Prometheus 和 Grafana 是两个非常流行的开源工具,通常结合使用来实现监控、可视化和告警功能。
它们在现代 DevOps 和云原生环境中被广泛使用。
1、Prometheus
定义:
Prometheus 是一个开源的系统监控和告警工具包,最初由 SoundCloud 开发,现在是 CNCF(云原生计算基金会)的毕业项目。
核心功能:
数据采集:通过拉取(Pull)方式从目标服务(如应用程序、服务器、数据库等)收集指标数据。
数据存储:将采集到的时序数据(Time Series Data)存储在本地或远程存储中。
查询语言:提供强大的查询语言 PromQL,用于分析和查询监控数据。
告警功能:支持基于规则的告警,可以通过 Alertmanager 发送告警通知(如邮件、Slack、PagerDuty 等)。
特点:
多维数据模型(通过标签区分不同的指标)。
支持服务发现,动态监控目标。
高性能,适合大规模监控。
适用场景:
监控 Kubernetes 集群。
监控微服务架构。
监控基础设施(如服务器、数据库、网络设备等)。
2、 Grafana
定义:
Grafana 是一个开源的指标分析和可视化工具,支持多种数据源(如 Prometheus、InfluxDB、Elasticsearch 等)。
核心功能:
数据可视化:通过丰富的图表(如折线图、柱状图、仪表盘等)展示监控数据。
多数据源支持:支持 Prometheus、InfluxDB、MySQL、Elasticsearch 等多种数据源。
仪表盘:用户可以创建和共享自定义的监控仪表盘。
告警功能:Grafana 也支持告警功能,可以根据指标设置告警规则并发送通知。
特点:
界面美观,交互性强。
支持插件扩展,功能丰富。
社区活跃,有大量现成的仪表盘模板。
适用场景:
可视化 Prometheus 的监控数据。
分析和展示时序数据。
创建自定义的监控和运维仪表盘。
3、 Prometheus + Grafana 的结合
Prometheus 负责数据采集和存储,而 Grafana 负责数据的可视化和展示。
典型工作流程:
Prometheus 从目标服务(如应用程序、服务器)拉取指标数据。
Prometheus 将数据存储在其时序数据库中。
Grafana 连接到 Prometheus 数据源,查询数据并展示在仪表盘上。
用户通过 Grafana 的仪表盘实时监控系统状态。
如果需要告警,可以通过 Prometheus 的 Alertmanager 或 Grafana 的告警功能发送通知。
部署环境:
OS:Rocky Linux 9.4
上传所需软件版本:
prometheus-2.40.1.linux-amd64.tar.gz
grafana-enterprise-9.2.4-1.x86_64.rpm
node_exporter-1.4.0.linux-amd64.tar.gz

初始化操作:
关闭防火墙和seLinux,这台机之前关过了,所以没啥提示
systemctl stop firewalld
systemctl disable firewalld
setenforce 0 #临时关闭,也可在/etc/selinux/config文件里永久关闭

修改一下主机名:
hostnamectl set-hostname prometheus
下载prometheus安装包:
地址:https://prometheus.io/download/
解压并重命名和启动prometheus:
tar xf prometheus-2.40.1.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/prometheus-2.40.1.linux-amd64/ /usr/local/prometheus
nohup /usr/local/prometheus/prometheus --config.file="/usr/local/prometheus/prometheus.yml" &
查看启动情况:
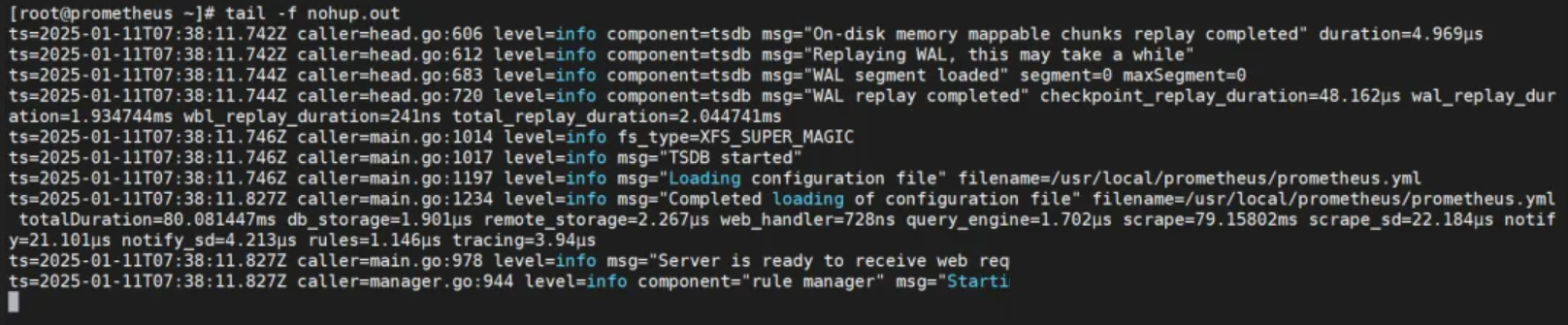
查看启动端口:
netstat -an |grep 9090

通过主机IP:端口浏览器访问:
默认可以查看到已监控本机
菜单Status -> Targets
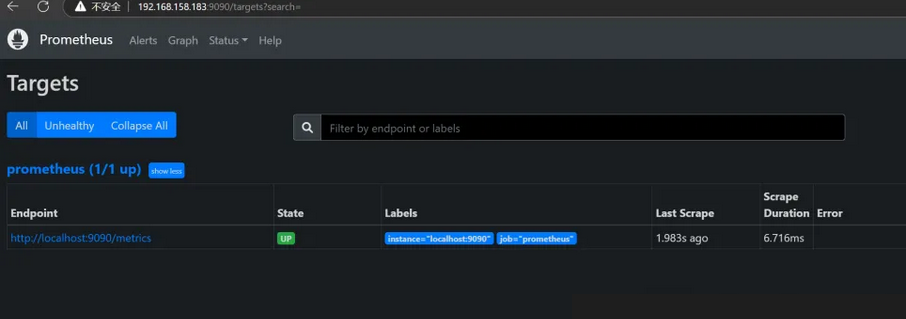
查看监控数据:主机IP:端口/metrics

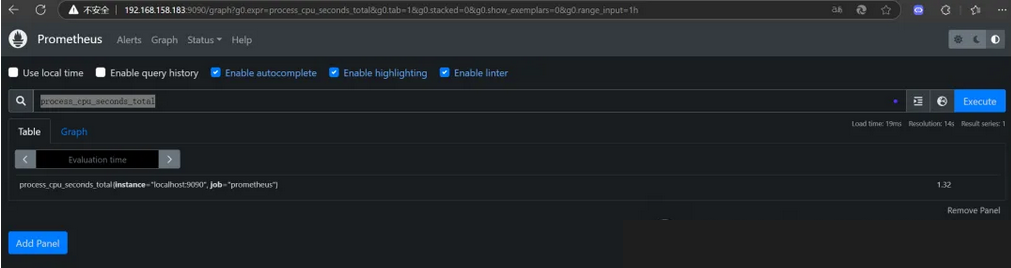
在WEB界面首页可以通过关键字搜索查询监控项
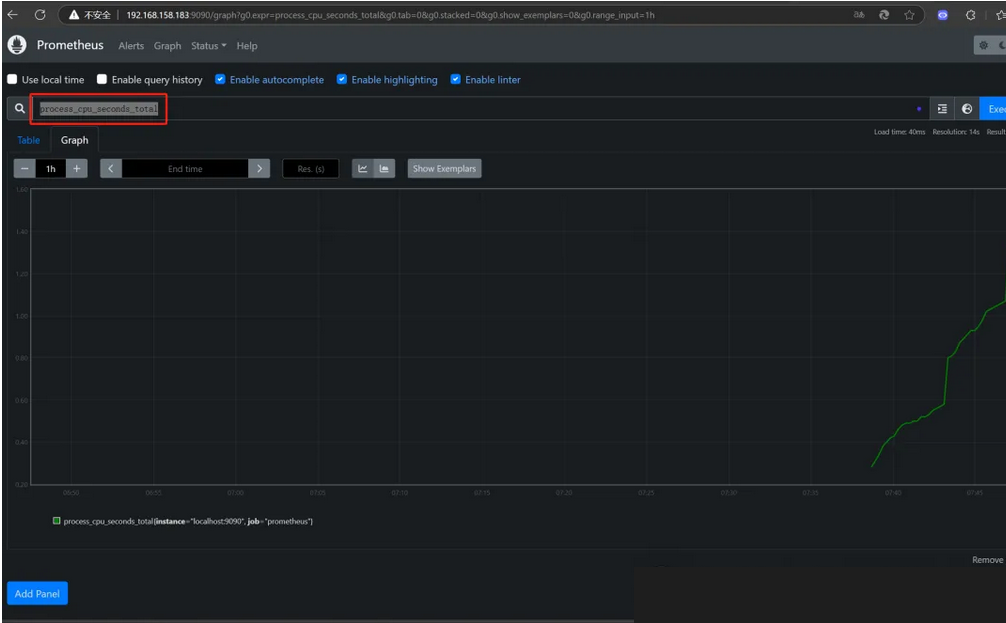
接下来安装Grafana图形化监测工具
官网:https://grafana.com/
下载安装包:
地址:
https://dl.grafana.com/enterprise/release/grafana-enterprise-9.2.4-1.x86_64.rpm
上传grafana的rpm包之后,先安装两个依赖
yum install fontconfig urw-fonts
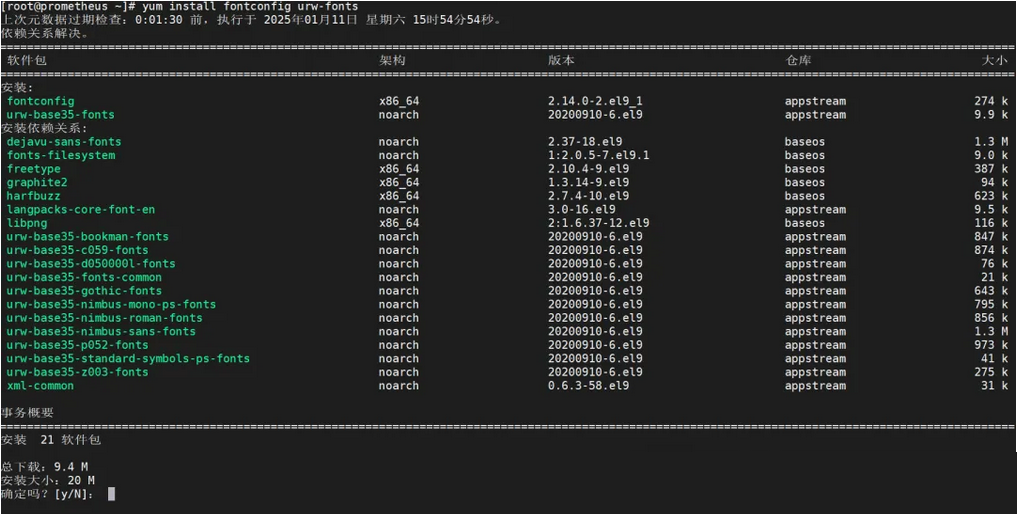
如果安装grafana报了这个问题:

我这里直接强制跳过了这个chkconfig依赖
rpm -ivh --nodeps grafana-enterprise-9.2.4-1.x86_64.rpm

接着启动grafana并查看端口号是否正在监听
systemctl start grafana-server
systemctl enable grafana-server
netstat -an |grep 3000

浏览使用主机ip:端口访问,默认账号密码:admin/admin
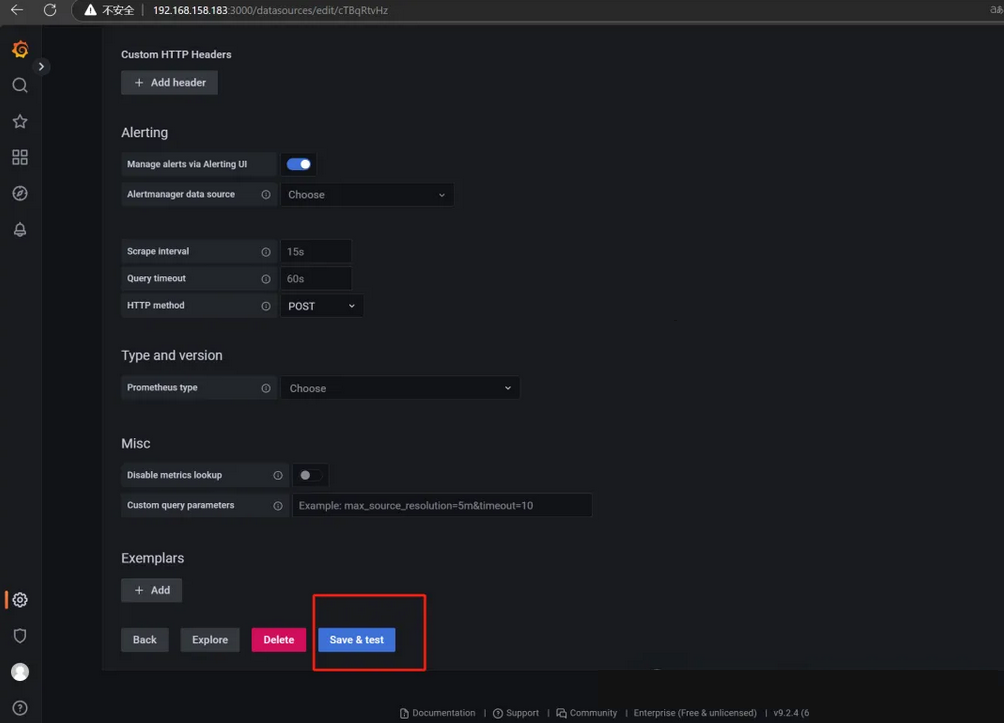
登录后把prometheus服务器收集的数据作为一个数据源添加到grafana,让grafana可以得到prometheus的数据
(1)从左侧导航栏找到Data sources菜单
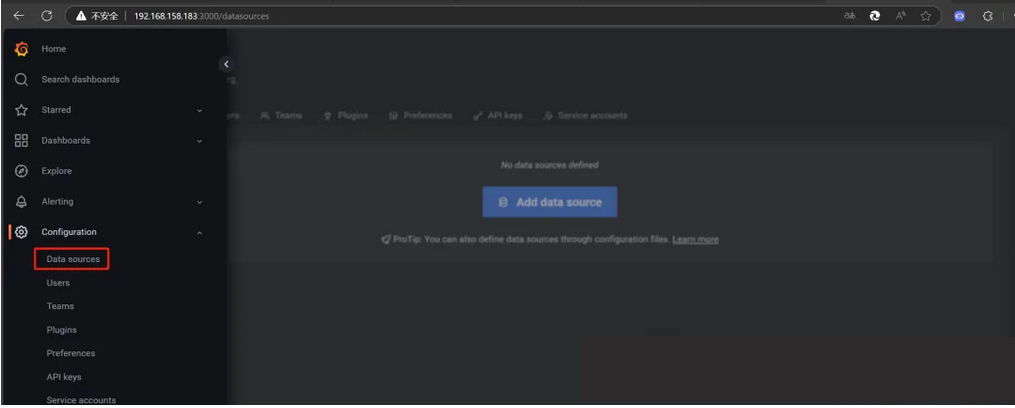

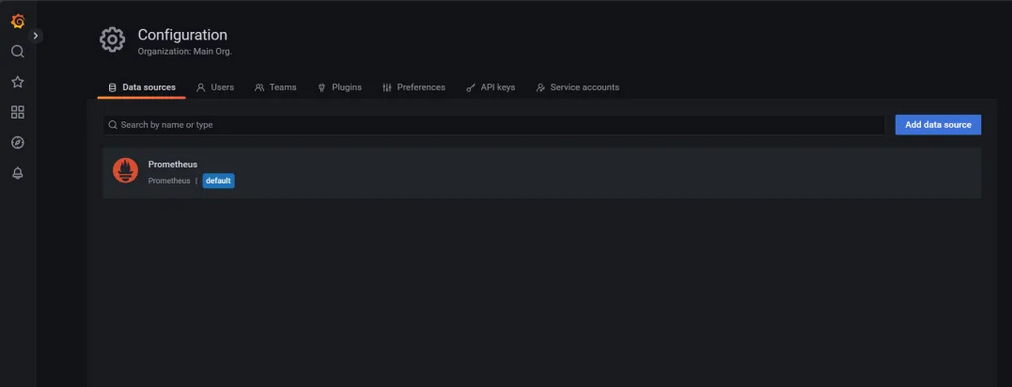
url填上PrometheusIP地址加端口

2.2配置Grafana仪表板
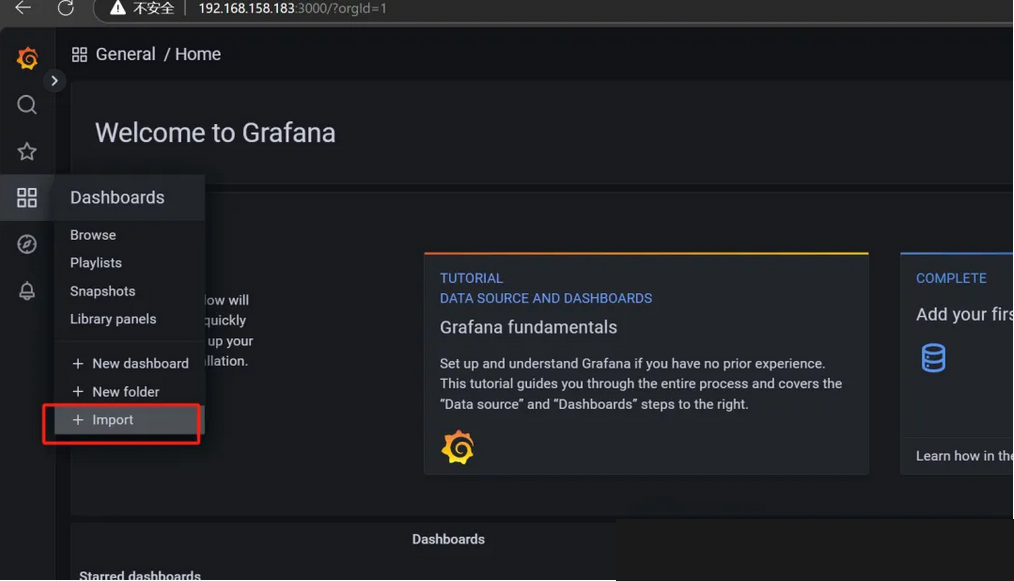
配置完数据源后,grafana接收到prometheus的数据需要使用仪表板展示,仪表板可自定义或导入模板,grafana官网也有非常多类型的模板供下载
Grafana dashboards | Grafana Labs
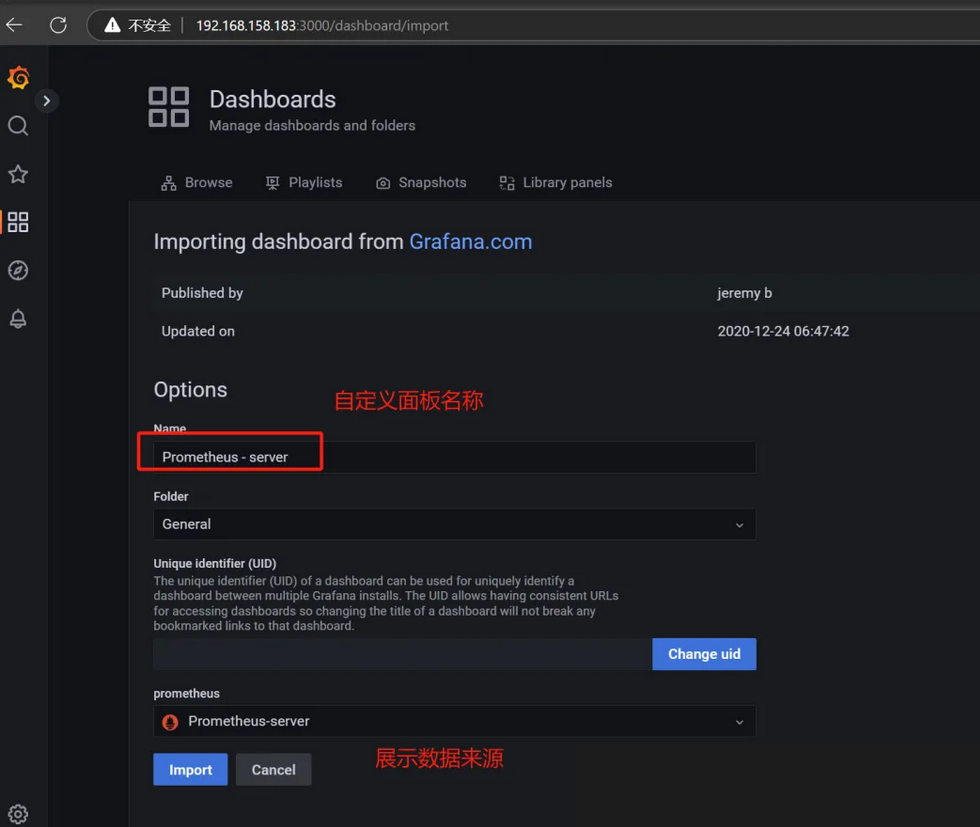
(1)从左侧导航栏找到导入仪表板,选择添加一个面板我选了官网的3662面板
接下来采集Linux主机系统资源
下载安装包:
地址:Download | Prometheus
上传采集器node_exporter-1.4.0.linux-amd64.tar.gz

解压文件
移动文件到/usr/local/目录下并重命名为node_exporter
启动采集器并修改默认端口
tar -zxf node_exporter-1.4.0.linux-amd64.tar.gz
mv node_exporter-1.4.0.linux-amd64 /usr/local/node_exporter
nohup /usr/local/node_exporter/node_exporter --web.listen-address=":9900" &

接下来配置prometheus
编辑prometheus.yml文件,配置监控项
[root@prometheus prometheus]# cat prometheus.yml
# my global config
global:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:#- "/usr/local/prometheus/rules.yml"# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: "prometheus"# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ["192.168.158.183:9090"]- job_name: 'linux'file_sd_configs:- files:- /usr/local/prometheus/node_exporter_targets.json

如果有大批量的机器要监控的话,为了方便维护,可以把所有主机信息单独存放到一个文件中
标签名:beijing代表这台机是北京区域的,prod代表是生产环境的,可自行修改。
[root@prometheus prometheus]# cat /usr/local/prometheus/node_exporter_targets.json
[{"targets": ["192.168.158.183:9900"],"labels": {"project": "beijing","env": "prod"}}
]
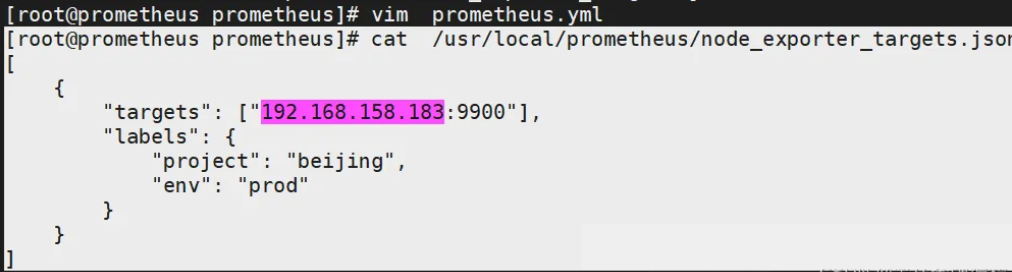
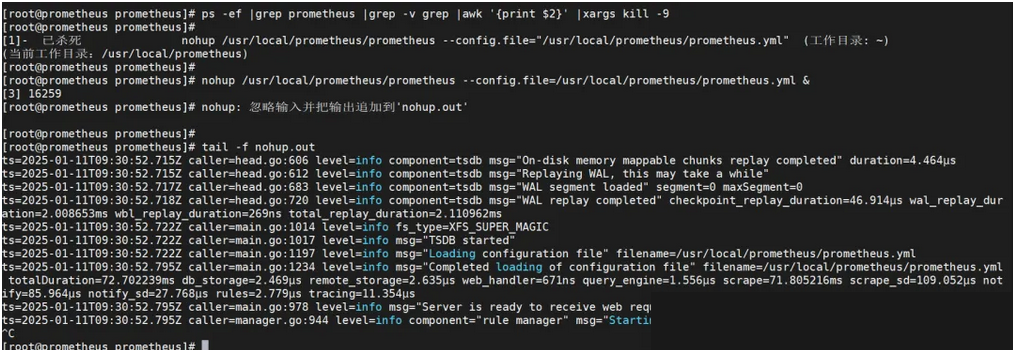
接下来执行
ps -ef |grep prometheus |grep -v grep |awk '{print $2}' |xargs kill -9
停止prometheus进程并启动。
nohup /usr/local/prometheus/prometheus --config.file=/usr/local/prometheus/prometheus.yml &
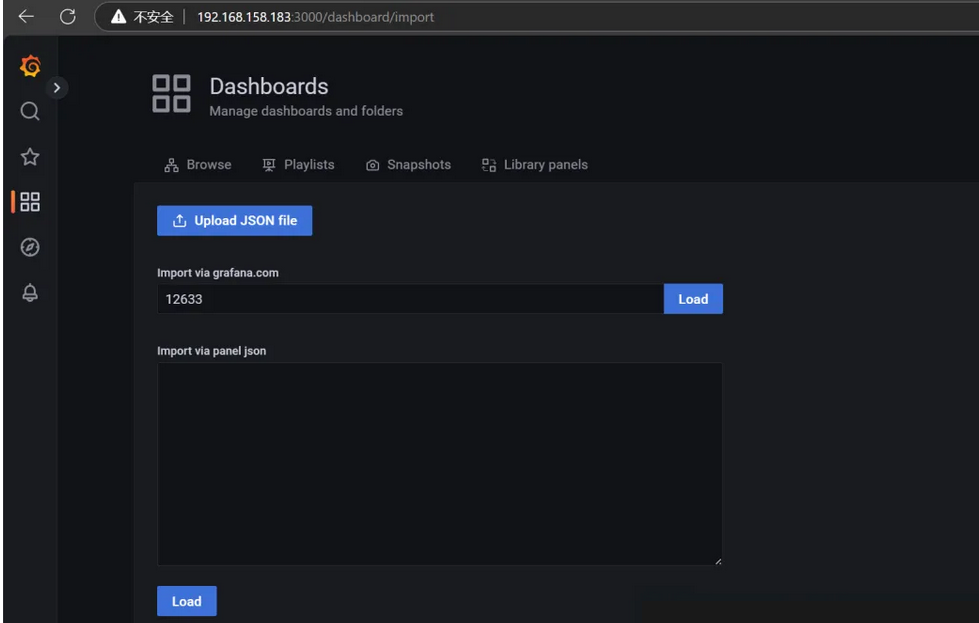
接下来在grafana导入linux主机详情监控面板
我选择了这个面板
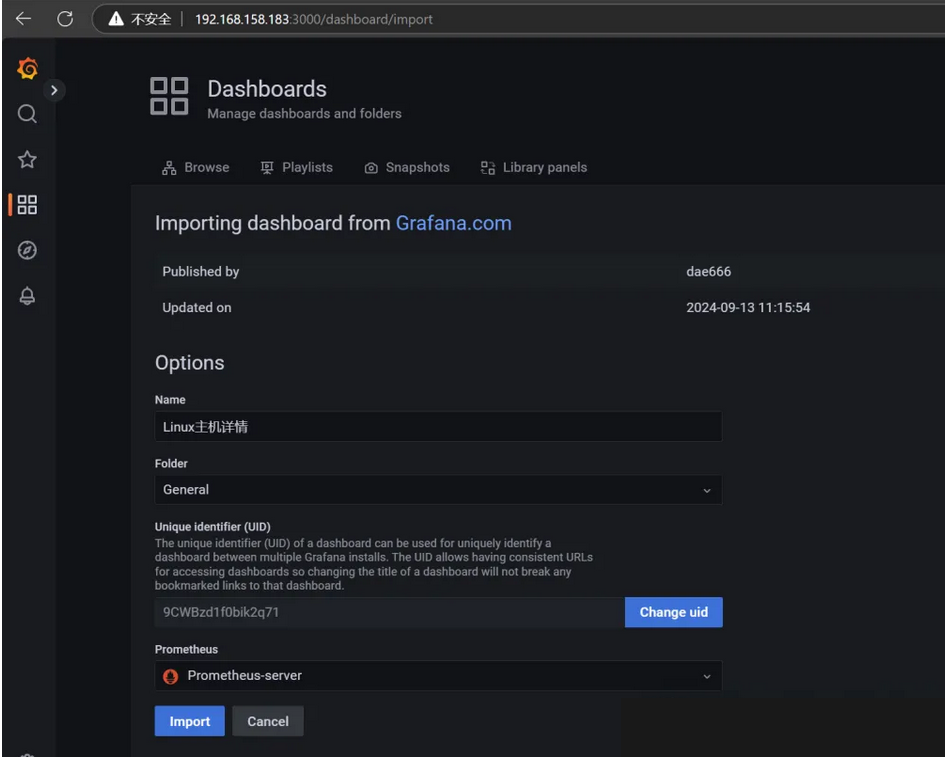
修改面板添加env变量并修改这两个查询语句
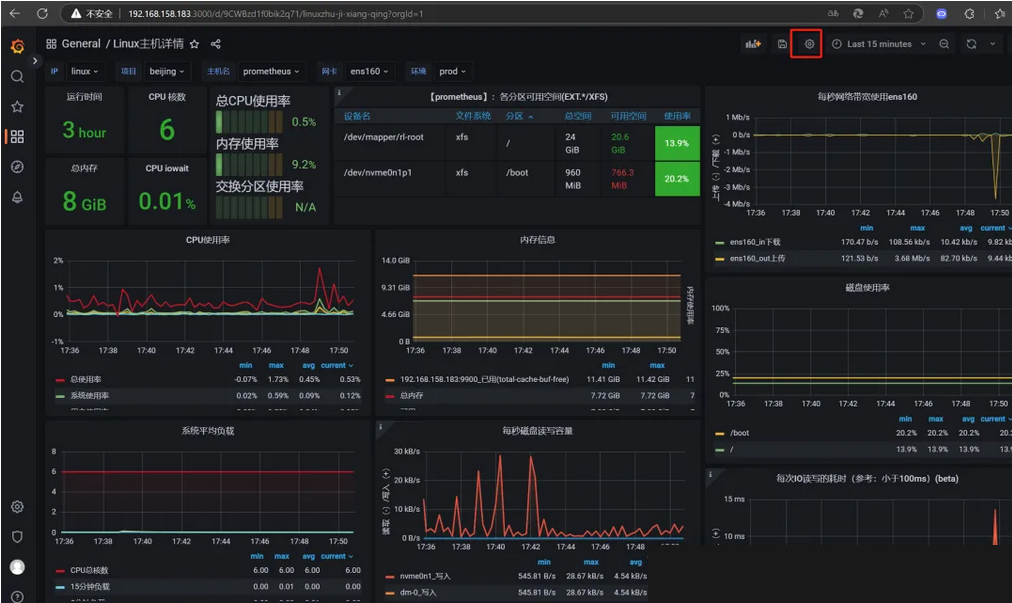
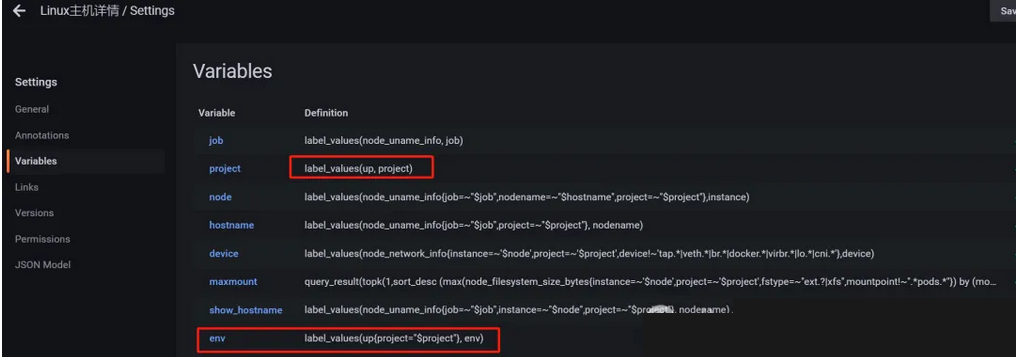
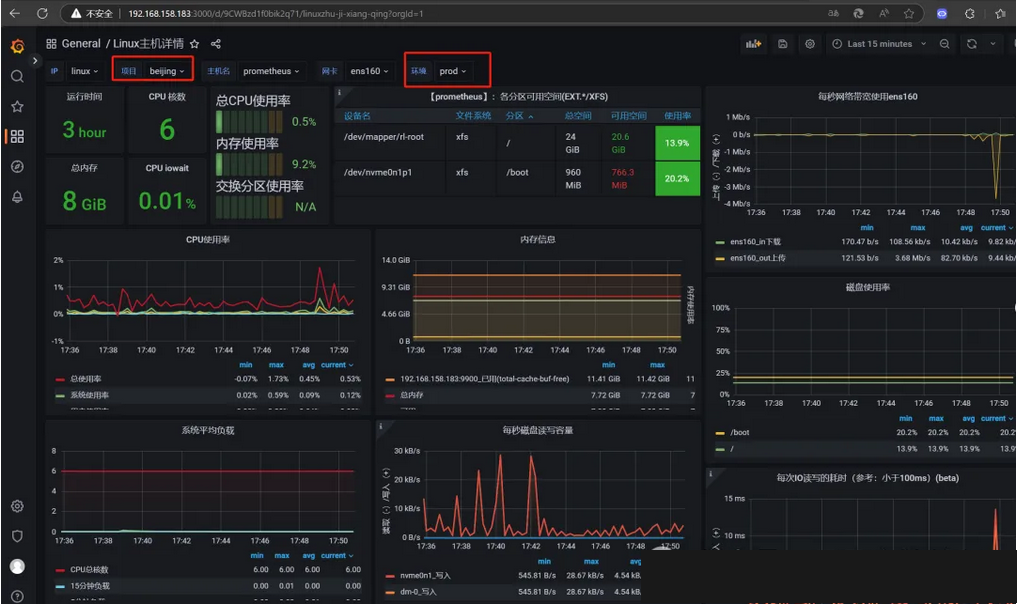
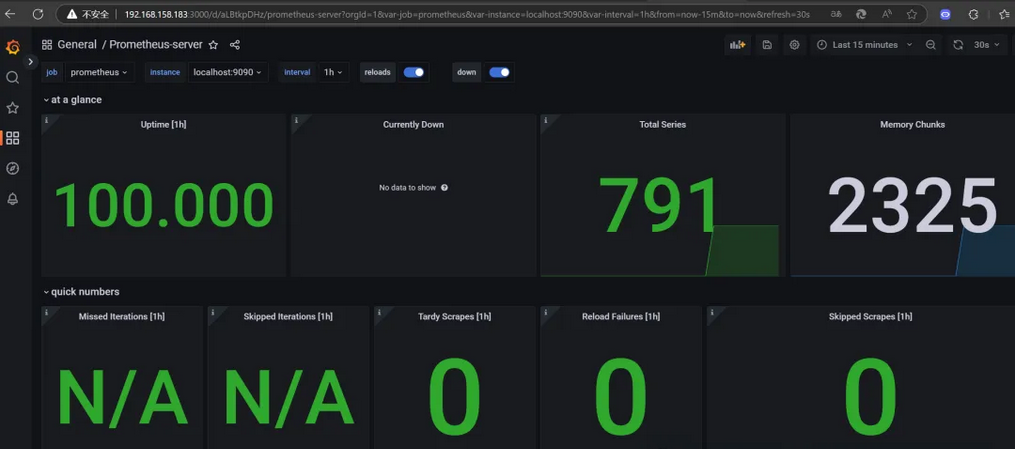
此时可以直观看到这台机的资源使用率,后续将继续完善监控系统添加报警功能。
原创 YQ编程 黑马金牌编程