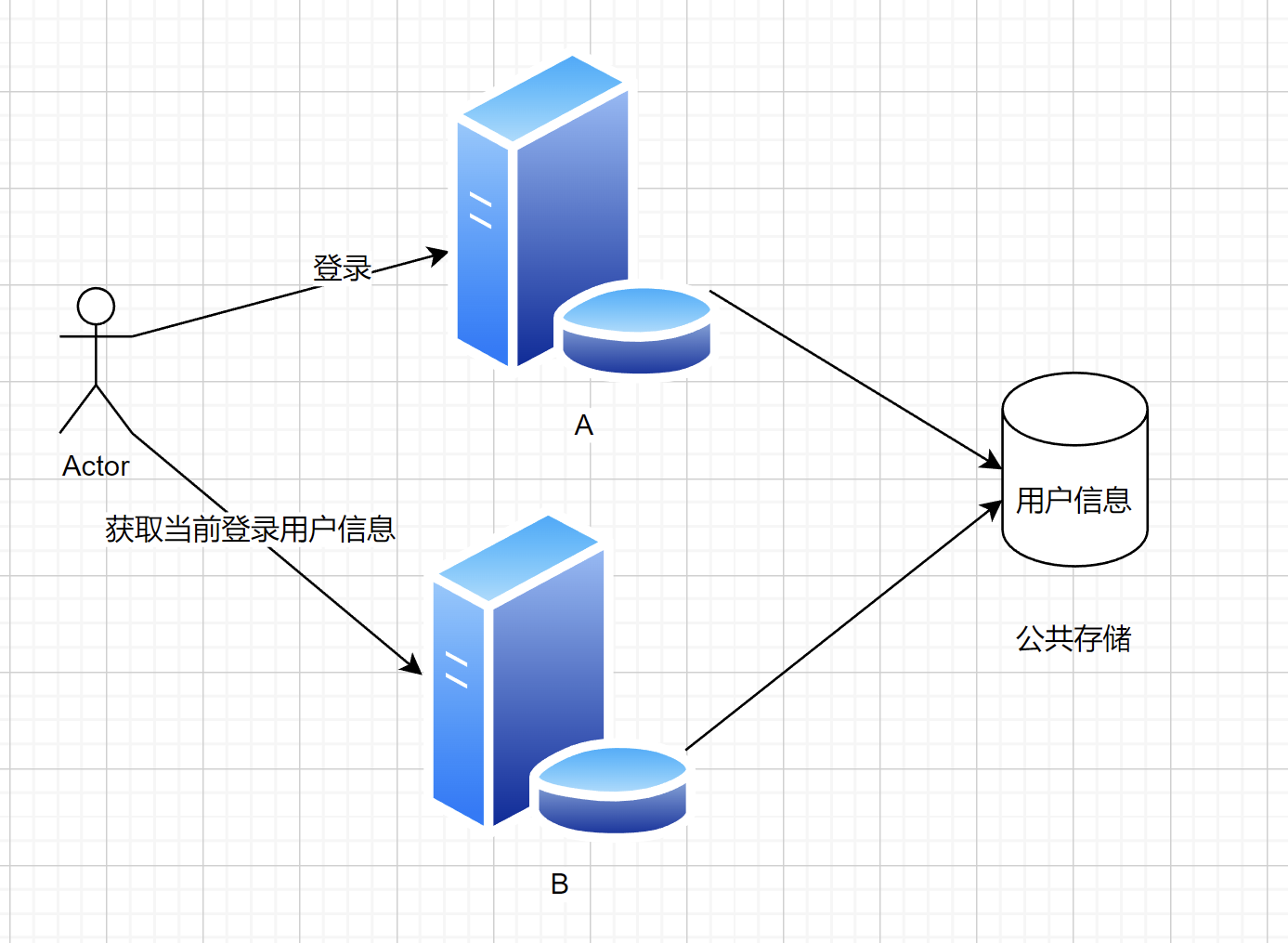
1. 物联网
1.1. 边缘设备(edge device)通常是指远程站点里的服务器,这几年也用来指代智能手机与平板计算机
1.2. 物联网是边缘运算(edge computing,也叫边缘计算)的一个子集
-
1.2.1. 所连接的设备在本组织的数据环境里处于相当边缘的地位
-
1.2.2. 所连接的设备要比刚才那些更为边缘,这些设备可能是数据收集设备,也可能是信息展示设备
-
1.2.2.1. 前者则会创建出大量有待保护的数据
-
1.2.2.2. 后者并不创建数据,因此不在数据保护人员的关注范围里面
-
1.2.3. 极其微小、只执行一项功能,并且只收集一种数据的设备
-
1.2.4. 形体袖珍,耗电量特别低,而且自身通常没有多少存储空间
1.3. 商店里的销售时点设备(point-of-sale device)可能也是一种边缘运算设备,只不过这种设备不太适合归入物联网设备
1.4. 大多数物联网设备都会把它们所创建的数据立刻发送给其他某种设备,让那种设备去正式地保存这些数据
-
1.4.1. 几乎总是需要通过某种云端服务来实现此功能,这样可能就不会出现有待保护的实体服务器了
-
1.4.2. 得仔细检视你们的物联网设备,看看它到底有没有把数据同步到另一台服务器上,或者有没有将其交给另一种服务去保存
1.5. 必须尽量缩减备份所占的空间
-
1.5.1. 需要判断这次备份的文件与上次相比,有哪些字节发生了变化,而不是把整个文件直接备份下来
-
1.5.2. 必须尽量缩减其中的重复数据
-
1.5.3. 有助于减轻备份工作所带来的计算压力,并减少所需执行的I/O操作量
1.6. 如果你们的物联网设备根本就没有把数据集中同步到某个数据存储设备里,那么这些数据备份起来或许就相当困难了
-
1.6.1. 这种物联网设备的带宽一般不高,然而它们所创建的数据量通常又不少
-
1.6.2. 高清视频监控系统
-
1.6.2.1. 启用动作觉察机制(motion
activation),让摄像头只在前方出现运动物体时才开始录像
- 1.6.3. 许多边缘设备也会大量产生这种很难移动到别处的数据
2. 备份决策
2.1. 备份某个数据时所采用的方式也需要由你自己来决定
2.2. 数据的重要程度
-
2.2.1. 有些数据是无价的
-
2.2.1.1. 全球仅此一份的数据
-
2.2.2. 做决策时,你可以给不同的数据集赋予不同的权重,以此来决定它们的重要程度
2.3. 恢复数据所需的时间
-
2.3.1. 采用的备份方式可能会让将来恢复该数据时所花的时间过长
-
2.3.2. 将来恢复数据时会不会特别慢,如果会,那么你们能否承担由此造成的损失
-
2.3.2.1. 如果证据丢失,那么法官可能会给你宽限一段时间,也可能不会
-
2.3.2.2. 假若这份重要的证据恢复起来相当慢,那某人可能因为你们的延期申请遭到拒绝而丧命
-
2.3.3. 关系到的可能是成本或损失
-
2.3.3.1. 如果恢复数据耗费的时间过久,那么对于公司来说,可能会错失很多赚钱机会
-
2.3.3.2. 对于政府机构来说,可能会错失很多应该征收的税费
2.4. 数据源的特点
-
2.4.1. 判断某个数据源应该如何备份时,应该考虑这种数据源有什么特殊的地方
-
2.4.2. 选择占用带宽比较少的方案
-
2.4.2.1. 对于数据中心来说,带宽问题通常并不严重
-
2.4.2.2. 在备份笔记本计算机、移动设备、远程办公场所里的设备以及云端的资源时,这可能就是一个相当大的挑战了
-
2.4.3. 有待备份的数据源在行为方面具备何种特征
-
2.4.3.1. 笔记本不一定总是开机
-
2.4.3.2. 给持有该数据的人一些自主权,让他们在笔记本开机时去备份
-
2.4.4. 有待备份的数据在备份过程中是否会发生变化
-
2.4.4.1. 数据库就是一个典型的例子
-
2.4.5. 将来可能会在什么样的情况下执行恢复
-
2.4.5.1. 设计方案时必须要考虑到将来有可能要在什么样的情况下恢复数据,而不能总是假设一定会在本组织里面执行恢复
3. 备份的一些概念
3.1. 凡是与原始数据分开保存,且能够在原始系统受损之后用来恢复其数据的副本,都叫作备份
- 3.1.1. 所有的备份均必须能在它所保护的文件、数据库、服务器与应用程序因遭受事故、网络入侵或勒索攻击而受损之后,将其恢复到原来的状态
3.2. 磁带机
3.3. 对文件与数据库所做的那种批处理式的备份流程
3.4. 数据重制(replication,也叫数据复制)、快照(snapshot)、持续数据保护(Continuous Data
Protection, CDP)等概念
3.5. 用传统手段来恢复数据的备份方案
- 3.5.1. 方案在恢复数据时都会通过某种流程把数据复制到需要恢复的系统里,只不过这个流程必须在你主动触发恢复操作时才会启动,而不是随时准备启动
3.6. 即时恢复
- 3.6.1. 不需要执行传统的恢复流程,就能够在某段时间内直接把备份当作正本使用
3.7. BaaS(Backup-as-a-Service,备份即服务)
3.8. CDP(Continuous Data Protection,持续数据保护)与准CDP(near-CDP)这两个概念
4. 传统恢复流程的备份方案
4.1. 传统的恢复流程启动之后,需要一定的时间才能执行完毕,这可能是几分钟,也可能是几小时(甚至几天)
-
4.1.1. 具体多长,取决于备份系统必须把多少数据传输到有待恢复的那个系统,另外还取决于备份系统执行恢复时的效率
-
4.1.2. 效率受到带宽的影响,还与备份系统与恢复系统的性能有关
4.2. multiplexing
-
4.2.1. 多路复用/多工
-
4.2.2. 一种向磁带里面写入数据时所使用的技术,用以解决磁带速度与备份数据的输入速度不匹配的问题
-
4.2.3. 磁带机总是想让磁带走得快一些,但是许多备份数据(尤其是制作增量备份时所产生的那种数据)输入磁带机的速度却相当缓慢
-
4.2.3.1. 前者的理想速度是每秒钟上百MB
-
4.2.3.2. 典型的增量备份每秒只能产生10~20MB的数据
-
4.2.4. 反向的擦鞋问题
-
4.2.5. 大幅增加数据块的尺寸,并采用这样的数据块来穿插安排各条备份流
-
4.2.5.1. 要求备份软件那边必须多做一些处理,而且可能意味着备份方案需要耗费更多的资金,但总之,数据块的尺寸已经变得足够大,从而不会产生擦鞋问题
4.3. 传统的完全备份与增量备份
-
4.3.1. 每月做一次完全备份,每周做一次积累式的增量备份,每天做一次常规的增量备份
-
4.3.1.1. 所需移动的数据量要比以前低得多,这不仅能减轻客户端的压力,而且能够降低传输备份数据时所需的网络带宽
-
4.3.2. 合成式的完全备份,这种备份从恢复的角度来看跟普通的完全备份一样,但在制作时并不需要像制作普通的完全备份时那样,要求备份客户端把涉及该备份的所有数据都传过来
-
4.3.3. 必须先对完全备份做恢复,然后还得按照当初创建这些增量备份时的顺序,逐个对增量备份做恢复
4.4. 文件级别的incremental forever
-
4.4.1. 从文件这一层面来考虑某个东西是否需要备份的
-
4.4.2. 某份文件里有某个内容发生变化,那么该文件的修改时间或存档位会有所改变,于是,我们就把整份文件备份下来
-
4.4.3. 如果某个备份产品要从一开始就制作文件级别的增量备份,那么它只能在刚启用时做一次完全备份(无论是合成式的还是普通的都行),然后必须一直做增量备份,而不能再做完全备份
-
4.4.4. 从一开始就制作增量备份是有许多好处的,因为这种做法能够大幅缩减客户端所需处理的数据量以及传输数据时所需占用的带宽
-
4.4.5. 它以后不需要再制作完全备份,因此还意味着备份系统所需存储的数据比较少,而你需要复制到其他存储设备(也包括云端存储设备)里的数据同样比较少
-
4.4.6. 如果你能够从一开始就做增量备份(以后不再制作完全备份),那么从去除重复数据的角度看,这就是一个相当良好的开局
-
4.4.7. 以后不需要再浪费CPU资源、网络带宽与存储空间去制作完全备份了
-
4.4.8. 对于磁带来说,增量备份做得越多,问题就越严重
-
4.4.9. 能够直接把正确的那个版本恢复出来,而不用先恢复某个版本,然后再用后续的版本覆盖它,直至找到想要的版本为止
4.5. 块级别的incremental forever
-
4.5.1. 只会在刚开始时制作一次完全备份,以后就一直做增量备份,而不再做完全备份了
-
4.5.2. 应用程序必须维护一种位图,用来指出哪个数据或哪部分数据发生了变化,这种技术通常又称为CBT(Changed-Block Tracking,数据块修改追踪)
-
4.5.3. 最容易遇到它的地方,还是那些需要使用虚拟机的场合
-
4.5.4. 能够大幅降低从客户端发往服务器的数据量,因此,在备份远程系统时相当有用
-
4.5.5. 采用incremental forever方式来给笔记本计算机与远程办公室做备份的
-
4.5.6. 必须用某个东西来实现CBT机制,但并非每个系统都能做到这一点
-
4.5.7. 只能把备份数据保存到磁盘上
-
4.5.7.1. 由于磁盘本身就是一种能够随机访问的介质,因此很适合充当这种备份方案的目标介质
4.6. 源端去重
-
4.6.1. 源端去重系统会在备份流程刚启动时执行重复数据去除操作(也就是说,它会从数据的源头去重)
-
4.6.2. 会站在备份客户端的立场上,决定是否需要把某个新的数据块传输给备份系统
-
4.6.3. 也是一种incremental forever式的备份方法,这种方法不会把从前已经见过的chunk(块)重新备份一遍
-
4.6.4. 这种办法所需备份的数据,要比block(块)级别的incremental
forever方案更少
-
4.6.5. 需要通过网络传输备份的场合里效率相当高
-
4.6.6. 至少能够缩减备份系统所要处理的内容,不会让里面出现太多的重复数据
-
4.6.7. 能够减少客户端传给备份系统的数据量,它比块级别的增量备份方案还要好,因此,很适合备份远程设备,例如笔记本计算机、移动设备、远程办公室里的设备以及云端的虚拟机等
-
4.6.8. 缺点在于,你可能得先改变备份软件,然后才能开始实施该方案



![[转]教大家如何选择正确的Google Play服务](https://img2024.cnblogs.com/blog/597729/202412/597729-20241226000222504-618752269.png)