一、安装
Beautiful Soup 是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
pip install beautifulsoup4
二、使用案例
from bs4 import BeautifulSoup
import requests
import asyncio
import functools
import rehouse_info = []'''异步请求获取链家每页数据'''
async def get_page(page_index):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}request = functools.partial(requests.get, f'https://sh.lianjia.com/ershoufang/pudong/pg{page_index}/',headers=headers)loop = asyncio.get_running_loop()response = await loop.run_in_executor(None, request)return response'''使用xpath获取房屋信息'''
def get_house_info(soup):house_info_list = soup.select('.info') # 房屋titlereg = re.compile(r'\n|\s')for html in house_info_list:house_info.append({'title': re.sub(reg,'',html.select('.title a')[0].getText()),'house_pattern': re.sub(reg,'',html.select('.houseInfo')[0].getText()),'price': re.sub(reg,'',html.select('.unitPrice')[0].getText()),'location': re.sub(reg,'',html.select('.positionInfo')[0].getText()),'total': re.sub(reg,'',html.select('.totalPrice')[0].getText())})'''异步获取第一页数据,拿到第一页房屋信息,并返回分页总数和当前页'''
async def get_first_page():response = await get_page(1)soup = BeautifulSoup(response.text, 'lxml')get_house_info(soup)print(house_info)if __name__ == '__main__':asyncio.run(get_first_page())三、创建soup对象
soup = BeautifulSoup(markup=“”, features=None, builder=None,parse_only=None, from_encoding=None, exclude_encodings=None,element_classes=None)
- markup:要解析的HTML或XML文档字符串。可以是一个字符串变量,也可以是一个文件对象(需要指定"html.parser"或"lxml"等解析器)。
- features:指定解析器的名称或类型。默认为"html.parser",可以使用其他解析器如"lxml"、"html5lib"等。
- builder:指定文档树的构建器。默认为None,表示使用默认构建器。可以使用"lxml"或"html5lib"等指定其他构建器。
- parse_only:指定要解析的特定部分。可以传递一个解析器或一个标签名或一个元素的列表。
- from_encoding:指定解析器使用的字符编码。默认为None,表示自动检测编码。
- exclude_encodings:指定要排除的编码列表,用于字符编码自动检测。
- element_classes:指定要用于解析文档的元素类。默认为None,表示使用默认元素类。
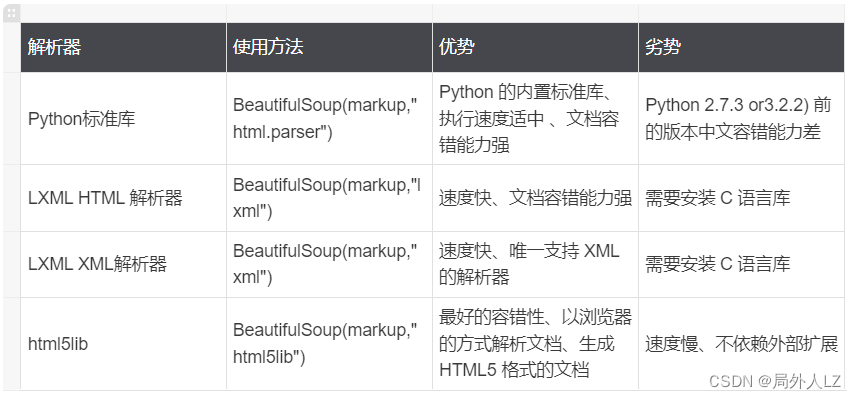
四、soup对象
- soup.prettify(encoding=None, formatter=“minimal”):返回格式化后的HTML或XML文档的字符串表示。它将文档内容缩进并使用适当的标签闭合格式,以提高可读性
- soup.title:返回文档的
标签的内容,如果存在的话 - soup.head:返回文档的标签的内容,作为一个BeautifulSoup对象
- soup.body:返回文档的标签的内容,作为一个BeautifulSoup对象
- soup.html:返回文档的标签的内容,作为一个BeautifulSoup对象
- soup.find(name, attrs, recursive, string)):在文档中查找具有指定名称和属性的第一个元素,并返回该元素的BeautifulSoup对象。可以使用name参数指定标签名称,使用attrs参数指定属性字典,使用recursive参数指定是否递归搜索子元素,使用string参数指定元素的文本内容,还可以使用其他关键字参数指定其他属性条件
- soup.find_all(name, attrs, recursive, string, limit)):在文档中查找具有指定名称和属性的所有元素,并返回这些元素的列表。参数和用法与find()方法相似,但它会返回所有匹配的元素
- soup.select(selector)):使用CSS选择器语法在文档中查找元素,并返回匹配的元素列表。选择器可以是标签名、类名、id、属性等。返回的是一个BeautifulSoup对象的列表
- soup.get_text():获取文档中所有元素的文本内容,并将它们连接成一个字符串返回
- soup.get(attrName):获取属性值
- soup.find_parents(name, attrs, recursive, string)):在文档中查找具有指定名称和属性的所有父元素,并返回这些父元素的列表
- soup.find_next_sibling(name, attrs, string)):在文档中查找具有指定名称和属性的下一个同级元素,并返回该元素的BeautifulSoup对象
- soup.find_previous_sibling(name, attrs, string)):在文档中查找具有指定名称和属性的上一个同级元素,并返回该元素的BeautifulSoup对象
- soup.find_next(name, attrs, string)):在文档中查找具有指定名称和属性的下一个元素,并返回该元素的BeautifulSoup对象
- soup.find_previous(name, attrs, string)):在文档中查找具有指定名称和属性的上一个元素,并返回该元素的BeautifulSoup对象
- soup.decompose(): 从文档中移除当前元素,并清理其占用的内存。
- soup.encode(formatter=None): 将解析后的文档编码为字节字符串。
- soup.decode(encoding=“utf-8”, errors=“strict”): 将字节字符串解码为Unicode字符串。
- soup.new_tag(name, namespace=None, attrs={}, **kwargs)
- soup.new_string(s, parent=None): 创建一个新的字符串对象。
- soup.replace_with(replacement): 将当前元素替换为指定的元素或字符串。
- soup.wrap(wrapper): 将当前元素包装在指定的包装器标签中。
from bs4 import BeautifulSouphtml_str = '<html><head><title>我是标题</title></head><body><div><div class="div1">我是div1</div><div class="div2">我是div2</div><div class="div3">我是div3</div></div></body</html>'soup = BeautifulSoup(html_str, 'lxml')
print('title:',soup.title)
print('head:', soup.head)
print('body:', soup.body)
print('html:', soup.html)
print('find:', soup.find('div',attrs={'class':'div1'}))
print('find_all:', soup.find_all('div'))
print('select:', soup.select('.div1'))
print('get_text:', soup.select('.div1')[0].get_text())
print('get:', soup.select('.div1')[0].get('class'))
div1 = soup.select('.div1')[0]
print('find_parents:', div1.find_parents('div'))
print('find_next_sibling:', div1.find_next_sibling())
print('find_previous_sibling:', div1.find_previous_sibling())
print('find_next:', div1.find_next())
print('find_previous:', div1.find_previous())