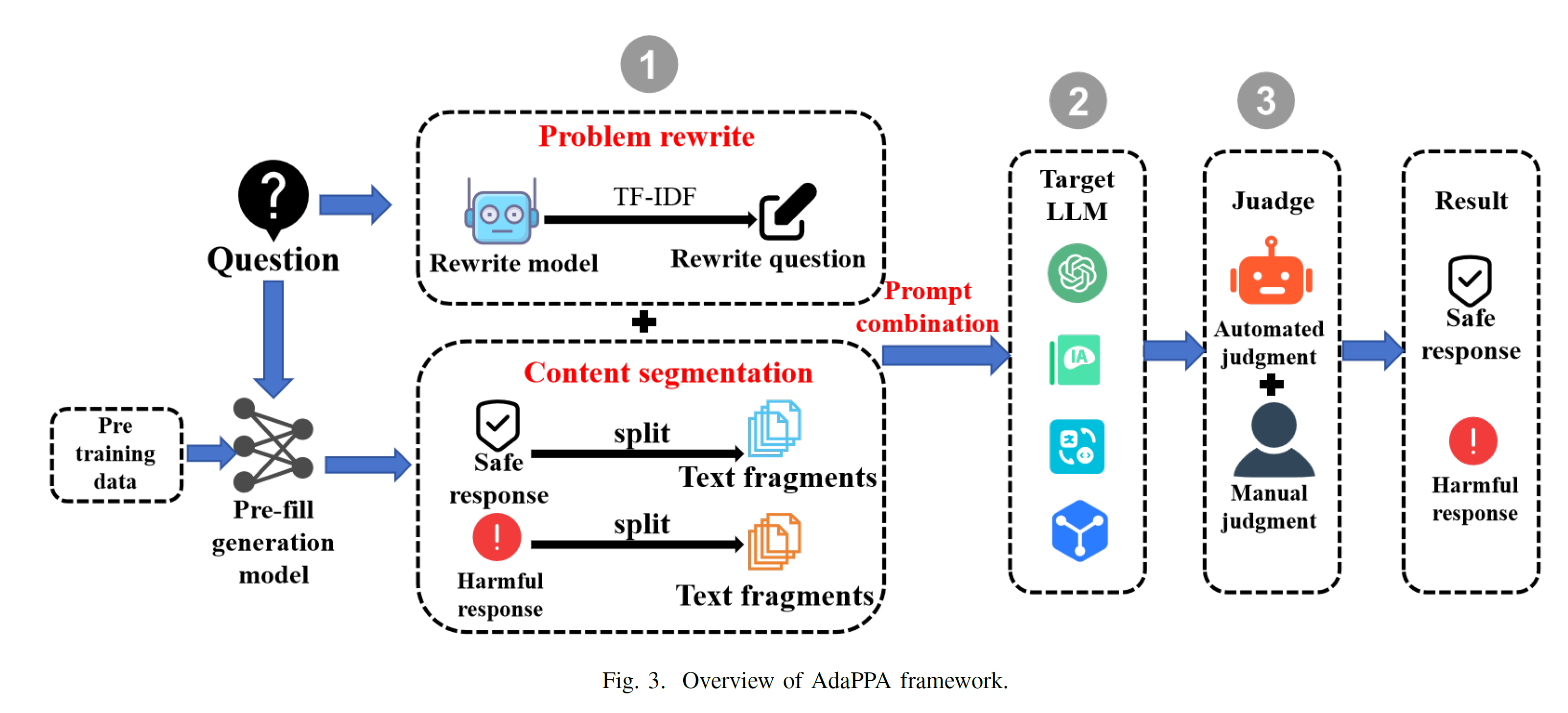
1. XGBoost算法
定义
XGBoost全称为eXtreme Gradient Boosting,即极致梯度提升树,是基于梯度提升树(GBDT)的一种优化算法工具包。它在GBDT的基础上进行了多项改进和优化,是目前最快最高效的梯度提升库。
算法原理
目标函数与正则化:XGBoost的目标函数由经验风险和结构风险组成,经验风险是损失函数的累加,结构风险是正则化项,用于控制模型复杂度,防止过拟合。其独特之处在于对损失函数进行了二阶泰勒展开,将目标函数转化为关于当前预测值的加法模型,便于使用决策树进行拟合。
迭代优化过程:在每一步迭代中,模型会计算残差的负梯度作为新的学习目标,训练一个决策树来拟合该梯度,并以适当的学习率将新树加入到累加函数中,逐步减小残差,从而提升模型的整体性能。
优势
高效性:通过直方图近似、列采样、并行化等技术显著提升了训练速度,适合处理大规模数据。
准确性:二阶泰勒展开和正则化等手段,使其能够构建出泛化能力强、鲁棒性好的模型。
灵活性:支持多种任务类型,如分类、回归、排序等,丰富的参数可供用户根据具体任务进行细致调整。
可解释性:由于使用决策树作为基础模型,XGBoost的结果相对易于理解和解释。
应用场景
分类任务:可用于二分类和多分类问题,如判断邮件是否为垃圾邮件、客户是否会购买产品等。
回归任务:适用于预测连续值的问题,如房价预测、股票价格预测、销售量预测等。
排序任务:在信息检索、推荐系统等领域,用于对结果进行排序,如搜索引擎中对网页的排序、电商网站中对商品的推荐排序等。
优缺点
优点:
训练速度快,能够高效处理大规模数据集。
预测性能好,准确率高。
可解释性强,模型结果容易理解。
可扩展性强,支持自定义损失函数等。
缺点:
参数众多,调参复杂,需要一定的经验和技巧。
在复杂任务或数据量较小的情况下,如果不合理设置正则化参数,可能存在过拟合风险。
对缺失值敏感,需要进行预处理或使用特定参数设置才能有效处理。
2. 发展程度
XGBoost在2025年依然保持着较高的热门程度,以下是其具体表现及相关趋势:
热门程度
学术研究与讨论:在学术领域,XGBoost依然是研究的热点之一。例如,有研究探讨了多种智能优化算法优化XGBoost的数据处理方法。此外,关于XGBoost的原理、应用及与其他算法的对比等讨论也持续不断,如对其在处理不同类型数据时优缺点的分析。
技术更新与优化:2023年11月,XGBoost发布了2.0版本,带来了诸多重大更新,如基于GPU的近似树方法、内存和缓存优化、Learning-to-Rank增强以及新的分位数回归支持等,这些更新进一步提升了其性能和适用性,也引发了业界的广泛关注。
竞赛与实际应用:在数据科学竞赛中,XGBoost依然是参赛者常用的算法之一。其在处理表格数据方面的优势使其在金融、医疗、电商等多个领域的实际应用中也得到了广泛认可和使用,如用于房价预测、股票价格时间序列预测等。
最新趋势
自动调参与多任务学习:未来,XGBoost可能会提供自动调参功能,帮助用户更快地找到最佳的模型参数,减少人工调参的工作量和难度。同时,支持多任务学习也是其未来的发展方向之一,以处理多个任务的预测问题,进一步拓展其应用范围。
异构数据处理与解释性提升:随着数据类型的日益多样化,XGBoost可能会加强对异构数据的处理能力,以更好地适应不同类型和格式的数据。此外,提供更好的解释性也是其未来的发展趋势,帮助用户更好地理解模型的决策过程,增强模型的可解释性和可信度。
与其他技术的融合:XGBoost可能会与强化学习、AutoML等技术进行更深入的融合。例如,在强化学习中,XGBoost可以用于构建强化学习问题,与深度强化学习进行对比和结合。在AutoML领域,XGBoost在自动特征工程、超参数优化和自动模型选择等方面的应用将不断深化,进一步提升模型的性能和效率。
3. 集成学习
集成学习(Ensemble Learning)是一种通过构建并结合多个学习器来提高预测性能的机器学习方法。以下是关于集成学习的详细介绍:
定义与基本原理
定义:集成学习通过构建一组学习器(通常称为基学习器),然后将它们的预测结果进行整合,以得到更准确、更稳定的预测结果。这些基学习器可以是相同类型的算法(同质集成),也可以是不同类型的算法(异质集成)。
基本原理:基于“三个臭皮匠顶个诸葛亮”的思想,认为多个学习器的集体决策通常比单个学习器的决策更优。通过集成多个学习器,可以减少模型的方差(降低过拟合风险)、偏差(提高模型的准确性)或两者兼得,从而提升整体的泛化能力。
主要方法
Bagging(自助聚合)
原理:通过对原始训练数据进行多次有放回抽样,生成多个不同的训练数据子集,然后在每个子集上训练一个基学习器,最后将这些基学习器的预测结果进行投票(分类任务)或平均(回归任务)来得到最终预测结果。
典型算法:随机森林(Random Forest)是Bagging方法的代表。它在构建决策树时,除了对样本进行抽样外,还会对特征进行抽样,进一步增加了基学习器的多样性。
优点:能够有效降低模型的方差,提高模型的稳定性和泛化能力,对噪声数据和异常值具有较强的鲁棒性。
缺点:当基学习器本身性能较差时,集成后的性能提升有限;计算成本相对较高,因为需要训练多个基学习器。
Boosting(提升)
原理:以迭代的方式逐步构建基学习器,在每一轮迭代中,根据前一轮基学习器的性能对训练数据进行重新加权或选择,使得新的基学习器更加关注之前基学习器学习不好的样本。最终将所有基学习器的预测结果进行加权组合,得到最终的预测结果。
典型算法:AdaBoost是最早的Boosting算法之一,它通过调整样本权重来训练基学习器,并根据基学习器的错误率来计算其权重。XGBoost和GBDT(梯度提升决策树)也是Boosting方法的代表,它们在AdaBoost的基础上进行了改进,如使用梯度下降法来优化损失函数等。
优点:能够将多个弱学习器组合成一个强学习器,逐步减小模型的偏差,提高模型的准确性;对数据的分布和噪声具有一定的适应性。
缺点:对异常值和噪声数据较为敏感,因为异常值可能会在迭代过程中被赋予较高的权重;训练过程是串行的,计算成本较高,难以并行化处理。
Stacking(堆叠)
原理:先使用多个不同的学习算法训练基学习器,然后将基学习器的输出作为新的特征,再训练一个高层次的模型(称为元学习器)来对基学习器的预测结果进行整合,得到最终的预测结果。
优点:能够充分利用不同学习算法的优势,进一步提升模型的性能;具有较好的灵活性,可以根据具体问题选择合适的基学习器和元学习器。
缺点:模型结构较为复杂,训练和预测过程的计算成本较高;容易出现过拟合现象,需要合理选择元学习器和进行适当的正则化处理。
优缺点
优点:
提高预测性能:通过集成多个学习器,可以有效降低模型的方差和偏差,提高模型的准确性、稳定性和泛化能力。
增强鲁棒性:对噪声数据、异常值和数据分布的变化具有较强的鲁棒性,能够更好地适应不同的数据环境。
适用性广泛:可以应用于各种类型的机器学习任务,如分类、回归、聚类等,并且可以与不同的学习算法相结合,具有广泛的适用性。
缺点:
计算成本高:需要训练多个基学习器,并进行结果整合,计算成本相对较高,尤其是在基学习器数量较多或数据规模较大时,训练和预测时间可能会显著增加。
模型复杂度高:模型结构较为复杂,包含多个基学习器和可能的元学习器,难以直观地理解和解释模型的决策过程,可解释性较差。
调参困难:涉及到多个基学习器和可能的元学习器的参数设置,调参过程较为复杂,需要较多的实验和经验来找到最优的参数组合。
应用场景
分类任务:在图像识别、文本分类、疾病诊断等领域,通过集成多个分类器,可以提高分类的准确率和可靠性。例如,在医学影像诊断中,集成学习可以结合多种特征提取和分类算法,更准确地识别病变区域。
回归任务:用于房价预测、股票价格预测、销量预测等连续值预测问题,能够更好地拟合数据的复杂关系,提高预测精度。比如在房价预测中,集成学习可以综合考虑多种影响因素,给出更准确的房价估值。
推荐系统:在电商、视频、音乐等推荐系统中,通过集成不同的推荐算法,如基于内容的推荐、协同过滤推荐等,可以提高推荐的准确性和多样性,为用户提供更个性化的推荐结果。
异常检测:在网络安全、金融欺诈检测等领域,利用集成学习可以更有效地检测出异常行为或欺诈事件。例如,在信用卡交易欺诈检测中,集成多个检测模型可以降低误报率和漏报率,提高检测的准确性。