|
解决方案
|
设计思路
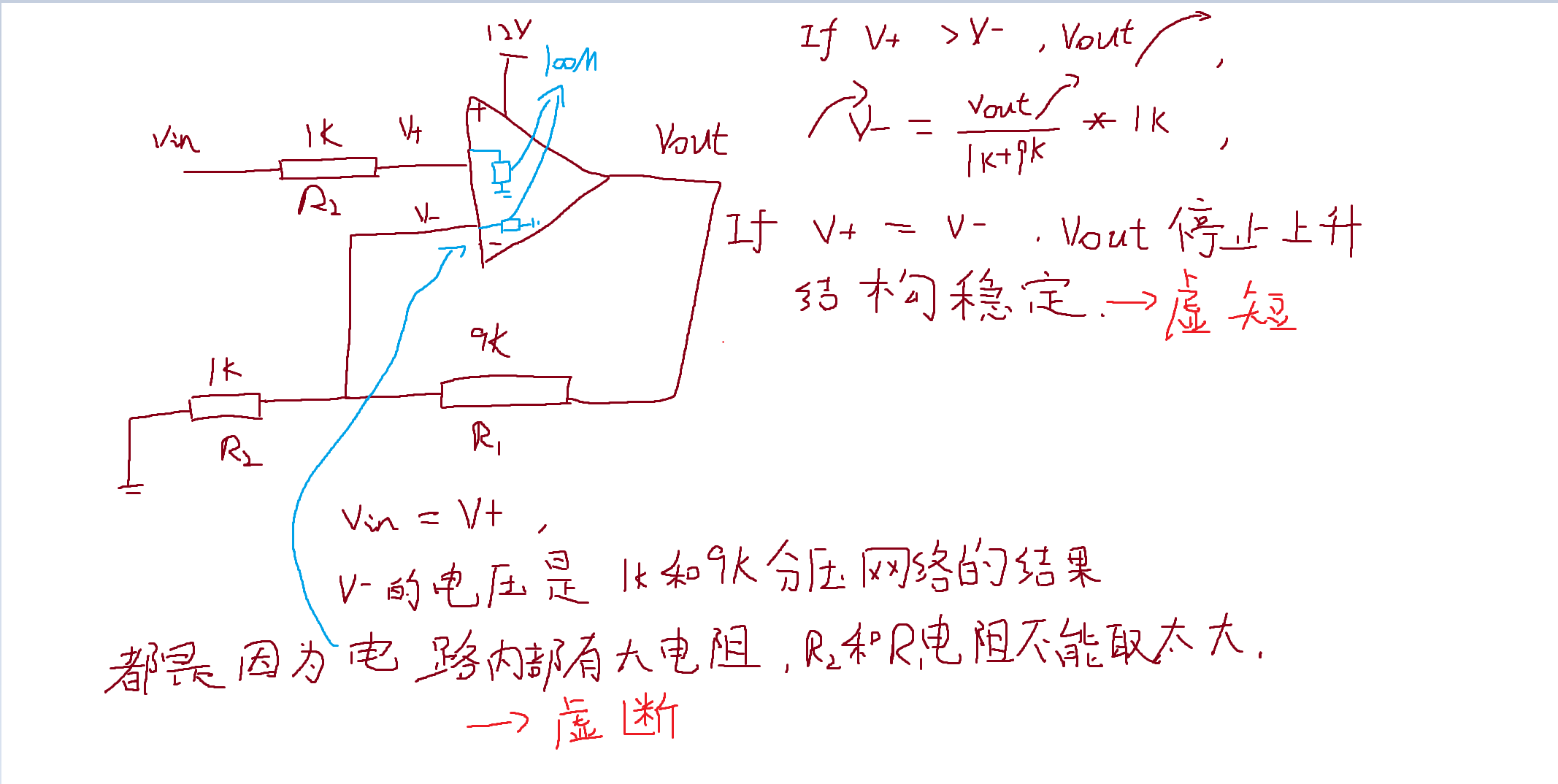
1、数据探索:初步了解数据集的结构和特征,检查数据的完整性和分布。
2、数据预处理:对数据进行标准化处理,以消除不同量纲的影响。
3、特征选择:分析各特征与目标变量的相关性,选择对预测结果影响较大的特征。
4、模型选择:根据目标变量的性质(分类或回归),选择合适的机器学习模型。
5、模型训练与评估:训练模型并使用交叉验证评估模型的泛化能力。
6、结果分析:分析模型的预测结果,评估模型性能。
实现步骤
1、导入数据集:使用pandas读取Excel文件中的数据。
2、数据探索:使用.head()和.info()方法查看数据的基本信息。
3、数据可视化:使用seaborn的pairplot方法展示特征之间的关系。
4、数据预处理:使用StandardScaler对特征进行标准化处理。
5、划分数据集:使用train_test_split将数据集划分为训练集和测试集。
6、模型训练:如果目标变量是分类的,使用RandomForestClassifier。
如果目标变量是回归的,使用RandomForestRegressor。
7、交叉验证:使用cross_val_score评估模型的泛化能力。
8、预测与评估:
对测试集进行预测。
如果是分类问题,使用classification_report和confusion_matrix评估模型。
如果是回归问题,计算MSE、RMSE、MAE和R²分数。
9、结果分析:根据评估指标分析模型性能,讨论可能的改进方向。
|
|
代码
|
# 导入必要的库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score, precision_score, recall_score, f1_score
# 1. 导入数据集并读取前6条数据,返回数据信息
data = pd.read_excel('BP_R_Data.xlsx')
print(data.head(6))
print(data.info())
# 2. 数据可视化处理
sns.pairplot(data)
plt.show()
# 3. 数据预处理,并将原始数据集划分为训练集和测试集
X = data.drop(['y'], axis=1)
y = data['y']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 4. 选择机器学习算法进行拟合
rf = RandomForestClassifier(random_state=42)
rf.fit(X_train, y_train)
# 交叉验证
scores = cross_val_score(rf, X_scaled, y, cv=5)
print("交叉验证分数:", scores)
# 5. 预测结果分析及可视化
y_pred = rf.predict(X_test)
# 绘制混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
# 分类报告
print(classification_report(y_test, y_pred))
# 计算分类模型的性能指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
print("精度 (Accuracy):", accuracy)
print("查准率 (Precision):", precision)
print("查全率 (Recall):", recall)
print("F1值 (F1 Score):", f1)
# 保存模型,如果需要的话
# from joblib import dump, load
# dump(rf, 'random_forest_model.joblib') |