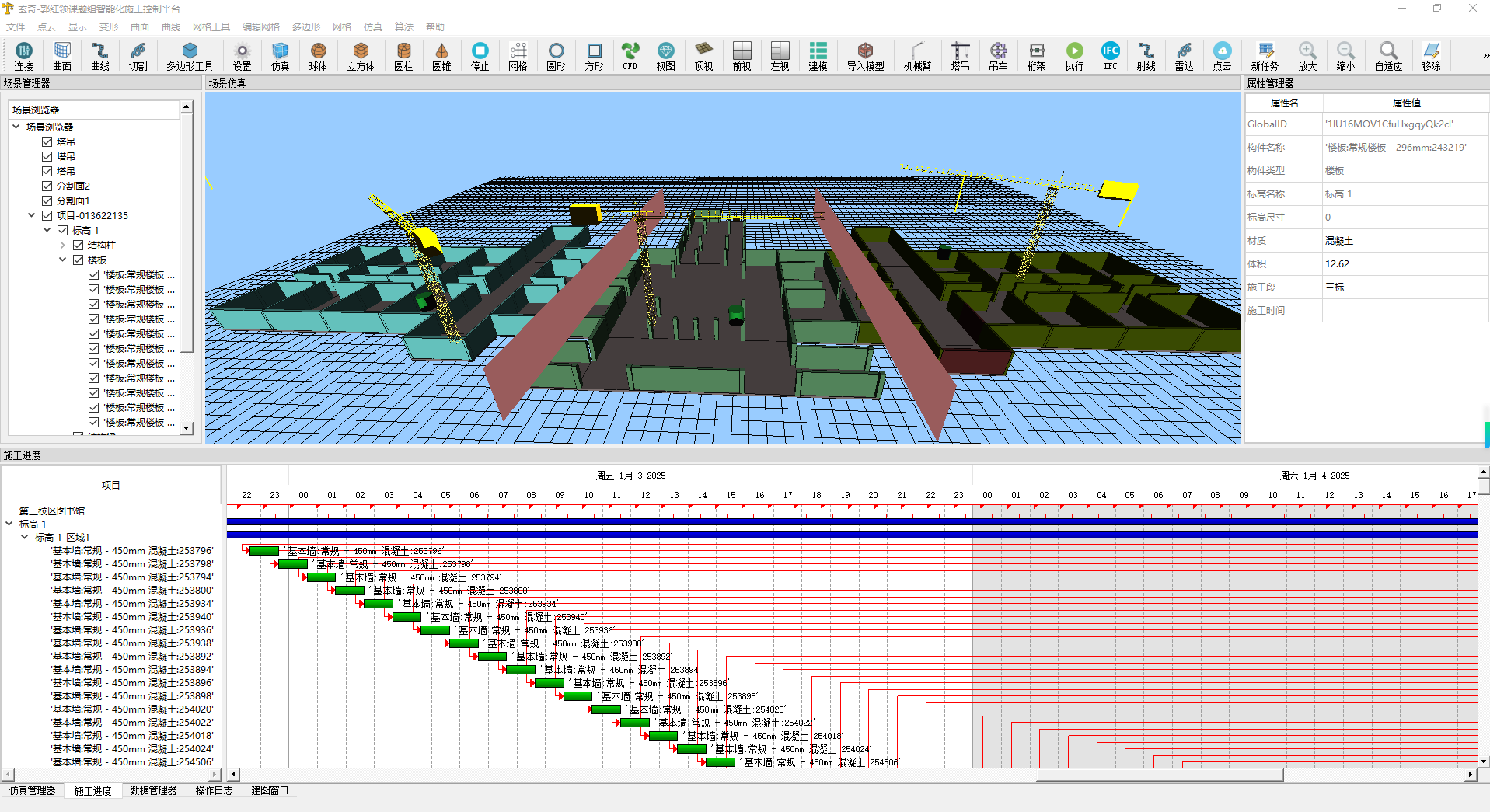
OpenCL设备端并行执行内核
Vortex存储库的tests/OpenCL目录中有OpenCL测试程序。OpenCL程序分为主机代码[cc|cpp]和设备代码kernel.cl。
OpenCL通过在设备端并行执行内核来加快速度。在tests/opencl/sgemm中的代码作为一个具体的例子。代码经过了轻微修改,使差异更加清晰。
1)展示主机上运行的main.cc中的matmul函数,代码如下。
void matmul(const float* A,
const float* B,
float* C,
int N) {
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
float acc = 0.0f;
for (int k = 0; k < N; ++k) {
acc += A[i + k * N] * B[k + j * N];
}
C[i + j * N] = acc;
}
}
}
2)在与上述功能相对应的设备上,运行kernel.cl的程序,代码如下。
__kernel void sgemm(__global const float* A,
__global const float* B,
__global float* C,
int N) {
const int i = get_global_id(0);
const int j = get_global_id(1);
float acc = 0.0f;
for (int k = 0; k < N; ++k) {
acc += A[i + k * N] * B[k + j * N];
}
C[i + j * N] = acc;
}
OpenCL通过在设备端并行执行内核来优化加速,如图1-41所示。

图1-41 OpenCL通过在设备端并行执行内核来加快速度