redis的zset有两种数据结构:跳表和压缩列表
压缩列表除了一般元素外还包括列表长度、列表元素个数、尾部偏移量、列表结束标识等。在zset的长度较小的时候,用这个比较好
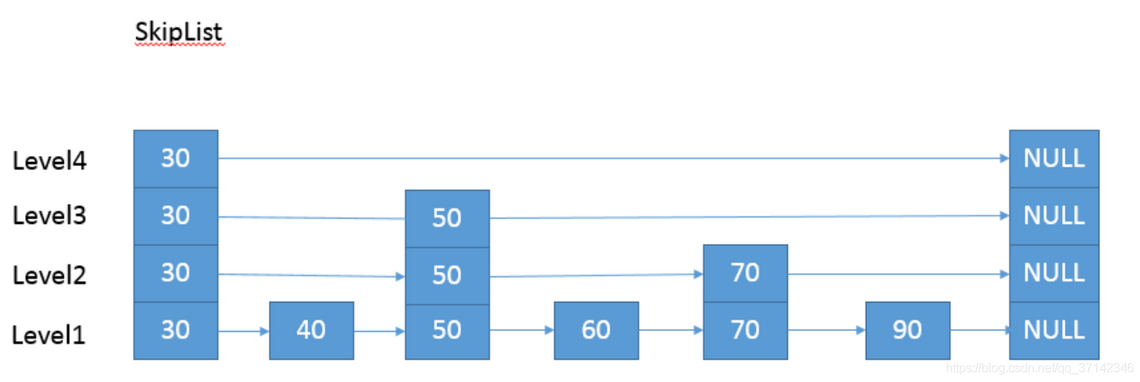
什么是跳表
跳表是在链表的基础上,增加了多层索引,利用多级索引的跳转快速实现查询。每次新增一个节点,他的上层索引的设置概率为50%,即如果对于这个节点来说运气好的话,他能一直向上设立索引。大体来看,整体就像二分一样。数据量特别大的时候时间复杂度为logn
为什么mysql使用B+树,而redis的zset使用跳表呢?
redis直接操作内存,不需要进行磁盘IO。而MySQL需要读取io。如果使用跳表实现MySQL,会出现非常高的层级,会极大增加磁盘io的开销。而redis使用跳表则是因为该数据结构在内存中查找插入和删除非常简单高效,