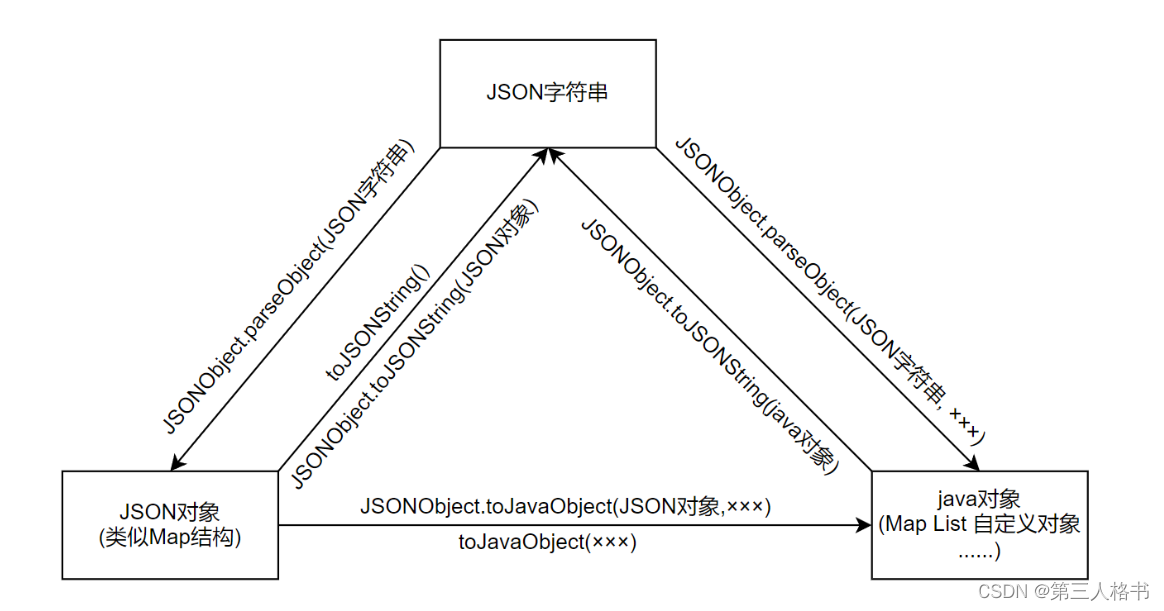
前言
本文总结深度学习领域的图像风格迁移发展脉络。重点关注随着GAN、CUT、StyleGAN、CLIP、Diffusion Model 这些网络出现以来,图像风格迁移在其上的发展。本文注重这些网络对图像风格迁移任务的影响,以及背后的关键技术和研究,并总结出一些经典论文作为学习参考。
目录
- Optimization-based Neural Style Transfer
- 基础结构
- AdaIN
- 基于GAN的风格迁移
- 基础结构
- CycleGAN
- loss优化
- 水墨画
- 风景画
- 卡通画
- 人脸肖像画
- CUT对比学习
- StarGAN 多域风格迁移
- 基于StyleGAN的风格迁移
- 基础结构
- 风格迁移实现
- few-shot style transfer
- Fixation and Adaptation
- Latent Space Adaptation
- JoJoGAN
- 基于自然语言语义信息(textual)指导的风格迁移
- CLIP
- 语义信息(textual)指导风格迁移
- CLIPStyle
- One-Shot Adaptation of GAN in Just One CLIP
- StyleGAN-NADA
- 基于Diffusion Model的风格迁移
- 基础结构
- 风格迁移实现
- DISENTANGLED STYLE AND CONTENT REPRESENTATION
- Inversion-Based
- ProSpect
- T2I-Adapter
- 其余论文
Optimization-based Neural Style Transfer
基础结构
A Neural Algorithm of Artistic Style 2015

基于具有一定图像理解能力的VGG-16网络,对内容图像和风格图像进行特征提取,再根据这些特征的一阶特征矩阵(轮廓)构建content-loss,根据二阶特征矩阵(风格纹理)构建style-loss,使得新生成的图像内容符合内容图像、风格符合风格图像;



两个损失分别负责内容和风格生成的任务,可以生成质量较好的风格化图像,但具有以下缺点:
(1)每张内容/风格图像都要重新训练网络,训练时长也不短
(2)训练不稳定,很容易出现模式坍塌、过拟合等情况
(3)实用场景局限
AdaIN
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization 2017
在依据图像特征构建损失的过程中,有研究人员发现VGG网络中特征的均值/方差代表了风格,在构建损失前对图像特征进行去风格化(去除均值/方差),对网络学习效果和速度有很大的提升;



可以看到,Instance Norm是先去风格化再构建损失的曲线,收敛快、效果好;
AdaIN方法在图像风格迁移任务中被广泛应用,在后续网络中都有运用;
基于GAN的风格迁移
基础结构
Generative Adversarial Nets 2014


‘最锋利的剑与最坚固的盾’ 相互对抗,使得生成器能够从一个噪声空间中学习到向目标图像域的映射,最终生成器能够不断生成我们需要的图像;
直接利用在风格迁移:对预训练好的生成器微调,数据集换成风格图像,微调较少的epoch,即将原域图像映射到风格图像域中;
基于GAN的风格迁移缺点:
(1)模式坍塌、过拟合,当生成器‘记住’少数几幅风格图像,生成时将这些图像复制输出,则‘最锋利的剑与最坚固的盾’的机制将无法再约束模型;(解决:CycleGAN、CUT)
(2)Random noise 是一个抽象数学域,无法有效控制;(解决:StyleGAN、CycleGAN)
CycleGAN
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 2020



使用两组生成器/鉴别器,分别完成原域/目标域相互的转换;这样不仅可以保证输出结果是可控的,也通过循环一致性使得‘最锋利的剑与最坚固的盾’ 对抗机制持续有效,网络无法‘记住’风格图像(需要将输出图像重新转换到原域);
loss优化
仅仅通过对抗机制的损失约束模型,在特定艺术风格领域生成效果无法做到最好,通常需要额外的损失,增强模型学习能力;
水墨画
水墨画;线条、笔画模糊损失;
ChipGAN: A Generative Adversarial Network for Chinese Ink Wash Painting Style Transfer 2018

风景画
风景画:边缘损失
End-to-End Chinese Landscape Painting Creation Using Generative Adversarial Networks 2020

卡通画
卡通画:结构损失、纹理模糊损失、色彩损失
Learning to Cartoonize Using White-box Cartoon Representations 2020

人脸肖像画
人脸肖像画:边缘损失、基于细粒度鉴别器的五官约束损失
Unpaired Portrait Drawing Generation via Asymmetric Cycle Mapping 2020

CUT
Contrastive Learning for Unpaired Image-to-Image Translation 2020


在GAN的基础上引入特征之间的对比损失,对encoder端的特征按patch划分,然后相同部位的patch应当拉近距离,而不同部位的patch则推远;此方法对于保存原域特征十分有效,且对比损失会利于特征解耦,有利于特征向目标域映射;
(1)对比学习的思想在后续研究中都会有涉及(StyleGAN、Diffusion Model)
(2)对比学习在特定艺术风格迁移任务上,也需要辅助的loss设计,如上
StarGAN 多域风格迁移
StarGAN v2: Diverse Image Synthesis for Multiple Domains 2020




以往的研究都是完成单个域之间的转换,如 马<=>斑马,人脸<=>笑脸,人脸<=>哭脸;有两个缺点:
(1)每两个单域的转换都需要训练一个网络,实用受限;
(2)许多转换任务应当是可以共享参数资源的,如人脸表情的转换;
因此,starGAN提出在风格迁移任务中用域标签标定多个目标域,在网络设计和损失中增加多域分类的任务,使得网络可以根据特定的域标签实现向目标域的风格迁移;
最终,一个主干网络、多个子目标域对应的模块,即可实现单个域向多个目标域的风格迁移;但是仍然有很大的提升空间:
- 风格迁移的域仍然是有限的,想实现更细致的转化还是很难;如:在伤心脸和哭脸中 间应当还有很多种状态,而不是简单的跳变;
- 风格style空间的定义仍然是一个不可控的域,无法观察到特征变化与实质结果的对 照,无法对这个style空间进一步控制;
基于StyleGAN的风格迁移
基础结构
A Style-Based Generator Architecture for Generative Adversarial Networks 2020

(1)与传统GAN中latent是随机不可控噪声不同,StyleGAN用一个Mapping网络将latent映射到一个18*512的向量空间,这个向量空间是可解释、可控的,对应着生成图像各个层次的风格特征;
(2)原先的随机噪声由另一端B引入,且同样分多层引入,以实现多层次的风格控制生成;Noise与上层输出合并后经过AdaIN去风格化,以使得A实现对style的控制;
(3)网络结构更大、层数更多,大量数据训练后有强大的生成能力

风格控制能力:替换原图像的某几层latent为目标图的,以实现多层次的控制;如上图,StyleGAN的风格控制是分层次的、且接近线性的,可实现不同程度的控制;如粗粒度对应性别和脸型、中粒度对应脸部特征、细粒度对应皮肤纹理;
问题:StyleGAN的风格控制/迁移只能在其原先的域内完成,如表情/脸型的变化;当想往Latent域外迁移时则做不到,如实现 人脸=>素描;
风格迁移
使用StyleGAN实现向Latent域外迁移,与GAN中的方法一样,通过鉴别器、特定损失设计、对比损失等进行约束,训练模式与普通的GAN相似;
由于预训练好的StyleGAN(大模型雏形)已经有很强的图像表征能力了,因此在实现风格迁移时往往不需要大量目标域图像,研究重点往往放在few-shot style transfer上;使用5-10张目标域的图像对StyleGAN进行微调,使其生成的图像符合目标域特征;
few-shot style transfer
使用StyleGAN微调以实现风格迁移,关键难点在于:
(1)从少量风格图像中充分利用风格特征信息;
(2)保持StyleGAN原域结构不破坏,防止StyleGAN‘记住’少量风格图像欺骗鉴别器,而不去微调完成风格迁移的任务;
Fixation and Adaptation
(1) 固定一个StyleGAN,微调另一个;在输出端运用细粒度的鉴别器以充分利用风格信息,对称生成图像的特征层用KL散度损失以约束StyleGAN原域的结构;
Few-shot Image Generation via Cross-domain Correspondence 2021



(2) 对微调前后的StyleGAN中相同层的self-correlation矩阵进行一致性约束,以确保原域结构不破坏;微调前后输出图像的Latent相互关系约束对齐,以保持StyleGAN原域结构;细粒度的鉴别器充分学习风格特征;
Few shot generative model adaption via relaxed spatial structural alignment 2022



(3) 与前两个方法相似,但是引入CUT对比损失加强风格学习能力
CtlGAN: Few-shot Artistic Portraits Generation with Contrastive Transfer Learning 2022

A Closer Look at Few-shot Image Generation 2022

Latent Space Adaptation
不微调StyleGAN网络的参数,而是用一个Adaptor网络学习Latent Space的映射,将原域的Latent Space映射到目标域以实现风格迁移;这个方法基本不破坏StyleGAN原域的结构,但是风格学习能力十分有限;
ONE-SHOT GENERATIVE DOMAIN ADAPTATION 2021

JoJoGAN
JoJoGAN: One Shot Face Stylization 2022
小结
StyleGAN 风格迁移的总结;
优点:
(1)基于StyleGAN的风格迁移可以在少量数据下学习效果很好;
(2)具有风格控制能力(Latent Space),迁移后的网络不同层输入的Latent可以控制使用原域或者目标域的,以实现多层次的风格迁移控制;
缺点:
直接操作Latent Space控制生成还是需要一定的专业知识,要懂得StyleGAN的结构才能完成;
因此,再进一步的研究目标应该是让这个风格控制可以通过自然语言控制;
基于自然语言语义信息(textual)指导的风格迁移
CLIP
Learning Transferable Visual Models From Natural Language Supervision 2021

原始的CLIP:基于对比学习,在大量图-文对数据上进行训练,让图像特征和文本特征在同一个向量空间中对齐;这个空间包含了图像和文本域的相关信息,因此我们可以根据自然语言得到其在图像层面的特征,进一步控制风格迁移的过程;
发展的CLIP:预训练数据越来越多,特征对齐完成度很高,文本信息能够和多层次的图像特征对齐,在控制风格迁移时效果越来越好;
语义信息(textual)指导风格迁移
基本思想:对于原域和目标域有准确的文本描述,网络输出图像和原域图像在CLIP向量空间中的距离应当与文本的距离一样,这个过程用对比损失约束;
语义信息的约束关键在输出端构建损失,而网络是不受限制的,可以是最初始的VGG、CycleGAN,也可以是StyleGAN;
(1) CLIPstyler: Image Style Transfer with a Single Text Condition 2022


(2) 在StyleGAN风格迁移上引入CLIP增强效果,原先训练模式和结构不变
One-Shot Adaptation of GAN in Just One CLIP 2022

(3) 没有使用风格图像,直接依靠CLIP的语义对齐能力,通过文本指导风格迁移
StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators 2022

基于Diffusion Model的风格迁移
相比于StyleGAN,Diffusion Model的图像生成能力进一步增强,且图像生成的控制约束不再通过特定的损失loss,而是解耦成一些condition(textual信息、辅助图像特征等),对于Latent Space的控制更强、实用性更高;
基础结构
原始的Diffusion Model:
Diffusion Models Beat GANs on Image Synthesis NeurlIPS 2021

不像GAN模型那样研究从噪声中逐渐生成完整图像,而是每一步都给原图像加随机噪声,再通过网络从加噪后的图像中还原出噪声,重复500-1000个steps,网络对图像多层次的特征都能学习到,并且能够对这些特征进行 ‘反扩散’ 也即控制;
优化增强的Diffusion Model
High-Resolution Image Synthesis with Latent Diffusion Models 2022



(1)不在原本的像素空间上建模扩散模型,而是构建出一个 Latent Space,增强模型能力
(2)网络对噪声的预测过程中,增加若干控制信号 condition,通过Transformer的交叉注意力机制进行学习;
(3)这里的condition可以是 CLIP 编码的 textual 信息(基于文本的图像生成)、风格图像(风格迁移的实现)、Semantic Map(图像分割的实现)
风格迁移实现
将风格图像嵌入为 condition,微调扩散模型,使得扩散模型能够学习到风格condition;
(1) 基于目标图像的 condition、对比损失优化,微调模型,实现风格迁移
DIFFUSION-BASED IMAGE TRANSLATION USING DIS- ENTANGLED STYLE AND CONTENT REPRESENTATION 2022

(2) 将图像通过 CLIP 编码得到特征 condition,再通过一个额外的Attention层优化
Inversion-Based Creativity Transfer with Diffusion Models 2022



(3) 研究不同step对于生成图像的控制:对应StyleGAN中不同层的控制;将condition分解成若干个控制向量,以实现细致的风格迁移与控制
ProSpect: Expanded Conditioning for the Personalization of Attribute-aware Image Generation 2023

上述三个方法思路相似,通过目标域图像的 condition 微调扩散模型参数,以实现风格迁移,对应 StyleGAN 中的 Fixation and Adaptation;下述方法不微调模型,而是通过调整 Latent Space 的分布,以实现风格迁移,对应 StyleGAN 中的 Adaptor;
(4) 通过额外接入 Adaptor 引入 condition,不调整模型参数,而是让 Adaptor 学习怎样产生符合扩散模型需求的控制向量 condition
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models 2023

其余论文
(1) 通过 ChatGPT 增强文本提示,并构建对比损失,模型更稳健;提出 cross-attention guidance,观察到 Transformer 中的 cross-attention map 对应了生成图的结构,因此尽力保存这个map的一致
Zero-shot Image-to-Image Translation 2023
(2) 增多Diffusion Model中的condition条件,实现对图像的多层次信息控制
Composer: Creative and Controllable Image Synthesis with Composable Conditions 2023