Linux内核定义的TCP首部的结构体tcphdr如下图所示。你会发现一个奇怪的问题:处理器使用大端字节序时字节内部的位域定义顺序和处理器使用小端字节序时相反,但是位域的字节顺序相同。如果你能把这个问题解释清楚,那么说明你已经完全掌握字节序和比特序,不需要阅读这篇文章。

1. 字节序和比特序
字节序是指多字节数据(例如C语言中的short、int和long类型)在计算机内存中存储或者网络传输时字节的排列顺序。
字节序分为大端(big-endian)序和小端(little-endian)序。大端序把多字节数据的高字节存放在内存的低地址,把数据的低字节存放在内存的高地址。这种排列方式和数据用字节表示时的书写顺序一致,符合人类的阅读习惯。除了处理器以外,其它场合几乎都使用大端字节序,例如网络传输和文件存储。
小端序把多字节数据的低字节存放在内存的低地址,把数据的高字节存放在内存的高地址。处理器先处理低位,效率比较高,因为计算都是从低位开始的,例如加法运算,如果从高位开始,不知道低位是否产生进位。
比特序是一个字节的8个二进制位的顺序。通常处理器使用的比特序和字节序保持一致,使用大端字节序的时候比特序是大端序,也就是从高位到低位存放;使用小端字节序的时候比特序是小端序,也就是从低位到高位存放。
例如16进制的32位整数0x12345678使用两种字节序在内存中的存储顺序如下。
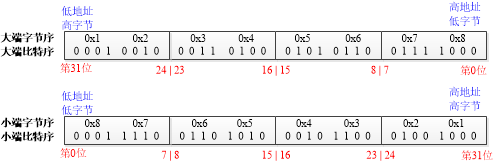
x86处理器使用小端字节序和小端比特序,ARM64处理器的字节序是可配置的。
ARM64架构的GCC编译器提供机器相关选项“-mbig-endian”和“-mlittle-endian”。选项“-mbig-endian”生成大端序代码,为“aarch64_be--”目标配置GCC的时候这个选项是默认的。选项“-mlittle-endian”生成小端序代码,为“aarch64--”目标配置GCC的时候这个选项是默认的。
1.1. 主机字节序和网络字节序
主机字节序是处理器的字节序,网络字节序是多字节数据在网络上的字节传输顺序。为了保证数据在不同主机之间传输时能够被正确解释,IP协议的规范RFC 791规定发送多字节数据的时候先发送高字节,也就是规定网络字节序是大端字节序。以太网是现实世界中最普遍的一种计算机网络,先传输高字节,但是每个字节先传输低位。
网卡把从网络收到的报文写到内存的时候,把每个字节的比特序转换成处理器使用的比特序。软件读取报文中的多字节数据,需要把字节序从网络字节序转换为主机字节序。网卡只负责转换每个字节的比特序,不负责转换字节序,因为网卡不知道多字节数据的起始位置和长度,只有软件才知道。
发送报文的时候,软件需要把报文中的所有多字节数据从主机字节序转换为网络字节序。网卡从内存读取报文、把报文发送到网络的时候,把每个字节的比特序转换成网络使用的比特序。
1.2. glibc库提供的字节序编程接口
可以使用宏__BYTE_ORDER判断字节序:如果__BYTE_ORDER等于__BIG_ENDIAN,那么使用大端字节序;如果__BYTE_ORDER等于__LITTLE_ENDIAN,那么使用小端字节序。__PDP_ENDIAN是PDP字节序(PDP-Endian),又称为中间序(Middle-Endian)或者混合序(Mixed-Endian),是DEC PDP-11处理器使用的字节序,是小端序和大端序的混合体,32位整数的存储方式是高16位和低16位使用大端序、但16位内部使用小端序。现在很少使用PDP字节序,我们不需要关注它。
可以使用宏BYTE_ORDER判断字节序:如果BYTE_ORDER等于BIG_ENDIAN,那么使用大端字节序;如果BYTE_ORDER等于LITTLE_ENDIAN,那么使用小端字节序。
可以使用GNU C扩展的预定义宏__BYTE_ORDER__判断字节序,
它的值可能是__ORDER_LITTLE_ENDIAN__、__ORDER_BIG_ENDIAN__或者__ORDER_PDP_ENDIAN__。
函数htonl()把32位整数从主机字节序转换为网络字节序,函数htons()把16位整数从主机字节序转换为网络字节序。
函数ntohl()把32位整数从网络字节序转换为主机字节序,函数ntohs()把16位整数从网络字节序转换为主机字节序。
下面这些函数把16、32或64位整数在主机字节序和大/小端字节序之间转换。
(1) htobe16()、htobe32()、htobe64()、htole16()、htole32()和htole64()。
(2) be16toh()、be32toh()、be64toh()、le16toh()、le32toh()和le64toh()。
1.3. Linux内核提供的字节序编程接口
如果定义了宏__BIG_ENDIAN,那么应该使用大端字节序。如果定义了宏__LITTLE_ENDIAN,那么应该使用小端字节序。
如果定义了宏__BIG_ENDIAN_BITFIELD,那么位域应该使用大端字节序。如果定义了宏__LITTLE_ENDIAN_BITFIELD,那么位域应该使用小端字节序。
定义使用大端字节序的整数的时候,应该使用__be16、 __be32和__be64这些类型。__be16是__u16的别名,__be32是__u32的别名,__be64是__u64的别名,好处是名字可以提示你使用大端字节序。
定义使用小端字节序的整数的时候,应该使用__le16、__le32和__le64这些类型。__le16是__u16的别名,__le32是__u32的别名,__le64是__u64的别名,好处是名字可以提示你使用小端字节序。
宏htonl()把32位整数从主机字节序转换为网络字节序,宏htons()把16位整数从主机字节序转换为网络字节序。
宏ntohl()把32位整数从网络字节序转换为主机字节序,宏ntohs()把16位整数从网络字节序转换为主机字节序。
__constant_htonl()、__constant_htons()、__constant_ntohl()和__constant_ntohs()这4个宏的参数是常数。
下面这些宏把16、32或64位整数在处理器字节序和大/小端字节序之间转换。
(1) cpu_to_be16()、cpu_to_be32()、cpu_to_be64()、cpu_to_le16()、cpu_to_le32()和cpu_to_le64()。
(2) be16_to_cpu()、be32_to_cpu()、be64_to_cpu()、le16_to_cpu()、le32_to_cpu()和le64_to_cpu()。
下面这些宏把指针指向的16、32或64位整数在处理器字节序和大/小端字节序之间转换,返回转换后的值,不修改指针指向的内存。
(1) cpu_to_be16p()、cpu_to_be32p()、cpu_to_be64p()、cpu_to_le16p()、cpu_to_le32p()和cpu_to_le64p()。
(2) be16_to_cpup()、be32_to_cpup()、be64_to_cpup()、le16_to_cpup()、le32_to_cpup()和le64_to_cpup()。
原创 微信号szyhb1981 Linux驿站
![[Windows/虚拟化/OS] WSL(Windows Subsystem for Linux)技术](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)