正如你在课程的第一周所看到的,训练LLMs需要大量的计算资源。完整的微调不仅需要内存来存储模型,还需要在训练过程中使用的各种其他参数。
即使你的计算机可以容纳模型权重,最大模型的权重现在已经达到几百GB,你还必须能够为优化器状态、梯度、前向激活和训练过程中的临时内存分配内存。这些额外的组件可能比模型大数倍,很快就会变得太大,难以在消费者硬件上处理。

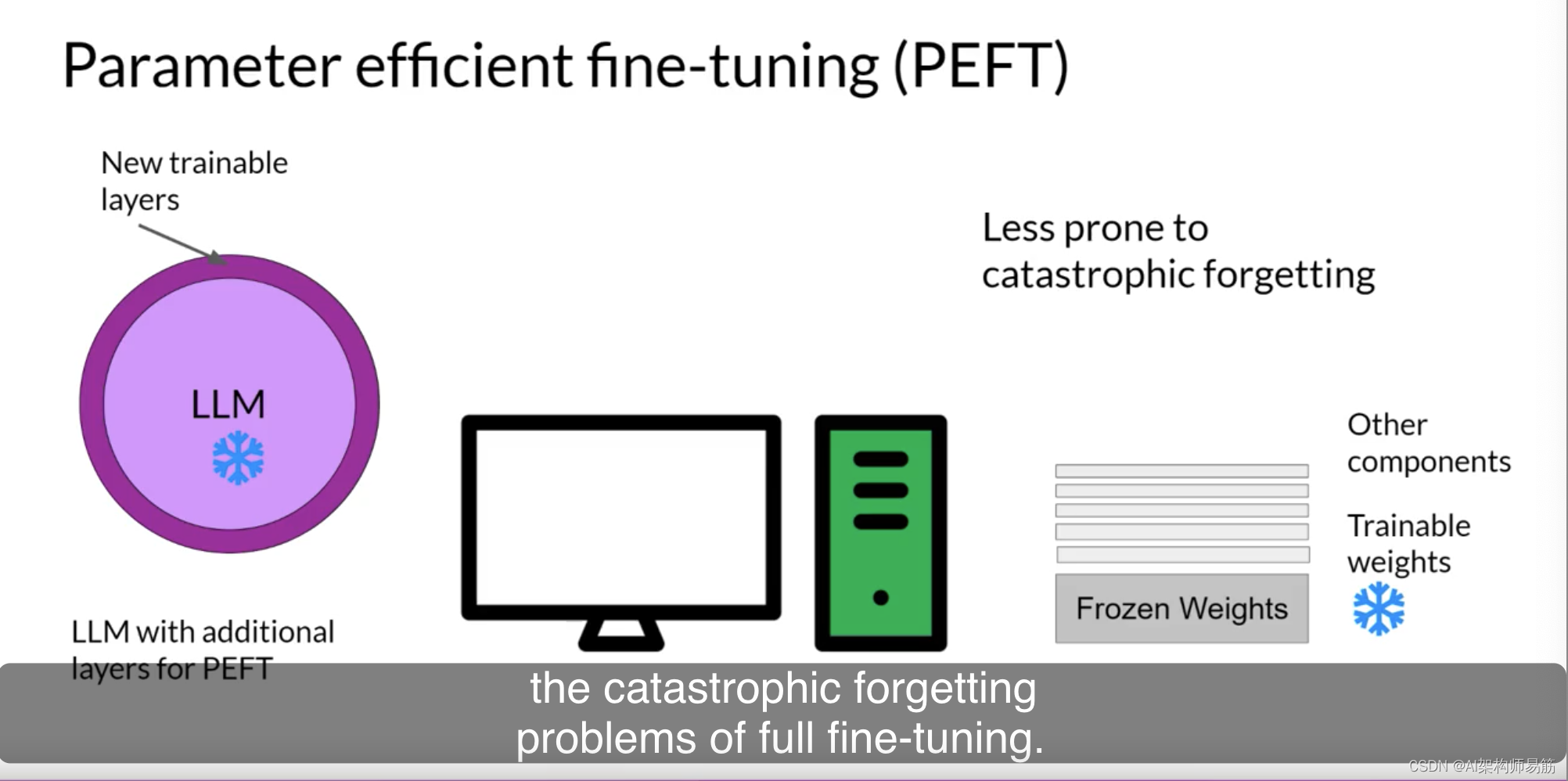
与完整的微调不同,完整微调会在监督学习期间更新每个模型权重,而参数高效微调方法仅更新一小部分参数。
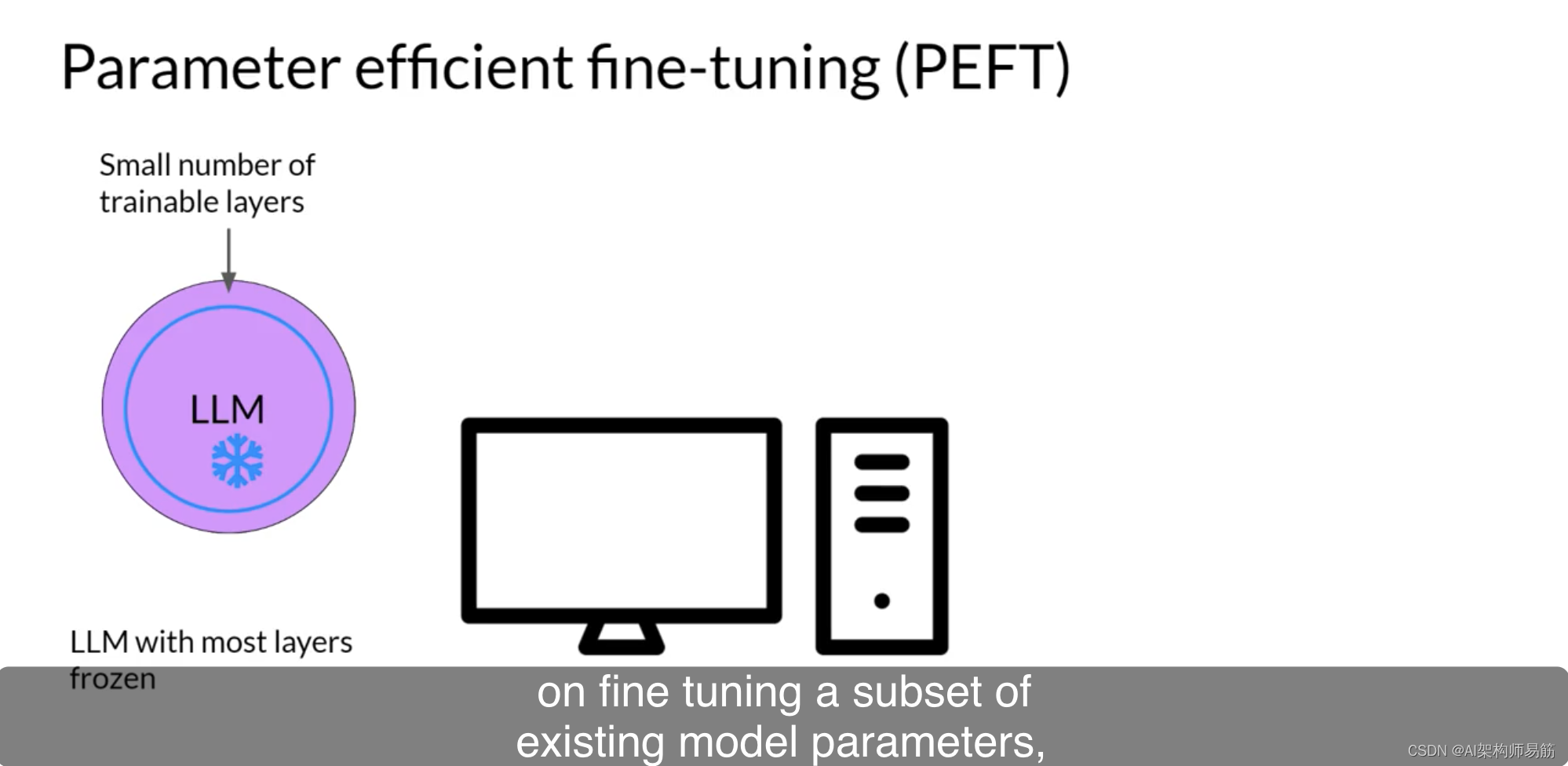
一些路径技术会冻结大部分模型权重,并专注于微调现有模型参数的子集,例如特定层或组件。
其他技术根本不会触及原始模型权重,而是添加少量新参数或图层,并仅对新组件进行微调。
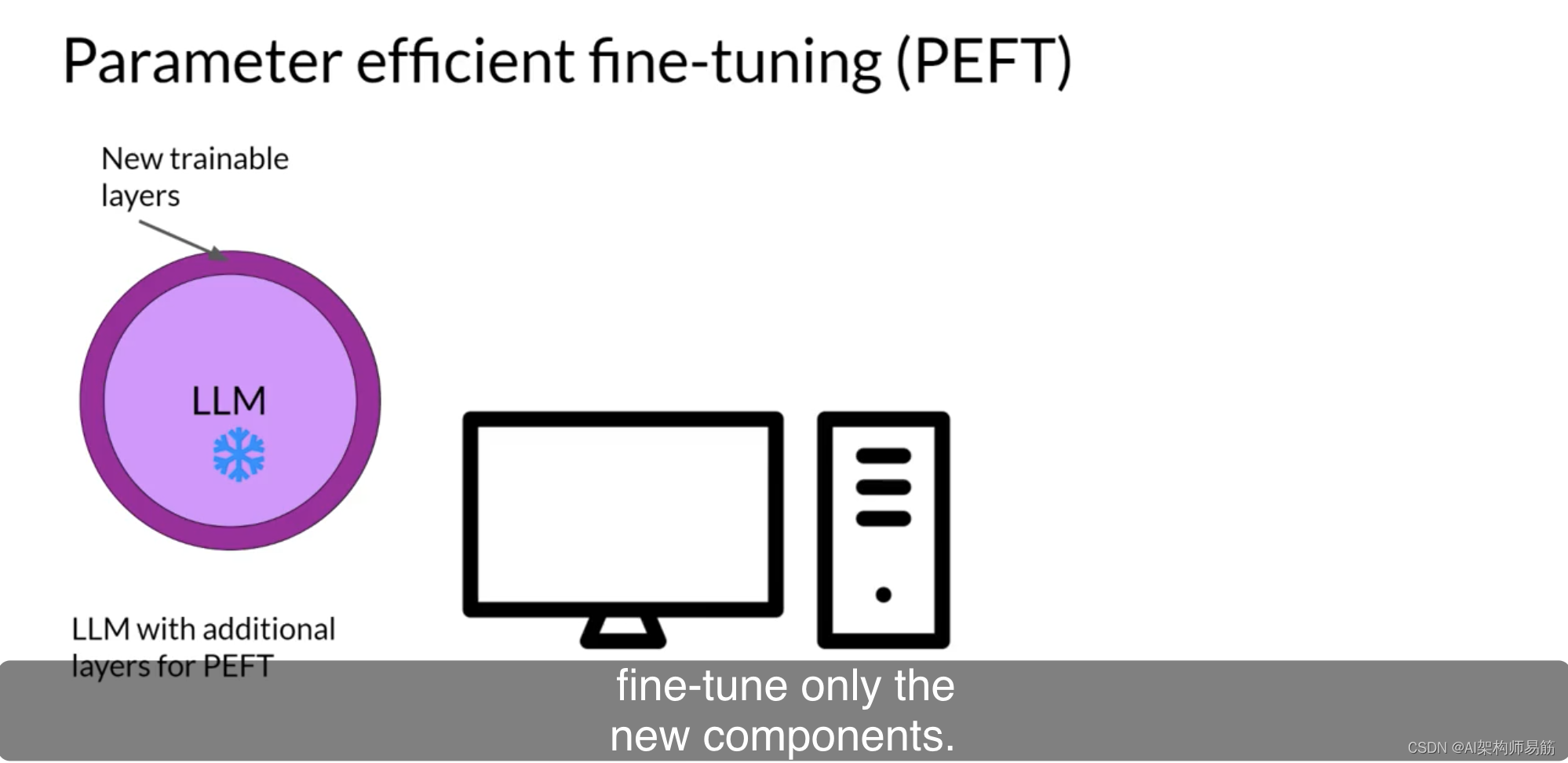
使用PEFT,大多数甚至全部LLM权重都被保持冻结。因此,训练的参数数量要比原始LLM中的参数数量小得多。在某些情况下,仅占原始LLM权重的15-20%。这使得训练的内存需求更加可管理。
实际上,PEFT通常可以在单个GPU上执行。而且,由于原始LLM只是稍作修改或保持不变,PEFT对于完整微调的灾难性遗忘问题不太容易发生。
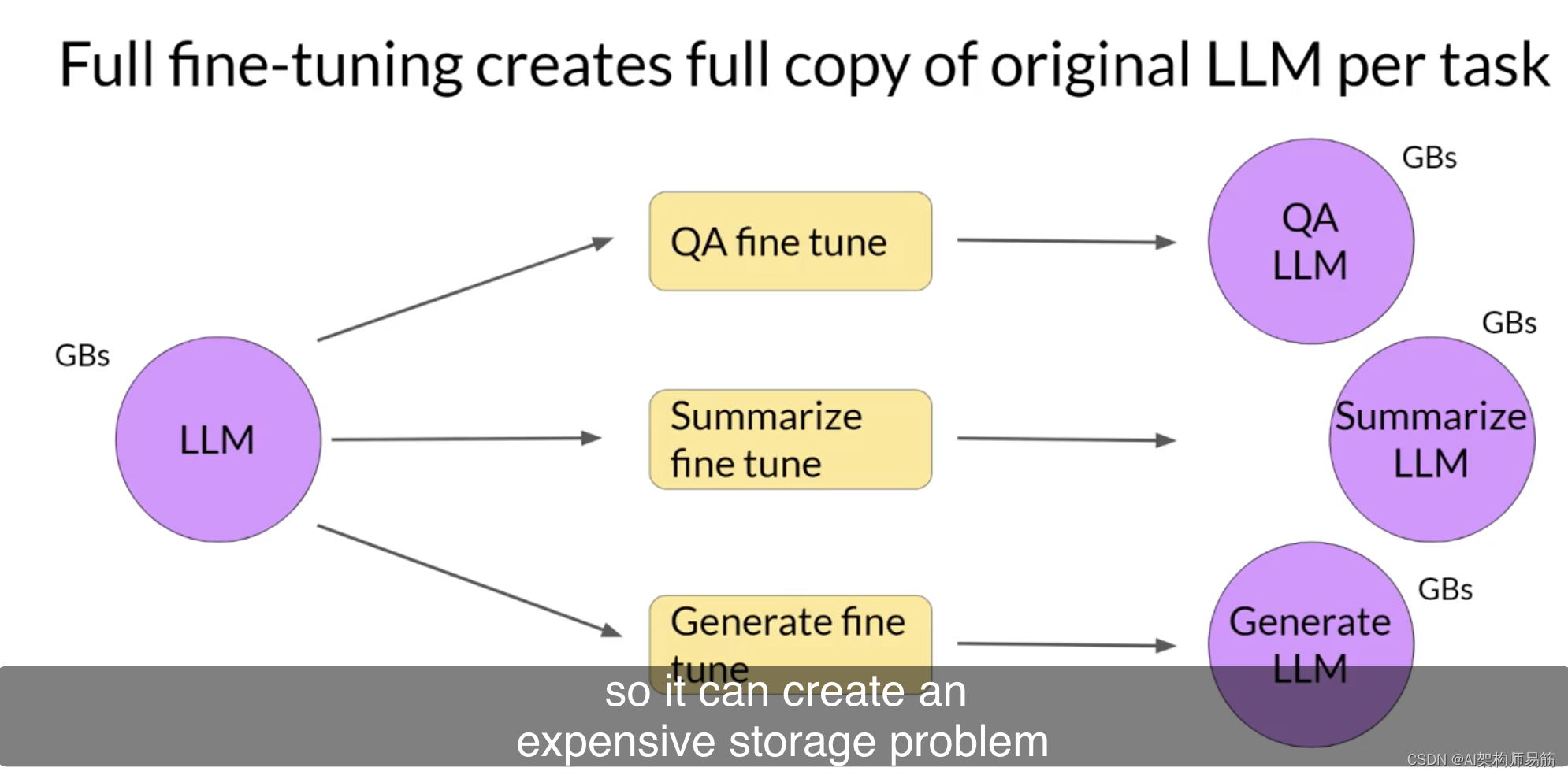
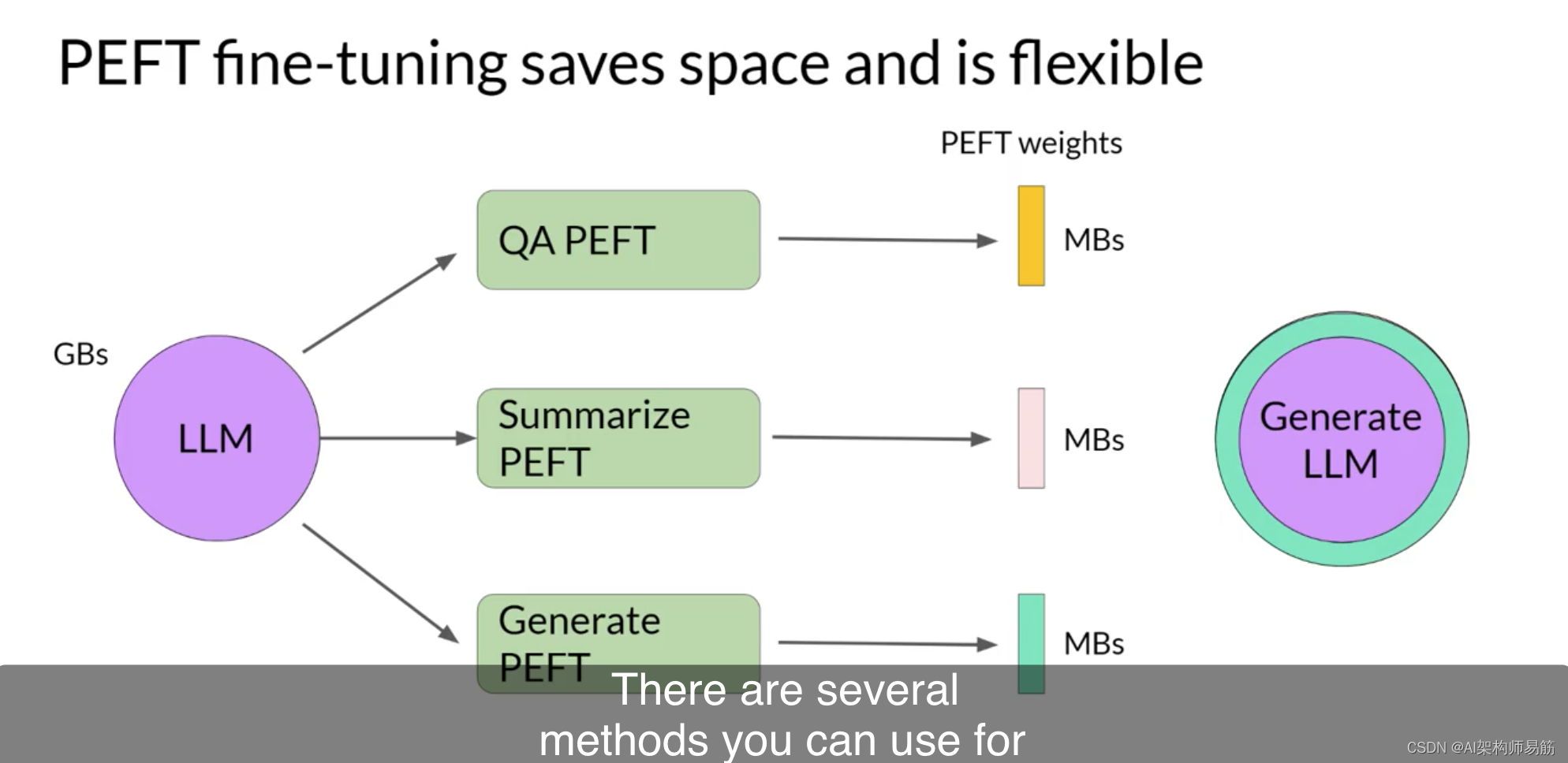
完整微调会为你训练的每个任务产生一个新版本的模型。这些模型的大小与原始模型相同,因此如果你为多个任务进行微调,可能会导致昂贵的存储问题。
让我们看看如何使用PEFT来改善这种情况。通过参数高效微调,你只训练少量权重,从而在整体上获得更小的占用空间,具体取决于任务,可能仅为几兆字节。
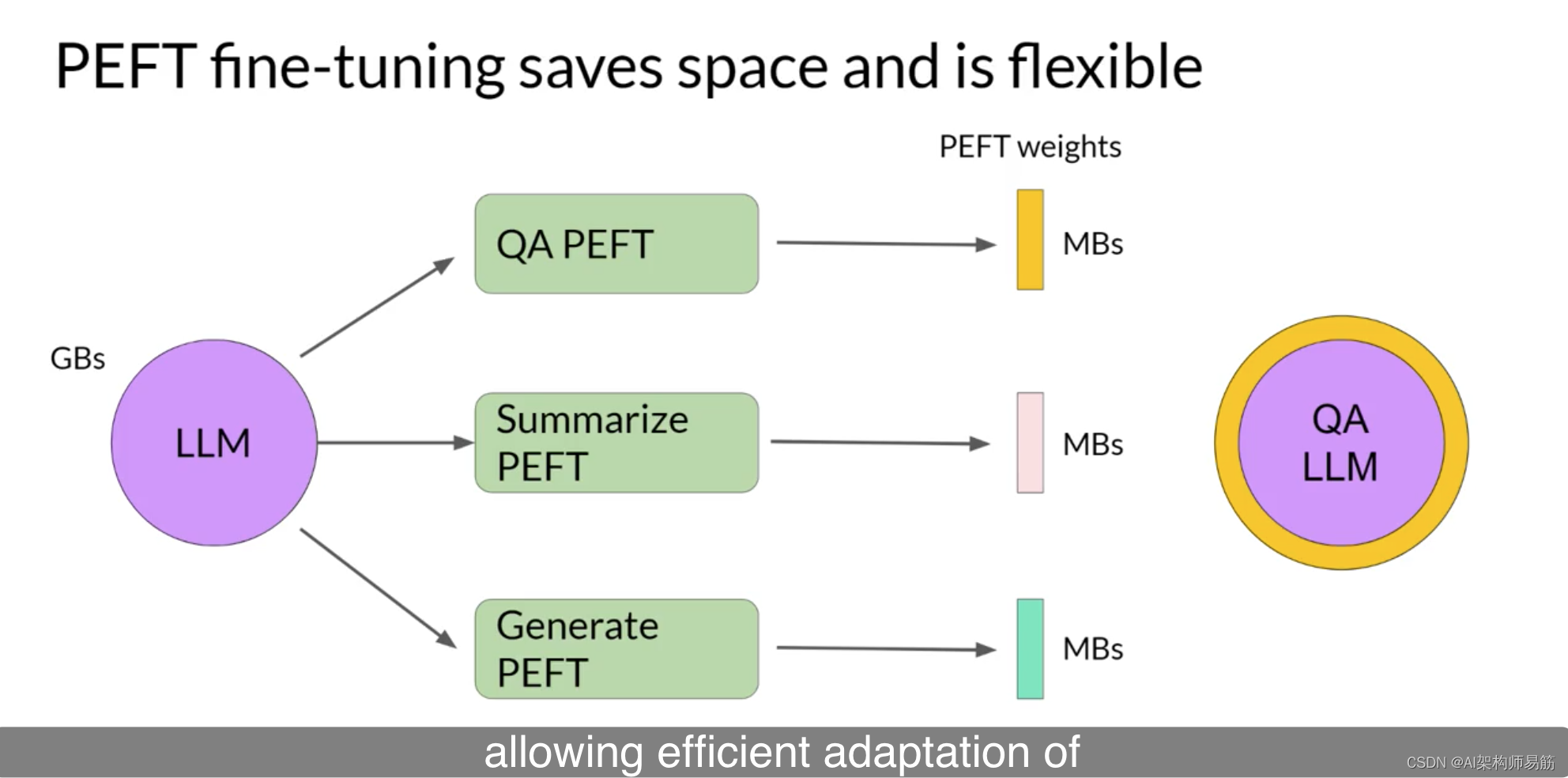
新的参数与原始LLM权重结合进行推理。PEFT权重会针对每个任务进行训练,并且可以在推理时轻松替换,
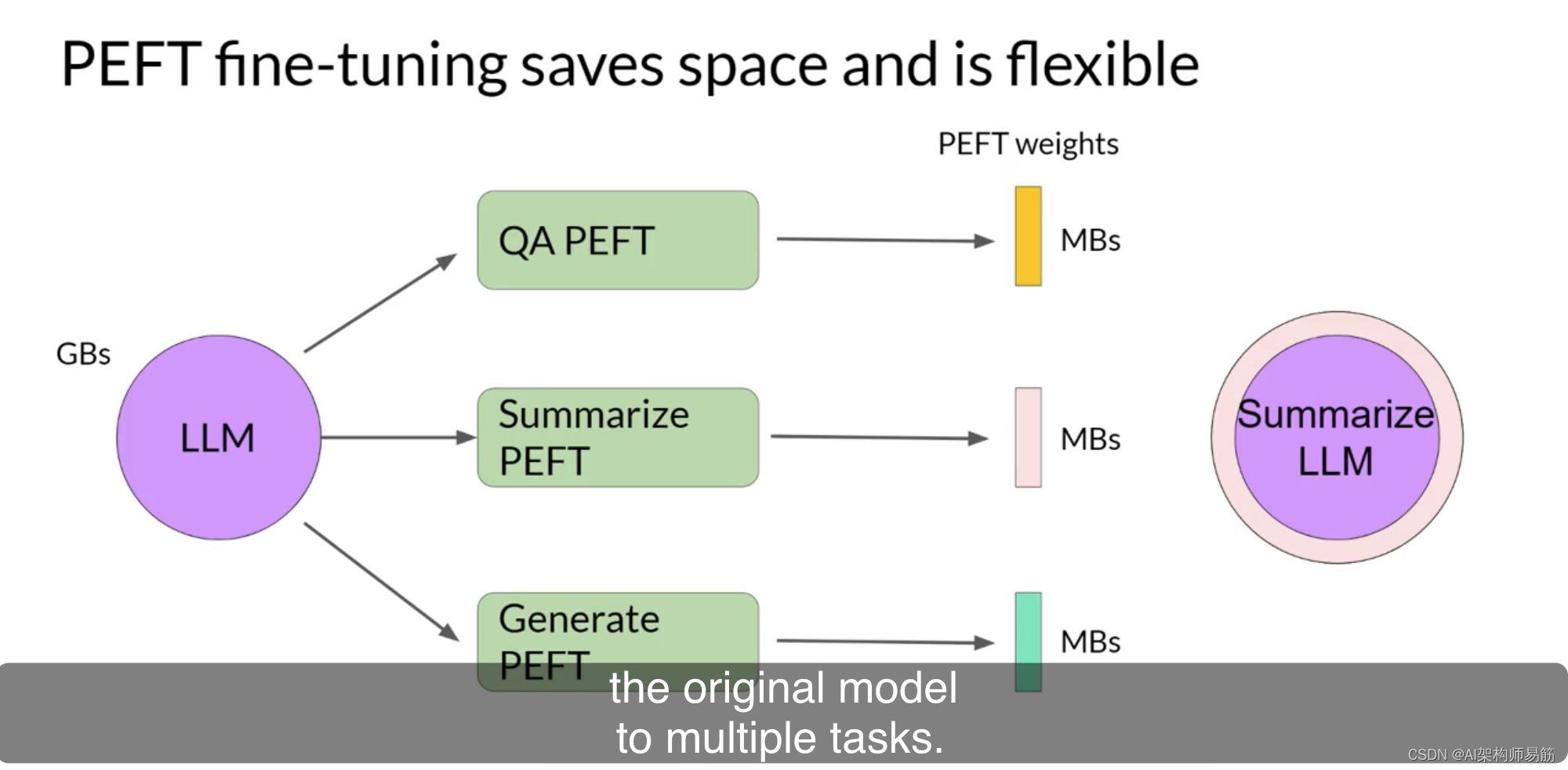
从而实现将原始模型高效地适应多个任务。
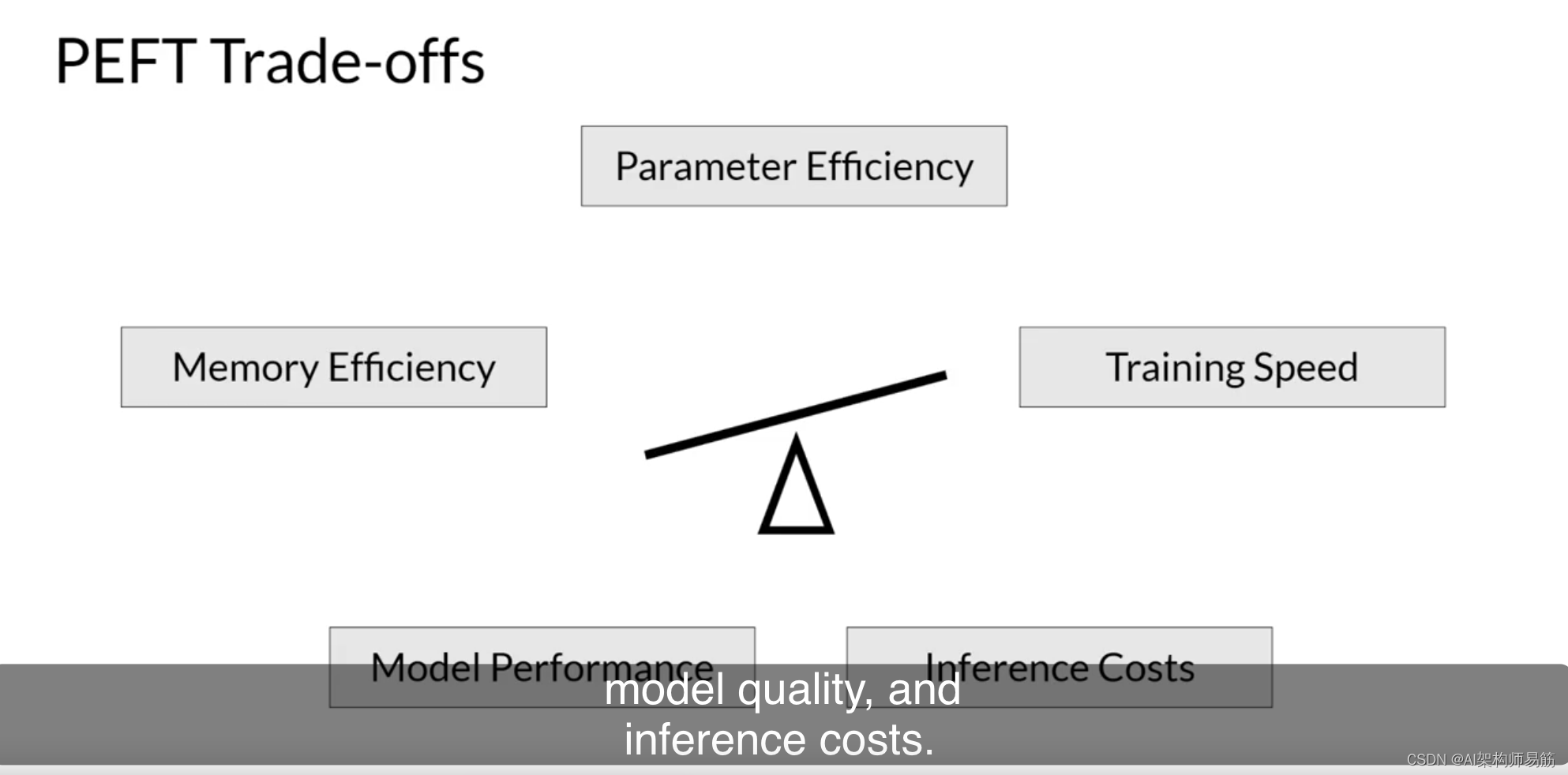
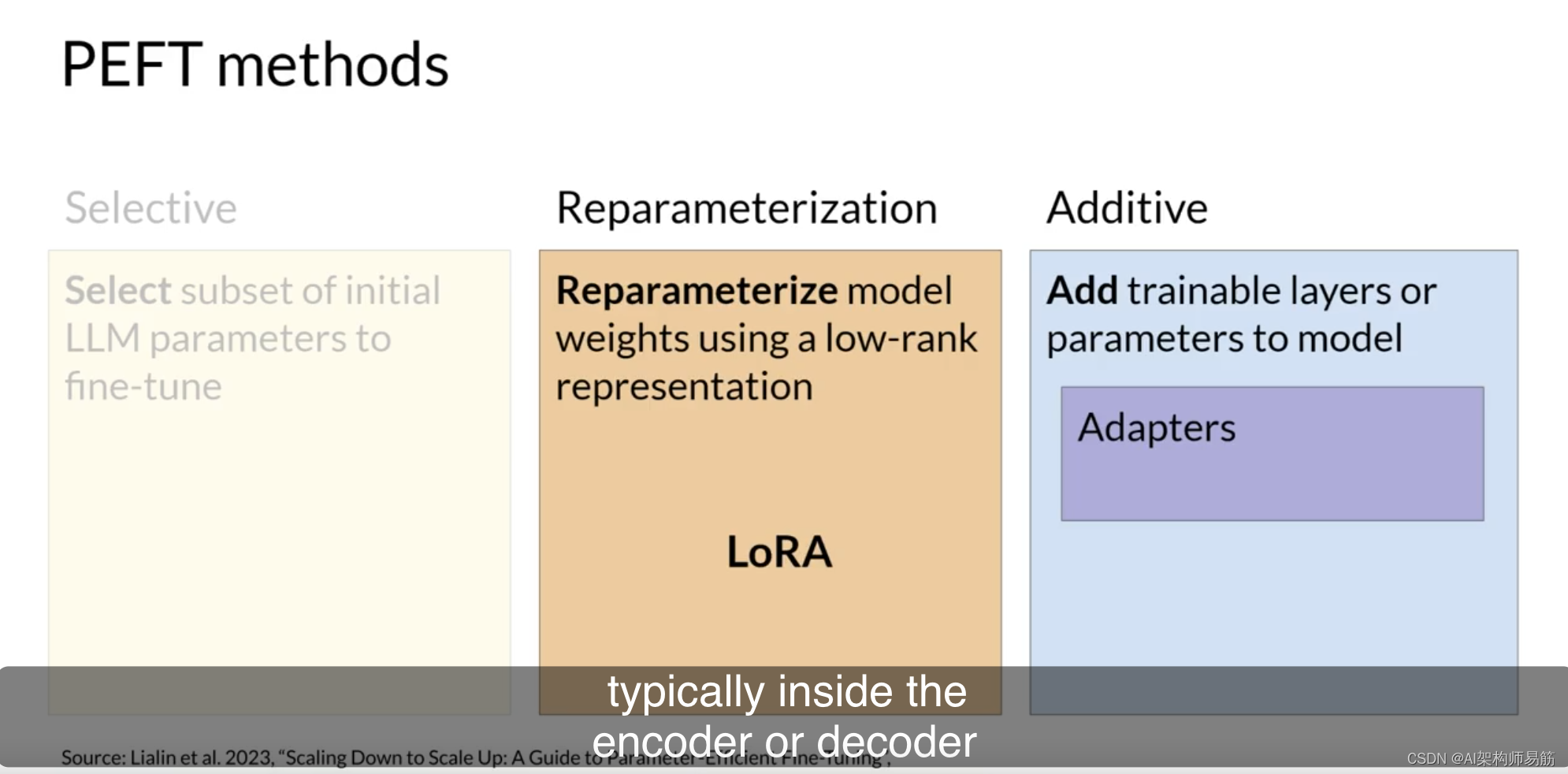
有几种方法可以用于参数高效微调,每种方法在参数效率、内存效率、训练速度、模型质量和推理成本方面都存在权衡。
让我们来看一下三种主要类别的PEFT方法。
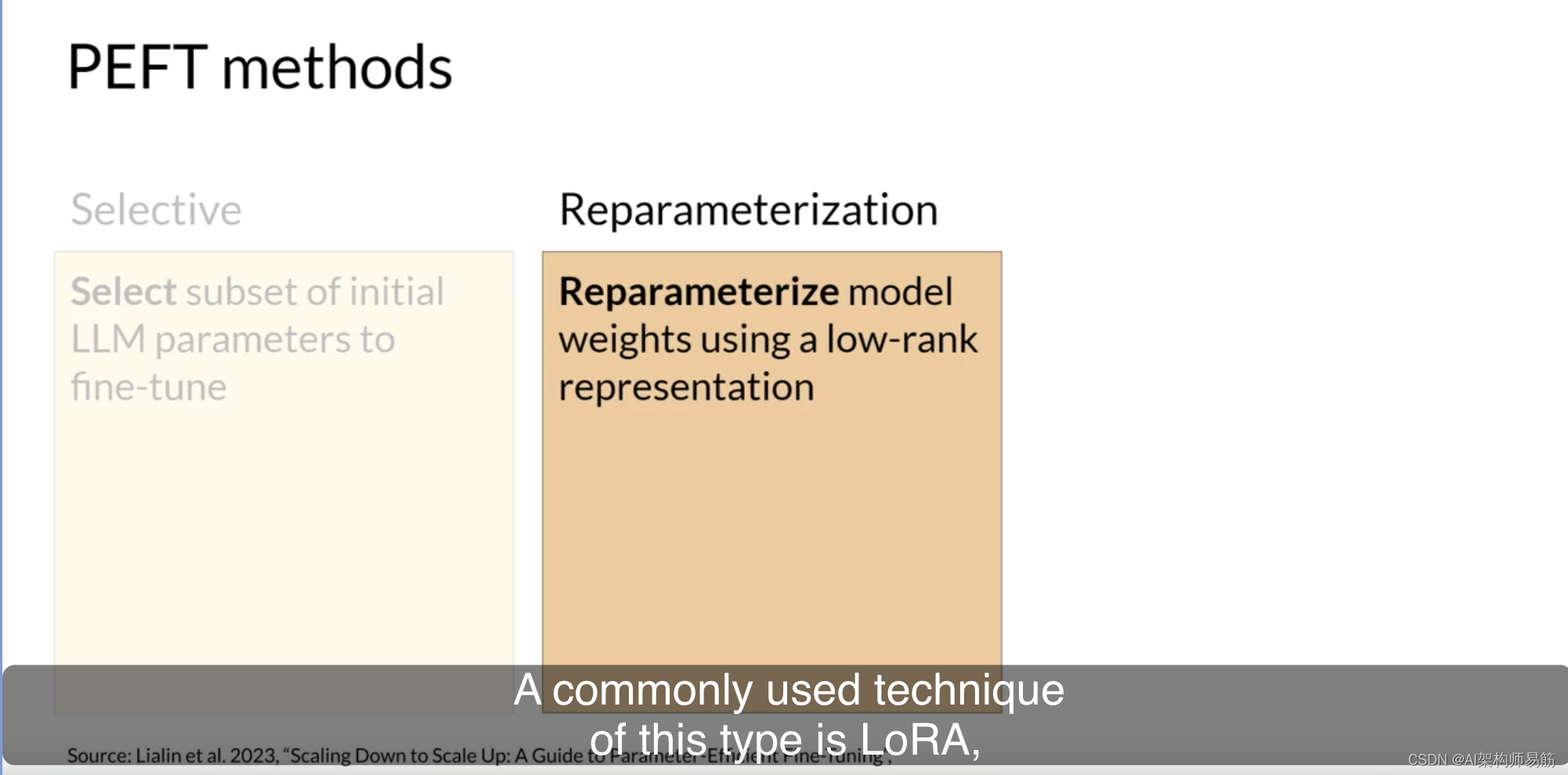
选择性方法只微调原始LLM参数的子集。你可以采用几种方法来确定要更新的参数。你可以选择仅训练模型的某些组件或特定层,甚至是单个参数类型。研究人员发现,这些方法的性能是参差不齐的,参数效率和计算效率之间存在显著的权衡。在本课程中,我们不会重点讨论它们。

重新参数化方法也使用原始LLM参数,但通过创建原始网络权重的新低秩转换来减少要训练的参数数量。这种类型的常用技术是LoRA,我们将在下一个视频中详细探讨。
最后,附加方法通过保持所有原始LLM权重冻结并引入新的可训练组件来进行微调。
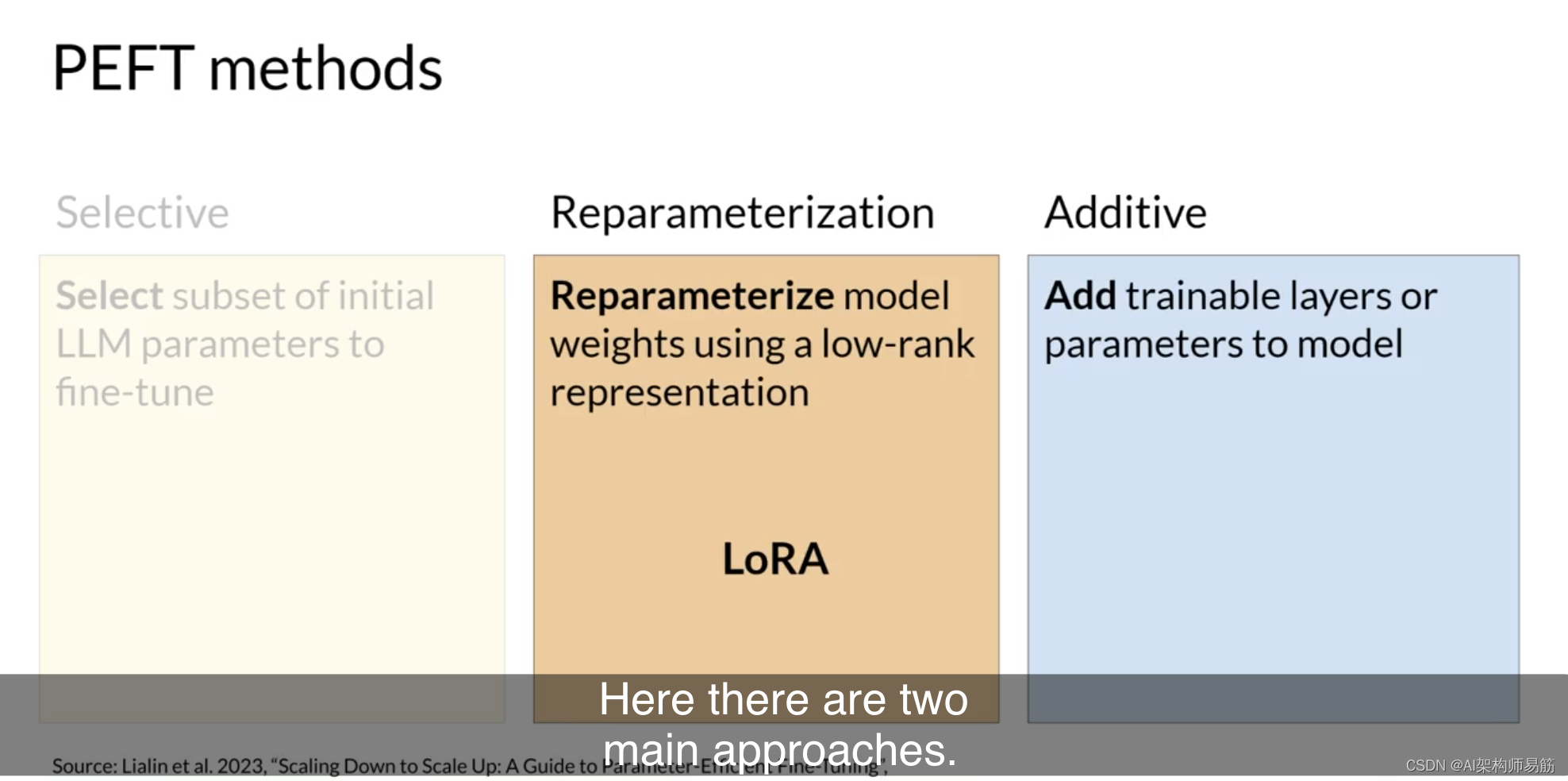
在这里,有两种主要方法。
适配器方法在模型的体系结构中添加新的可训练层,通常位于注意力或前馈层之后的编码器或解码器组件内。
另一方面,软提示方法保持模型体系结构固定且冻结,并专注于操作输入以实现更好的性能。可以通过向提示嵌入添加可训练参数或保持输入固定并重新训练嵌入权重来实现这一点。在本课程中,你将了解一种特定的软提示技术,称为提示微调。
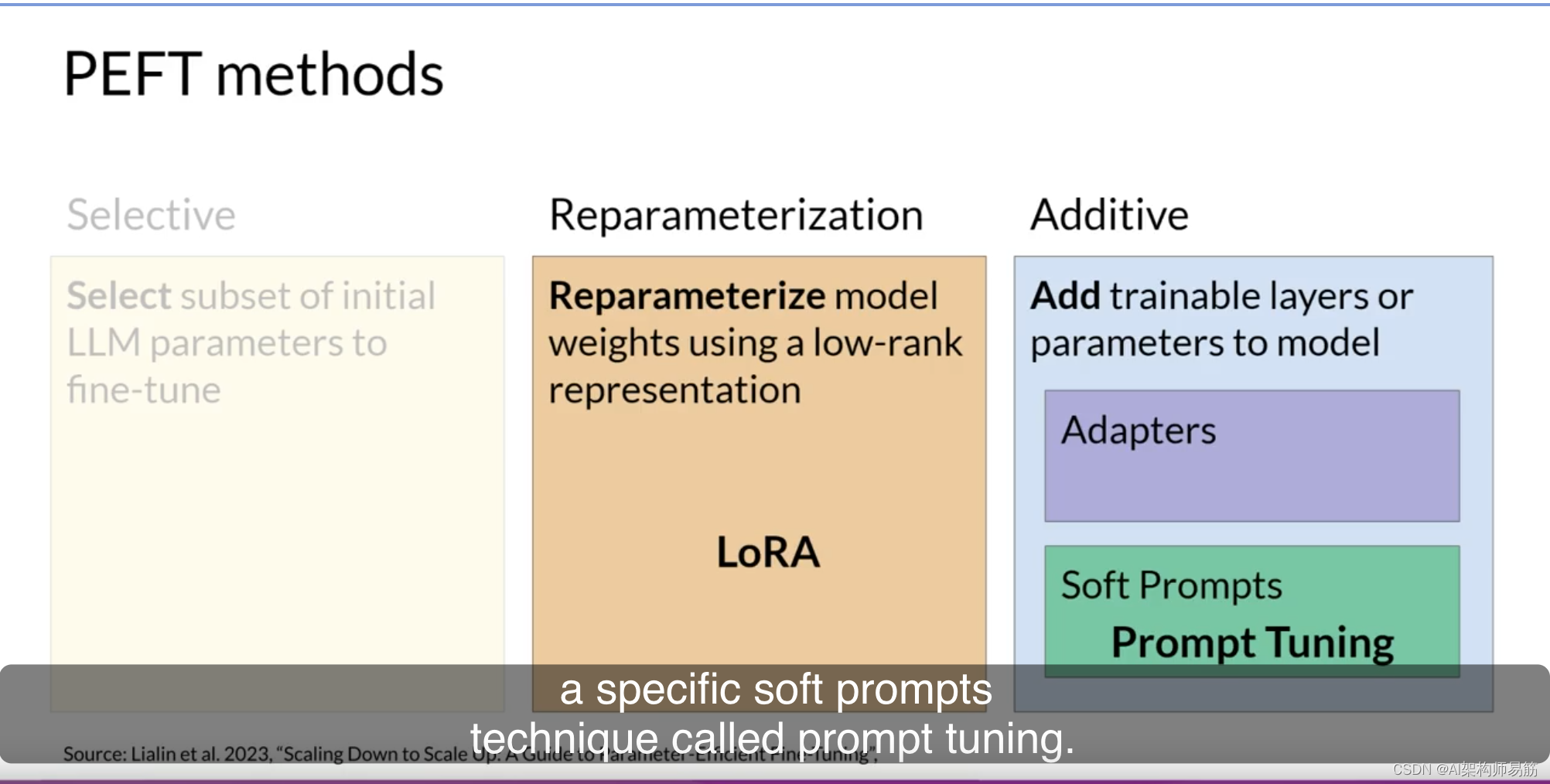
首先,让我们继续下一个视频,更详细地了解LoRA方法,看看它如何减少训练所需的内存。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/rCE9r/parameter-efficient-fine-tuning-peft