构,如图5-16所示。

图5-16 提出的多尺度变换解码器视觉提示的详细架构
在5-16中,设计使用支持集初始化新颖的视觉提示。接下来是连续的创新,以基础因果注意,CA,以及跨尺度的提示目标特征交叉注意,C。因果注意力在标尺和解码器层之间使用共享权重。设计允许利用未标记的测试图像对视觉提示进行传感精细调谐。
混淆矩阵基础与创新,如图5-17所示。

图5-17 混淆矩阵基础与创新
在图5-17中,混淆矩阵:(左)具有新颖基础因果注意的模型;(右)没有新到基础因果注意的模型。创新到基础因果注意减少了创新和基础类别之间的混淆(左下角块)。
学习基础和新颖提示特征的TSNE可视化,如图5-18所示。

图5-18 学习基础和新颖提示特征的TSNE可视化
Pascal-

单次注射的定性结果如图5-19所示。

图5-19 Pascal-

单次注射的定性结果
在图5-19中,左列显示图像和真实掩模;第3列基线无因果关系;第4列在归纳环境中;第5列在转换环境中;第6列DIaM。最后一行表示故障。