BERT 发布于 2018 年(从人工智能发展速度来看已是遥远的过去),但它至今仍在广泛使用:实际上它目前是 HuggingFace hub 上下载量第二高的模型,月下载量超过 6800 万次,仅次于另一个针对检索任务优化的编码器模型。这源于其编码器架构在处理日常实际问题方面表现出色,例如检索(如用于 RAG)、分类(如内容审核)和实体提取(如隐私保护和合规性检查)等任务。
经过六年的发展,我们终于迎来了它的继任者。ModernBERT 是一个全新的模型系列,在速度和准确性两个维度上全面超越了 BERT 及其后继模型。这个新模型整合了近年来大语言模型(LLMs)研究中的数十项技术进展,并将这些创新应用到 BERT 风格的模型中,包括对架构和训练过程的全面优化。
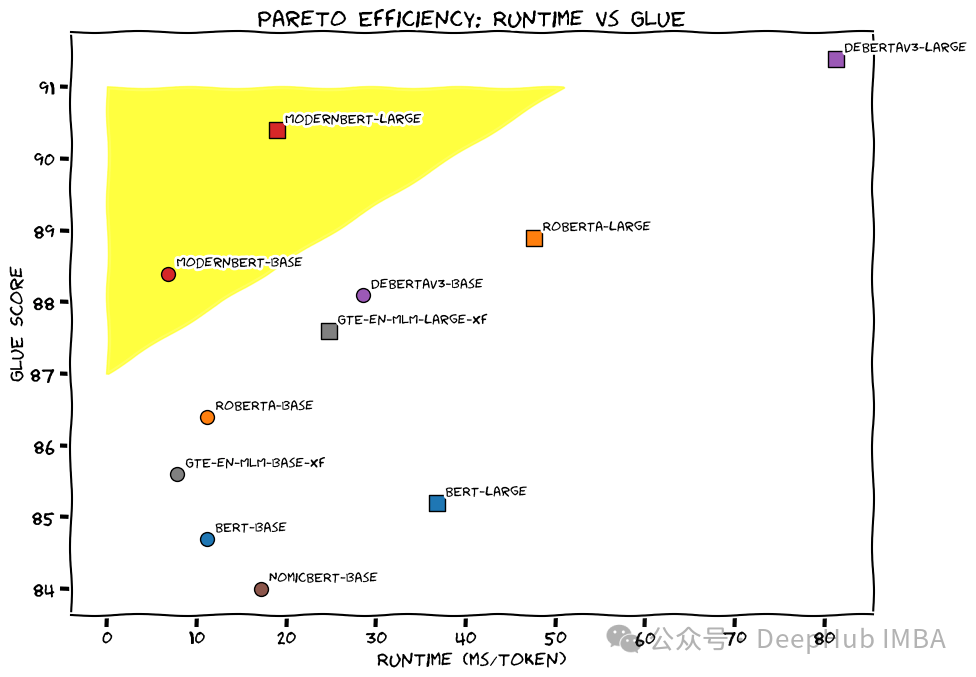
我们预计 ModernBERT 将成为目前广泛应用编码器模型领域的新标准,特别是在检索增强生成(RAG)管道和推荐系统等应用场景中。
ModernBERT 不仅在性能和速度上有所提升,还将上下文长度扩展到了 8k tokens(相比之下,大多数编码器仅为 512),并且首次在训练数据中大规模引入了代码数据。这些特性开启了此前开源模型无法实现的新应用领域,如大规模代码搜索、创新的 IDE 功能,以及基于完整文档而非小片段的新型检索管道。
在详细介绍这个新的架构之前,我们首先回顾一下这个领域的发展历程。
https://avoid.overfit.cn/post/3b7337af12a14732b3d24852ebe0a682