@
目录
- 前言
- 导航
- BeautifulSoup
- BeautifulSoup介绍
- BeautifulSoup的使用
- 1. 导入库
- 2. 实例化对象
- 3. 提取数据
- 成果
- 共勉
- 博客
前言
当我们进行爬取各种资源,拿到源码进行解析数据的时候,会用到各种解析方式,本文介绍的爬取小说的一个案例,使用比较受欢迎的python第三方库BeautifuSoup来进行解析数据。
导航
- 持续更新中
- 持续更新中
- 持续更新中
- 持续更新中
- 持续更新中
BeautifulSoup
BeautifulSoup介绍
BeautifulSoup 是一个用于从 HTML 和 XML 文件中提取数据的 Python 库。它提供了一些简单的函数用来处理导航、搜索、修改分析树等功能。它能够帮助开发者高效地从网页等结构化文档中抓取和解析信息,比如提取网页中的文本、链接、图片等各种元素。
BeautifulSoup的使用
BeautifulSoup不是python标准库的一部分,因此需要在终端使用pip命令单独安装。此外,BeautifulSoup支持多种解析器,包括Python标准库中的HTML解析器、lxml HTML解析器以及html5lib等,我们常用的就是lxml Html解析器,这些解析其也需要单独安装。
pip install beautifulsoup4
pip install lxml
BeautifulSoup的使用一般包含四个步骤
1. 导入库
from bs4 import BeautifulSoup
import requests # 数据请求模块
2. 实例化对象
url='http://xxx.com'
response=requests.get(url=url)
soup=BeautifulSoup(response.text,'lxml')
3. 提取数据
提取数据方式分为很多种,其中find(),find_all()方法进行查找数据比较常见,find()函数用于查找单个元素,而find_all()函数用于查找多个元素,其中可以通过class属性和id属性以及标签来进行定位。
如下面示例:
# 用标签定位查找-->定位标签为link的元素
soup.link# 用class属性进行查找-->查找class属性为info的div元素,find()函数只取第一个元素
soup.find("div",class_="info")
# find_all函数查找多个元素
soup.find_all("div",class_="info")# 用id属性进行定位查找-->查找id为content的div元素,只取第一个
soup.find("div",id = "content")
# find_all函数用于查找多个元素
soup.find_all("div",id = "content")
查找到元素就要提取其中的文字或者属性,其中常见的有三种
- .string:获取标签内的文本内容,只适用于只有一个子节点的标签
- .text:获取标签及其所有子节点的文本内容
- .attrs:获取标签的所有属性,返回一个字典
# 获取id为content的div元素的所有文本内容
soup.find("div",id = "content").text
# 获取class为info的div元素的文本内容
soup.find("div",class_="info").string
# 获取p标签的所有属性,返回一个字典
soup.p.attrs
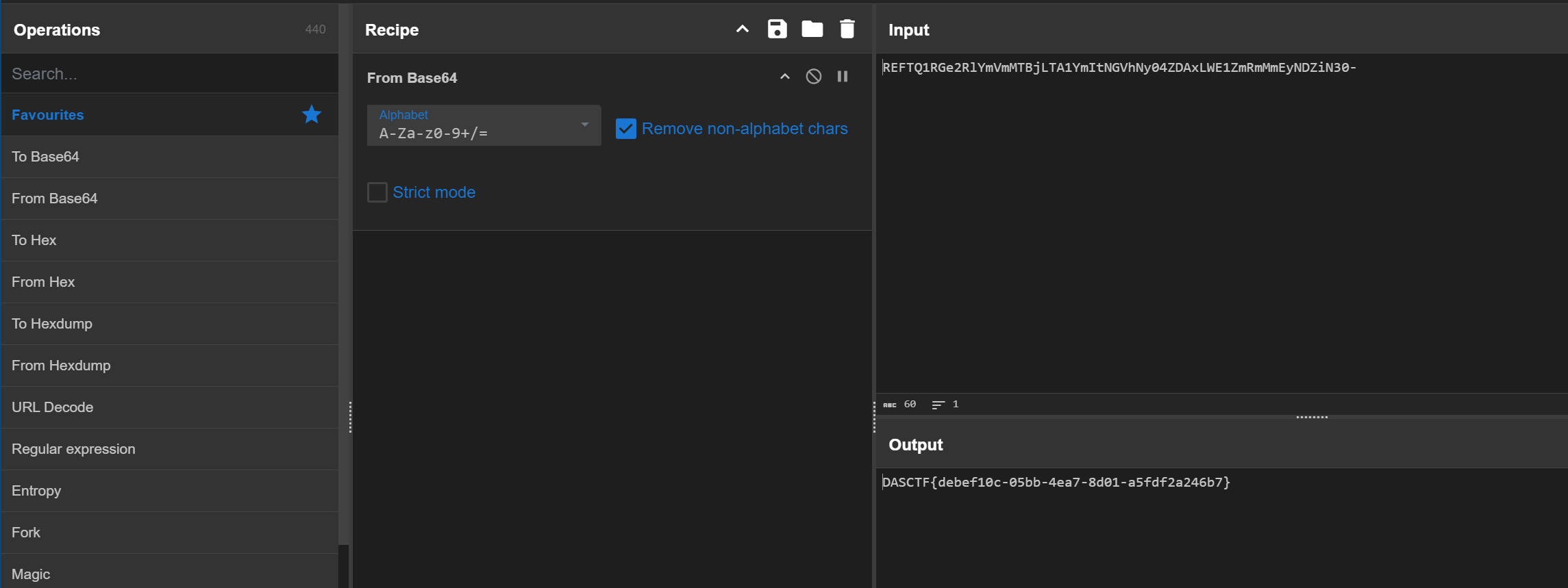
下面通过爬取起点小说网的万相之王并把每章的内容储存到本地为例,来实战BeautifulSoup的应用。
import requests # 数据请求模块
import bs4 from BeautifulSoup # 导入BeautifulSoup库,bs4为别名
import lxml # 用于解析xml和html文件
import os # 文件管理模块# 创建chapter文件夹,用于储存每章的小说内容
if not os.path.exists("./chapter"):os.mkdir("./chapter")# 起点小说网网址
url="https://www.qidian.com/book/1027368101/"
# 请求头 Users-Agent为浏览器的标识,Cookie为会话标识
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0","Cookie":"e1=%7B%22l6%22%3A%221%22%2C%22l7%22%3A%22%22%2C%22l1%22%3A%22%22%2C%22l3%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%221%22%2C%22l7%22%3A%22%22%2C%22l1%22%3A3%2C%22l3%22%3A%22%22%2C%22pid%22%3A%22qd_P_xiangqing%22%2C%22eid%22%3A%22qd_H_shuyouclass%22%7D; _csrfToken=zK5XAjMErDwmXg9Ea69GM5HZPBLGGvNdK3kHgmXC; newstatisticUUID=1725338674_1056963668; fu=1252791423; supportwebp=true; supportWebp=true; se_ref=; traffic_search_engine=; e1=%7B%22l6%22%3A%22%22%2C%22l7%22%3A%22%22%2C%22l1%22%3A2%2C%22l3%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; e2=%7B%22l6%22%3A%22%22%2C%22l7%22%3A%22%22%2C%22l1%22%3A2%2C%22l3%22%3A%22%22%2C%22pid%22%3A%22qd_p_qidian%22%2C%22eid%22%3A%22%22%7D; traffic_utm_referer=https%3A//cn.bing.com/; w_tsfp=ltvuV0MF2utBvS0Q6qjolUqqEzwudzw4h0wpEaR0f5thQLErU5mG04d7v8/yNXPa58xnvd7DsZoyJTLYCJI3dwMUR5rEdN0ViQ2Yw4l0jocQAEY2QJiOX1cXJu0j7GFDL3hCNxS00jA8eIUd379yilkMsyN1zap3TO14fstJ019E6KDQmI5uDW3HlFWQRzaLbjcMcuqPr6g18L5a5T3Y5QmqeAh8UbtA2BOQh3ofXX1250K5d+oLNh6vK8z7SqA="
}
# 发送get请求
response = requests.get(url,headers=headers)
# 利用BeautifulSoup库进行数据解析
soup = BeautifulSoup(response.text, 'lxml')
# 查找每个章节所在的所有li标签-->类名为"chapter-item"
chapter=soup.find_all('li',class_='chapter-item')
# 对每个章节进行遍历
for li_data in chapter:# 每章章节名 strip()去除空格chapter_title=li_data.text.strip()# 每章的地址chapter_href=li_data.a["href"]# https协议chapter_href="https:"+chapter_hreftry:# 对每章的url地址进行请求chapter_detail = requests.get(url=chapter_href, headers=headers)# 解析数据soup_detail = BeautifulSoup(chapter_detail.text, 'lxml')chapter_detail_data = soup_detail.find("main",class_="content").textprint(chapter_detail_data)# 把每章都写入本地with open("./chapter/" + chapter_title + '.md', 'w', encoding='utf-8') as f:f.write(chapter_detail_data)print("chapter:" + chapter_title + " 写入成功")except:print(f"需要登录才能查看完整的章节:{chapter_title},{chapter_href}")
成果
共勉
自给自足的光,永远不会暗!
博客
- 本人是一个渗透爱好者,不时会在微信公众号(laity的渗透测试之路)更新一些实战渗透的实战案例,感兴趣的同学可以关注一下,大家一起进步。
- 之前在公众号发布了一个kali破解WiFi的文章,感兴趣的同学可以去看一下,在b站(up主:laity1717)也发布了相应的教学视频。