本文将带您深入了解一个与之相关的真实事故现场及其问题定位过程,波折重重,其中的xenomai问题定位思路具有一定借鉴意义,希望对你定位xenomai问题有所帮助。
本文将带您深入了解一个与之相关的真实事故现场及其问题定位过程,波折重重,其中的xenomai问题定位思路具有一定借鉴意义,希望对你定位xenomai问题有所帮助。- 一 前言
- 二 背景
- 三 原因分析及措施
- 硬件原因
- 应用软件
- 操作系统
- 四 分析定位
- 转机
- 拨云见雾
- irq计数
- Schedstat
- coreclk
- 现象结论
- 五 原因一
- 六 原因二
- 七 解决
- 八 结语
一 前言
在上一篇博文中,我们详细介绍了Xenomai的看门狗机制。本文将带您深入了解一个与之相关的真实事故现场及其问题定位过程。为了专注于技术细节,本文去除了所有与具体业务相关的信息,其中的xenomai问题定位思路具有一定借鉴意义,希望对你定位xenomai问题有所帮助。
二 背景
简单介绍一下背景,这是一个基于xenomai的linux实时嵌入式系统,为方便表述,使用设备A代替,使用的是linux5.4+ipipe,CPU为单核 ARMv7(32位)。其上面跑了一个中大型实时应用,其中包含优先级!0且优先级不一的实时任务有25+,这些实时任务其中之一是个TCP/IP协议栈,可见业务之复杂。
该系统上市一年多,期间未出现问题,后来在多个不同现场出现"死机",不同现场前后间隔几天集中爆发,且毫无规律,出现间隔时长从数日至一两个月不等,令人捉摸不透。初步排查期间没有对系统升级,虽然应用在升级迭代,但经详尽检查后未发现会导致死机的应用变更,很是费解。
期间我们尝试搭建与现场一样的环境,复制了同样设备连接和网络环境均未复现,对现场的网络包进行抓包分析未见异常,这一系列的结果令人倍感困惑。
三 原因分析及措施
在第一个客户现场A发生“死机”发生时,与市场人员沟通初步排查反馈是:系统无正常响应,linux系统ip ping无响应,实时任务的tcpip协议栈的ip ping也无响应。既然搭建与现场一样的环境也无法复现,只能从多方面推导可能的原因,逐一验证猜想,有如下几个方面。
硬件原因
第一个是硬件层面,怀疑现场可能存在干扰,或者硬件存在物料替换导致的系统死机,但经过硬件和EMC现场排查测量未发现问题,加不同程度干扰也未复现。硬件回溯不存在大的物料替换,且发生问题的硬件是不同批次,排除物料导致的问题。硬件排查无果,转而怀疑软件系统问题。
应用软件
怀疑高优先级任务存在bug,如果高优先级任务存在某些触发条件触发(也包括xenomai内核实时任务)进入while(1)死循环逻辑,不释放CPU,会导致的低优先级任务饿死,对外表现就是死机。
熟悉xenomai的朋友都知道,xenomai是一个双内核操作系统,Linux内核是实时核的idle任务,而xenomai又没有PREEMPT-RT那样的实时限流(RT Throttling)机制,只有在实时核调度的实时任务都让出CPU后Linux调度的普通任务才能得到运行,这意味着Linux基本调试手段如串口终端、telnet、ping、coredump、存储IO等等在该情况下会完全失效。这种情况发生时,对外表现就是死机,同时也影响对系统的进一步观测和分析。
而上一篇博文中提到的xenomai watchdog,在我们的系统中并未打开,也就不能确定是该原因导致的死机,否则xenomai watchdog会及时将while(1)死循环逻辑实时任务杀死。
由于实时任务的tcpip协议栈的ip ping也无响应,说明出问题的只能是比tcpip协议栈优先级更高的任务,对此我们对满足条件的实时任务执行流进行了排查,未查找到可能的异常点。
为此我们给现场A发布了临时版本,启用xenomai watchdog,同时添加linux内核coredump,增加另一个更高优先级的任务周期检测应用是否异常等措施,现场A刷机后只能等待复现,但刷机后,该现场不出现了,原本一周左右就能复现,同事出差现场蹲了两周仍未复现!!!而没过几天,而远在千里之外的现场B出现了同样的问题,也只能暂时刷机等待复现。
操作系统
接下来是最后一个可能原因,操作系统可能完全挂了(panic),但产品没有串口终端、没有调试接口,这个原因更不好求证。我们的产品对外只有一个网口和几个状态灯,只能使用最原始的办法,点灯或者在网络接收中断中添加调试手段,当接收到特定网络包时,直接替换源mac后通过网口发送出来,这样能表明系统没挂,但由于现场复现周期变长,导入也不能立即见效,此时比较担心的是如果真是系统挂了,不知道触发原因,该如何定位?
四 分析定位
转机
事情迎来转机是同事的一次发现和现场C的出现。
在前文中,我们介绍了Xenomai的调度逻辑。如果一个高优先级任务(包括Xenomai内核实时任务)在某些触发条件下进入while(1)死循环,不释放CPU资源,会导致低优先级任务饿死,并使得Linux系统的所有输入输出无响应,表现为系统死机。经过应用同事的验证,这一逻辑是正确的。
然而,应用同事还发现,当一个低优先级任务(优先级为1)进入while(1)死循环后,高优先级的TCP/IP协议栈会在几分钟后失去响应,导致无法ping通。这一现象引起了我的关注,这个现象冲击着我对xenomai的认知,这种反常有问题。
拨云见雾
现场不复现,只能先分析这一反常的原因,反复测试后发现规律如下:
- 未启动while(1)低优先级实时任务时,系统正常运行,linux正常输入输出。
- 启动while(1)实时任务,linux Ping无响应,启动后的2~3分钟内,高优先级的TCP/IP协议栈正常,能ping通,ping响应时间<1ms。
- 之后高优先级的TCP/IP协议栈出现 ping不通,很长时间偶尔由ARP请求回复,ping响应时间>5s,持续几分钟。
- 最后系统彻底失去响应,无任何响应。
尽管异常表现与现场死机表现一致,但我们未能找到两者之间的直接联系,无法确凿地证明它们之间存在关联。那究竟是什么导致了这样的异常?
这是一个棘手的问题,启动while(1)低优先级实时任务后,由于linux得不到cpu资源,常规的linux调试分析手段均无效,没有硬件调试器,只能使用最原始方式,xenomai内核直接操作硬件IO来调试,把系统终端串口从板子上焊接引出。
由于ping帧经过网卡->rtnet网络协议栈(raw packet)->高优先级的TCP/IP协议栈任务,问题是否出在网络的某个环节上?为了验证网卡的正常工作状态,我们在网卡驱动中添加了收发调试信息,希望通过这种方式来确定网络路径是否异常。
- 网口接收中断中和发送接口添加打印,因为中断优先级最高。
- 打印不能使用常规linux
printk(),使用raw_console接口直接操作串口输出。
结果发现死机后,向板子发送广播帧,网卡有接收打印,说明网卡接收中断工作正常,但是没有发送打印,说明应用层没有调用发送。
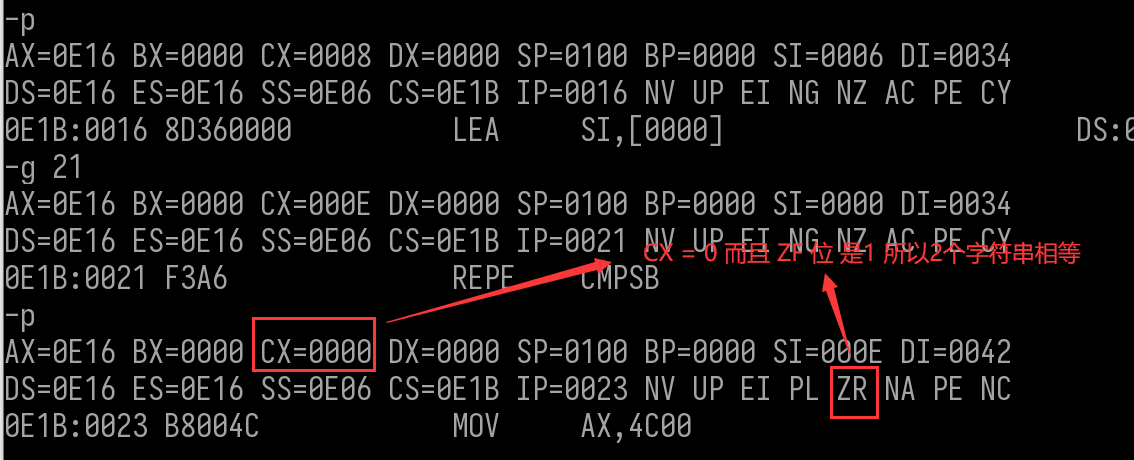
这时候就需要确认系统中各任务的具体状态,如果是正常的系统,我们从/proc/xenomai/下的就可以得到xenomai内核状态信息。但我们现在只有网络和串口输出接口,所以我们定义了一系列网络帧,网卡收到帧后解析,将系统信息通过串口打印出来,达到查看/proc/xenomai/的效果,解析-获取-打印均是在网卡中断中完成的,发现如下异常:
irq计数
调试发现,除网卡收发包中断计数还在增加外,系统timer中断增加很慢,几十秒才增加1。
IRQ CPU016: 616863165 [timer/0]32: 0 rtser150: 38 gpio4051: 2 gpio441027: 408313 [virtual]
##此处间隔了几秒IRQ CPU016: 616863165 [timer/0]32: 0 rtser150: 38 gpio4051: 2 gpio441027: 408313 [virtual]
Schedstat
结合xenomai状态定义,前后两次查看系统任务状态信息,发现cpu当前运行的是while(1)低优先级实时任务,此外只有网卡中断任务的上下文切换。
coreclk
应用层1ms的周期定时任务,已经超时上百秒,这显然不正常。
CPU SCHED/SHOT STATUS TIMEOUT INTERVAL NAME
0 27005/22425 21 - - [host-timer]
0 826283/0 1 - - [rrb-timer]
0 244/243 34 110s934ms44 1s410ms65u optional much
0 116/115 34 113s85ms189 3s netdbg_tiemr
现象结论
总结如下:
- 系统网络收发中断能正常响应,说明xenomai没有跑飞或挂死。
- 各任务状态正常,但系统调度异常,除网卡中断外没有发生任务上下文切换。
- Xenomai timer子系统异常:系统调度依赖的timer中断由于某种原因停止,各周期timer处于超时状态,timer回调得不到执行!!!
经过以上初步定位,可以确定问题出现在timer子系统中,为什么硬件timer中断几乎没有了?接着我们聚焦到xenomai最底层,添加调试信息,将每次写硬件timer操作时的各个时间记录下来,发现如下异常。
.4293209491 4293195842 13655
.4293284491 4293270854 13643
.4293359491 4293345841 13656
.4293434491 4293420847 13649
.4293509491 4293495851 13645
.4293584491 4293570843 13654
.4293659491 4293645841 13656
.4293734491 4293720844 13652
.4294034491 4294020845 13652
.4294109491 4294095841 13655
.4294184491 4294170841 13655
.4294259491 4294245842 13654
.4294334491 4294320838 13659
.4294409491 4294395843 13654
.4294484491 4294470847 13650
.4294559491 4294545844 13652
.4294634491 4294620842 13655
.4294709491 4294695850 13646
.4294784491 4294770851 13646
.4294859491 4294845842 13654
.4294934491 4294920845 13652
.4294934491 28527 4294905969
数值说明:
数值1,下一个最近到期timer的时间点
数值2,当前clocksoure时间值
数值3,当前时间与期望时间之间的差值(需要写入定时器的值)
实时任务while(1)条件下,系统失去响应的前一刻,clocksoure当前时间戳值由于某种原因突变了,导致计算的写入硬件timer的时间错误,所以才会出现很长时间才触发一次timer中断。
五 原因一
Xenomai框架图如下,在内核空间,在标准linux基础上添加一个实时内核Cobalt,通过Ipipe,使Cobalt内核在内核空间与linux内核并存,并把标准的Linux内核作为实时内核中的一个idle(优先级为-1)的进程在实时内核上调度。
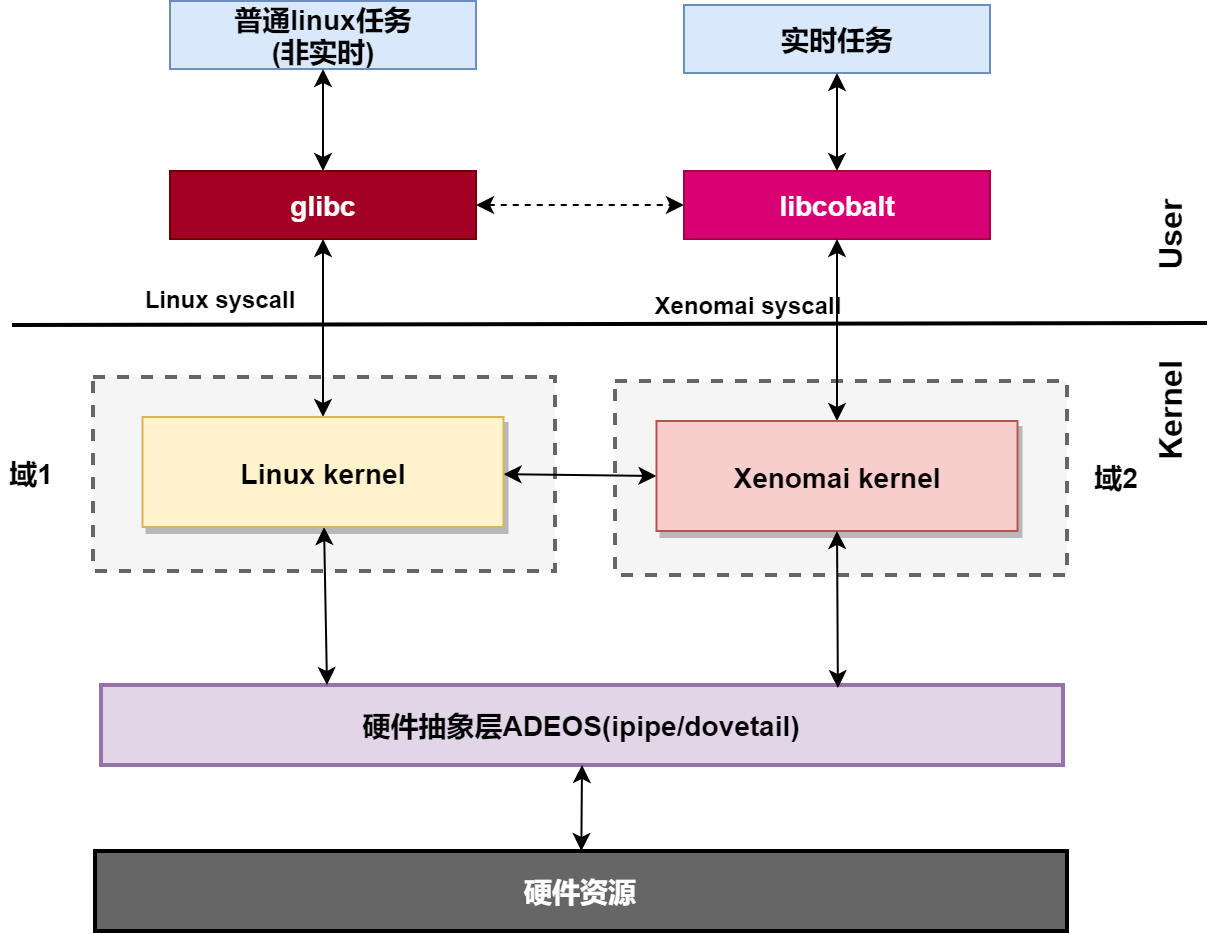
xenomai内核启动时,ipipe通过替换回调函数将原linux系统硬件timer作为xenomai 系统timer,由xenomai接管硬件,直接对层硬件timer编程。
而linux,由于linux退化为xenomai的idle任务,linux底层调度定时器变成xenomai timer子系统中的一个软件timer,原来由linux直接对层硬件timer编程变成了对xenomai 的软件hrtimer --- idle hrtimer编程。
详细信息请看本博客博文xenomai内核下Linux时钟工作流程
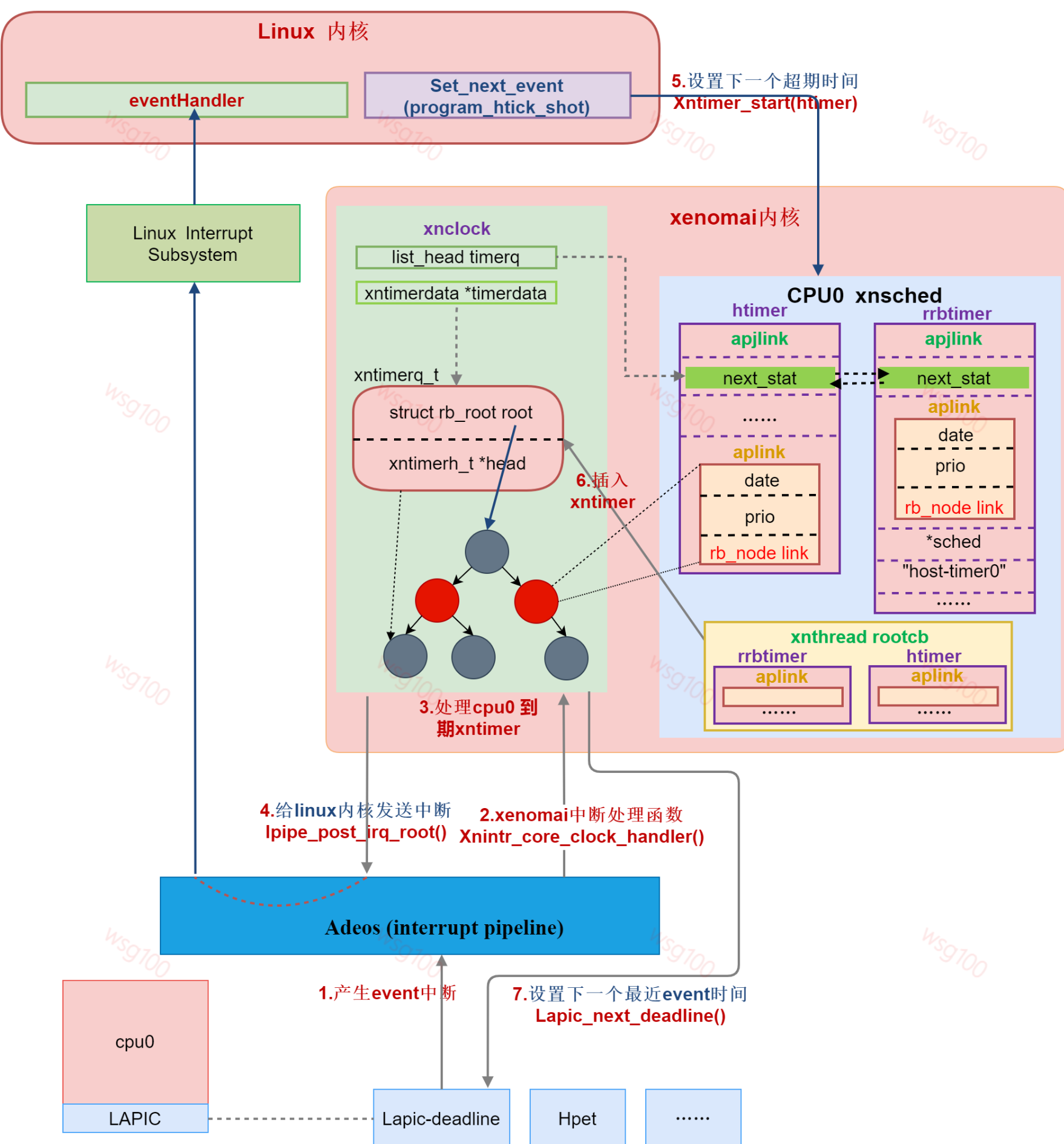
在操作系统中,时钟子系统的运行需要clocksource提供时间值和clokevent触发事件(中断),而应用程序的计时操作最终是通过这些底层定时中断来实现的。
为了减少高精度测量短时间的开销,Xenomai引入了64位高分辨率计数器。在x86架构上,这通常通过专门的rdtsc指令读取时间戳计数器完成。然而,在ARM处理器中,由于不直接提供用户空间可用的64位高精度计数器,Xenomai采用策略是读取系统内可用的任何高分辨率计数器来实现此功能。在这里,ipipe作为桥梁,屏蔽了底层硬件间的差异性,并向Xenomai内核提供了clocksource。
不同类型的硬件定时器具有不同的计数位宽(16位、32位或64位),这取决于具体的硬件设计。针对那些非原生64位的硬件,ipipe提供了一种机制:每次硬件timer溢出的周期内,系统会执行一次更新时间戳计数器(tsc)的操作,将它扩充到正确的64位格式上。这个更新操作由linux的一个软件定时任务完成。
/*arm/kernel/ipipe_tsc.c*/
void __ipipe_tsc_update(void)
{if (tsc_info.type == IPIPE_TSC_TYPE_DECREMENTER) {unsigned cnt = *(unsigned *)tsc_info.counter_vaddr;int offset = ipipe_tsc_value->last_cnt - cnt;if (offset < 0)offset += tsc_info.u.dec.mask + 1;ipipe_tsc_value->last_tsc += offset;ipipe_tsc_value->last_cnt = cnt;return;}/* Update last_tsc, in order to remain compatible with legacyuser-space 32 bits free-running counter implementation */WRITE_ONCE(ipipe_tsc_value->last_tsc, __ipipe_tsc_get() - 1);
}
我们用的这颗SOC所有硬件timer 计数器都是32位的,计数频率为25MHZ,因为硬件timer的计数器是32位的,32位25MHZ的频率过171秒就会溢出,这就要linux必须在每次溢出的周期内执行一次更新tsc。
系统实际使用的是timer1,ipipe防止32位timer溢出,更新64位Tsc的周期为171798 ms,如下:
...
[ 0.000000] clockevent source: timer2 at 25000000 Hz
[ 0.000026] sched_clock: 32 bits at 25MHz, resolution 40ns, wraps every 85899345900ns
[ 0.000050] I-pipe, 25.000 MHz clocksource, wrap in 171798 ms
[ 0.000059] I-pipe, __ipipe_tsc_get:0xffff0f00 tsc_area:0xc7efeee0,tsc_addr:0xc7efeefc
[ 0.000079] clocksource: ipipe_tsc: mask: 0xffffffffffffffff max_cycles: 0x5c40939b5, max_idle_ns: 440795202646 ns
[ 0.000096] I-pipe, 25.000 MHz clocksource, wrap in 8589 ms
[ 0.000108] clocksource: timer1: mask: 0xffffffff max_cycles: 0xffffffff, max_idle_ns: 76450417870 ns
[ 0.000114] clocksource: timer1 at 25000000 Hz
[ 0.000441] timer_probe: no matching timers found
[ 0.000868] Interrupt pipeline (release #1)
[ 0.000975] printk: console [rawcon-1] enabled
[ 0.001141] Console: colour dummy device 80x30
如果实时任务一直抢占linux,linux得不到运行,64位tsc在硬件timer溢出时间内得不到更新,就会导致tsc值异常,进一步xenomai timer子系统运行时间计算错误,设定硬件timer触发中断的时间错误,整个系统失去响应,结果就是前文看到的现象,timer不工作了,很久才触发一次中断。
到这,我们找到了低优先级实时任务while(1)条件下,为何高优先级任务也会失去响应的根本原因,但还是没有发现与现场死机之间的直接联系。
六 原因二
将两者联系起来的是现场C也出现死机,而且极易出现,因为现场C是一个设备组装调试现场,不像现场A和B那样的已经在生产现场,意味着现场C对我们有更大的容忍度,可以直接介入调试,我们在现场C上刷了启用xenomai看门狗的固件,同时保留了上文中的网络输出调试手段。
导入后没多久,复现了,此时系统正常,登录终端后发现xenomai看门狗触发了,查看内核日志触发看门狗的是RT_ThreadA。而这个任务A是一个网络系统升级任务,现场调试人员表示并没有升级操作。
博文看门狗(watchdog)机制及作用介绍 中我们提到,看门狗看管的是整个实时任务集合,不是某个特定任务,看门狗超时触发的时候会把当前 cpu 运行的任务 kill 掉,任何一个实时任务都有可能在watchdog触发这个时间点上,存在误伤,所以我们认为还是没有抓到真凶,等着下一次复。
[Xenomai] watchdog triggered on CPU #0 -- runaway thread 'RT_ThreadA' signaled
两天后一个晚上,又复现了,登录终端后发现xenomai看门狗触发了,查看内核日志触发看门狗的仍然是RT_ThreadA,这才引起我们的怀疑,经过对RT_ThreadA的深入分析后发现,由于该任务是一个tcp服务端,在客户端断开后,对read()调用的返回值判断错误,当read()返回0的时候,本应该调用close()来释放,但该同事当做超时直接返回了,导致了while(1)。
void* RT_ThreadA(void* arg) {int server_fd, new_socket;...// 创建套接字文件描述符server_fd = socket(AF_INET, SOCK_STREAM, 0);....// 监听连接请求listen(server_fd, 3);while (1) {// 接受连接请求new_socket = accept(server_fd, (struct sockaddr *)&address,(socklen_t*)&addrlen));while (1) {// 读取客户端数据int valread = read(new_socket, buffer, BUFFER_SIZE);// 错误处理:当read()返回0时,表示客户端已断开连接if (valread <= 0) {if (valread == 0) {close(new_socket);break; // 应该close()后退出循环,但原代码中直接continue了} ....}...}// 注意:为了模拟问题,这里省略了其他可能的错误处理和业务逻辑}
....
}
到此,一切合理,但还有一个疑惑,现场调试人员表示并没有升级操作🤣,直到后来现场调试人员提到他们在调试其他类型的设备B,一切豁然开朗。
由于设备B刚上市,出现了设备A与设备B在一个网络里共同工作的场景,公司为了统一产品的后台工具,其中很多设备的调试及升级使用的是同一TCP端口,而出问题的设备A这个产品并不具备这样的调试功能,仅有升级接口,后台工具扫描链接了设备A,导致设备A中的RT_ThreadA BUG暴露。
现场A和现场B的网络很庞大,所以维护人员使用后台工具查看设备B运行信息,并未发现百米外的另一个设备A因为该操作而死机。
到此心中阴霾尽散,唯有豁然开朗的畅快!
七 解决
修复RT_ThreadA 的BUG,以后开发xenomai任务可以通过以下方式去尽早暴露或避免。
- 应用层面
xenomai设计是不允许实时任务长时间占用CPU的,为方便debug这类应用异常,提供了内核看门狗检测功能。所以在实时软件开发阶段,开启watchdog可以尽早暴露实时应用潜在的出错或无限循环问题,避免软件发布后产生严重后果。
- 内核层面
- 内核开启xenomai看门狗。
- 如果不开启xenomai看门狗,为避免该情况发生时,保证实时任务的正常调度,需要将属于低优先级的linux 的周期更新tsc操作,迁移到xenomai上下文,由xenomai完成。由于该问题发生条件需同时满足ipipe+ARMv7(32位)+xenomai watchdog disable+实时任务while(1)不释放cpu才能出现,ipipe也将随着时间慢慢退出,没有向xenomai社区提交补丁。
八 结语
这个问题前后跟踪多月,此番波折,终成磨砺心智的宝贵历程。
![[Paper Reading] StegoType: Surface Typing from Egocentric Cameras](https://img2024.cnblogs.com/blog/1067530/202412/1067530-20241226162638553-336090645.png)